AI with dataflows
This article shows how you can use artificial intelligence (AI) with dataflows. This article describes:
- Cognitive Services
- Automated machine learning
- Azure Machine Learning Integration
Cognitive Services in Power BI
With Cognitive Services in Power BI, you can apply different algorithms from Azure Cognitive Services to enrich your data in the self-service data prep for Dataflows.
The services that are supported today are Sentiment Analysis, Key Phrase Extraction, Language Detection, and Image Tagging. The transformations are executed on the Power BI service and don't require an Azure Cognitive Services subscription. This feature requires Power BI Premium.
Enable AI features
Cognitive services are supported for Premium capacity nodes EM2, A2, or P1 and other nodes with more resources. Cognitive services are also available with a Premium Per User (PPU) license. A separate AI workload on the capacity is used to run cognitive services. Before you use cognitive services in Power BI, the AI workload needs to be enabled in the Capacity settings of the Admin portal. You can turn on the AI workload in the workloads section and define the maximum amount of memory you would like this workload to consume. The recommended memory limit is 20%. Exceeding this limit causes the query to slow down.

Get started with Cognitive Services in Power BI
Cognitive Services transforms are part of the Self-Service Data Prep for dataflows. To enrich your data with Cognitive Services, start by editing a dataflow.

Select the AI Insights button in the top ribbon of the Power Query Editor.

In the pop-up window, select the function you want to use and the data you want to transform. This example scores the sentiment of a column that contains review text.

LanguageISOCode is an optional input to specify the language of the text. This column expects an ISO code. You can use a column as input for LanguageISOCode, or you can use a static column. In this example, the language is specified as English (en) for the whole column. If you leave this column blank, Power BI automatically detects the language before applying the function. Next, select Invoke.

After you invoke the function, the result is added as a new column to the table. The transformation is also added as an applied step in the query.

If the function returns multiple output columns, invoking the function adds a new column with a row of the multiple output columns.
Use the expand option to add one or both values as columns to your data.

Available functions
This section describes the available functions in Cognitive Services in Power BI.
Detect Language
The language detection function evaluates text input and, for each column, returns the language name and ISO identifier. This function is useful for data columns that collect arbitrary text, where language is unknown. The function expects data in text format as input.
Text Analytics recognizes up to 120 languages. For more information, see What is language detection in Azure Cognitive Service for Language.
Extract Key Phrases
The Key Phrase Extraction function evaluates unstructured text and, for each text column, returns a list of key phrases. The function requires a text column as input and accepts an optional input for LanguageISOCode. For more information, see the Get Started.
Key phrase extraction works best when you give it bigger chunks of text to work on, opposite from sentiment analysis. Sentiment analysis performs better on smaller blocks of text. To get the best results from both operations, consider restructuring the inputs accordingly.
Score Sentiment
The Score Sentiment function evaluates text input and returns a sentiment score for each document, ranging from 0 (negative) to 1 (positive). This function is useful for detecting positive and negative sentiment in social media, customer reviews, and discussion forums.
Text Analytics uses a machine learning classification algorithm to generate a sentiment score between 0 and 1. Scores closer to 1 indicate positive sentiment. Scores closer to 0 indicate negative sentiment. The model is pre-trained with an extensive body of text with sentiment associations. Currently, it's not possible to provide your own training data. The model uses a combination of techniques during text analysis, including text processing, part-of-speech analysis, word placement, and word associations. For more information about the algorithm, see Machine Learning and Text Analytics.
Sentiment analysis is performed on the entire input column, as opposed to extracting sentiment for a particular table in the text. In practice, there's a tendency for scoring accuracy to improve when documents contain one or two sentences rather than a large block of text. During an objectivity assessment phase, the model determines whether an input column as a whole is objective or contains sentiment. An input column that is mostly objective doesn't progress to the sentiment detection phrase, resulting in a 0.50 score, with no further processing. For input columns continuing in the pipeline, the next phase generates a score greater or less than 0.50, depending on the degree of sentiment detected in the input column.
Currently, Sentiment Analysis supports English, German, Spanish, and French. Other languages are in preview. For more information, see What is language detection in Azure Cognitive Service for Language.
Tag Images
The Tag Images function returns tags based on more than 2,000 recognizable objects, living beings, scenery, and actions. When tags are ambiguous or not common knowledge, the output provides 'hints' to clarify the meaning of the tag in context of a known setting. Tags aren't organized as a taxonomy, and no inheritance hierarchies exist. A collection of content tags forms the foundation for an image 'description' displayed as human readable language formatted in complete sentences.
After uploading an image or specifying an image URL, Computer Vision algorithms output tags based on the objects, living beings, and actions identified in the image. Tagging isn't limited to the main subject, such as a person in the foreground, but also includes the setting (indoor or outdoor), furniture, tools, plants, animals, accessories, gadgets, and so on.
This function requires an image URL or abase-64 column as input. At this time, image tagging supports English, Spanish, Japanese, Portuguese, and Simplified Chinese. For more information, see ComputerVision Interface.
Automated machine learning in Power BI
Automated machine learning (AutoML) for dataflows enables business analysts to train, validate, and invoke machine learning (ML) models directly in Power BI. It includes a simple experience for creating a new ML model where analysts can use their dataflows to specify the input data for training the model. The service automatically extracts the most relevant features, selects an appropriate algorithm, and tunes and validates the ML model. After a model is trained, Power BI automatically generates a performance report that includes the results of the validation. The model can then be invoked on any new or updated data within the dataflow.
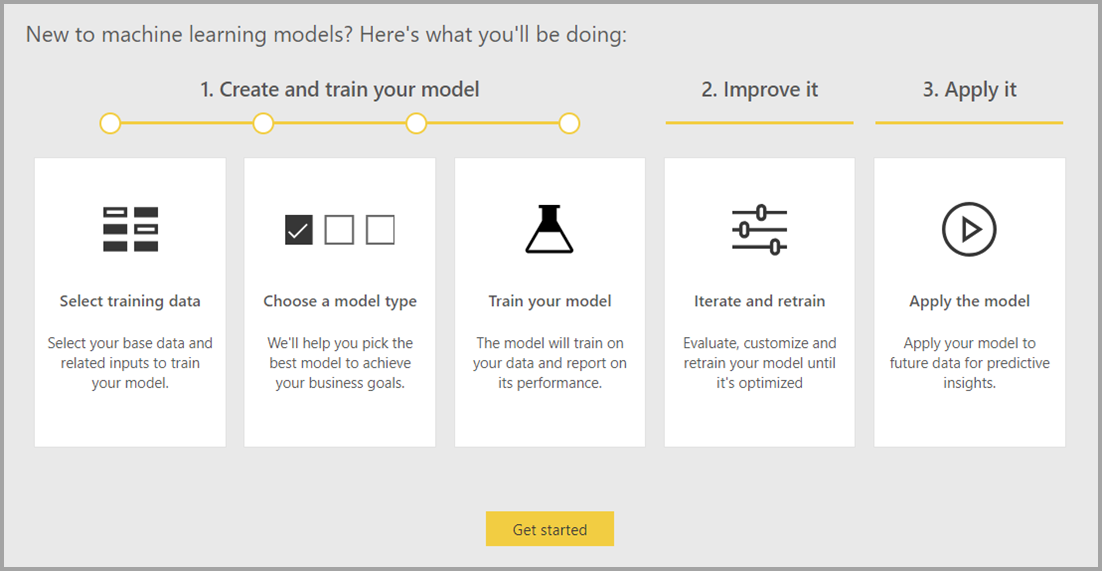
Automated machine learning is available for dataflows that are hosted on Power BI Premium and Embedded capacities only.
Work with AutoML
Machine learning and AI are seeing an unprecedented rise in popularity from industries and scientific research fields. Businesses are also looking for ways to integrate these new technologies into their operations.
Dataflows offer self-serve data prep for big data. AutoML is integrated into dataflows and enables you to use your data prep effort for building machine learning models, right within Power BI.
AutoML in Power BI enables data analysts to use dataflows to build machine learning models with a simplified experience by using just Power BI skills. Power BI automates most of the data science behind the creation of the ML models. It has guardrails to ensure that the model produced has good quality and provides visibility into the process used to create your ML model.
AutoML supports the creation of Binary Prediction, Classification, and Regression Models for dataflows. These features are types of supervised machine learning techniques, which means that they learn from the known outcomes of past observations to predict the outcomes of other observations. The input semantic model for training an AutoML model is a set of rows that are labeled with the known outcomes.
AutoML in Power BI integrates automated ML from Azure Machine Learning to create your ML models. However, you don't need an Azure subscription to use AutoML in Power BI. The Power BI service entirely manages the process of training and hosting the ML models.
After an ML model is trained, AutoML automatically generates a Power BI report that explains the likely performance of your ML model. AutoML emphasizes explainability by highlighting the key influencers among your inputs that influence the predictions returned by your model. The report also includes key metrics for the model.
Other pages of the generated report show the statistical summary of the model and the training details. The statistical summary is of interest to users who would like to see the standard data science measures of model performance. The training details summarize all the iterations that were run to create your model, with the associated modeling parameters. It also describes how each input was used to create the ML model.
You can then apply your ML model to your data for scoring. When the dataflow is refreshed, your data is updated with predictions from your ML model. Power BI also includes an individualized explanation for each specific prediction that the ML model produces.
Create a machine learning model
This section describes how to create an AutoML model.
Data prep for creating an ML model
To create a machine learning model in Power BI, you must first create a dataflow for the data containing the historical outcome information, which is used for training the ML model. You should also add calculated columns for any business metrics that might be strong predictors for the outcome you're trying to predict. For details on configuring your dataflow, see Configure and consume a dataflow.
AutoML has specific data requirements for training a machine learning model. These requirements are described in the following sections, based on respective model types.
Configure the ML model inputs
To create an AutoML model, select the ML icon in the Actions column of the dataflow table, and select Add a machine learning model.
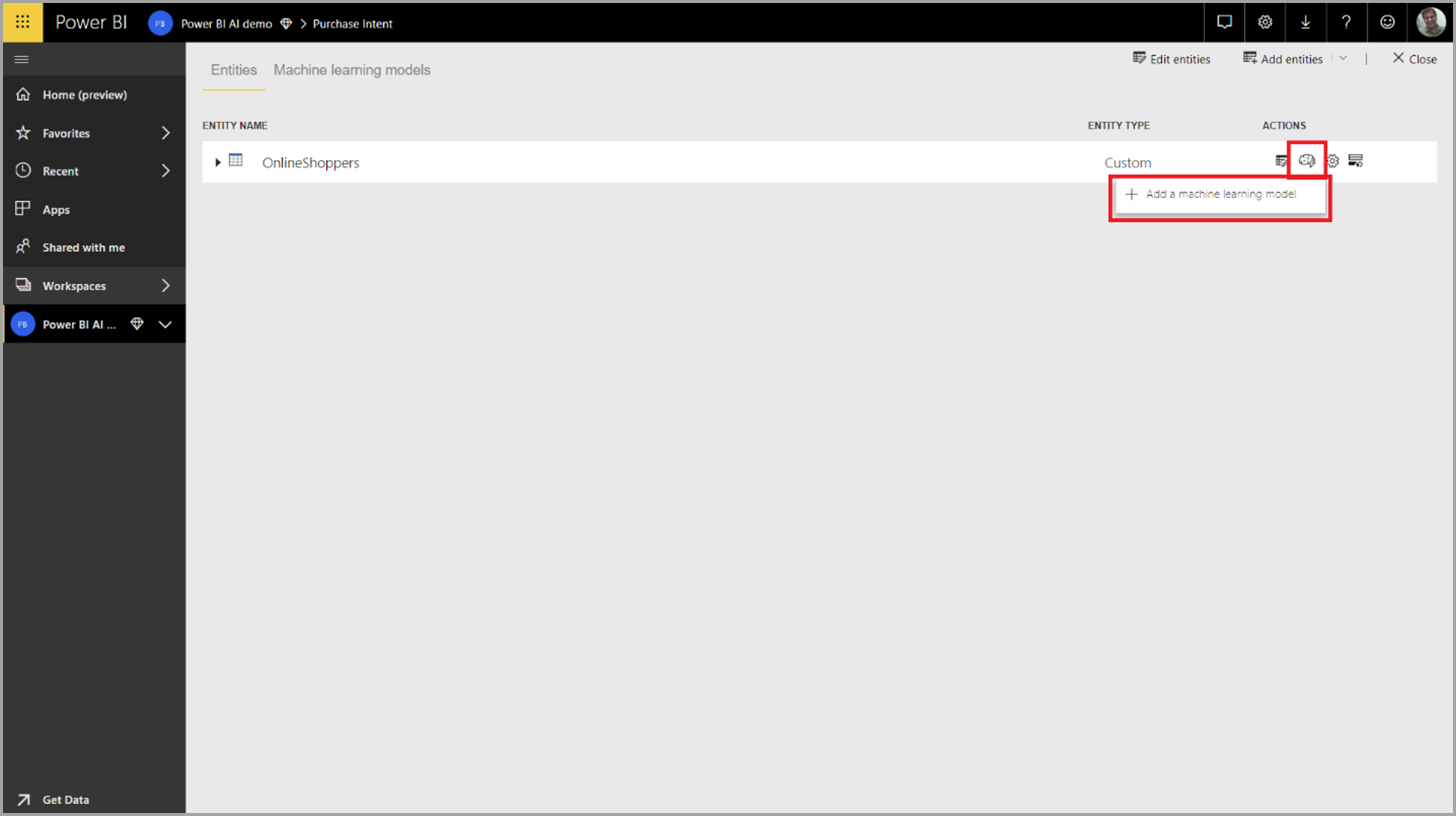
A simplified experience launches, consisting of a wizard that guides you through the process of creating the ML model. The wizard includes the following simple steps.
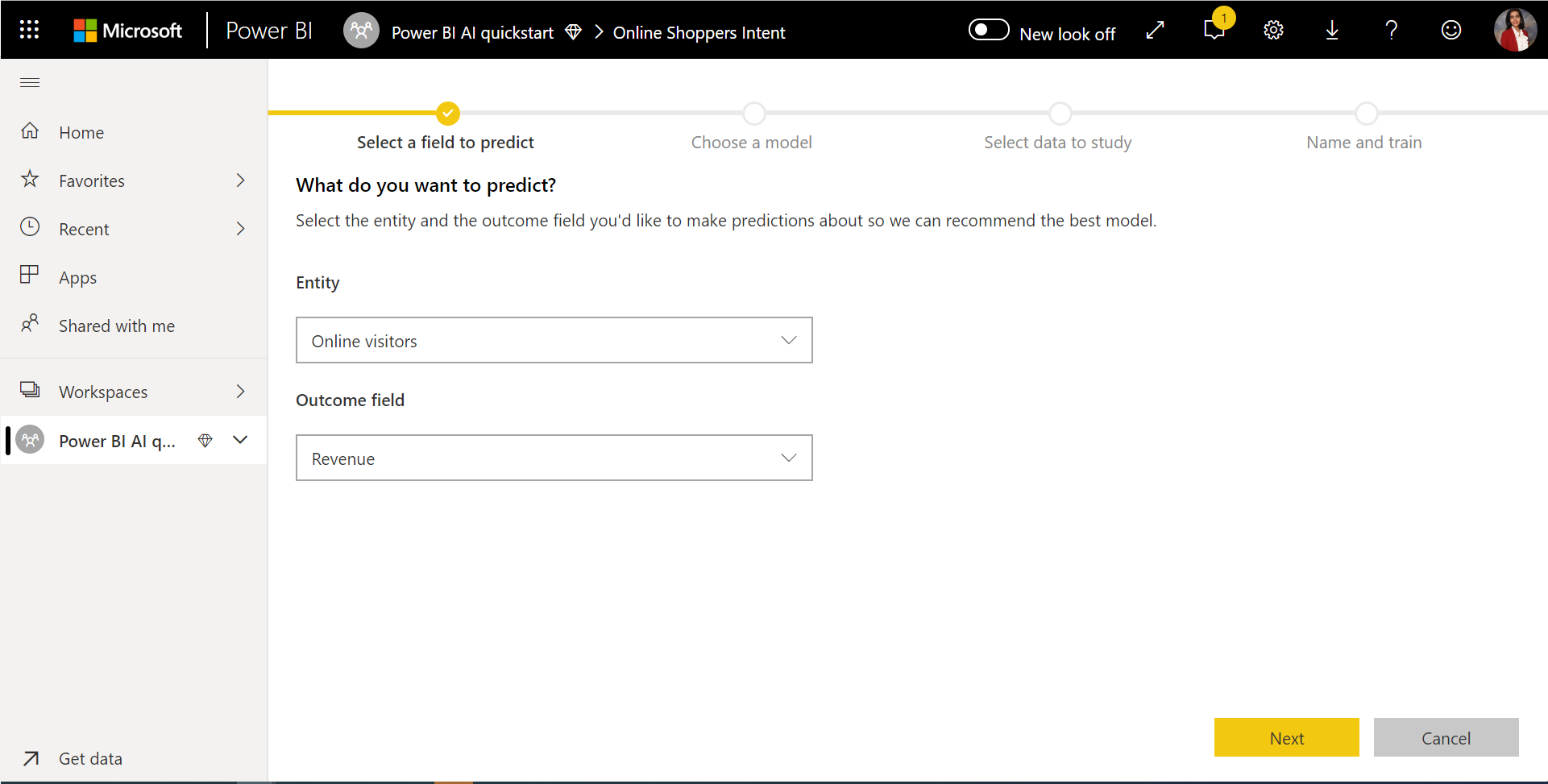
1. Select the table with the historical data, and choose the outcome column for which you want a prediction
The outcome column identifies the label attribute for training the ML model, shown in the following image.
2. Choose a model type
When you specify the outcome column, AutoML analyzes the label data to recommend the most likely ML model type that can be trained. You can pick a different model type as shown in the following image by clicking on Choose a model.
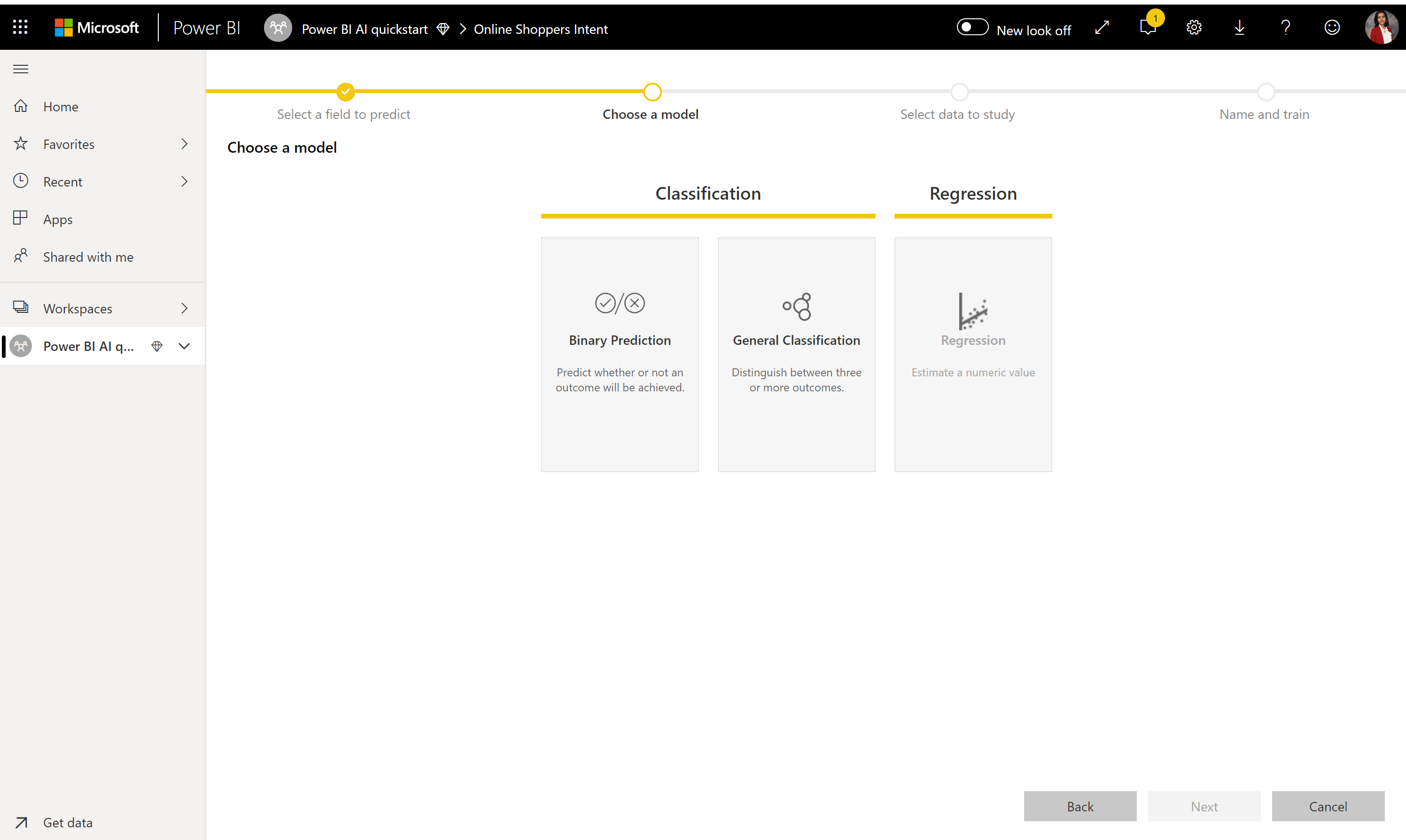
Note
Some model types might not be supported for the data that you have selected, and so, it would be disabled. In the previous example, Regression is disabled, because a text column is selected as outcome column.
3. Select the inputs you want the model to use as predictive signals
AutoML analyzes a sample of the selected table to suggest the inputs that can be used for training the ML model. Explanations are provided next to columns that aren't selected. If a particular column has too many distinct values or only one value, or low or high correlation with the output column, it isn't recommended.
Any inputs that are dependent on the outcome column (or the label column) shouldn't be used for training the ML model, since they affect its performance. Such columns are flagged as having “suspiciously high correlation with output column”. Introducing these columns into the training data causes label leakage, where the model performs well on the validation or test data but can't match that performance when used in production for scoring. Label leakage could be a possible concern in AutoML models when training model performance is too good to be true.
This feature recommendation is based on a sample of a data, so you should review the inputs used. You can change the selections to include only the columns you want the model to study. You can also select all the columns by selecting the checkbox next to the table name.
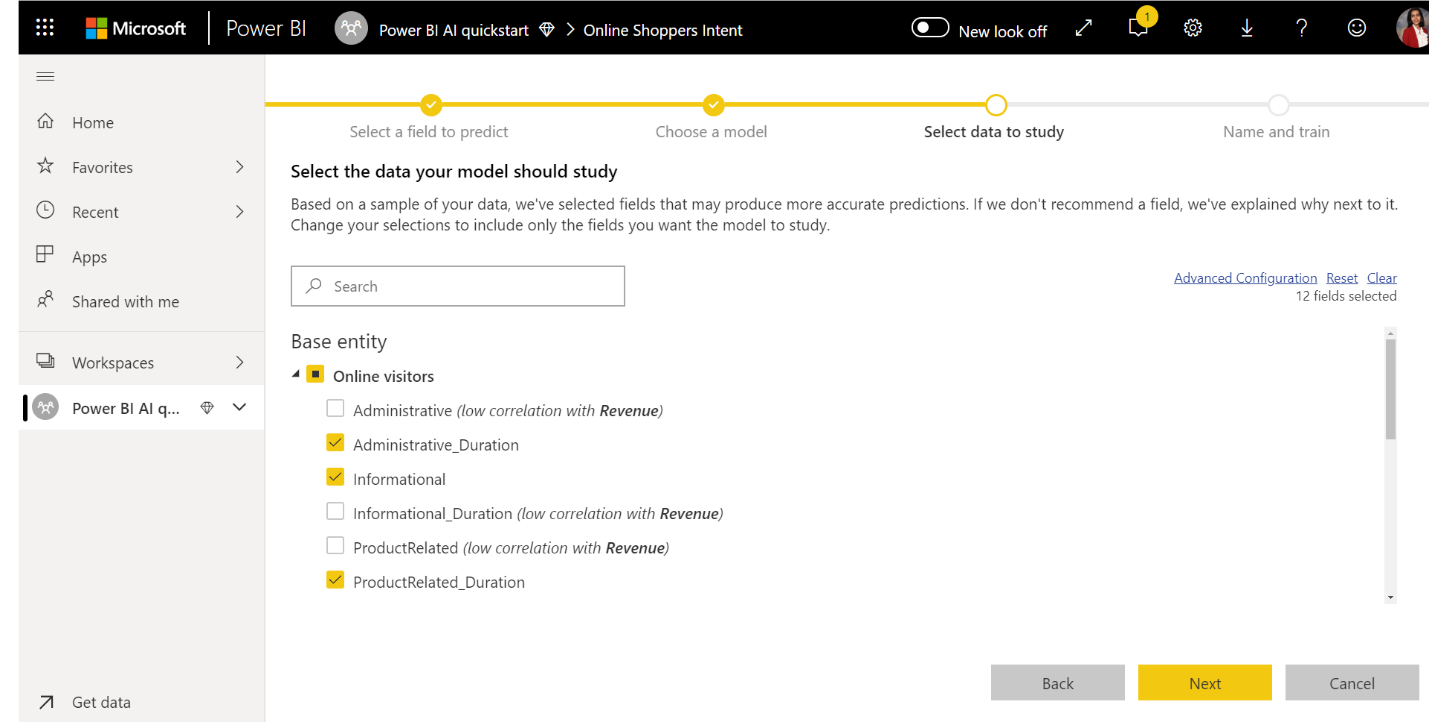
4. Name your model and save your configuration
In the final step, you can name the model, select Save, and choose which begins training the ML model. You can choose to reduce the training time to see quick results or increase the amount of time spent in training to get the best model.
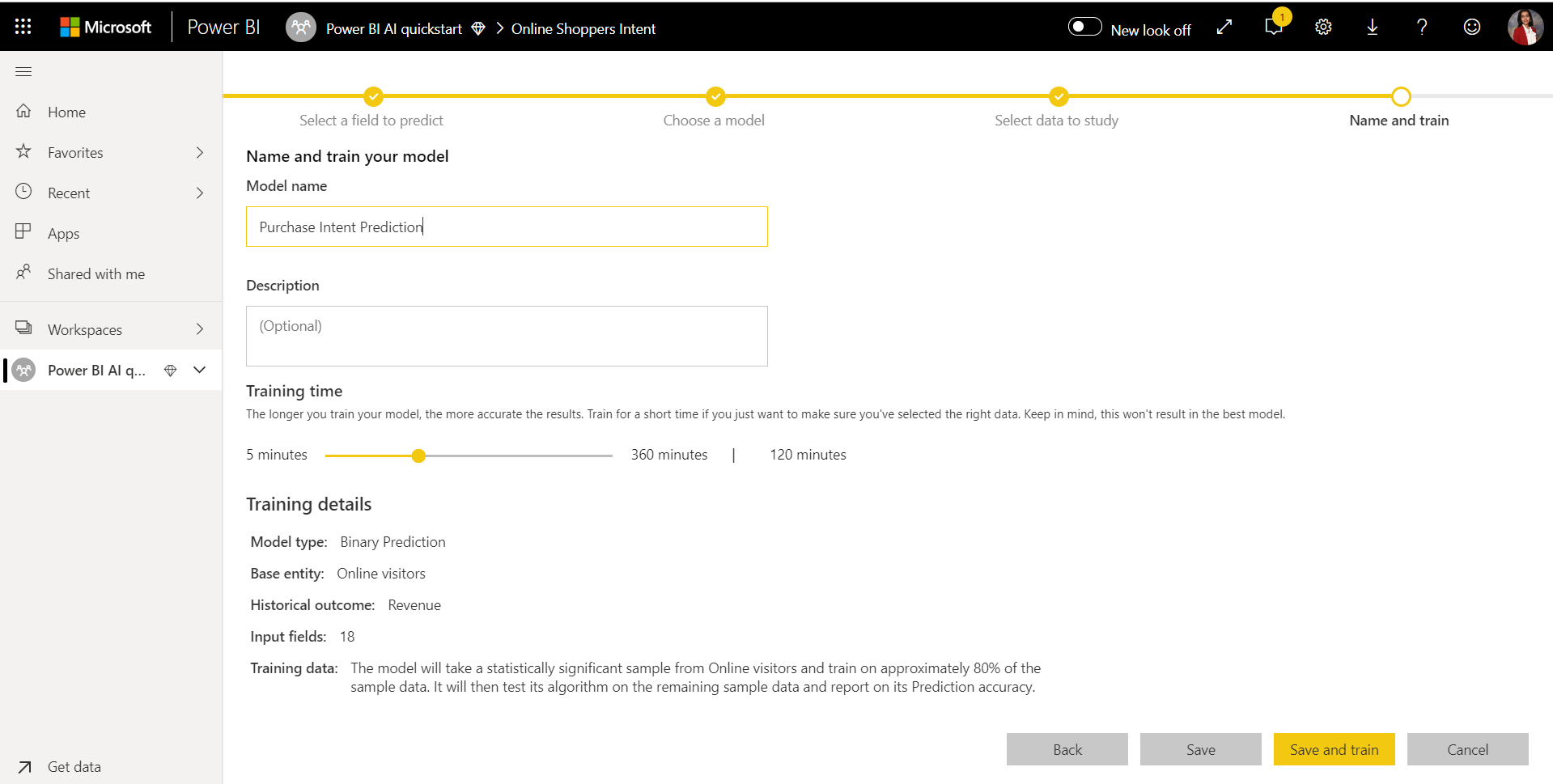
ML model training
Training of AutoML models is a part of the dataflow refresh. AutoML first prepares your data for training. AutoML splits the historical data you provide into training and testing semantic models. The test semantic model is a holdout set that is used for validating the model performance after training. These sets are realized as Training and Testing tables in the dataflow. AutoML uses cross-validation for the model validation.
Next, each input column is analyzed and imputation is applied, which replaces any missing values with substituted values. A couple of different imputation strategies are used by AutoML. For input attributes treated as numeric features, the mean of the column values is used for imputation. For input attributes treated as categorical features, AutoML uses the mode of the column values for imputation. The AutoML framework calculates the mean and mode of values used for imputation on the subsampled training semantic model.
Then, sampling and normalization are applied to your data as required. For classification models, AutoML runs the input data through stratified sampling and balances the classes to ensure the row counts are equal for all.
AutoML applies several transformations on each selected input column based on its data type and statistical properties. AutoML uses these transformations to extract features for use in training your ML model.
The training process for AutoML models consists of up to 50 iterations with different modeling algorithms and hyperparameter settings to find the model with the best performance. Training can end early with lesser iterations if AutoML notices that there's no performance improvement being observed. AutoML assesses the performance of each of these models by validating with the holdout test semantic model. During this training step, AutoML creates several pipelines for training and validation of these iterations. The process of assessing the performance of the models can take time, anywhere from several minutes, to a couple of hours, up-to the training time configured in the wizard. The time taken depends on the size of your semantic model and the capacity resources available.
In some cases, the final model generated might use ensemble learning, where multiple models are used to deliver better predictive performance.
AutoML model explainability
After the model has been trained, AutoML analyzes the relationship between the input features and the model output. It assesses the magnitude of change to the model output for the holdout test semantic model for each input feature. This relationship is known as the feature importance. This analysis happens as a part of the refresh after training is complete. Hence your refresh might take longer than the training time configured in the wizard.
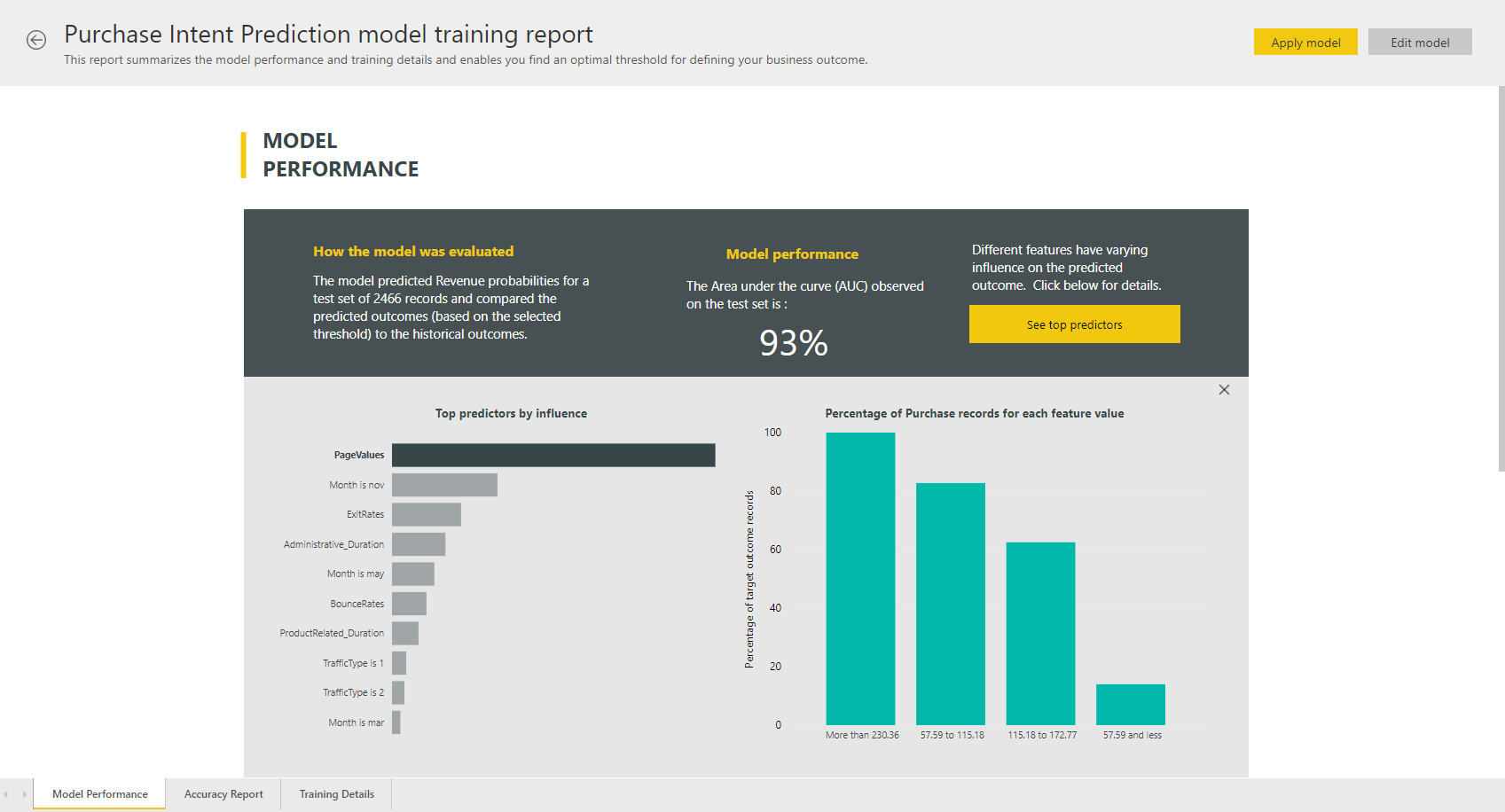
AutoML model report
AutoML generates a Power BI report that summarizes the performance of the model during validation, along with the global feature importance. This report can be accessed from the Machine Learning Models tab after the dataflow refresh is successful. The report summarizes the results from applying the ML model to the holdout test data and comparing the predictions with the known outcome values.
You can review the model report to understand its performance. You can also validate that the key influencers of the model align with the business insights about the known outcomes.
The charts and measures used to describe the model performance in the report depend on the model type. These performance charts and measures are described in the following sections.
Other pages in the report might describe statistical measures about the model from a data science perspective. For instance, the Binary Prediction report includes a gain chart and the ROC curve for the model.
The reports also include a Training Details page that includes a description of how the model was trained, and a chart describing the model performance over each of the iterations run.
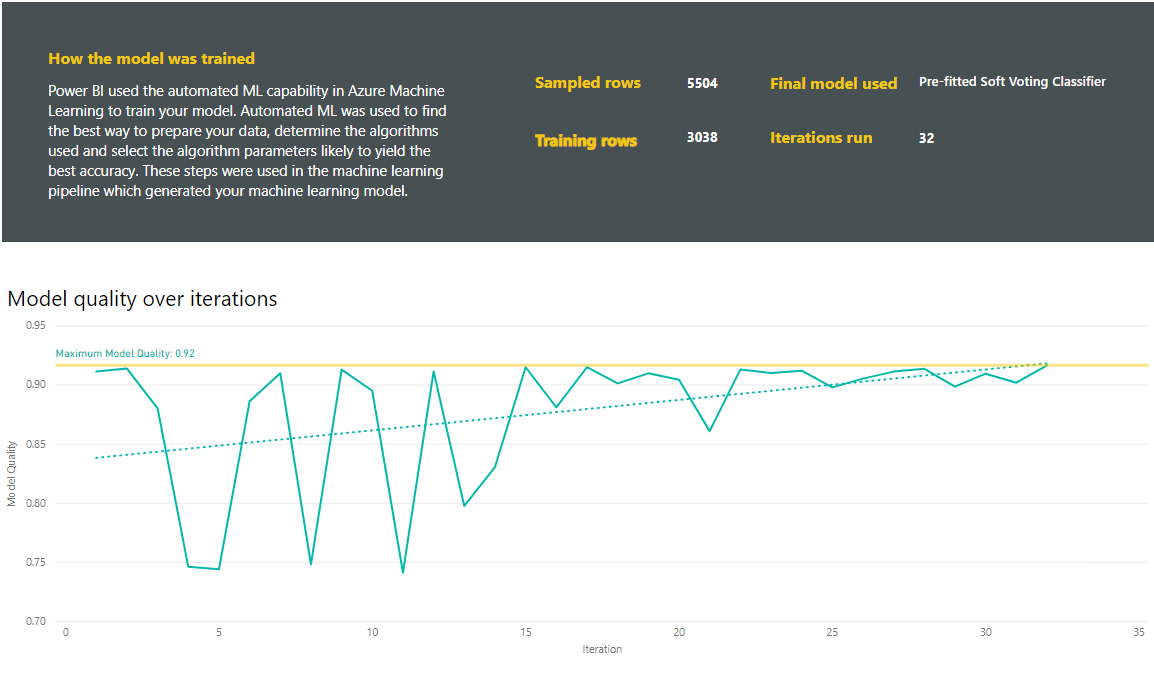
Another section on this page describes the detected type of the input column and imputation method used for filling missing values. It also includes the parameters used by the final model.
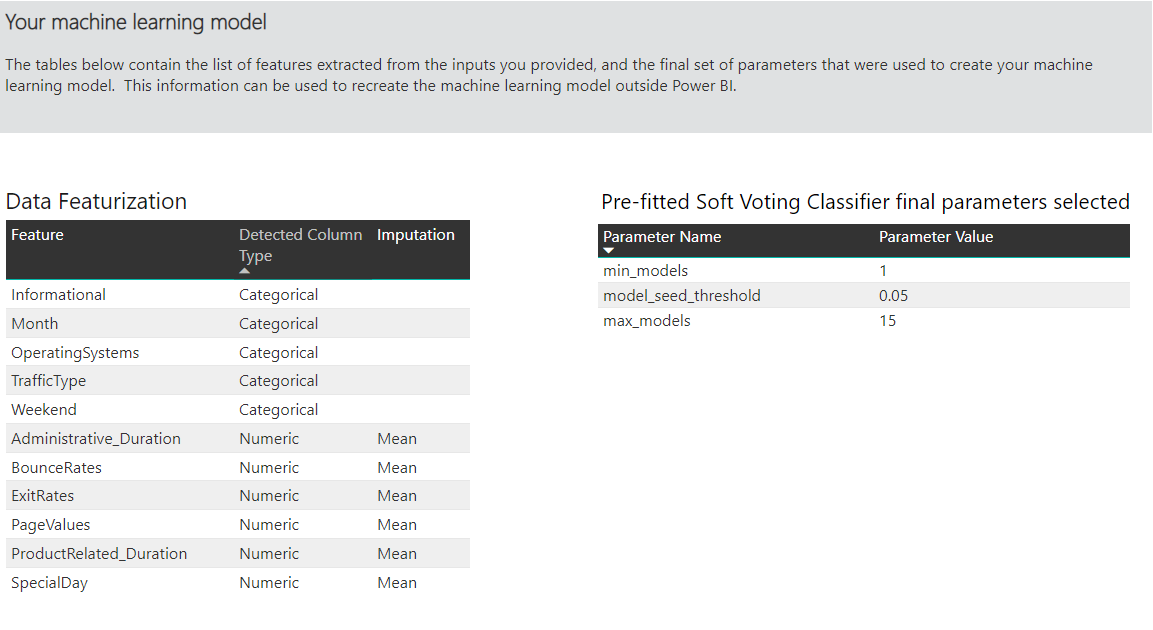
If the model produced uses ensemble learning, then the Training Details page also includes a chart showing the weight of each constituent model in the ensemble and its parameters.

Apply the AutoML model
If you're satisfied with the performance of the ML model created, you can apply it to new or updated data when your dataflow is refreshed. In the model report, select the Apply button in the top-right corner or the Apply ML Model button under actions in the Machine Learning Models tab.
To apply the ML model, you must specify the name of the table to which it must be applied and a prefix for the columns that will be added to this table for the model output. The default prefix for the column names is the model name. The Apply function might include more parameters specific to the model type.
Applying the ML model creates two new dataflow tables that contain the predictions and individualized explanations for each row that it scores in the output table. For instance, if you apply the PurchaseIntent model to the OnlineShoppers table, the output generates the OnlineShoppers enriched PurchaseIntent and OnlineShoppers enriched PurchaseIntent explanations tables. For each row in the enriched table, The Explanations is broken down into multiple rows in the enriched explanations table based on the input feature. An ExplanationIndex helps map the rows from the enriched explanations table to the row in enriched table.
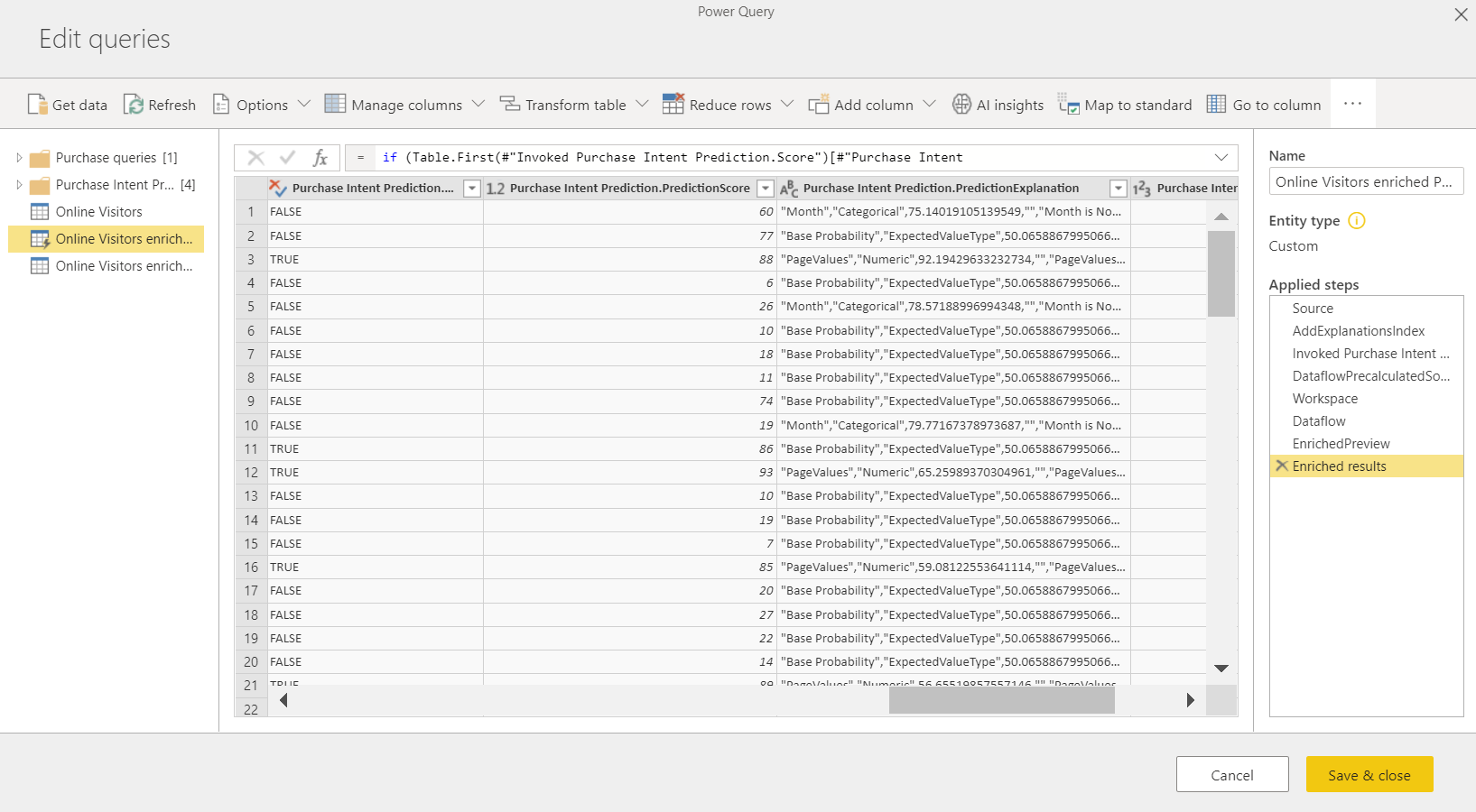
You can also apply any Power BI AutoML model to tables in any dataflow in the same workspace by using AI Insights in the PQO function browser. This way, you can use models created by others in the same workspace without necessarily being an owner of the dataflow that has the model. Power Query discovers all the Power BI ML models in the workspace and exposes them as dynamic Power Query functions. You can invoke those functions by accessing them from the ribbon in Power Query Editor or by invoking the M function directly. This functionality is currently only supported for Power BI dataflows and for Power Query Online in the Power BI service. This process is different from applying ML models within a dataflow using the AutoML wizard. There's no explanations table created by using this method. Unless you're the owner of the dataflow, you can't access model training reports or retrain the model. Also, if the source model is edited by adding or removing input columns or the model or source dataflow is deleted,then this dependent dataflow would break.

After you apply the model, AutoML always keeps your predictions up-to-date whenever the dataflow is refreshed.
To use the insights and predictions from the ML model in a Power BI report, you can connect to the output table from Power BI Desktop by using the dataflows connector.
Binary Prediction models
Binary Prediction models, more formally known as binary classification models, are used to classify a semantic model into two groups. They're used to predict events that can have a binary outcome. For instance, whether a sales opportunity will convert, whether an account will churn, whether an invoice will be paid on time, whether a transaction is fraudulent, and so on.
The output of a Binary Prediction model is a probability score, which identifies the likelihood that the target outcome will be achieved.
Train a Binary Prediction model
Pre-requisites:
- A minimum of 20 rows of historical data is required for each class of outcomes
The process of creation for a Binary Prediction model follows the same steps as other AutoML models, described in the previous section, Configure the ML model inputs. The only difference is in the Choose a model step where you can select the target outcome value that you’re most interested in. You can also provide friendly labels for the outcomes to be used in the automatically generated report that summarizes the results of the model validation.
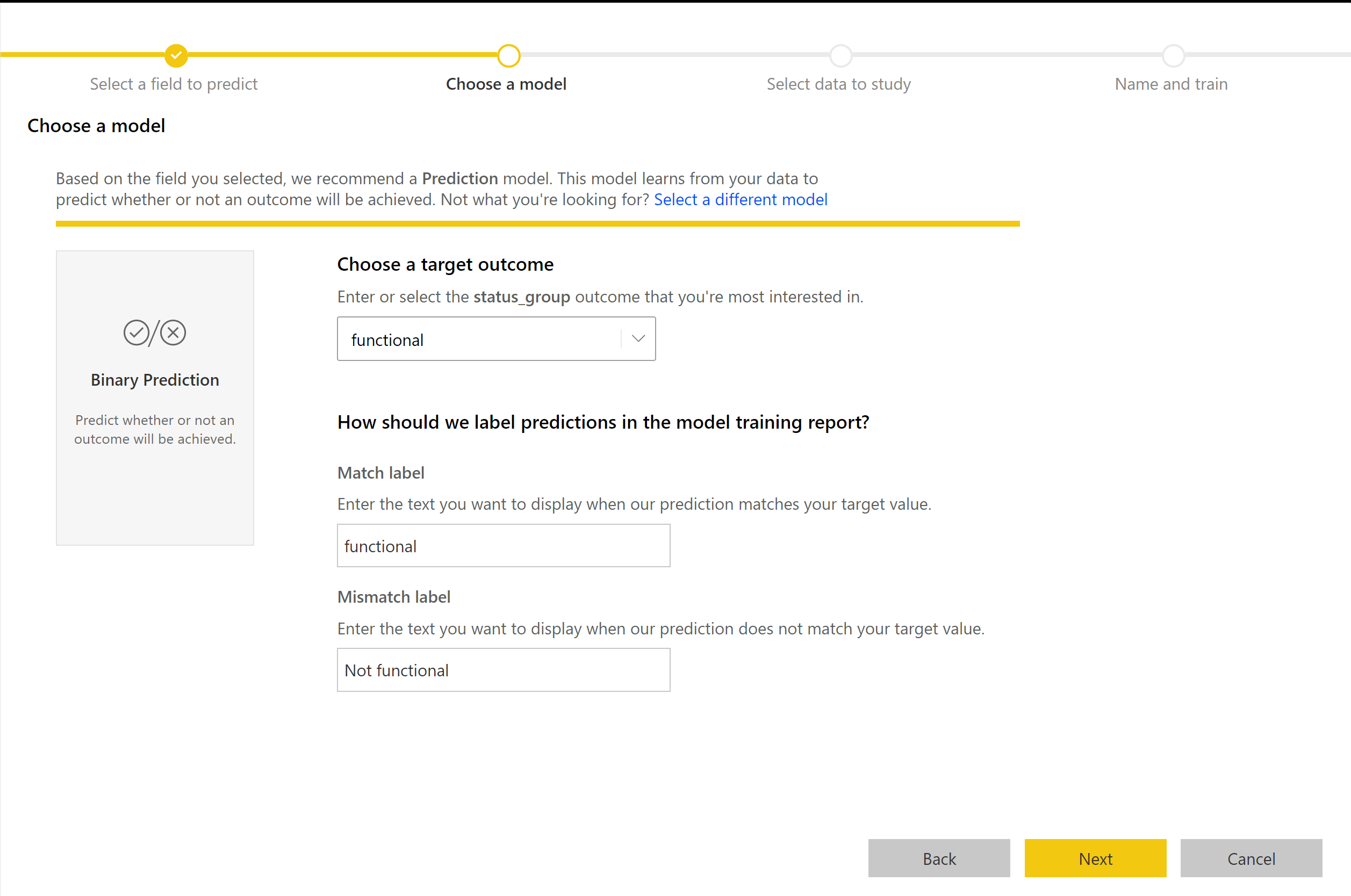
Binary Prediction model report
The Binary Prediction model produces as an output a probability that a row will achieve the target outcome. The report includes a slicer for the probability threshold, which influences how the scores greater and less than the probability threshold are interpreted.
The report describes the performance of the model in terms of True Positives, False Positives, True Negatives, and False Negatives. True Positives and True Negatives are correctly predicted outcomes for the two classes in the outcome data. False Positives are rows that were predicted to have Target outcome but actually didn't. Conversely, False Negatives are rows that had target outcomes but were predicted as not them.
Measures, such as Precision and Recall, describe the effect of the probability threshold on the predicted outcomes. You can use the probability threshold slicer to select a threshold that achieves a balanced compromise between Precision and Recall.

The report also includes a Cost-Benefit analysis tool to help identify the subset of the population that should be targeted to yield the highest profit. Given an estimated unit cost of targeting and a unit benefit from achieving a target outcome, Cost-Benefit analysis attempts to maximize profit. You can use this tool to pick your probability threshold based on the maximum point in the graph to maximize profit. You can also use the graph to compute the profit or cost for your choice of probability threshold.
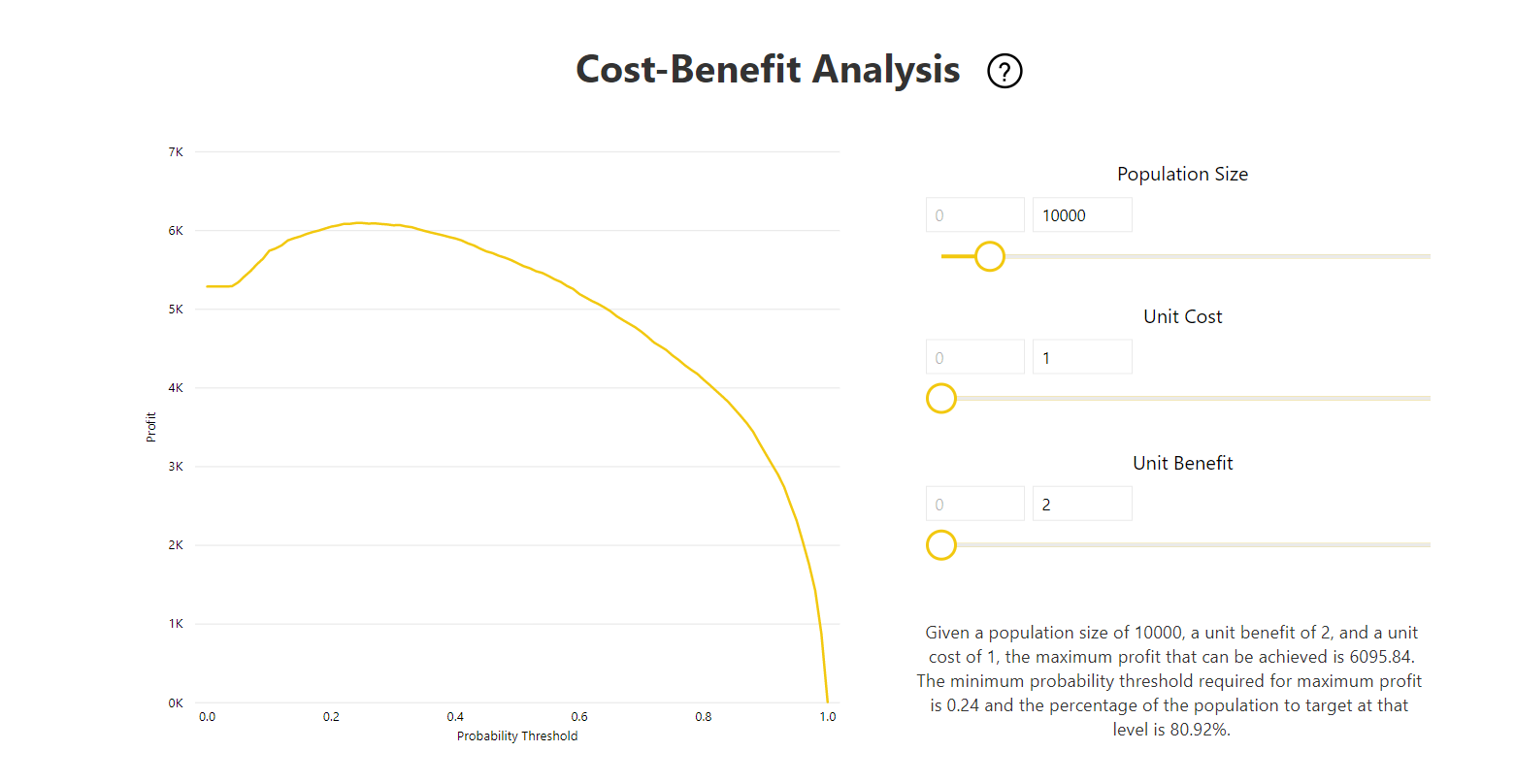
The Accuracy Report page of the model report includes the Cumulative Gains chart and the ROC curve for the model. This data provides statistical measures of the model performance. The reports include descriptions of the charts shown.
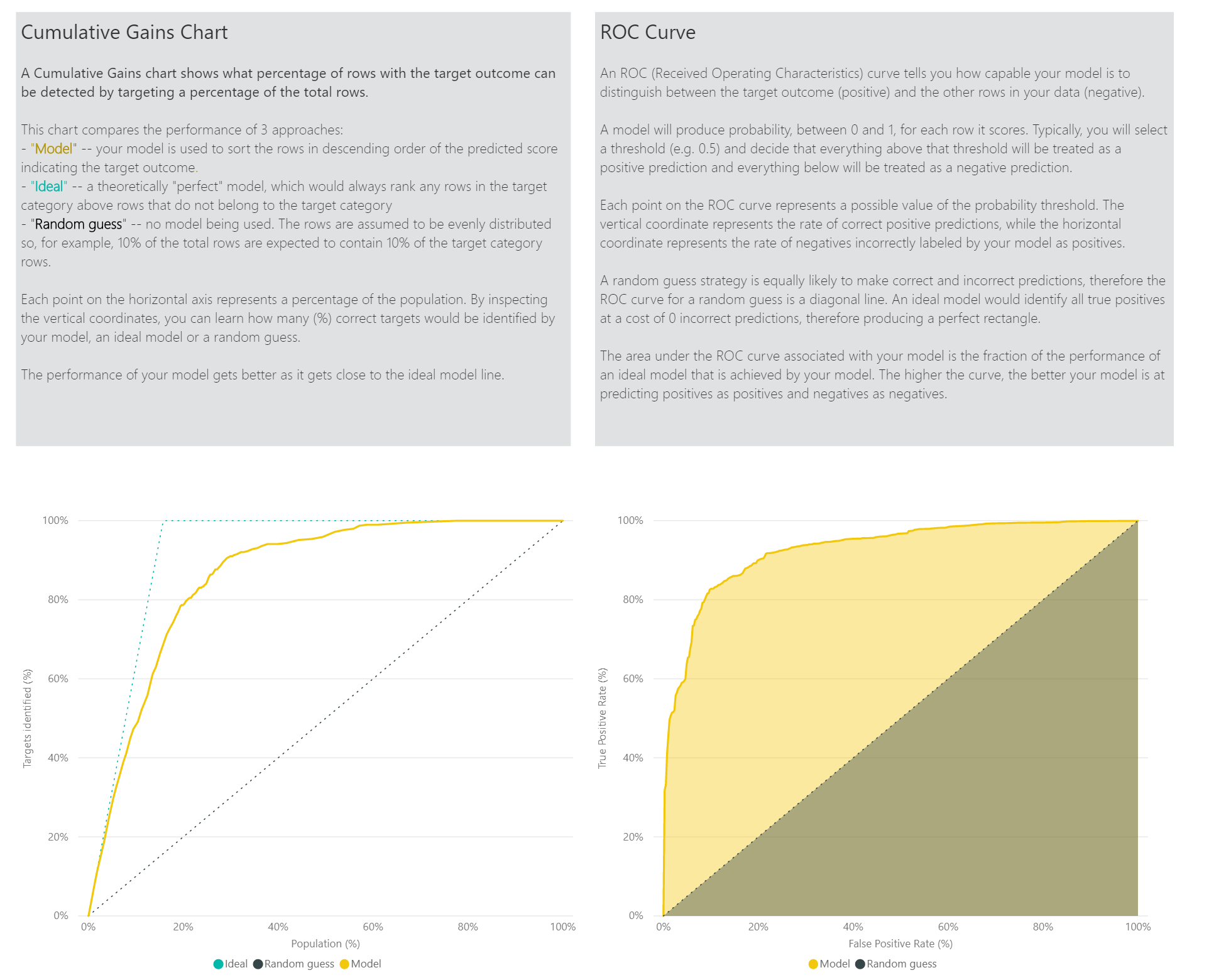
Apply a Binary Prediction model
To apply a Binary Prediction model, you must specify the table with the data to which you want to apply the predictions from the ML model. Other parameters include the output column name prefix and the probability threshold for classifying the predicted outcome.
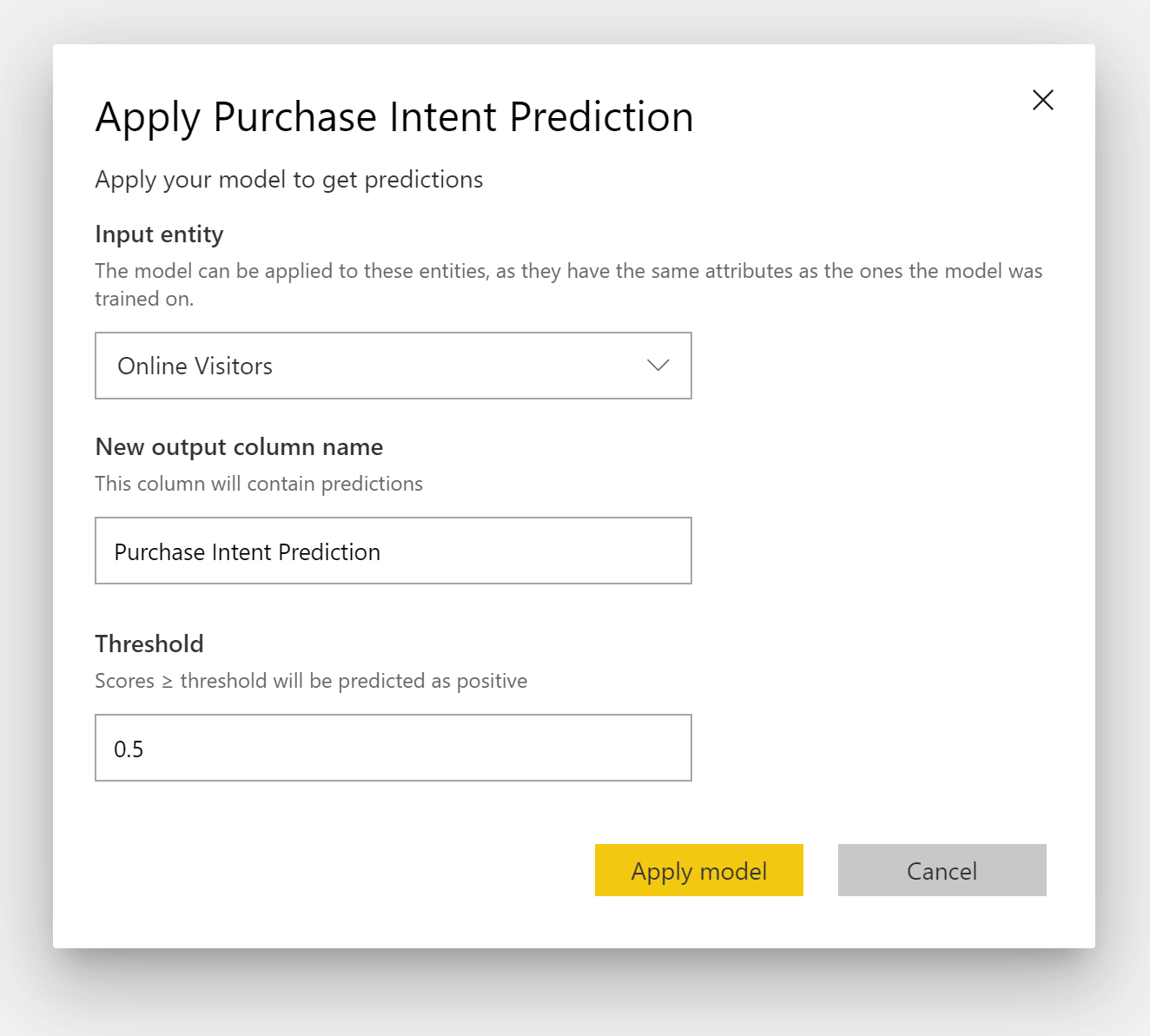
When a Binary Prediction model is applied, it adds four output columns to the enriched output table: Outcome, PredictionScore, PredictionExplanation, and ExplanationIndex. The column names in the table have the prefix specified when the model is applied.
PredictionScore is a percentage probability, which identifies the likelihood that the target outcome will be achieved.
The Outcome column contains the predicted outcome label. Records with probabilities exceeding the threshold are predicted as likely to achieve the target outcome and are labeled as True. Records less than the threshold are predicted as unlikely to achieve the outcome and are labeled as False.
The PredictionExplanation column contains an explanation with the specific influence that the input features had on the PredictionScore.
Classification models
Classification models are used to classify a semantic model into multiple groups or classes. They're used to predict events that can have one of the multiple possible outcomes. For instance, whether a customer is likely to have a high, medium, or low Lifetime Value. They can also predict whether the risk of default is high, moderate, low, and so on.
The output of a Classification model is a probability score, which identifies the likelihood that a row will achieve the criteria for a given class.
Train a Classification model
The input table containing your training data for a classification model must have a string or whole number column as the outcome column, which identifies the past known outcomes.
Pre-requisites:
- A minimum of 20 rows of historical data is required for each class of outcomes
The process of creation for a classification model follows the same steps as other AutoML models, described in the previous section, Configure the ML model inputs.
Classification model report
Power BI creates the classification model report by applying the ML model to the holdout test data. Then it compares the predicted class for a row with the actual known class.
The model report includes a chart that includes the breakdown of the correctly and incorrectly classified rows for each known class.
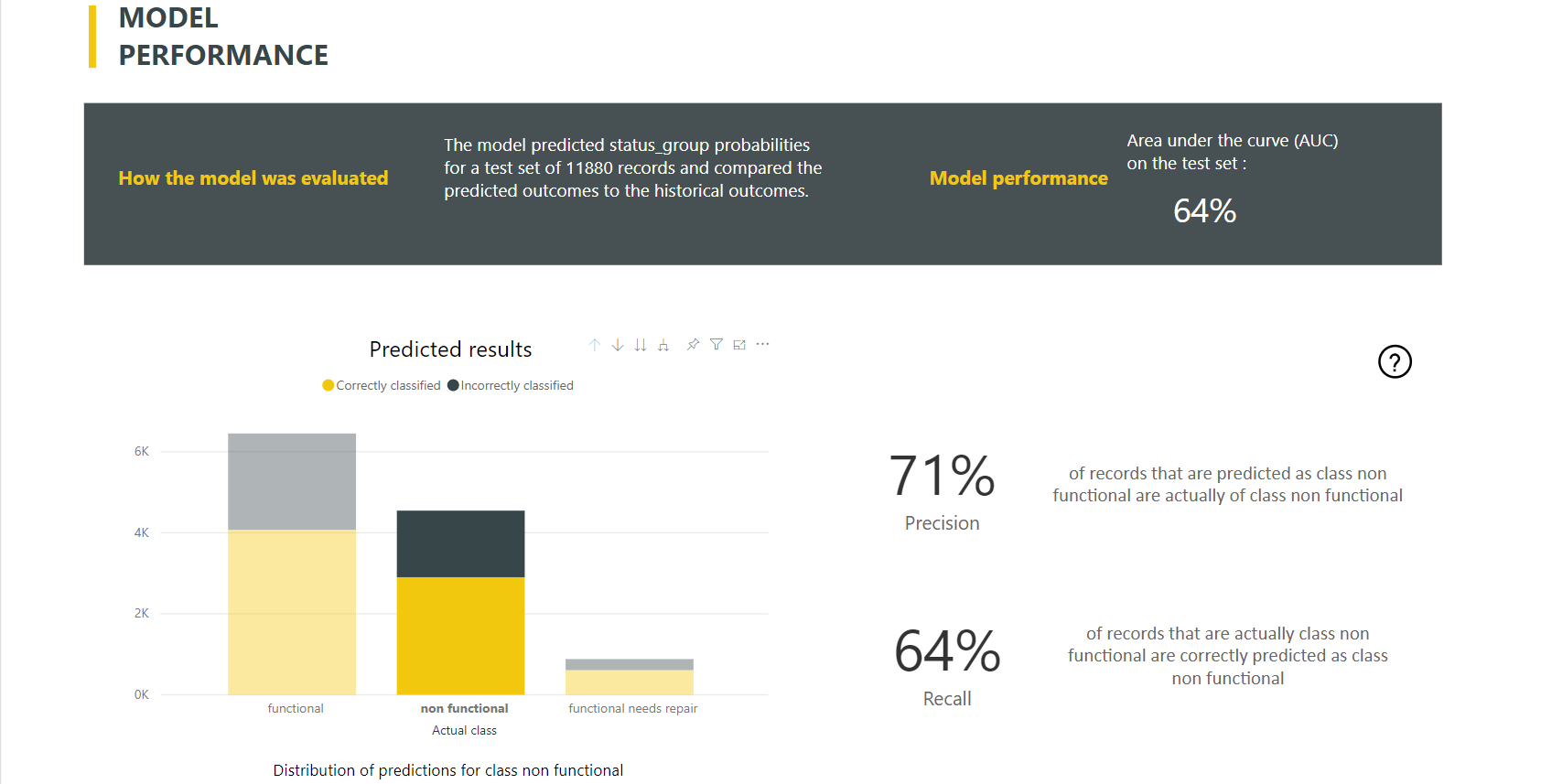
A further class-specific drill-down action enables an analysis of how the predictions for a known class are distributed. This analysis shows the other classes in which rows of that known class are likely to be misclassified.
The model explanation in the report also includes the top predictors for each class.
The classification model report also includes a Training Details page similar to the pages for other model types, as described earlier, in AutoML model report.
Apply a classification model
To apply a classification ML model, you must specify the table with the input data and the output column name prefix.
When a classification model is applied, it adds five output columns to the enriched output table: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities, and ExplanationIndex. The column names in the table have the prefix specified when the model is applied.
The ClassProbabilities column contains the list of probability scores for the row for each possible class.
The ClassificationScore is the percentage probability, which identifies the likelihood that a row will achieve the criteria for a given class.
The ClassificationResult column contains the most likely predicted class for the row.
The ClassificationExplanation column contains an explanation with the specific influence that the input features had on the ClassificationScore.
Regression models
Regression models are used to predict a numeric value and can be used in scenarios like determining:
- The revenue likely to be realized from a sales deal.
- The lifetime value of an account.
- The amount of a receivable invoice that is likely to be paid
- The date on which an invoice might be paid, and so on.
The output of a Regression model is the predicted value.
Training a Regression model
The input table containing the training data for a Regression model must have a numeric column as the outcome column, which identifies the known outcome values.
Pre-requisites:
- A minimum of 100 rows of historical data is required for a Regression model.
The process of creation for a Regression model follows the same steps as other AutoML models, described in the previous section, Configure the ML model inputs.
Regression model report
Like the other AutoML model reports, the Regression report is based on the results from applying the model to the holdout test data.
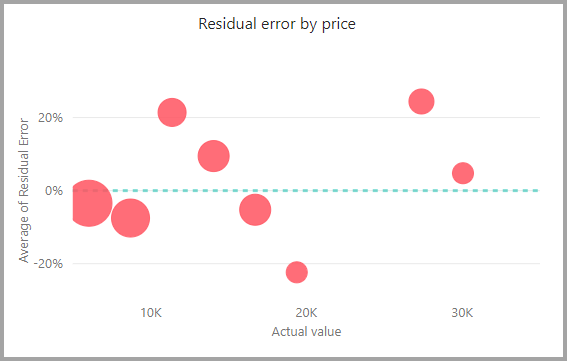
The model report includes a chart that compares the predicted values to the actual values. In this chart, the distance from the diagonal indicates the error in the prediction.
The residual error chart shows the distribution of the percentage of average error for different values in the holdout test semantic model. The horizontal axis represents the mean of the actual value for the group. The size of the bubble shows the frequency or count of values in that range. The vertical axis is the average residual error.
The Regression model report also includes a Training Details page like the reports for other model types, as described in the previous section, AutoML model report.
Apply a regression model
To apply a Regression ML model, you must specify the table with the input data and the output column name prefix.
When a Regression model is applied, it adds three output columns to the enriched output table: RegressionResult, RegressionExplanation, and ExplanationIndex. The column names in the table have the prefix specified when the model is applied.
The RegressionResult column contains the predicted value for the row based on the input columns. The RegressionExplanation column contains an explanation with the specific influence that the input features had on the RegressionResult.
Azure Machine Learning integration in Power BI
Numerous organizations use machine learning models for better insights and predictions about their business. You can use machine learning with your reports, dashboards and other analytics to gain these insights. The ability to visualize and invoke insights from these models can help disseminate these insights to the business users who need it the most. Power BI now makes it simple to incorporate the insights from models hosted on Azure Machine Learning, by using straightforward point-and-click gestures.
To use this capability, a data scientist can grant access to the Azure Machine Learning model to the BI analyst by using the Azure portal. Then, at the start of each session, Power Query discovers all the Azure Machine Learning models to which the user has access and exposes them as dynamic Power Query functions. The user can then invoke those functions by accessing them from the ribbon in Power Query Editor, or by invoking the M function directly. Power BI also automatically batches the access requests when invoking the Azure Machine Learning model for a set of rows to achieve better performance.
This functionality is currently only supported for Power BI dataflows and for Power Query online in the Power BI service.
To learn more about dataflows, see Introduction to dataflows and self-service data prep.
To learn more about Azure Machine Learning, see:
- Overview: What is Azure Machine Learning?
- Quick Starts and Tutorials for Azure Machine Learning: Azure Machine Learning Documentation
Grant access to the Azure Machine Learning model to a Power BI user
To access an Azure Machine Learning model from Power BI, the user must have Read access to the Azure subscription and the Machine Learning workspace.
The steps in this article describe how to grant a Power BI user access to a model hosted on the Azure Machine Learning service to access this model as a Power Query function. For more information, see Assign Azure roles using the Azure portal.
Sign in to the Azure portal.
Go to the Subscriptions page. You can find the Subscriptions page through the All Services list in the nav pane menu of the Azure portal.

Select your subscription.

Select Access Control (IAM), and then choose the Add button.

Select Reader as the Role. Then choose the Power BI user to whom you wish to grant access to the Azure Machine Learning model.

Select Save.
Repeat steps three through six to grant Reader access to the user for the specific machine learning workspace hosting the model.




Schema discovery for machine learning models
Data scientists primarily use Python to develop, and even deploy, their machine learning models for machine learning. The data scientist must explicitly generate the schema file by using Python.
This schema file must be included in the deployed web service for machine learning models. To automatically generate the schema for web service, you must provide a sample of the input/output in the entry script for the deployed model. For more information, see Deploy and score a machine learning model by using an online endpoint. The link includes the example entry script with the statements for the schema generation.
Specifically, the @input_schema and @output_schema functions in the entry script reference the input and output sample formats in the input_sample and output_sample variables. The functions use these samples to generate an OpenAPI (Swagger) specification for the web service during deployment.
These instructions for schema generation by updating the entry script must also be applied to models created by using automated machine learning experiments with the Azure Machine Learning SDK.
Note
Models created by using the Azure Machine Learning visual interface don't currently support schema generation but will in subsequent releases.
Invoking the Azure Machine Learning model in Power BI
You can invoke any Azure Machine Learning model to which you have been granted access, directly from the Power Query Editor in your dataflow. To access the Azure Machine Learning models, select the Edit Table button for the table that you want to enrich with insights from your Azure Machine Learning model, as shown in the following image.

Selecting the Edit Table button opens the Power Query Editor for the tables in your dataflow.

Select the AI Insights button in the ribbon, and then select the Azure Machine Learning Models folder from the nav pane menu. All the Azure Machine Learning models to which you have access are listed here as Power Query functions. Also, the input parameters for the Azure Machine Learning model are automatically mapped as parameters of the corresponding Power Query function.
To invoke an Azure Machine Learning model, you can specify any of the selected table's columns as an input from the drop-down. You can also specify a constant value to be used as an input by toggling the column icon to the left of the input dialog.

Select Invoke to view the preview of the Azure Machine Learning model's output as a new column in the table. The model invocation shows up as an applied step for the query.

If the model returns multiple output parameters, they're grouped together as a row in the output column. You can expand the column to produce individual output parameters in separate columns.

After you save your dataflow, the model is automatically invoked when the dataflow is refreshed, for any new or updated rows in the table.
Considerations and limitations
- Dataflows Gen2 does not currently integrate with automated machine learning.
- AI insights (Cognitive Services and Azure Machine Learning models) aren't supported on machines with proxy authentication setup.
- Azure Machine Learning models aren't supported for Guest users.
- There are some known issues with using Gateway with AutoML and Cognitive Services. If you need to use a gateway, we recommend creating a dataflow that imports the necessary data via gateway first. Then create another dataflow that references the first dataflow to create or apply these models and AI functions.
- If your AI work with dataflows fails, you may need to enable Fast Combine when using AI with dataflows. Once you have imported your table and before you begin to add AI features, select Options from the Home ribbon, and in the window that appears select the checkbox beside Allow combining data from multiple sources to enable the feature, then select OK to save your selection. Then you can add AI features to your dataflow.
Related content
This article provided an overview of Automated Machine Learning for Dataflows in the Power BI service. The following articles might also be useful.
The following articles provide more information about dataflows and Power BI:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for