Optimize the source system - advanced
Oracle Row ID table splitting
SAP has released SAP Note #1043380, which contains a script that converts the WHERE clause in a WHR file to a ROW ID value. Alternatively, the latest versions of SAPInst automatically generate ROW ID split WHR files if SWPM is configured for Oracle to Oracle R3load migration. The STR and WHR files generated by SWPM are independent of operating system and database (as are all aspects of the OS/DB migration process).
The OSS note contains the statement “ROWID table splitting CANNOT be used if the target database is a non-Oracle database”. Technically, the R3load dump files are independent of database and operating system. There's one restriction, however, restart of a package during import isn't possible on SQL Server. In this scenario, the entire table needs to be dropped and all packages for the table restarted. It's always recommended to kill R3load tasks for a specific split table, TRUNCATE the table and restart the entire import process if one split R3load aborts. The reason for this is that the recovery process built into R3load involves doing single row-by-row DELETE statements to remove the records loaded by the R3load process that aborts. This is slow and will often cause blocking/locking situations on the database. Experience has shown it's faster to start the import of this specific table from the beginning, therefore the limitation mentioned in SAP Note #1043380 isn't a limitation.
ROW ID has a disadvantage in that calculation of the splits must be done during downtime – see SAP Note #1043380.
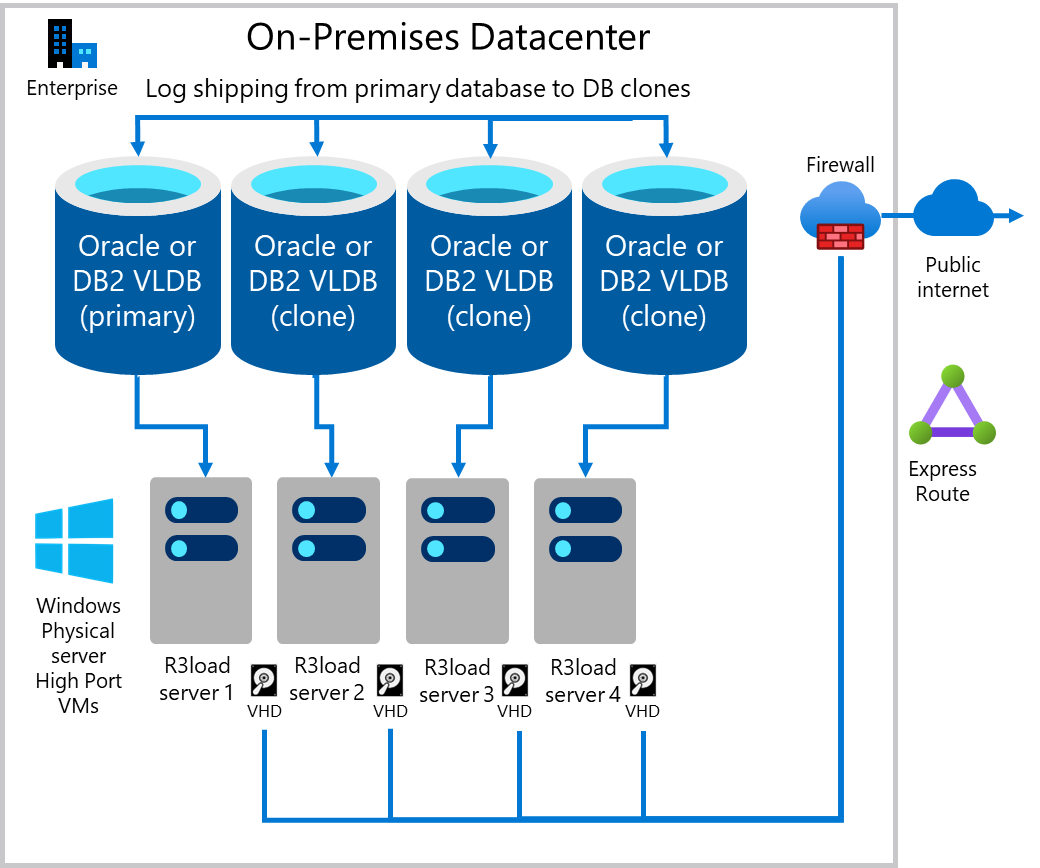
Create multiple “clones” of the source database and export in parallel
One method to increase export performance is to export from multiple copies of the same database. If the underlying infrastructure including servers, network, and storage are scalable, then this approach tends to be linearly scalable. Exporting from two copies of the same database is twice as fast, four copies is four times as fast. Migration Monitor is configured to export on a select number of tables from each “clone” of the database. In the following case, the export workload is distributed approximately 25% on each of the four database servers.
- DB server 1 & export server 1 – dedicated to the largest 1-4 tables (depending on how skewed the data distribution is on the source database)
- DB server 2 & export server 2 – dedicated to tables with table splits
- DB server 3 & export server 3 – dedicated to tables with table splits
- DB server 4 & export server 4 – all remaining tables
Care must be taken to ensure that the databases are precisely synchronized, otherwise data loss or data inconsistencies could occur. If the steps provided are precisely followed, data integrity is preserved.
The technique is simple and cheap with standard commodity Intel hardware but is also possible for customers running proprietary UNIX hardware. Substantial hardware resources are free towards the middle of an OS/DB migration project when Sandbox, Development, QAS, Training, and DR systems have already moved to Azure. There's no strict requirement that the “clone” servers have identical hardware resources. With adequate CPU, RAM, disk, and network performance, the addition of each clone increases performance.
If additional export performance is still required open an SAP incident in BC-DB-MSS for additional steps to boost export performance (advanced consultants only).
The steps to implement a multiple parallel export are as follows:
- Back up the primary database and restore onto “n” number of servers (where n = number of clones). For this example, assume n = 3 servers making a total of four DB servers.
- Restore backup onto three servers.
- Establish log shipping from the Primary source DB server to three target “clone” servers.
- Monitor log shipping for several days and ensure log shipping is working reliably.
- At the start of downtime shutdown all SAP application servers except the PAS. Ensure all batch processing is stopped and all RFC traffic is stopped.
- In transaction SM02, enter text “Checkpoint PAS Running”. This updates table TEMSG.
- Stop the Primary Application Server. SAP is now shut down. No more write activity can occur in the source DB. Ensure that no non-SAP application is connected to the source DB (there never should be, but check for any non-SAP sessions at the DB level).
- Run this query on the Primary DB server:
SELECT EMTEXT FROM [schema].TEMSG; - Run the native DBMS level statement:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(exact syntax depends on source DBMS. INSERT into EMTEXT) - Halt automatic transaction log backups. Manually run one final transaction log backup on the Primary DB server. Ensure the log backup is copied to the clone servers.
- Restore the final transaction log backup on all three nodes.
- Recover the database on the 3 “clone” nodes.
- Run the following SELECT statement on all four nodes:
SELECT EMTEXT FROM [schema].TEMSG; - Capture the screen results of the SELECT statement for each of the four DB servers (the primary and the three clones). Be sure to carefully include each hostname – to serve as a proof that the clone DB and the primary are identical and contain the same data from the same point in time.
- Start export_monitor.bat on each Intel R3load export server.
- Start the dump file copy to Azure process (either AzCopy or Robocopy).
- Start import_monitor.bat on the R3load Azure VMs.
The following diagram shows an existing Production DB server log shipping to “clone” databases. Each DB server has one or more Intel R3load servers.