Cloud challenges: Communication
Even with distributed shared-memory systems, such as DSM, messages are passed internally between machines, albeit in a manner totally transparent to users. Hence, coordination all boils down to passing messages. We can argue, then, that the only way distributed systems can communicate is by passing messages. In fact, Coulouris and associates adopt just this definition for distributed systems.1 Distributed systems, such as the cloud, rely heavily on the underlying network to deliver messages rapidly enough to destination entities for three main reasons: performance, cost, and quality of service (QoS). Specifically, fast message delivery minimizes execution times, reduces costs (because cloud applications can commit earlier), and raises QoS, especially for audio and video applications. This condition makes the issue of communication a principal theme in developing cloud programs. Indeed, some might argue that communication lies at the heart of the cloud and constitutes one of its major bottlenecks.
Distributed programs can apply two techniques to address cloud communication bottlenecks.
Colocation
Distributing/partitioning work across machines attempts to place highly communicating entities together. This strategy can mitigate pressure on the cloud network and subsequently improve performance. Realizing this goal, however, is not as easy as it might seem. For instance, the standard edge-cut strategy seeks to partition graph vertices into p equally weighted partitions over p processors so that the total weight of the edges crossing between partitions is minimized.
Carefully inspecting this strategy, we recognize a serious shortcoming that directly impacts communication. As was previously shown in Figure 10, the minimum cut that resulted from the edge-cut metric overlooks the fact that some edges may represent the same information flow. In particular, $v_{2}$ at $P_{1}$ in the figure sends the same message twice to $P_{2}$ (specifically to $v_{4}$ and $v_{5}$ at $P_{2}$), while it suffices to communicate the message only once because $v_{4}$ and $v_{5}$ will exist on the same machine. Likewise, $v_{4}$ and $v_{7}$ can communicate messages to $P_{1}$ only once, but they do it twice.
The standard edge-cut metric thus overcounts communication volume and consequently leads to superfluous network traffic. As a result, interconnection bandwidth can be potentially stressed and performance degraded. Even if the total communication volume (or the number of messages) is minimized more effectively, load imbalance can generate a bottleneck. In particular, it may happen that, although communication volume is minimized, some machines receive larger partitions (with more vertices) than others. An ideal, yet challenging, approach is to minimize communication overheads while circumventing computation skew among machines. This latter strategy strives for effective partitioning of work across machines so that highly communicating entities are colocated.
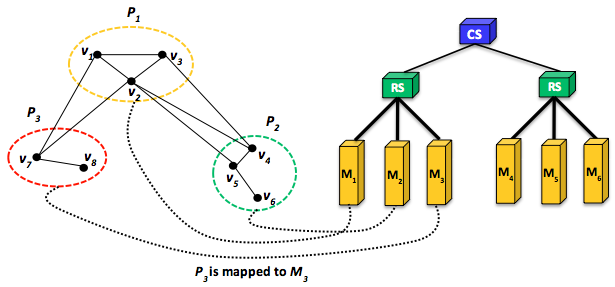
Figure 14: Effective mapping of graph partitions to cluster machines. A mapping of P1 to the other rack while P2 and P3 remain on the same rack causes more network traffic and potentially degraded performance.
Effective partition mapping
To be most effective, the strategy for mapping partitions—whether graph or data partitions—to machines should be totally aware of the underlying network topology. This goal usually requires determining the number of switches a message will hit before reaching its destination. As a specific example, Figure 14 demonstrates the same graph shown in Figure 10 (in an earlier unit) and a simplified cluster with a tree-style network and six machines. The cluster network consists of two rack switches (RSs), each connecting three machines, and a core switch (CS) connecting the two RSs. Note that the bandwidth between any two machines depends on their relative locations in the network topology. For instance, machines on the same rack share a higher-bandwidth connection as opposed to machines that are off rack. Thus, it pays to minimize network traffic across racks. If $P_{1}$, $P_{2}$, and $P_{3}$ are mapped to $M_{1}$, $M_{2}$, and $M_{3}$, respectively, less network latency will be incurred when $P_{1}$, $P_{2}$, and $P_{3}$ communicate versus if they are mapped across the two racks. More precisely, for $P_{1}$ to communicate with $P_{2}$ on the same rack, only one hop is incurred to route a message from $P_{1}$ to $P_{2}$. In contrast, for $P_{1}$ to communicate with $P_{2}$ on different racks, two hops are incurred per each message. Clearly, fewer hops reduce network latency and improve overall performance. Unfortunately, this objective is not as easy to achieve on clouds as it might seem for one main reason: especially on public cloud systems, network topologies remain hidden. Nevertheless, the network topology can still be learned (though not effectively) using a benchmark such as Netperf to measure point-to-point TCP stream bandwidths between all pairs of cluster nodes. This approach enables estimating the relative locality of nodes and arriving at a reasonable inference regarding the cluster's rack topology.
References
- G. Coulouris, J. Dollimore, T. Kindberg, and G. Blair (May 2011). Distributed Systems: Concepts and Design Addison-Wesley
- Netperf
- M. Hammoud, M. S. Rehman, and M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD