Describe the anatomy of a pipeline
Azure Pipelines can automatically build and validate every pull request and commit to your Azure Repos Git repository.
Azure Pipelines can be used with Azure DevOps public projects and Azure DevOps private projects.
In future training sections, we'll also learn how to use Azure Repos with external code repositories such as GitHub.
Let's start by creating a hello world YAML Pipeline.
Hello world
Start slowly and create a pipeline that echoes "Hello world!" to the console. No technical course is complete without a hello world example.
name: 1.0$(Rev:.r)
# simplified trigger (implied branch)
trigger:
- main
# equivalents trigger
# trigger:
# branches:
# include:
# - main
variables:
name: John
pool:
vmImage: ubuntu-latest
jobs:
- job: helloworld
steps:
- checkout: self
- script: echo "Hello, $(name)"
Most pipelines will have these components:
- Name – though often it's skipped (if it's skipped, a date-based name is generated automatically).
- Trigger – more on triggers later, but without an explicit trigger. There's an implicit "trigger on every commit to any path from any branch in this repo."
- Variables – "Inline" variables (more on other types of variables later).
- Job – every pipeline must have at least one job.
- Pool – you configure which pool (queue) the job must run on.
- Checkout – the "checkout: self" tells the job which repository (or repositories if there are multiple checkouts) to check out for this job.
- Steps – the actual tasks that need to be executed: in this case, a "script" task (the script is an alias) that can run inline scripts.
Name
The variable name is a bit misleading since the name is in the build number format. You'll get an integer number if you don't explicitly set a name format. A monotonically increasing number of runs triggered off this pipeline, starting at 1. This number is stored in Azure DevOps. You can make use of this number by referencing $(Rev).
To make a date-based number, you can use the format $(Date:yyyyMMdd) to get a build number like 20221003.
To get a semantic number like 1.0.x, you can use something like 1.0.$(Rev:.r).
Triggers
If there's no explicit triggers section, then it's implied that any commit to any path in any branch will trigger this pipeline to run.
However, you can be more precise by using filters such as branches or paths.
Let's consider this trigger:
trigger:
branches:
include:
- main
This trigger is configured to queue the pipeline only when a commit to the main branch exists. What about triggering for any branch except the main? You guessed it: use exclude instead of include:
trigger:
branches:
exclude:
- main
Tip
You can get the name of the branch from the variables Build.SourceBranch (for the full name like refs/heads/main) or Build.SourceBranchName (for the short name like main).
What about a trigger for any branch with a name that starts with topic/ and only if the change is in the webapp folder?
trigger:
branches:
include:
- feature/*
paths:
include:
- webapp/**
You can mix includes and excludes if you need to. You can also filter on tags.
Tip
Don't forget one overlooked trigger: none. You can use none if you never want your pipeline to trigger automatically. It's helpful if you're going to create a pipeline that is only manually triggered.
There are other triggers for other events, such as:
- Pull Requests (PRs) can also filter branches and paths.
- Schedules allow you to specify cron expressions for scheduling pipeline runs.
- Pipelines will enable you to trigger pipelines when other pipelines are complete, allowing pipeline chaining.
You can find all the documentation on triggers here.
Jobs
A job is a set of steps an agent executes in a queue (or pool). Jobs are atomic – they're performed wholly on a single agent. You can configure the same job to run on multiple agents simultaneously, but even in this case, the entire set of steps in the job is run on every agent. You'll need two jobs if you need some steps to run on one agent and some on another.
A job has the following attributes besides its name:
- displayName – a friendly name.
- dependsOn - a way to specify dependencies and ordering of multiple jobs.
- condition – a binary expression: if it evaluates to true, the job runs; if false, the job is skipped.
- strategy - used to control how jobs are parallelized.
- continueOnError - specify if the rest of the pipeline should continue if this job fails.
- pool – the pool name (queue) to run this job on.
- workspace - managing the source workspace.
- container - for specifying a container image to execute the job later.
- variables – variables scoped to this job.
- steps – the set of steps to execute.
- timeoutInMinutes and cancelTimeoutInMinutes for controlling timeouts.
- services - sidecar services that you can spin up.
Dependencies
When you define multiple stages in a pipeline, by default, they run sequentially in the order in which you define them in the YAML file. The exception to this is when you add dependencies. With dependencies, stages run in the order of the dependsOn requirements.
Pipelines must contain at least one stage with no dependencies.
Let's look at a few examples. Consider this pipeline:
jobs:
- job: A
steps:
# steps omitted for brevity
- job: B
steps:
# steps omitted for brevity
Because no dependsOn was specified, the jobs will run sequentially: first A and then B.
To have both jobs run in parallel, we add dependsOn: [] to job B:
jobs:
- job: A
steps:
# steps omitted for brevity
- job: B
dependsOn: [] # This removes the implicit dependency on the previous stage and causes this to run in parallel.
steps:
# steps omitted for brevity
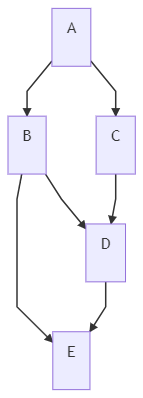
If we want to fan out and fan in, we can do that too:
jobs:
- job: A
steps:
- script: echo' job A.'
- job: B
dependsOn: A
steps:
- script: echo' job B.'
- job: C
dependsOn: A
steps:
- script: echo' job C.'
- job: D
dependsOn:
- B
- C
steps:
- script: echo' job D.'
- job: E
dependsOn:
- B
- D
steps:
- script: echo' job E.'
Checkout
Classic builds implicitly checkout any repository artifacts, but pipelines require you to be more explicit using the checkout keyword:
- Jobs check out the repo they're contained in automatically unless you specify
checkout: none. - Deployment jobs don't automatically check out the repo, so you'll need to specify checkout: self for deployment jobs if you want access to the YAML file's repo.
Download
Downloading artifacts requires you to use the download keyword. Downloads also work the opposite way for jobs and deployment jobs:
- Jobs don't download anything unless you explicitly define a download.
- Deployment jobs implicitly do a download: current, which downloads any pipeline artifacts created in the existing pipeline. To prevent it, you must specify
download: none.
Resources
What if your job requires source code in another repository? You'll need to use resources. Resources let you reference:
- other repositories
- pipelines
- builds (classic builds)
- containers (for container jobs)
- packages
To reference code in another repo, specify that repo in the resources section and then reference it via its alias in the checkout step:
resources:
repositories:
- repository: appcode
type: git
name: otherRepo
steps:
- checkout: appcode
Steps are Tasks
Steps are the actual "things" that execute in the order specified in the job.
Each step is a task: out-of-the-box (OOB) tasks come with Azure DevOps. Many have aliases and tasks installed on your Azure DevOps organization via the marketplace.
Creating custom tasks is beyond the scope of this chapter, but you can see how to make your custom tasks here.
Variables
It would be tough to achieve any sophistication in your pipelines without variables. Though this classification is partly mine, several types of variables exist, and pipelines don't distinguish between these types. However, I've found it helpful to categorize pipeline variables to help teams understand nuances when dealing with them.
Every variable is a key: value pair. The key is the variable's name, and it has a value.
To dereference a variable, wrap the key in $(). Let's consider this example:
variables:
name: John
steps:
- script: echo "Hello, $(name)!"
It will write Hello, John! To the log.