Idées de solution
Cet article présente une idée de solution. Si vous souhaitez que nous développions le contenu avec d’autres informations, telles que des cas d’usage potentiels, d’autres services, des considérations d’implémentation ou un guide des prix, adressez-nous vos commentaires GitHub.
Cet article est un guide d’implémentation et un exemple de scénario qui fournit un exemple de déploiement de la solution décrite dans Implémenter la reconnaissance vocale personnalisée :
Architecture
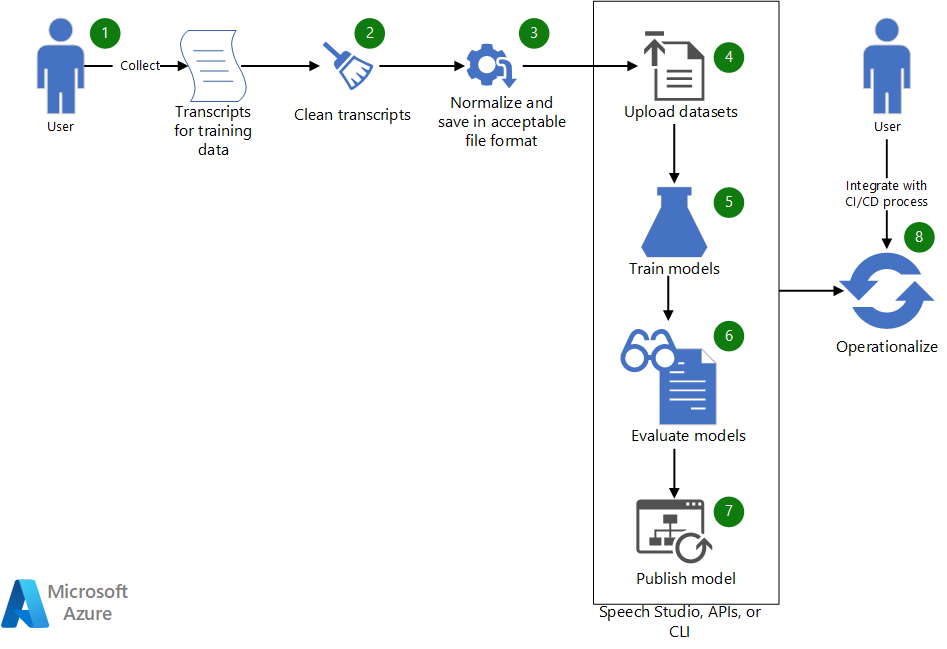
Téléchargez un fichier Visio de cette architecture.
Workflow
- Collectez les transcriptions existantes à utiliser pour entraîner un modèle vocal personnalisé.
- Si les transcriptions sont au format WebVTT ou SRT, rendez les fichiers propres afin qu’ils incluent uniquement les parties de texte des transcriptions.
- Normalisez le texte en supprimant la ponctuation, en séparant les mots répétés et en épelant toutes les grandes valeurs numériques. Vous pouvez combiner plusieurs transcriptions propres en une seule pour créer un jeu de données. De même, créez un jeu de données à des fins de test.
- Une fois les jeux de données prêts, chargez-les à l’aide de Speech Studio. Si le jeu de données se trouve dans un magasin d’objets blob, vous pouvez également utiliser l’API de reconnaissance vocale (STT) Azure et l’interface CLI Speech. Dans l’API et l’interface CLI, vous pouvez transférer une entrée à l’URI du jeu de données pour créer un jeu de données pour l’entraînement et le test du modèle.
- Dans Speech Studio ou via l’API ou l’interface CLI, utilisez le nouveau jeu de données pour entraîner un modèle vocal personnalisé.
- Évaluez le modèle nouvellement entraîné par rapport au jeu de données de test.
- Si les performances du modèle personnalisé répondent à vos attentes en matière de qualité, publiez-le pour une utilisation dans la transcription vocale. Sinon, utilisez Speech Studio pour passer en revue le taux d’erreur de mots et les détails des erreurs spécifiques et déterminer les données supplémentaires nécessaires pour l’entraînement.
- Utilisez les API et l’interface CLI pour rendre opérationnel le processus de génération, d’évaluation et de déploiement du modèle.
Composants
- Azure Machine Learning est un service de classe Entreprise pour le cycle de vie de Machine Learning de bout en bout.
- Azure AI Services est un ensemble d’API, de Kits de développement logiciel (SDK) et de services qui vous permet de créer des applications plus intelligentes, plus attrayantes et plus exploitables.
- Speech Studio est un ensemble d’outils basés sur une interface utilisateur permettant de créer et d’intégrer des fonctionnalités du service Azure AI Speech dans vos applications. Ici, il s’agit d’une alternative pour l’entraînement des jeux de données. Il est également utilisé pour passer en revue les résultats de l’entraînement.
- L’API REST de reconnaissance vocale est une API que vous pouvez utiliser pour charger vos propres données, tester et entraîner un modèle personnalisé, comparer la justesse des différents modèles et déployer un modèle sur un point de terminaison personnalisé. Vous pouvez également l’utiliser pour rendre opérationnelle la création, l’évaluation et le déploiement de votre modèle.
- L’interface CLI Speech est un outil en ligne de commande qui vous permet d’utiliser le service Speech sans avoir à écrire du code. Elle offre une autre alternative pour la création et l’entraînement de jeux de données et pour l’opérationnalisation de vos processus.
Détails du scénario
Cet article est basé sur le scénario fictif suivant :
Contoso, Ltd., est une société de médias de transmission qui diffuse des émissions et des commentaires sur les événements olympiques. Dans le cadre du contrat de transmission, Contoso fournit la transcription d’événements pour l’accessibilité et l’exploration de données.
Contoso souhaite utiliser le service Azure Speech pour fournir un sous-titrage et une transcription audio en direct pour les événements olympiques. Contoso emploie des commentateurs du sexe féminin et masculin du monde entier qui parlent avec divers accents. De plus, chaque sport a une terminologie spécifique qui peut rendre la transcription difficile. Cet article décrit le processus de développement d’application pour ce scénario : fournir des sous-titres pour une application qui doit fournir une transcription d’événement précise.
Contoso dispose déjà des composants prérequis suivants :
- Transcriptions générées par l’homme pour des événements olympiques précédents. Les transcriptions représentent des commentaires de différents sports et de divers commentateurs.
- Une ressource Azure Cognitive Services. Vous pouvez en créer une sur le Portail Azure.
Développer une application vocale personnalisée
Une application vocale utilise le Kit de développement logiciel (SDK) Azure Speech pour se connecter au service Azure Speech afin de générer une transcription audio textuelle. Le service Speech prend en charge plusieurs langues et deux modes de fluidité : conversationnel et dictée. Pour développer une application vocale personnalisée, vous devez généralement effectuer les étapes suivantes :
- Utiliser Speech Studio, le Kit de développement logiciel (SDK) Azure Speech, l’interface CLI Speech ou l’API REST pour générer des transcriptions pour les phrases et les énoncés prononcés.
- Comparer la transcription générée avec la transcription générée par l’homme.
- Si certains mots spécifiques à un domaine sont transcrits de manière incorrecte, envisager de créer un modèle vocal personnalisé pour ce domaine spécifique.
- Passer en revue les différentes options de création de modèles personnalisés. Déterminer si un ou plusieurs modèles personnalisés fonctionneront mieux.
- Collecter des données d’entraînement et de test.
- Vérifier que les données sont dans un format acceptable.
- Entraîner, tester, évaluer et déployer le modèle.
- Utiliser le modèle personnalisé pour la transcription.
- Rendre opérationnel le processus de génération, d’évaluation et de déploiement du modèle.
Examinons de plus près ces étapes :
1. Utiliser Speech Studio, le Kit de développement logiciel (SDK) Azure Speech, l’interface CLI Speech ou l’API REST pour générer des transcriptions pour les phrases et les énoncés prononcés
Azure Speech fournit des Kits de développement logiciel (SDK), une interface CLI et une API REST pour générer des transcriptions à partir de fichiers audio ou directement à partir d’une entrée de microphone. Si le contenu se trouve dans un fichier audio, il doit être dans un format pris en charge. Dans ce scénario, Contoso a des enregistrements d’événements précédents (audio et vidéo) dans des fichiers .avi. Contoso peut utiliser des outils tels que FFmpeg pour extraire l’audio des fichiers vidéo et l’enregistrer dans un format pris en charge par le Kit de développement logiciel (SDK) Azure Speech, comme .wav.
Dans le code suivant, le codec audio PCM standard, pcm_s16le, est utilisé pour extraire l’audio dans un canal unique (mono) qui a un taux d’échantillonnage de 8 kilohertz (KHz).
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. Comparer la transcription générée avec la transcription générée par l’homme
Pour effectuer la comparaison, Contoso échantillonne l’audio des commentaires de plusieurs sports et utilise Speech Studio pour comparer la transcription générée par l’homme avec les résultats transcrits par le service Azure Speech. Les transcriptions générées par l’homme de Contoso sont au format WebVTT. Pour utiliser ces transcriptions, Contoso les rend propres et génère un fichier .txt simple contenant du texte normalisé sans les informations d’horodatage.
Pour plus d’informations sur l’utilisation de Speech Studio pour créer et évaluer un jeu de données, consultez Jeux de données d’entraînement et de test.
Speech Studio fournit une comparaison côte à côte de la transcription générée par l’homme et des transcriptions produites à partir des modèles sélectionnés pour la comparaison. Les résultats des tests incluent un taux d’erreur de mots pour les modèles, comme illustré ici :
| Modèle | Taux d’erreur | Insertion | Substitution | Suppression |
|---|---|---|---|---|
| Modèle 1 : 20211030 | 14,69 % | 6 (2,84 %) | 22 (10,43 %) | 3 (1,42 %) |
| Modèle 2 : Olympics_Skiing_v6 | 6,16 % | 3 (1,42 %) | 8 (3,79 %) | 2 (0,95 %) |
Pour plus d’informations sur le taux d’erreur de mots, consultez Évaluer le taux d’erreur de mots.
Sur la base de ces résultats, le modèle personnalisé (Olympics_Skiing_v6) est meilleur que le modèle de base (20211030) pour le jeu de données.
Notez les taux d’insertion et de suppression, qui indiquent que le fichier audio est relativement propre et ne présente qu’un faible bruit de fond.
3. Si certains mots spécifiques à un domaine sont transcrits de manière incorrecte, envisager de créer un modèle vocal personnalisé pour ce domaine spécifique
D’après les résultats du tableau précédent, pour le modèle de base, Modèle 1 : 20211030, environ 10 % des mots sont remplacés. Dans Speech Studio, utilisez la fonctionnalité de comparaison détaillée pour identifier les mots spécifiques au domaine qui sont manqués. Le tableau suivant présente une section de la comparaison.
| Transcription générée par l’homme | Modèle n° 1 | Modèle n° 2 |
|---|---|---|
| le champion olympique juste derrière dans la descente depuis mille neuf cent quatre-vingt-dix-huit le grand katja seizinger d’Allemagne en quoi quatre-vingt-quatorze et quatre-vingt-dix huit | le champion olympique juste derrière dans la descente depuis mille neuf cent quatre-vingt-dix-huit le grand cas tiens six l’heure d’Allemagne en quoi quatre-vingt-quatorze et quatre-vingt-dix huit | le champion olympique juste derrière dans la descente depuis mille neuf cent quatre-vingt-dix-huit le grand katja seizinger d’Allemagne en quoi quatre-vingt-quatorze et quatre-vingt-dix huit |
| elle a détrôné la championne olympique goggia | elle a détrôné la championne olympique georgia | elle a détrôné la championne olympique goggia |
Le modèle 1 ne reconnaît pas les mots propres à un domaine comme les noms des athlètes « Katja Seizinger » et « Goggia ». Toutefois, lorsque le modèle personnalisé est entraîné avec des données qui incluent les noms des athlètes et d’autres mots et expressions spécifiques au domaine, il est en mesure de les apprendre et de les reconnaître.
4. Passer en revue les différentes options de création de modèles personnalisés. Déterminez si un ou plusieurs modèles personnalisés fonctionneront mieux.
En expérimentant différentes façons de créer des modèles personnalisés, Contoso a constaté qu’ils pouvaient obtenir une meilleure précision en utilisant la personnalisation du modèle de langage et de prononciation. (Consultez le premier article de ce guide.) Contoso a également noté des améliorations mineures en incluant des données acoustiques (audio d’origine) pour la création du modèle personnalisé. Toutefois, les avantages n’étaient pas assez significatifs pour qu’il soit utile de maintenir et d’entraîner un modèle acoustique personnalisé.
Contoso a constaté que la création de modèles linguistiques personnalisés distincts pour chaque sport (un modèle pour le ski alpin, un modèle pour la luge, un modèle pour le snowboard, etc.) a fourni de meilleurs résultats de reconnaissance. Ils ont également noté que la création de modèles acoustiques distincts basés sur le type de sport pour augmenter les modèles linguistiques n’était pas nécessaire.
5 Collecter des données d’entraînement et de test
L’article Jeux de données d’entraînement et de test fournit des détails sur la collecte des données nécessaires à l’entraînement d’un modèle personnalisé. Contoso a collecté les transcriptions de divers sports olympiques à partir de divers commentateurs et a utilisé l’adaptation du modèle de langage pour créer un modèle par type de sport. Toutefois, ils ont utilisé un fichier de prononciation pour tous les modèles personnalisés (un pour chaque sport). Étant donné que les données de test et d’entraînement sont séparées, après la création d’un modèle personnalisé, Contoso a utilisé l’audio de l’événement dont les transcriptions n’étaient pas incluses dans le jeu de données d’entraînement pour l’évaluation du modèle.
6. Vérifier que les données sont dans un format acceptable
Comme décrit dans Jeux de données d’entraînement et de test, les jeux de données utilisés pour créer un modèle personnalisé ou tester le modèle doivent être dans un format spécifique. Les données de Contoso se trouvent dans des fichiers WebVTT. Ils ont créé des outils simples pour produire des fichiers texte contenant du texte normalisé pour l’adaptation du modèle de langage.
7. Entraîner, tester, évaluer et déployer le modèle
De nouveaux enregistrements d’événements sont utilisés pour tester et évaluer davantage le modèle entraîné. Quelques itérations de test et d’évaluation peuvent être nécessaires pour affiner un modèle. Enfin, lorsque le modèle génère des transcriptions qui ont des taux d’erreur acceptables, il est déployé (publié) pour être consommé à partir du Kit de développement logiciel (SDK).
8. Utiliser le modèle personnalisé pour la transcription
Une fois le modèle personnalisé déployé, vous pouvez utiliser le code C# suivant pour utiliser le modèle dans le Kit de développement logiciel (SDK) pour la transcription :
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
Remarques concernant le code :
endpointest l’ID du point de terminaison du modèle personnalisé déployé à l’étape 7.subscriptionKeyetregionsont la clé et la région d’abonnement Azure AI Services. Vous pouvez obtenir ces valeurs à partir du Portail Azure en accédant au groupe de ressources où la ressource Azure AI Services a été créée et en examinant ses clés.
9. Rendre opérationnel le processus de génération, d’évaluation et de déploiement du modèle
Une fois le modèle personnalisé publié, il doit être évalué régulièrement et mis à jour si du nouveau vocabulaire est ajouté. Votre entreprise peut évoluer et vous aurez peut-être besoin de plus de modèles personnalisés pour couvrir un plus grand nombre de domaines. L’équipe Azure Speech publie également de nouveaux modèles de base, qui sont entraînés sur plus de données, à mesure qu’ils deviennent disponibles. L’automatisation peut vous aider à suivre ces modifications. La section suivante de cet article fournit plus de détails sur l’automatisation des étapes précédentes.
Déployer ce scénario
Pour plus d’informations sur l’utilisation des scripts pour simplifier et automatiser l’ensemble du processus de création de jeux de données à des fins de formation et de test, de création et d’évaluation de modèles et de publication de nouveaux modèles en fonction des besoins, consultez Custom-speech-STT sur GitHub.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Pratyush Mishra | Responsable principal de l’ingénierie
Autres contributeurs :
- Mick Alberts | Rédacteur technique
- Rania Bayoumy | Responsable de programme technique senior
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Qu’est-ce que Custom Speech ?
- Qu’est-ce que la synthèse vocale ?
- Former un modèle vocal Custom Speech
- Implémenter la reconnaissance vocale personnalisée
- Azure/custom-speech-STT sur GitHub