Plan your Azure Time Series Insights Gen1 environment
Note
The Time Series Insights (TSI) service will no longer be supported after March 2025. Consider migrating existing TSI environments to alternative solutions as soon as possible. For more information on the deprecation and migration, visit our documentation.
Caution
This is a Gen1 article.
This article describes how to plan your Azure Time Series Insights Gen1 environment based on your expected ingress rate and your data retention requirements.
Video
Watch this video to learn more about data retention in Azure Time Series Insights and how to plan for it:
Best practices
To get started with Azure Time Series Insights, it's best if you know how much data you expect to push by the minute and how long you need to store your data.
For more information about capacity and retention for both Azure Time Series Insights SKUs, read Azure Time Series Insights pricing.
To best plan your Azure Time Series Insights environment for long-term success, consider the following attributes:
- Storage capacity
- Data retention period
- Ingress capacity
- Shaping your events
- Ensuring that you have reference data in place
Storage capacity
By default, Azure Time Series Insights retains data based on the amount of storage you provision (units × the amount of storage per unit) and ingress.
Data retention
You can change the Data retention time setting in your Azure Time Series Insights environment. You can enable up to 400 days of retention.
Azure Time Series Insights has two modes:
- One mode optimizes for the most up-to-date data. It enforces a policy to Purge old data leaving recent data available with the instance. This mode is on, by default.
- The other optimizes data to remain below the configured retention limits. Pause ingress prevents new data from being ingressed when it's selected as the Storage limit exceeded behavior.
You can adjust retention and toggle between the two modes on the environment's configuration page in the Azure portal.
Important
You can configure a maximum of 400 days of data retention in your Azure Time Series Insights Gen1 environment.
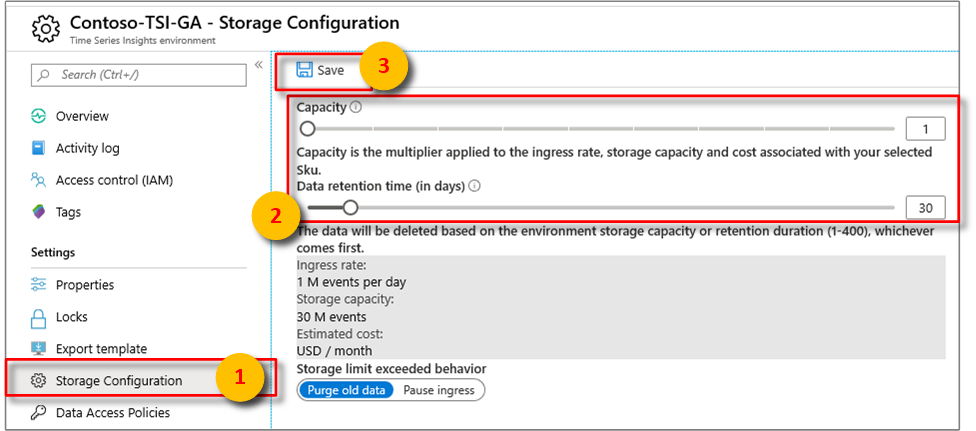
Configure data retention
In the Azure portal, select your Time Series Insights environment.
In the Time Series Insights environment pane, under Settings, select Storage configuration.
In the Data retention time (in days) box, enter a value between 1 and 400.

Tip
To learn more about how to implement an appropriate data retention policy, read How to configure retention.
Ingress capacity
The following summarizes key limits in Azure Time Series Insights Gen1.
SKU ingress rates and capacities
S1 and S2 SKU ingress rates and capacities provide flexibility when configuring a new Azure Time Series Insights environment. Your SKU capacity indicates your daily ingress rate based on number of events or bytes stored, whichever comes first. Note that ingress is measured per minute, and throttling is applied using the token bucket algorithm. Ingress is measured in 1-KB blocks. For example a 0.8-KB actual event would be measured as one event, and a 2.6-KB event is counted as three events.
| S1 SKU capacity | Ingress rate | Maximum storage capacity |
|---|---|---|
| 1 | 1 GB (1 million events) per day | 30 GB (30 million events) |
| 10 | 10 GB (10 million events) per day | 300 GB (300 million events) |
| S2 SKU capacity | Ingress rate | Maximum storage capacity |
|---|---|---|
| 1 | 10 GB (10 million events) per day | 300 GB (300 million events) |
| 10 | 100 GB (100 million events) per day | 3 TB (3 billion events) |
Note
Capacities scale linearly, so an S1 SKU with capacity 2 supports 2 GB (2 million) events per day ingress rate and 60 GB (60 million events) per month.
S2 SKU environments support substantially more events per month and have a significantly higher ingress capacity.
| SKU | Event count per month | Event count per minute | Event size per minute |
|---|---|---|---|
| S1 | 30 million | 720 | 720 KB |
| S2 | 300 million | 7,200 | 7,200 KB |
Property limits
Gen1 property limits depend on the SKU environment that's selected. Supplied event properties have corresponding JSON, CSV, and chart columns that can viewed within the Azure Time Series Insights Explorer.
| SKU | Maximum properties |
|---|---|
| S1 | 600 properties (columns) |
| S2 | 800 properties (columns) |
Event sources
A maximum of two event sources per instance is supported.
- Learn how to Add an event hub source.
- Configure an IoT hub source.
API limits
REST API limits for Azure Time Series Insights Gen1 are specified in the REST API reference documentation.
Environment planning
The second area to focus on for planning your Azure Time Series Insights environment is ingress capacity. The daily ingress storage and event capacity is measured per minute, in 1-KB blocks. The maximum allowed packet size is 32 KB. Data packets larger than 32 KB are truncated.
You can increase the capacity of an S1 or S2 SKU to 10 units in a single environment. You can't migrate from an S1 environment to an S2. You can't migrate from an S2 environment to an S1.
For ingress capacity, first determine the total ingress you require on a per-month basis. Next, determine what your per-minute needs are.
Throttling and latency play a role in per-minute capacity. If you have a spike in your data ingress that lasts less than 24 hours, Azure Time Series Insights can "catch up" at an ingress rate of two times the rates listed in the preceding table.
For example, if you have a single S1 SKU, you ingress data at a rate of 720 events per minute, and the data rate spikes for less than one hour at a rate of 1,440 events or less, there's no noticeable latency in your environment. However, if you exceed 1,440 events per minute for more than one hour, you likely will experience latency in data that is visualized and available for query in your environment.
You might not know in advance how much data you expect to push. In this case, you can find data telemetry for Azure IoT Hub and Azure Event Hubs in your Azure portal subscription. The telemetry can help you determine how to provision your environment. Use the Metrics pane in the Azure portal for the respective event source to view its telemetry. If you understand your event source metrics, you can more effectively plan and provision your Azure Time Series Insights environment.
Calculate ingress requirements
To calculate your ingress requirements:
Verify that your ingress capacity is above your average per-minute rate and that your environment is large enough to handle your anticipated ingress equivalent to two times your capacity for less than one hour.
If ingress spikes occur that last for longer than 1 hour, use the spike rate as your average. Provision an environment with the capacity to handle the spike rate.
Mitigate throttling and latency
For information about how to prevent throttling and latency, read Mitigate latency and throttling.
Shape your events
It's important to ensure that the way you send events to Azure Time Series Insights supports the size of the environment you are provisioning. (Conversely, you can map the size of the environment to how many events Azure Time Series Insights reads and the size of each event.) It's also important to think about the attributes that you might want to use to slice and filter by when you query your data.
Tip
Review the JSON shaping documentation in Sending events.
Ensure that you have reference data
A reference dataset is a collection of items that augment the events from your event source. The Azure Time Series Insights ingress engine joins each event from your event source with the corresponding data row in your reference dataset. The augmented event is then available for query. The join is based on the Primary Key columns that are defined in your reference dataset.
Note
Reference data isn't joined retroactively. Only current and future ingress data is matched and joined to the reference dataset after it's configured and uploaded. If you plan to send a large amount of historical data to Azure Time Series Insights and don't first upload or create reference data in Azure Time Series Insights, you might have to redo your work (hint: not fun).
To learn more about how to create, upload, and manage your reference data in Azure Time Series Insights, read our Reference dataset documentation.
Business disaster recovery
This section describes features of Azure Time Series Insights that keep apps and services running, even if a disaster occurs (known as business disaster recovery).
High availability
As an Azure service, Azure Time Series Insights provides certain high availability features by using redundancies at the Azure region level. For example, Azure supports disaster recovery capabilities through Azure's cross-region availability feature.
Additional high-availability features provided through Azure (and also available to any Azure Time Series Insights instance) include:
- Failover: Azure provides geo-replication and load balancing.
- Data restoration and storage recovery: Azure provides several options to preserve and recover data.
- Azure Site Recovery: Azure provides recovery features through Azure Site Recovery.
- Azure Backup: Azure Backup supports both on-premises and in-cloud backup of Azure VMs.
Make sure you enable the relevant Azure features to provide global, cross-region high availability for your devices and users.
Note
If Azure is configured to enable cross-region availability, no additional cross-region availability configuration is required in Azure Time Series Insights.
IoT and event hubs
Some Azure IoT services also include built-in business disaster recovery features:
- Azure IoT Hub high-availability disaster recovery, which includes intra-region redundancy
- Azure Event Hubs policies
- Azure Storage redundancy
Integrating Azure Time Series Insights with the other services provides additional disaster recovery opportunities. For example, telemetry sent to your event hub might be persisted to a backup Azure Blob storage database.
Azure Time Series Insights
There are several ways to keep your Azure Time Series Insights data, apps, and services running, even if they're disrupted.
However, you might determine that a complete backup copy of your Azure Time Series environment also is required, for the following purposes:
- As a failover instance specifically for Azure Time Series Insights to redirect data and traffic to
- To preserve data and auditing information
In general, the best way to duplicate an Azure Time Series Insights environment is to create a second Azure Time Series Insights environment in a backup Azure region. Events are also sent to this secondary environment from your primary event source. Make sure that you use a second dedicated consumer group. Follow that source's business disaster recovery guidelines, as described earlier.
To create a duplicate environment:
- Create an environment in a second region. For more information, read Create a new Azure Time Series Insights environment in the Azure portal.
- Create a second dedicated consumer group for your event source.
- Connect that event source to the new environment. Make sure that you designate the second dedicated consumer group.
- Review the Azure Time Series Insights IoT Hub and Event Hubs documentation.
If an event occurs:
- If your primary region is affected during a disaster incident, reroute operations to the backup Azure Time Series Insights environment.
- Because hub sequence numbers restart from 0 after the failover, recreate the event source in both regions/environments with different consumer groups to avoid creating what would look like duplicate events.
- Delete the primary event source, which is now inactive, to free up an available event source for your environment. (There's a limit of two active event sources per environment.)
- Use your second region to back up and recover all Azure Time Series Insights telemetry and query data.
Important
If a failover occurs:
- A delay might also occur.
- A momentary spike in message processing might occur, as operations are rerouted.
For more information, read Mitigate latency in Azure Time Series Insights.
Next steps
Get started by creating a new Azure Time Series Insights environment in the Azure portal.
Learn how to add an Event Hubs event source to Azure Time Series Insights.
Read about how to configure an IoT Hub event source.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for