Working with Data in ASP.NET Core Apps
Tip
This content is an excerpt from the eBook, Architect Modern Web Applications with ASP.NET Core and Azure, available on .NET Docs or as a free downloadable PDF that can be read offline.

"Data is a precious thing and will last longer than the systems themselves."
Tim Berners-Lee
Data access is an important part of almost any software application. ASP.NET Core supports various data access options, including Entity Framework Core (and Entity Framework 6 as well), and can work with any .NET data access framework. The choice of which data access framework to use depends on the application's needs. Abstracting these choices from the ApplicationCore and UI projects, and encapsulating implementation details in Infrastructure, helps to produce loosely coupled, testable software.
Entity Framework Core (for relational databases)
If you're writing a new ASP.NET Core application that needs to work with relational data, then Entity Framework Core (EF Core) is the recommended way for your application to access its data. EF Core is an object-relational mapper (O/RM) that enables .NET developers to persist objects to and from a data source. It eliminates the need for most of the data access code developers would typically need to write. Like ASP.NET Core, EF Core has been rewritten from the ground up to support modular cross-platform applications. You add it to your application as a NuGet package, configure it during app startup, and request it through dependency injection wherever you need it.
To use EF Core with a SQL Server database, run the following dotnet CLI command:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
To add support for an InMemory data source, for testing:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
The DbContext
To work with EF Core, you need a subclass of DbContext. This class holds properties representing collections of the entities your application will work with. The eShopOnWeb sample includes a CatalogContext with collections for items, brands, and types:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
Your DbContext must have a constructor that accepts DbContextOptions and pass this argument to the base DbContext constructor. If you have only one DbContext in your application, you can pass an instance of DbContextOptions, but if you have more than one you must use the generic DbContextOptions<T> type, passing in your DbContext type as the generic parameter.
Configuring EF Core
In your ASP.NET Core application, you'll typically configure EF Core in Program.cs with your application's other dependencies. EF Core uses a DbContextOptionsBuilder, which supports several helpful extension methods to streamline its configuration. To configure CatalogContext to use a SQL Server database with a connection string defined in Configuration, you would add the following code:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
To use the in-memory database:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Once you have installed EF Core, created a DbContext child type, and added the type to the application's services, you are ready to use EF Core. You can request an instance of your DbContext type in any service that needs it and start working with your persisted entities using LINQ as if they were simply in a collection. EF Core does the work of translating your LINQ expressions into SQL queries to store and retrieve your data.
You can see the queries EF Core is executing by configuring a logger and ensuring its level is set to at least Information, as shown in Figure 8-1.
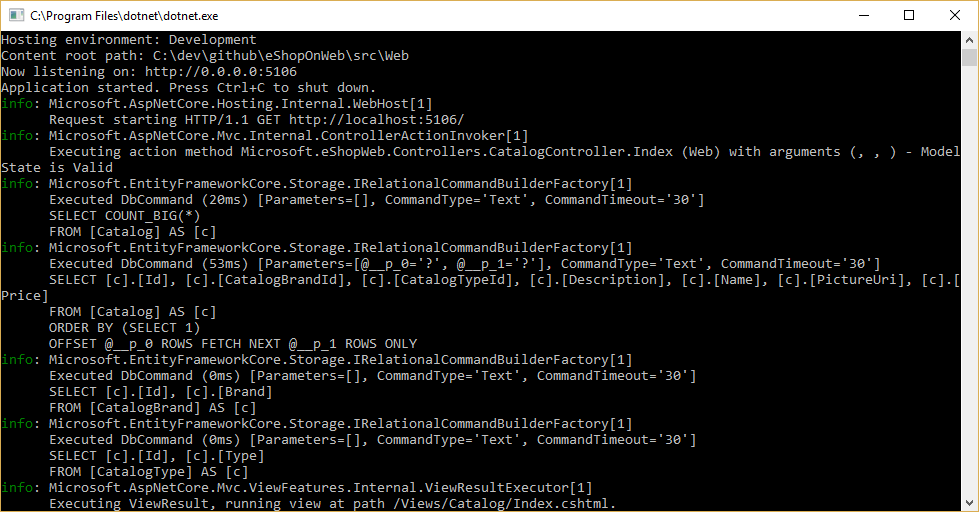
Figure 8-1. Logging EF Core queries to the console
Fetching and storing Data
To retrieve data from EF Core, you access the appropriate property and use LINQ to filter the result. You can also use LINQ to perform projection, transforming the result from one type to another. The following example would retrieve CatalogBrands, ordered by name, filtered by their Enabled property, and projected onto a SelectListItem type:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
It's important in the above example to add the call to ToListAsync in order to execute the query immediately. Otherwise, the statement will assign an IQueryable<SelectListItem> to brandItems, which will not be executed until it is enumerated. There are pros and cons to returning IQueryable results from methods. It allows the query EF Core will construct to be further modified, but can also result in errors that only occur at run time, if operations are added to the query that EF Core cannot translate. It's generally safer to pass any filters into the method performing the data access, and return back an in-memory collection (for example, List<T>) as the result.
EF Core tracks changes on entities it fetches from persistence. To save changes to a tracked entity, you just call the SaveChangesAsync method on the DbContext, making sure it's the same DbContext instance that was used to fetch the entity. Adding and removing entities is directly done on the appropriate DbSet property, again with a call to SaveChangesAsync to execute the database commands. The following example demonstrates adding, updating, and removing entities from persistence.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core supports both synchronous and async methods for fetching and saving. In web applications, it's recommended to use the async/await pattern with the async methods, so that web server threads are not blocked while waiting for data access operations to complete.
For more information, see Buffering and Streaming.
Fetching related data
When EF Core retrieves entities, it populates all of the properties that are stored directly with that entity in the database. Navigation properties, such as lists of related entities, are not populated and may have their value set to null. This process ensures EF Core is not fetching more data than is needed, which is especially important for web applications, which must quickly process requests and return responses in an efficient manner. To include relationships with an entity using eager loading, you specify the property using the Include extension method on the query, as shown:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
You can include multiple relationships, and you can also include subrelationships using ThenInclude. EF Core will execute a single query to retrieve the resulting set of entities. Alternately you can include navigation properties of navigation properties by passing a '.'-separated string to the .Include() extension method, like so:
.Include("Items.Products")
In addition to encapsulating filtering logic, a specification can specify the shape of the data to be returned, including which properties to populate. The eShopOnWeb sample includes several specifications that demonstrate encapsulating eager loading information within the specification. You can see how the specification is used as part of a query here:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Another option for loading related data is to use explicit loading. Explicit loading allows you to load additional data into an entity that has already been retrieved. Since this approach involves a separate request to the database, it's not recommended for web applications, which should minimize the number of database round trips made per request.
Lazy loading is a feature that automatically loads related data as it is referenced by the application. EF Core has added support for lazy loading in version 2.1. Lazy loading is not enabled by default and requires installing the Microsoft.EntityFrameworkCore.Proxies. As with explicit loading, lazy loading should typically be disabled for web applications, since its use will result in additional database queries being made within each web request. Unfortunately, the overhead incurred by lazy loading often goes unnoticed at development time, when the latency is small and often the data sets used for testing are small. However, in production, with more users, more data, and more latency, the additional database requests can often result in poor performance for web applications that make heavy use of lazy loading.
Avoid Lazy Loading Entities in Web Applications
It's a good idea to test your application while examining the actual database queries it makes. Under certain circumstances, EF Core may make many more queries or a more expensive query than is optimal for the application. One such problem is known as a Cartesian Explosion. The EF Core team makes available the AsSplitQuery method as one of several ways to tune runtime behavior.
Encapsulating data
EF Core supports several features that allow your model to properly encapsulate its state. A common problem in domain models is that they expose collection navigation properties as publicly accessible list types. This problem allows any collaborator to manipulate the contents of these collection types, which may bypass important business rules related to the collection, possibly leaving the object in an invalid state. The solution to this problem is to expose read-only access to related collections, and explicitly provide methods defining ways in which clients can manipulate them, as in this example:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
This entity type doesn't expose a public List or ICollection property, but instead exposes an IReadOnlyCollection type that wraps the underlying List type. When using this pattern, you can indicate to Entity Framework Core to use the backing field like so:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Another way in which you can improve your domain model is by using value objects for types that lack identity and are only distinguished by their properties. Using such types as properties of your entities can help keep logic specific to the value object where it belongs, and can avoid duplicate logic between multiple entities that use the same concept. In Entity Framework Core, you can persist value objects in the same table as their owning entity by configuring the type as an owned entity, like so:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
In this example, the ShipToAddress property is of type Address. Address is a value object with several properties such as Street and City. EF Core maps the Order object to its table with one column per Address property, prefixing each column name with the name of the property. In this example, the Order table would include columns such as ShipToAddress_Street and ShipToAddress_City. It's also possible to store owned types in separate tables, if desired.
Learn more about owned entity support in EF Core.
Resilient connections
External resources like SQL databases may occasionally be unavailable. In cases of temporary unavailability, applications can use retry logic to avoid raising an exception. This technique is commonly referred to as connection resiliency. You can implement your own retry with exponential backoff technique by attempting to retry with an exponentially increasing wait time, until a maximum retry count has been reached. This technique embraces the fact that cloud resources might intermittently be unavailable for short periods of time, resulting in the failure of some requests.
For Azure SQL DB, Entity Framework Core already provides internal database connection resiliency and retry logic. But you need to enable the Entity Framework execution strategy for each DbContext connection if you want to have resilient EF Core connections.
For instance, the following code at the EF Core connection level enables resilient SQL connections that are retried if the connection fails.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Execution strategies and explicit transactions using BeginTransaction and multiple DbContexts
When retries are enabled in EF Core connections, each operation you perform using EF Core becomes its own retryable operation. Each query and each call to SaveChangesAsync will be retried as a unit if a transient failure occurs.
However, if your code initiates a transaction using BeginTransaction, you are defining your own group of operations that need to be treated as a unit; everything inside the transaction has to be rolled back if a failure occurs. You will see an exception like the following if you attempt to execute that transaction when using an EF execution strategy (retry policy) and you include several SaveChangesAsync from multiple DbContexts in it.
System.InvalidOperationException: The configured execution strategy SqlServerRetryingExecutionStrategy does not support user initiated transactions. Use the execution strategy returned by DbContext.Database.CreateExecutionStrategy() to execute all the operations in the transaction as a retryable unit.
The solution is to manually invoke the EF execution strategy with a delegate representing everything that needs to be executed. If a transient failure occurs, the execution strategy will invoke the delegate again. The following code shows how to implement this approach:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
The first DbContext is the _catalogContext and the second DbContext is within the _integrationEventLogService object. Finally, the Commit action would be performed multiple DbContexts and using an EF Execution Strategy.
References – Entity Framework Core
- EF Core Docs https://learn.microsoft.com/ef/
- EF Core: Related Data https://learn.microsoft.com/ef/core/querying/related-data
- Avoid Lazy Loading Entities in ASPNET Applications https://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core or micro-ORM?
While EF Core is a great choice for managing persistence, and for the most part encapsulates database details from application developers, it isn't the only choice. Another popular open-source alternative is Dapper, a so-called micro-ORM. A micro-ORM is a lightweight, less full-featured tool for mapping objects to data structures. In the case of Dapper, its design goals focus on performance, rather than fully encapsulating the underlying queries it uses to retrieve and update data. Because it doesn't abstract SQL from the developer, Dapper is "closer to the metal" and lets developers write the exact queries they want to use for a given data access operation.
EF Core has two significant features it provides which separate it from Dapper but also add to its performance overhead. The first is the translation from LINQ expressions into SQL. These translations are cached, but even so there is overhead in performing them the first time. The second is change tracking on entities (so that efficient update statements can be generated). This behavior can be turned off for specific queries by using the AsNoTracking extension. EF Core also generates SQL queries that usually are very efficient and in any case perfectly acceptable from a performance standpoint, but if you need fine control over the precise query to be executed, you can pass in custom SQL (or execute a stored procedure) using EF Core, too. In this case, Dapper still outperforms EF Core, but only very slightly. Current performance benchmark data for a variety of data access methods can be found on the Dapper site.
To see how the syntax for Dapper varies from EF Core, consider these two versions of the same method for retrieving a list of items:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
If you need to build more complex object graphs with Dapper, you need to write the associated queries yourself (as opposed to adding an Include as you would in EF Core). This functionality is supported through various syntaxes, including a feature called Multi Mapping that lets you map individual rows to multiple mapped objects. For example, given a class Post with a property Owner of type User, the following SQL would return all of the necessary data:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Each returned row includes both User and Post data. Since the User data should be attached to the Post data via its Owner property, the following function is used:
(post, user) => { post.Owner = user; return post; }
The full code listing to return a collection of posts with their Owner property populated with the associated user data would be:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Because it offers less encapsulation, Dapper requires developers know more about how their data is stored, how to query it efficiently, and write more code to fetch it. When the model changes, instead of simply creating a new migration (another EF Core feature), and/or updating mapping information in one place in a DbContext, every query that is impacted must be updated. These queries have no compile-time guarantees, so they may break at run time in response to changes to the model or database, making errors more difficult to detect quickly. In exchange for these tradeoffs, Dapper offers extremely fast performance.
For most applications, and most parts of almost all applications, EF Core offers acceptable performance. Thus, its developer productivity benefits are likely to outweigh its performance overhead. For queries that can benefit from caching, the actual query may only be executed a tiny percentage of the time, making relatively small query performance differences moot.
SQL or NoSQL
Traditionally, relational databases like SQL Server have dominated the marketplace for persistent data storage, but they are not the only solution available. NoSQL databases like MongoDB offer a different approach to storing objects. Rather than mapping objects to tables and rows, another option is to serialize the entire object graph, and store the result. The benefits of this approach, at least initially, are simplicity and performance. It's simpler to store a single serialized object with a key than to decompose the object into many tables with relationships and update rows that may have changed since the object was last retrieved from the database. Likewise, fetching and deserializing a single object from a key-based store is typically much faster and easier than complex joins or multiple database queries required to fully compose the same object from a relational database. The lack of locks or transactions or a fixed schema also makes NoSQL databases amenable to scaling across many machines, supporting very large datasets.
On the other hand, NoSQL databases (as they are typically called) have their drawbacks. Relational databases use normalization to enforce consistency and avoid duplication of data. This approach reduces the total size of the database and ensures that updates to shared data are available immediately throughout the database. In a relational database, an Address table might reference a Country table by ID, such that if the name of a country/region were changed, the address records would benefit from the update without themselves having to be updated. However, in a NoSQL database, Address, and its associated Country might be serialized as part of many stored objects. An update to a country/region name would require all such objects to be updated, rather than a single row. Relational databases can also ensure relational integrity by enforcing rules like foreign keys. NoSQL databases typically do not offer such constraints on their data.
Another complexity NoSQL databases must deal with is versioning. When an object's properties change, it may not be able to be deserialized from past versions that were stored. Thus, all existing objects that have a serialized (previous) version of the object must be updated to conform to its new schema. This approach is not conceptually different from a relational database, where schema changes sometimes require update scripts or mapping updates. However, the number of entries that must be modified is often much greater in the NoSQL approach, because there is more duplication of data.
It's possible in NoSQL databases to store multiple versions of objects, something fixed schema relational databases typically do not support. However, in this case, your application code will need to account for the existence of previous versions of objects, adding additional complexity.
NoSQL databases typically do not enforce ACID, which means they have both performance and scalability benefits over relational databases. They're well suited to extremely large datasets and objects that are not well suited to storage in normalized table structures. There is no reason why a single application cannot take advantage of both relational and NoSQL databases, using each where it is best suited.
Azure Cosmos DB
Azure Cosmos DB is a fully managed NoSQL database service that offers cloud-based schema-free data storage. Azure Cosmos DB is built for fast and predictable performance, high availability, elastic scaling, and global distribution. Despite being a NoSQL database, developers can use rich and familiar SQL query capabilities on JSON data. All resources in Azure Cosmos DB are stored as JSON documents. Resources are managed as items, which are documents containing metadata, and feeds, which are collections of items. Figure 8-2 shows the relationship between different Azure Cosmos DB resources.
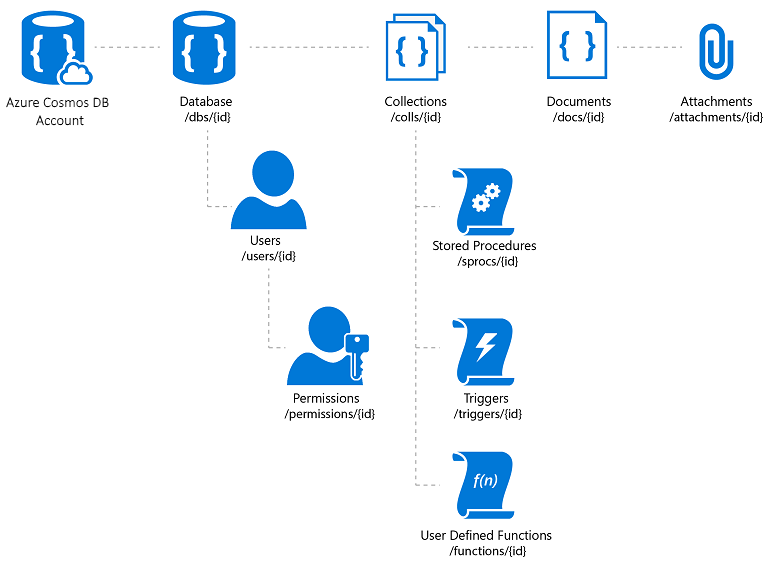
Figure 8-2. Azure Cosmos DB resource organization.
The Azure Cosmos DB query language is a simple yet powerful interface for querying JSON documents. The language supports a subset of ANSI SQL grammar and adds deep integration of JavaScript object, arrays, object construction, and function invocation.
References – Azure Cosmos DB
- Azure Cosmos DB Introduction https://learn.microsoft.com/azure/cosmos-db/introduction
Other persistence options
In addition to relational and NoSQL storage options, ASP.NET Core applications can use Azure Storage to store various data formats and files in a cloud-based, scalable fashion. Azure Storage is massively scalable, so you can start out storing small amounts of data and scale up to storing hundreds or terabytes if your application requires it. Azure Storage supports four kinds of data:
Blob Storage for unstructured text or binary storage, also referred to as object storage.
Table Storage for structured datasets, accessible via row keys.
Queue Storage for reliable queue-based messaging.
File Storage for shared file access between Azure virtual machines and on-premises applications.
References – Azure Storage
- Azure Storage Introduction https://learn.microsoft.com/azure/storage/common/storage-introduction
Caching
In web applications, each web request should be completed in the shortest time possible. One way to achieve this functionality is to limit the number of external calls the server must make to complete the request. Caching involves storing a copy of data on the server (or another data store that is more easily queried than the source of the data). Web applications, and especially non-SPA traditional web applications, need to build the entire user interface with every request. This approach frequently involves making many of the same database queries repeatedly from one user request to the next. In most cases, this data changes rarely, so there is little reason to constantly request it from the database. ASP.NET Core supports response caching, for caching entire pages, and data caching, which supports more granular caching behavior.
When implementing caching, it's important to keep in mind separation of concerns. Avoid implementing caching logic in your data access logic, or in your user interface. Instead, encapsulate caching in its own classes, and use configuration to manage its behavior. This approach follows the Open/Closed and Single Responsibility principles, and will make it easier for you to manage how you use caching in your application as it grows.
ASP.NET Core response caching
ASP.NET Core supports two levels of response caching. The first level does not cache anything on the server, but adds HTTP headers that instruct clients and proxy servers to cache responses. This functionality is implemented by adding the ResponseCache attribute to individual controllers or actions:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
The previous example will result in the following header being added to the response, instructing clients to cache the result for up to 60 seconds.
Cache-Control: public,max-age=60
In order to add server-side in-memory caching to the application, you must reference the Microsoft.AspNetCore.ResponseCaching NuGet package, and then add the Response Caching middleware. This middleware is configured with services and middleware during app startup:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
The Response Caching Middleware will automatically cache responses based on a set of conditions, which you can customize. By default, only 200 (OK) responses requested via GET or HEAD methods are cached. In addition, requests must have a response with a Cache-Control: public header, and cannot include headers for Authorization or Set-Cookie. See a complete list of the caching conditions used by the response caching middleware.
Data caching
Rather than (or in addition to) caching full web responses, you can cache the results of individual data queries. For this functionality, you can use in memory caching on the web server, or use a distributed cache. This section will demonstrate how to implement in memory caching.
Add support for memory (or distributed) caching with the following code:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Be sure to add the Microsoft.Extensions.Caching.Memory NuGet package as well.
Once you've added the service, you request IMemoryCache via dependency injection wherever you need to access the cache. In this example, the CachedCatalogService is using the Proxy (or Decorator) design pattern, by providing an alternative implementation of ICatalogService that controls access to (or adds behavior to) the underlying CatalogService implementation.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
To configure the application to use the cached version of the service, but still allow the service to get the instance of CatalogService it needs in its constructor, you would add the following lines in Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
With this code in place, the database calls to fetch the catalog data will only be made once per minute, rather than on every request. Depending on the traffic to the site, this can have a significant impact on the number of queries made to the database, and the average page load time for the home page that currently depends on all three of the queries exposed by this service.
An issue that arises when caching is implemented is stale data – that is, data that has changed at the source but an out-of-date version remains in the cache. A simple way to mitigate this issue is to use small cache durations, since for a busy application there is a limited additional benefit to extending the length data is cached. For example, consider a page that makes a single database query, and is requested 10 times per second. If this page is cached for one minute, it will result in the number of database queries made per minute to drop from 600 to 1, a reduction of 99.8%. If instead the cache duration was made one hour, the overall reduction would be 99.997%, but now the likelihood and potential age of stale data are both increased dramatically.
Another approach is to proactively remove cache entries when the data they contain is updated. Any individual entry can be removed if its key is known:
_cache.Remove(cacheKey);
If your application exposes functionality for updating entries that it caches, you can remove the corresponding cache entries in your code that performs the updates. Sometimes there may be many different entries that depend on a particular set of data. In that case, it can be useful to create dependencies between cache entries, by using a CancellationChangeToken. With a CancellationChangeToken, you can expire multiple cache entries at once by canceling the token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Caching can dramatically improve the performance of web pages that repeatedly request the same values from the database. Be sure to measure data access and page performance before applying caching, and only apply caching where you see a need for improvement. Caching consumes web server memory resources and increases the complexity of the application, so it's important you don't prematurely optimize using this technique.
Getting data to Blazor WebAssembly apps
If you're building apps that use Blazor Server, you can use Entity Framework and other direct data access technologies as they've been discussed thus far in this chapter. However, when building Blazor WebAssembly apps, like other SPA frameworks, you will need a different strategy for data access. Typically, these applications access data and interact with the server through web API endpoints.
If the data or operations being performed are sensitive, be sure to review the section on security in the previous chapter and protect your APIs against unauthorized access.
You'll find an example of a Blazor WebAssembly app in the eShopOnWeb reference application, in the BlazorAdmin project. This project is hosted within the eShopOnWeb Web project, and allows users in the Administrators group to manage the items in the store. You can see a screenshot of the application in Figure 8-3.
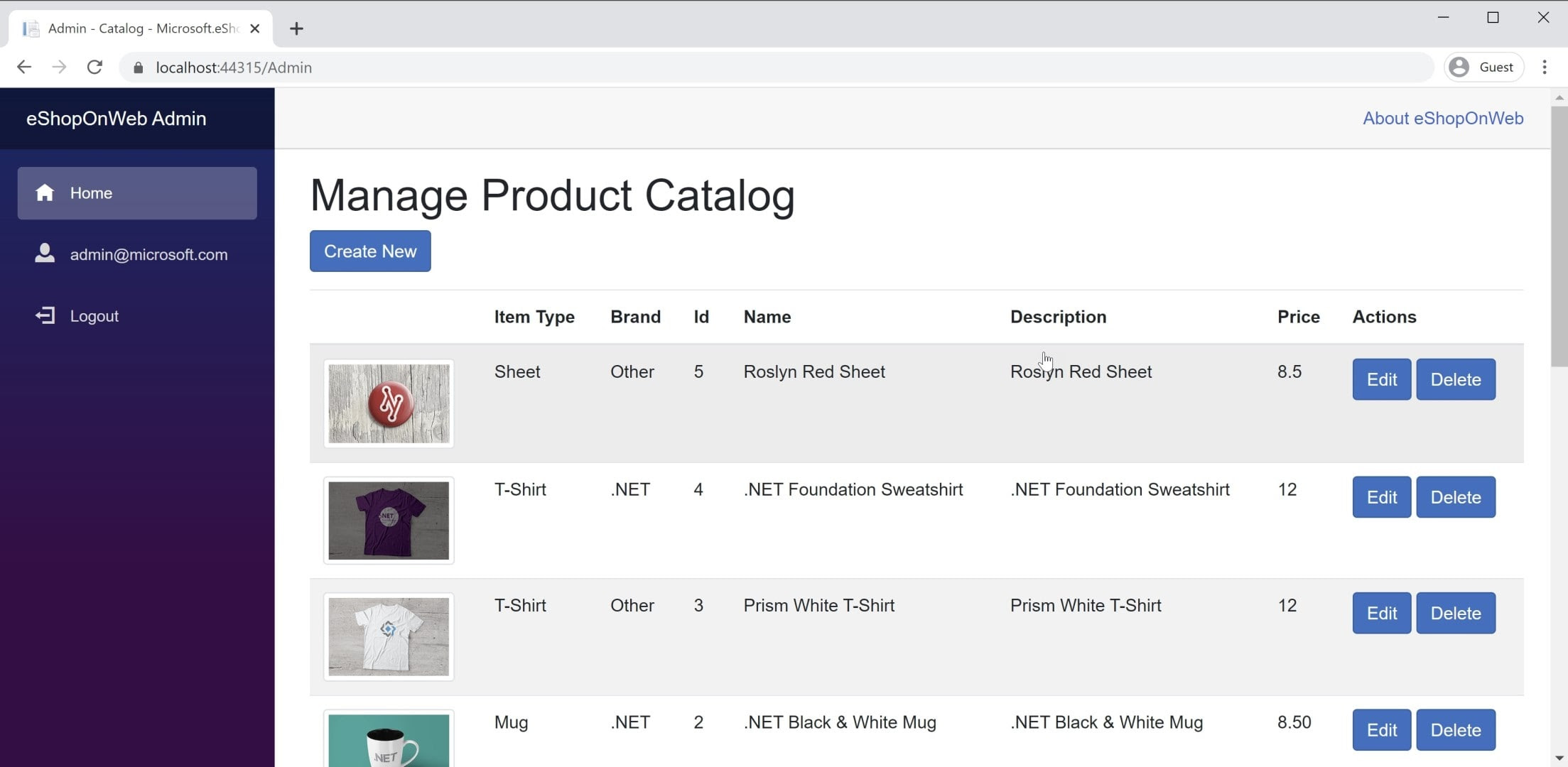
Figure 8-3. eShopOnWeb Catalog Admin Screenshot.
When fetching data from web APIs within a Blazor WebAssembly app, you just use an instance of HttpClient as you would in any .NET application. The basic steps involved are to create the request to send (if necessary, usually for POST or PUT requests), await the request itself, verify the status code, and deserialize the response. If you're going to make many requests to a given set of APIs, it's a good idea to encapsulate your APIs and configure the HttpClient base address centrally. This way, if you need to adjust any of these settings between environments, you can make the changes in just one place. You should add support for this service in your Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
If you need to access services securely, you should access a secure token and configure the HttpClient to pass this token as an Authentication header with every request:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
This activity can be done from any component that has the HttpClient injected into it, provided that HttpClient wasn't added to the application's services with a Transient lifetime. Every reference to HttpClient in the application references the same instance, so changes to it in one component flow through the entire application. A good place to perform this authentication check (followed by specifying the token) is in a shared component like the main navigation for the site. Learn more about this approach in the BlazorAdmin project in the eShopOnWeb reference application.
One benefit of Blazor WebAssembly over traditional JavaScript SPAs is that you don't need to keep copies of your data transfer objects(DTOs) synchronized. Your Blazor WebAssembly project and your web API project can both share the same DTOs in a common shared project. This approach eliminates some of the friction involved in developing SPAs.
To quickly get data from an API endpoint, you can use the built-in helper method, GetFromJsonAsync. There are similar methods for POST, PUT, etc. The following shows how to get a CatalogItem from an API endpoint using a configured HttpClient in a Blazor WebAssembly app:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Once you have the data you need, you'll typically track changes locally. When you want to make updates to the backend data store, you'll call additional web APIs for this purpose.
References – Blazor Data
- Call a web API from ASP.NET Core Blazor https://learn.microsoft.com/aspnet/core/blazor/call-web-api
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for