Connect to Azure Data Explorer using Apache Spark for Azure Synapse Analytics
This article describes how to access an Azure Data Explorer database from Synapse Studio with Apache Spark for Azure Synapse Analytics.
Prerequisites
- Create an Azure Data Explorer cluster and database.
- Have an existing Azure Synapse Analytics workspace, or create a new workspace by following the steps in Quickstart: Create an Azure Synapse workspace.
- Have an existing Apache Spark pool, or create a new pool by following the steps in Quickstart: Create an Apache Spark pool using the Azure portal.
- Create a Microsoft Entra app by provisioning a Microsoft Entra application.
- Grant your Microsoft Entra app access to your database by following the steps in Manage Azure Data Explorer database permissions.
Go to Synapse Studio
From an Azure Synapse workspace, select Launch Synapse Studio. On the Synapse Studio home page, select Data to go to Data Object Explorer.
Connect an Azure Data Explorer database to an Azure Synapse workspace
Connecting an Azure Data Explorer database to a workspace is done through a linked service. With an Azure Data Explorer linked service, you can browse and explore data, read, and write from Apache Spark for Azure Synapse. You can also run integration jobs in a pipeline.
From the Data Object Explorer, follow these steps to directly connect an Azure Data Explorer cluster:
Select the + icon near Data.
Select Connect to connect to external data.
Select Azure Data Explorer (Kusto).
Select Continue.
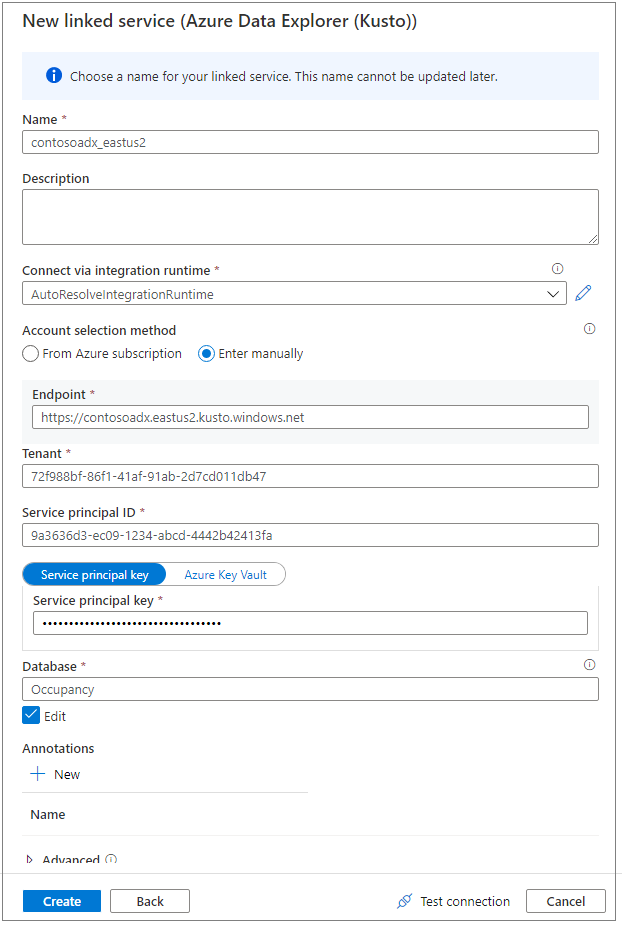
Use a friendly name to name the linked service. The name will appear in the Data Object Explorer and is used by Azure Synapse runtimes to connect to the database.
Select the Azure Data Explorer cluster from your subscription, or enter the URI.
Enter the Service principal ID and Service principal key. Ensure this service principal has view access on the database for read operation and ingestor access for ingesting data.
Enter the Azure Data Explorer database name.
Select Test connection to ensure you have the right permissions.
Select Create.
Note
(Optional) Test connection doesn't validate write access. Ensure your service principal ID has write access to the Azure Data Explorer database.
Azure Data Explorer clusters and databases appear on the Linked tab under the Azure Data Explorer section.

Before you can interact with the linked service from a notebook, it must be published to the Workspace. Click Publish in the toolbar, review the pending changes and click OK.
Note
In the current release, the database objects are populated based on your Microsoft Entra account permissions on the Azure Data Explorer databases. When you run the Apache Spark notebooks or integration jobs, the credential in the link service will be used (for example, service principal).
Quickly interact with code-generated actions
When you right-click a database or table, a list of sample Spark notebooks appears. Select an option to read, write, or stream data to Azure Data Explorer.

Here's an example of reading data. Attach the notebook to your Spark pool, and run the cell.

Note
First-time execution might take more than three minutes to initiate the Spark session. Subsequent executions will be significantly faster.
Limitations
The Azure Data Explorer connector is currently not supported with Azure Synapse managed virtual networks.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for