Configure a Virtual Machine Scale Set
When you scale, you add instances to your Virtual Machine Scale Set. In the shipping-company scenario, scaling is a good way to handle the changing number of requests over time. Scaling adjusts the number of virtual machines that run the web application as the number of users changes. In this way, the system maintains an even response time, regardless of the current load.
In this unit, you learn how to scale a Virtual Machine Scale Set. You can scale manually by explicitly setting the number of virtual machine instances in the scale set. You can configure autoscaling by defining scale rules that trigger the allocation and deallocation of virtual machines. These scale rules determine when to scale the system by monitoring various performance metrics.
Manually scale Virtual Machine Scale Sets
You scale a Virtual Machine Scale Set manually by increasing or decreasing the instance count. You can do this task programmatically or in the Azure portal.
The following code uses the Azure CLI to change the number of instances in a Virtual Machine Scale Set:
az vmss scale \
--name webServerScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Autoscale Virtual Machine Scale Sets
Manual scaling is useful in some circumstances. But in many situations, autoscaling is better. It lets the system control the number of instances in a scale set.
You can base the autoscale on:
- Schedule: Use this approach if you know that you have an increased workload on a specified date or time period.
- Metrics: Adjust scaling by monitoring performance metrics associated with the scale set. When these metrics exceed a specified threshold, the scale set can automatically start new virtual machine instances. When the metrics indicate that the extra resources are no longer required, the scale set can stop any excess instances.
Define autoscale conditions, rules, and limits
Autoscaling is based on a set of scale conditions, rules, and limits. A scale condition combines time and a set of scale rules. If the current time falls within the period defined in the scale condition, the condition's scale rules are evaluated. The results of this evaluation determine whether to add or remove instances in the scale set. The scale condition also defines the limits of scaling for the maximum and minimum number of instances.
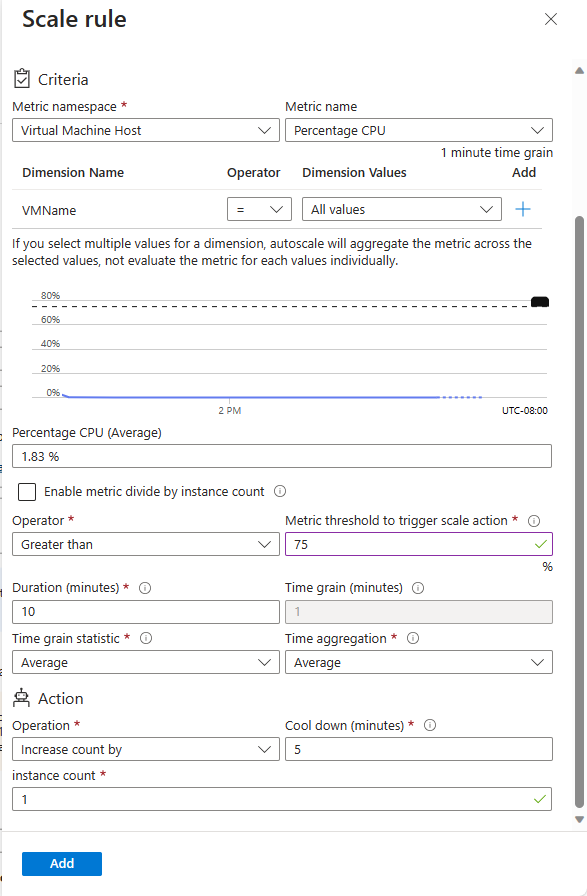
In the shipping-company scenario, you can add scale rules that monitor the CPU usage across the scale set. If the CPU usage exceeds the 75 percent threshold, the scale rule can increase the number of virtual machine instances. A second scale rule can also monitor CPU usage, but reduce the number of virtual machine instances when usage falls below 50 percent. Because the application is global, these rules should be active all the time rather than just at specific hours.
A Virtual Machine Scale Set can contain many scale conditions. Each matching scale condition is acted on. A scale set can also contain a default scale condition to use if no other scale conditions match the current time and performance metrics. The default scale condition is always active. It contains no scale rules, effectively acting like a null scale condition that doesn't scale in or out. However, you can modify the default scale condition to set a default instance count, or you can add a pair of scale rules that scale out and back in again.
Use schedule-based autoscaling
Schedule-based scaling specifies a start and end time and the number of instances to add to the scale set. The following screenshot shows an example in the Azure portal. The number of instances is scaled out to 20 between 6 AM and 6 PM each Monday and Wednesday. Outside of these times, if there are no other scale conditions, the default scale condition is applied.
In this case, the default rule scales the system back down to two instances. This value is the Maximum in this default scale condition.

Use metrics-based autoscaling
A metrics-based scale rule specifies the resources to monitor, such as CPU usage or response time. This scale rule adds or removes instances from the scale set according to the values of these metrics. You can specify limits on the number of instances to prevent a scale set from excessively scaling in or out.
In the example scenario, you want to increase the instance count by one when the average CPU usage exceeds 75 percent. Additionally, you want to limit the scale-out operation to 50 instances. This limit can help to prevent costly runaway scaling caused by an attack. Similarly, you want to scale in when the average CPU usage drops below 50 percent.
These metrics are commonly used to monitor a Virtual Machine Scale Set:
- Percentage CPU: This metric indicates the CPU usage across all instances. A high value shows that instances are becoming CPU-bound, which could delay the processing of client requests.
- Inbound flows and outbound flows: These metrics show how fast network traffic is flowing into and out of virtual machines in the scale set.
- Disks read operations/sec and disk write operations/sec: These metrics show the volume of disk I/O across the scale set.
- Data disk queue depth: This metric shows how many I/O requests to only the data disks on the virtual machines are waiting to be serviced.
A scale rule aggregates the values retrieved for a metric for all instances. It aggregates the values across a period known as the time grain. Each metric has an intrinsic time grain, but usually this period is one minute. The aggregated value is known as the time aggregation. The time-aggregation options are average, minimum, maximum, total, last, and count.
A one-minute interval is too short to determine whether any change in the metric is long-lasting enough to make autoscaling worthwhile. A scale rule takes a second step, further aggregating the time aggregation's value over a longer, user-specified period. This period is called the duration. The minimum duration is five minutes. For example, if the duration is set to 10 minutes, the scale rule aggregates the 10 values calculated for the time grain.
The duration's aggregation calculation can differ from the time grain's aggregation calculation. For example, let's say the time aggregation is average and the statistic gathered is percentage CPU across a one-minute time grain. For every minute, the average CPU percentage usage across all instances during that minute is calculated. If the time-grain statistic is set to maximum and the rule's duration is set to 10 minutes, the maximum of the 10 average values for the CPU usage percentage determines whether the rule threshold has been crossed.
When a scale rule detects that a metric crosses a threshold, it can do a scale action. A scale action can be a scale-out or a scale-in. A scale-out action increases the number of instances. A scale-in action reduces the instance count.
A scale action uses an operator such as less than, greater than, or equal to to determine how to react to the threshold. Scale-out actions typically use the greater than operator to compare the metric value to the threshold. Scale-in actions tend to compare the metric value to the threshold by using the less than operator. A scale action also sets the instance count to a specific level rather than increasing or decreasing the number available.
A scale action has a cool down period, specified in minutes. During this period, the scale rule isn't triggered again. The cool-down allows the system to stabilize between scale events. Starting or shutting down instances takes time, so any metrics gathered might not show significant changes for several minutes. The minimum cool-down period is five minutes.
Finally, you should plan for a scale-in when a workload decreases. Consider defining scale rules in pairs in the same scale condition. One scale rule should indicate how to scale the system out when a metric exceeds an upper threshold. The other rule needs to define how to scale the system back in again when the same metric drops below a lower threshold. Don't make both threshold values the same. Otherwise, you could trigger a series of oscillating events that scale out and back in again.
The following image shows a scale rule defined in the Azure portal.