What is an Always On availability group?
Applies to: ![]() SQL Server
SQL Server
This article introduces the Always On availability groups concepts that are central for configuring and managing one or more availability groups in the Enterprise edition of SQL Server. For the Standard edition, review Basic availability groups.
The Always On availability groups feature is a high-availability and disaster-recovery solution that provides an enterprise-level alternative to database mirroring. Introduced in SQL Server 2012 (11.x), Always On availability groups maximizes the availability of a set of user databases for an enterprise. An availability group supports a failover environment for a discrete set of user databases, known as availability databases, that fail over together. An availability group supports a set of read-write primary databases and one to eight sets of corresponding secondary databases. Optionally, secondary databases can be made available for read-only access and/or some backup operations.
With SQL Server enabled by Azure Arc, you can view availability groups in Azure portal.
Overview
An availability group supports a replicated environment for a discrete set of user databases, known as availability databases. You can create an availability group for high availability (HA) or for read-scale. An HA availability group is a group of databases that fail over together. A read-scale availability group is a group of databases that are copied to other instances of SQL Server for read-only workload. An availability group supports one set of primary databases and one to eight sets of corresponding secondary databases. Secondary databases aren't* backups. Continue to back up your databases and their transaction logs on a regular basis.
Tip
You can create any type of backup of a primary database. Alternatively, you can create log backups and copy-only full backups of secondary databases. For more information, see Active Secondaries: Backup on Secondary Replicas).
Each set of availability databases is hosted by an availability replica. Two types of availability replicas exist: a single primary replica. which hosts the primary databases, and one to eight secondary replicas, each of which hosts a set of secondary databases and serves as potential failover targets for the availability group. An availability group fails over at the level of an availability replica. An availability replica provides redundancy only at the database level for the set of databases in one availability group. Failovers aren't caused by database issues such as a database becoming suspect due to a loss of a data file or corruption of a transaction log.
The primary replica makes the primary databases available for read-write connections from clients. The primary replica sends transaction log records of each primary database to every secondary database. This process - known as data synchronization - occurs at the database level. Every secondary replica caches the transaction log records (hardens the log) and then applies them to its corresponding secondary database. Data synchronization occurs between the primary database and each connected secondary database, independently of the other databases. Therefore, a secondary database can be suspended or fail without affecting other secondary databases, and a primary database can be suspended or fail without affecting other primary databases.
Optionally, you can configure one or more secondary replicas to support read-only access to secondary databases, and you can configure any secondary replica to permit backups on secondary databases.
SQL Server 2017 introduced two different architectures for availability groups. Always On availability groups provide high availability, disaster recovery, and read-scale balancing. These availability groups require a cluster manager. In Windows, the failover clustering feature provides the cluster manager. In Linux, you can use Pacemaker. The other architecture is a read-scale availability group. A read scale availability group provides replicas for read-only workloads but not high availability. In a read-scale availability group, there's no cluster manager, as failover can't be automatic.
Deploying Always On availability groups for HA on Windows requires a Windows Server Failover Cluster (WSFC). Each availability replica of a given availability group must reside on a different node of the same WSFC. The only exception is that while being migrated to another WSFC cluster, an availability group can temporarily straddle two clusters.
Note
For information about availability groups on Linux, see Always On availability group for SQL Server on Linux.
In an HA configuration, a cluster role is created for every availability group that you create. The WSFC cluster monitors this role to evaluate the health of the primary replica. The quorum for Always On availability groups is based on all nodes in the WSFC cluster regardless of whether a given cluster node hosts any availability replicas. In contrast to database mirroring, there's no witness role in Always On availability groups.
Note
For information about the relationship of SQL Server Always On components to the WSFC cluster, see Windows Server Failover Clustering (WSFC) with SQL Server.
The following illustration shows an availability group that contains one primary replica and four secondary replicas. Up to eight secondary replicas are supported, including one primary replica and four synchronous-commit secondary replicas.
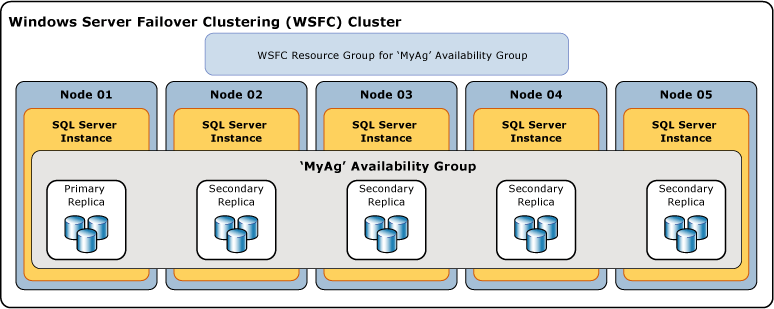
Terms and definitions
availability group
A container for a set of databases, availability databases, that fail over together.
availability database
A database that belongs to an availability group. For each availability database, the availability group maintains a single read-write copy (the primary database) and one to eight read-only copies (secondary databases).
primary database
The read-write copy of an availability database.
secondary database
A read-only copy of an availability database.
availability replica
An instantiation of an availability group that is hosted by a specific instance of SQL Server and maintains a local copy of each availability database that belongs to the availability group. Two types of availability replicas exist: a single primary replica and one to eight secondary replicas.
primary replica
The availability replica that makes the primary databases available for read-write connections from clients and, also, sends transaction log records for each primary database to every secondary replica.
secondary replica
An availability replica that maintains a secondary copy of each availability database, and serves as a potential failover targets for the availability group. Optionally, a secondary replica can support read-only access to secondary databases can support creating backups on secondary databases.
availability group listener
A server name to which clients can connect in order to access a database in a primary or secondary replica of an availability group. Availability group listeners direct incoming connections to the primary replica or to a read-only secondary replica.
Availability databases
To add a database to an availability group, the database must be an online, read-write database that exists on the server instance that hosts the primary replica. When you add a database, it joins the availability group as a primary database, while remaining available to clients. No corresponding secondary database exists until backups of the new primary database are restored to the server instance that hosts the secondary replica (using RESTORE WITH NORECOVERY). The new secondary database is in the RESTORING state until it's joined to the availability group. For more information, see Start Data Movement on an Always On Secondary Database.
Joining places the secondary database into the ONLINE state and initiates data synchronization with the corresponding primary database. Data synchronization is the process by which changes to a primary database are reproduced on a secondary database. Data synchronization involves the primary database sending transaction log records to the secondary database.
Important
An availability database is sometimes called a database replica in Transact-SQL, PowerShell, and SQL Server Management Objects (SMO) names. For example, the term "database replica" is used in the names of the Always On dynamic management views that return information about availability databases: sys.dm_hadr_database_replica_states and sys.dm_hadr_database_replica_cluster_states. However, in SQL Server Books Online, the term "replica" typically refers to availability replicas. For example, "primary replica" and "secondary replica" always refer to availability replicas.
Availability replicas
Each availability group defines a set of two or more failover partners known as availability replicas. Availability replicas are components of the availability group. Each availability replica hosts a copy of the availability databases in the availability group. For a given availability group, the availability replicas must be hosted by separate instances of SQL Server residing on different nodes of a WSFC cluster. Each of these server instances must be enabled for Always On.
SQL Server 2019 (15.x) increases the maximum number of synchronous replicas to 5, up from 3 in SQL Server 2017 (14.x). You can configure this group of five replicas to have automatic failover within the group. There's one primary replica, plus four synchronous secondary replicas.
A given instance can host only one availability replica per availability group. However, each instance can be used for many availability groups. A given instance can be either a stand-alone instance or a SQL Server failover cluster instance (FCI). If you require server-level redundancy, use Failover Cluster Instances.
Every availability replica is assigned an initial role-either the primary role or the secondary role, which is inherited by the availability databases of that replica. The role of a given replica determines whether it hosts read-write databases or read-only databases. One replica, known as the primary replica, is assigned the primary role and hosts read-write databases, which are known as primary databases. At least one other replica, known as a secondary replica, is assigned the secondary role. A secondary replica hosts read-only databases, known as secondary databases.
Note
When the role of an availability replica is indeterminate, such as during a failover, its databases are temporarily in a NOT SYNCHRONIZING state. Their role is set to RESOLVING until the role of the availability replica has resolved. If an availability replica resolves to the primary role, its databases become the primary databases. If an availability replica resolves to the secondary role, its databases become secondary databases.
Availability modes
The availability mode is a property of each availability replica. The availability mode determines whether the primary replica waits to commit transactions on a database until a given secondary replica has written the transaction log records to disk (hardened the log). Always On availability groups supports two availability modes-asynchronous-commit mode and synchronous-commit mode.
Asynchronous-commit mode
An availability replica that uses this availability mode is known as an asynchronous-commit replica. Under asynchronous-commit mode, the primary replica commits transactions without waiting for acknowledgment from asynchronous-commit secondary replicas to harden their transaction logs. Asynchronous-commit mode minimizes transaction latency on the secondary databases but allows them to lag behind the primary databases, making some data loss possible.
Synchronous-commit mode
An availability replica that uses this availability mode is known as a synchronous-commit replica. Under synchronous-commit mode, before committing transactions, a synchronous-commit primary replica waits for a synchronous-commit secondary replica to acknowledge that it has finished hardening the log. Synchronous-commit mode ensures that once a given secondary database is synchronized with the primary database, committed transactions are fully protected. This protection comes at the cost of increased transaction latency. Optionally, SQL Server 2017 introduced a required synchronized secondaries feature to further increase safety at the cost of latency when desired. The REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT feature can be enabled to require a specified number of synchronous replicas to commit a transaction before a primary replica is allowed to commit.
For more information, see Availability Modes.
Types of failover
Within the context of a session between the primary replica and a secondary replica, the primary and secondary roles are potentially interchangeable in a process known as failover. During a failover, the target secondary replica transitions to the primary role, becoming the new primary replica. The new primary replica brings its databases online as the primary databases, and client applications can connect to them. When the former primary replica is available, it transitions to the secondary role, becoming a secondary replica. The former primary databases become secondary databases and data synchronization resumes.
An availability group fails over at the level of an availability replica. Failovers aren't caused by database issues such as a database becoming suspect due to a loss of a data file, deletion of a database, or corruption of a transaction log.
Three forms of failover exist-automatic, manual, and forced (with possible data loss). The form or forms of failover supported by a given secondary replica depends on its availability mode, and, for synchronous-commit mode, on the failover mode on the primary replica and target secondary replica, as follows.
Synchronous-commit mode supports two forms of failover-planned manual failover and automatic failover, if the target secondary replica is currently synchronized with the primary replica. The support for these forms of failover depends on the setting of the failover mode property on the failover partners. If failover mode is set to "manual" on either the primary or secondary replica, only manual failover is supported for that secondary replica. If failover mode is set to "automatic" on both the primary and secondary replicas, both automatic and manual failover are supported on that secondary replica.
Planned manual failover (without data loss)
A manual failover occurs after a database administrator issues a failover command and causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection) and the primary replica to transition to the secondary role. A manual failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode, and the secondary replica must already be synchronized.
Automatic failover (without data loss)
An automatic failover occurs in response to a failure that causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection). When the former primary replica becomes available, it transitions to the secondary role. Automatic failover requires that both the primary replica and the target secondary replica are running under synchronous-commit mode with the failover mode set to "Automatic". In addition, the secondary replica must already be synchronized, have WSFC quorum, and meet the conditions specified by the flexible failover policy of the availability group.
Under asynchronous-commit mode, the only form of failover is forced manual failover (with possible data loss), typically called forced failover. Forced failover is considered a form of manual failover because it can only be initiated manually. Forced failover is a disaster recovery option. It's the only form of failover that is possible when the target secondary replica isn't synchronized with the primary replica.
For more information, see Failover and Failover Modes.
Important
- SQL Server Failover Cluster Instances (FCIs) do not support automatic failover by availability groups, so any availability replica that is hosted by an FCI can only be configured for manual failover.
- If you issue a forced failover command on a synchronized secondary replica, the secondary replica behaves the same as for a planned manual failover.
Benefits
Always On availability groups provide a rich set of options that improve database availability and improve resource use. The key components are as follows:
Supports up to nine availability replicas. An availability replica is an instantiation of an availability group that is hosted by a specific instance of SQL Server and maintains a local copy of each availability database that belongs to the availability group. Each availability group supports one primary replica and up to eight secondary replicas. For more information, see Overview of Always On availability groups.
Important
Each availability replica must reside on a different node of a single Windows Server Failover Clustering (WSFC) cluster. For more information about prerequisites, restrictions, and recommendations for availability groups, see Prerequisites, restrictions, and recommendations for availability groups.
Supports alternative availability modes, as follows:
Asynchronous-commit mode. This availability mode is a disaster-recovery solution that works well when the availability replicas are distributed over considerable distances.
Synchronous-commit mode. This availability mode emphasizes high availability and data protection over performance, at the cost of increased transaction latency. A given availability group can support up to five synchronous-commit availability replicas, including the current primary replica.
For more information, see Availability Modes.
Supports several forms of availability-group failover: automatic failover, planned manual failover (generally referred as simply "manual failover"), and forced manual failover (generally referred as simply "forced failover"). For more information, see Failover and Failover Modes.
Enables you to configure a given availability replica to support either or both of the following active-secondary capabilities:
Read-only connection access that enables read-only connections to the replica to access and read its databases when it's running as a secondary replica. For more information, see Active Secondaries: Readable secondary replicas.
Performing backup operations on its databases when it's running as a secondary replica. For more information, see Active Secondaries: Backup on secondary replicas.
Using active secondary capabilities improves your IT efficiency and reduces cost through better resource utilization of secondary hardware. In addition, offloading read-intent applications and backup jobs to secondary replicas helps to improve performance on the primary replica.
Supports an availability group listener for each availability group. An availability group listener is a server name to which clients can connect in order to access a database in a primary or secondary replica of an Always On availability group. Availability group listeners direct incoming connections to the primary replica or to a read-only secondary replica. The listener provides fast application failover after an availability group fails over. For more information, see Availability group Listeners, Client Connectivity, and Application Failover.
Supports a flexible failover policy for greater control over availability-group failover. For more information, see Failover and failover Modes.
Supports automatic page repair for protection against page corruption. For more information, see Automatic Page Repair.
Supports encryption and compression, which provide a secure, high performing transport.
Provides an integrated set of tools to simplify deployment and management of availability groups, including:
Transact-SQL DDL statements for creating and managing availability groups. For more information, see Transact-SQL Statements for availability groups.
SQL Server Management Studio tools, as follows:
The New Availability Group Wizard creates and configures an availability group. In some environments, this wizard can also automatically prepare the secondary databases and start data synchronization for each of them. For more information, see Use the New Availability Group Dialog Box.
The Add Database to Availability Group Wizard adds one or more primary databases to an existing availability group. In some environments, this wizard can also automatically prepare the secondary databases and start data synchronization for each of them. For more information, see Use the Add Database to Availability Group Wizard.
The Add Replica to Availability Group Wizard adds one or more secondary replicas to an existing availability group. In some environments, this wizard can also automatically prepare the secondary databases and start data synchronization for each of them. For more information, see Use the Add Replica to Availability Group Wizard.
The Fail Over Availability Group Wizard initiates a manual failover on an availability group. Depending on the configuration and state of the secondary replica that you specify as the failover target, the wizard can perform either a planned or forced manual failover. For more information, see Use the Fail Over Availability Group Wizard.
The Always On Dashboard monitors Always On availability groups, availability replicas, and availability databases and evaluates results for Always On policies. For more information, see Use the availability group Dashboard .
The Object Explorer Details pane displays basic information about existing availability groups. For more information, see Use Object Explorer Details to monitor availability groups.
PowerShell cmdlets. For more information, see PowerShell Cmdlets for availability groups.
Client connections
You can provide client connectivity to the primary replica of a given availability group by creating an availability group listener. An availability group listener provides a set of resources that is attached to a given availability group to direct client connections to the appropriate availability replica.
An availability group listener is associated with a unique DNS name that serves as a virtual network name (VNN), one or more virtual IP addresses (VIPs), and a TCP port number. For more information, see Availability group Listeners, Client Connectivity, and Application Failover.
Tip
If an availability group possesses only two availability replicas and is not configured to allow read-access to the secondary replica, clients can connect to the primary replica by using a database mirroring connection string. This approach can be useful temporarily after you migrate a database from database mirroring to Always On availability groups. Before you add additional secondary replicas, you will need to create an availability group listener for the availability group and update your applications to use the network name of the listener.
Active secondary replicas
Always On availability groups supports active secondary replicas. Active secondary capabilities include support for:
Performing backup operations on secondary replicas
The secondary replicas support performing log backups and copy-only backups of a full database, file, or filegroup. You can configure the availability group to specify a preference for where backups should be performed. It's important to understand that the preference isn't enforced by SQL Server, so it has no impact on ad hoc backups. The interpretation of this preference depends on the logic, if any, that you script into your back jobs for each of the databases in a given availability group. For an individual availability replica, you can specify your priority for performing backups on this replica relative to the other replicas in the same availability group. For more information, see Active Secondaries: Backup on secondary replicas.
Read-only access to one or more secondary replicas (readable secondary replicas)
Any secondary availability replica can be configured to allow only read-only access to its local databases, though some operations aren't fully supported. This prevents read-write connection attempts to the secondary replica. It's also possible to prevent read-only workloads on the primary replica by only allowing read-write access. This prevents read-only connections from being made to the primary replica. For more information, see Active Secondaries: Readable secondary replicas.
If an availability group currently possesses an availability group listener and one or more readable secondary replicas, SQL Server can route read-intent connection requests to one of them (read-only routing). For more information, see Availability group Listeners, Client Connectivity, and Application Failover.
Session-timeout period
The session-timeout period is an availability-replica property that determines how long connection with another availability replica can remain inactive before the connection is closed. The primary and secondary replicas ping each other to signal that they're still active. Receiving a ping from the other replica during the timeout period indicates that the connection is still open, and that the server instances are communicating. On receiving a ping, an availability replica resets its session-timeout counter on that connection.
The session-timeout period prevents either replica from waiting indefinitely to receive a ping from the other replica. If no ping is received from the other replica within the session-timeout period, the replica times out. Its connection is closed, and the timed-out replica enters the DISCONNECTED state. Even if a disconnected replica is configured for synchronous-commit mode, transactions won't wait for that replica to reconnect and resynchronize.
The default session-timeout period for each availability replica is 10 seconds. This value is user-configurable, with a minimum of 5 seconds. Generally, we recommend that you keep the time-out period at 10 seconds or greater. Setting the value to less than 10 seconds creates the possibility of a heavily loaded system declaring a false failure.
Note
In the resolving role, the session-timeout period does not apply because pinging does not occur.
Automatic page repair
Each availability replica tries to automatically recover from corrupted pages on a local database by resolving certain types of errors that prevent reading a data page. If a secondary replica can't read a page, the replica requests a fresh copy of the page from the primary replica. If the primary replica can't read a page, the replica broadcasts a request for a fresh copy to all the secondary replicas and gets the page from the first to respond. If this request succeeds, the unreadable page is replaced by the copy, which usually resolves the error.
For more information, see Automatic Page Repair.
Interoperability and Coexistence with Other Database Engine Features
Always On availability groups can be used with the following features or components of SQL Server:
Related content
- Prerequisites, Restrictions, and Recommendations for availability groups
- Create and configure availability groups
- Administration of an availability group
- Monitor availability groups
- Active Secondaries: Readable secondary replicas
- Active Secondaries: Backup on secondary replicas
- Availability group listeners, client connectivity, and application failover
- Transact-SQL statements for availability groups
- PowerShell Cmdlets for availability groups
Blogs:
- SQL Server Support Blog - High Availability
- SQL Server Blog - SQL Server Always On
- Archive: SQL Server Always On Team Blogs: The official SQL Server Always On Team Blog
- Archive: CSS SQL Server Engineers Blogs
Whitepapers:
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for