Idées de solution
Cet article présente une idée de solution. Si vous souhaitez que nous développions le contenu avec d’autres informations, telles que des cas d’usage potentiels, d’autres services, des considérations d’implémentation ou un guide des prix, adressez-nous vos commentaires GitHub.
Cet exemple indique comment effectuer un chargement incrémentiel dans un pipeline Extraire, charger et transformer (ELT). Elle utilise Azure Data Factory pour automatiser le pipeline ELT. Ce pipeline déplace de façon incrémentielle les données OLTP les plus récentes d’une base de données SQL Server locale vers Azure Synapse. Les données transactionnelles sont transformées en un modèle tabulaire à des fins d’analyse.
Architecture

Téléchargez un fichier Visio de cette architecture.
Cette architecture repose sur celle qui est décrite dans la section Décisionnel d’entreprise avec Azure Synapse, mais ajoute des fonctionnalités qui sont importantes pour les scénarios d’entreposage de données d’entreprise.
- Automatisation du pipeline à l’aide de Data Factory.
- Chargement incrémentiel.
- Intégration de plusieurs sources de données.
- Chargement des données binaires comme les données géospatiales et les images.
Workflow
L’architecture comprend les services et composants suivants.
Sources de données
Serveur SQL Server local. Les données sources sont situées dans une base de données SQL Server locale. Pour simuler l’environnement local. L’exemple de base de données OLTP Wide World Importers est utilisé comme base de données source.
Données externes. Un scénario courant de gestion des entrepôts de données consiste à intégrer plusieurs sources de données. Cette architecture de référence charge un jeu de données externe qui contient la population par ville et par année, et l’intègre dans les données de la base de données OLTP. Vous pouvez utiliser ces données pour obtenir des insights du type : « La croissance des ventes dans chaque région correspond-elle, voire dépasse-t-elle la croissance de la population ? »
Ingestion et stockage de données
Stockage d'objets blob. Le stockage d’objets blob est utilisé en tant que zone de processus de site pour les données sources, avant leur chargement dans Azure Synapse.
Azure Synapse. Azure Synapse est un système distribué conçu pour réaliser des analyses sur de grandes quantités de données. Il prend en charge le traitement MPP (Massive Parallel Processing), le rendant ainsi adapté à l’exécution d’analyses hautes performances.
Azure Data Factory. Data Factory est un service géré qui orchestre et automatise le déplacement et la transformation des données. Dans cette architecture, il coordonne les différentes étapes du processus ELT.
Analyse et rapports
Azure Analysis Services. Analysis Services est un service entièrement géré qui fournit des capacités de modélisation des données. Le modèle sémantique est chargé dans Analysis Services.
Power BI. Power BI est une suite d’outils d’analyse métier pour analyser les données et obtenir des informations métier. Dans cette architecture, il demande le modèle sémantique stocké dans Analysis Services.
Authentification
Microsoft Entra ID (Microsoft Entra ID) authentifie les utilisateurs qui se connectent au serveur Analysis Services à travers Power BI.
Data Factory peut également utiliser Microsoft Entra ID pour s’authentifier auprès d’Azure Synapse à l’aide d’un principal de service ou une identité MSI (Managed Service Identity).
Composants
- Stockage Blob Azure
- Azure Synapse Analytics
- Azure Data Factory.
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Détails du scénario
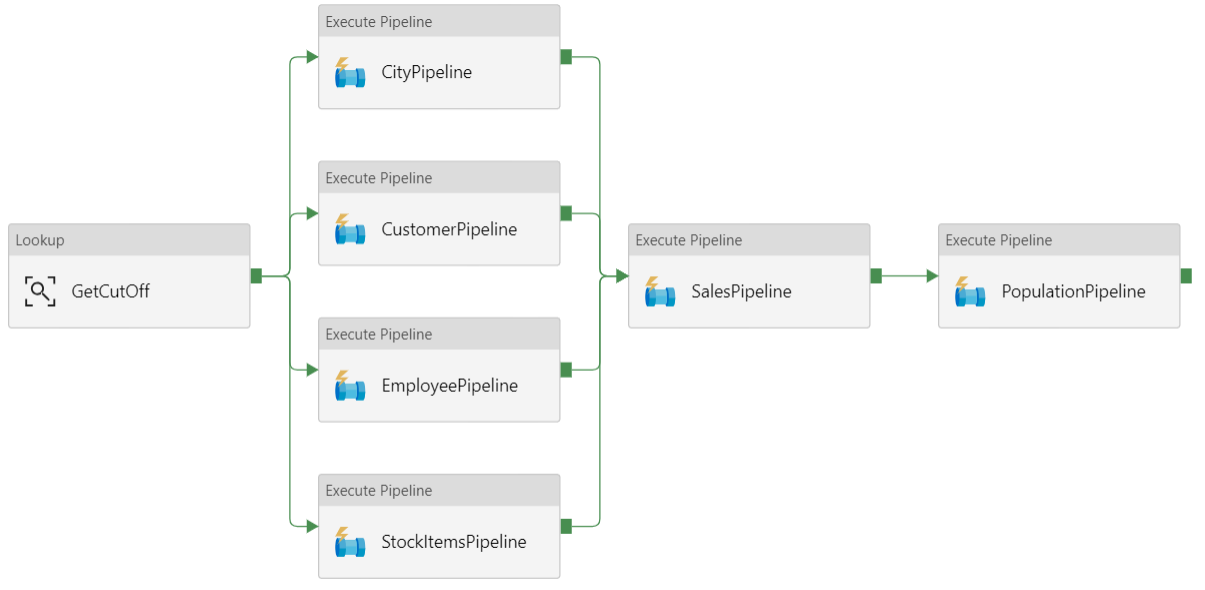
Pipeline de données
Dans Azure Data Factory, un pipeline est un regroupement logique d’activités qui permet de coordonner une tâche. Dans ce cas, il s’agit du chargement et de la transformation des données dans Azure Synapse.
Cette architecture de référence définit un pipeline parent qui exécute une suite de pipelines enfants. Chaque pipeline enfant charge les données dans une ou plusieurs tables d’entrepôt de données.
Recommandations
Chargement incrémentiel
Lorsque vous exécutez un processus ETL ou ELT automatisé, il s’avère plus efficace de charger uniquement les données modifiées depuis l’exécution précédente. Il s’agit d’un chargement incrémentiel, par opposition à un chargement complet, qui porte sur toutes les données. Pour effectuer un chargement incrémentiel, vous avez besoin d’une méthode d’identification des données modifiées. L’approche la plus courante consiste à utiliser une valeur limite supérieure, qui se traduit par le suivi de la valeur la plus récente d’une colonne de la table source, soit une colonne DateHeure, soit une colonne d’entier unique.
Depuis SQL Server 2016, vous pouvez utiliser des tables temporelles. Il s’agit de tables de système par version qui conservent un historique complet des modifications apportées aux données. Le moteur de base de données enregistre automatiquement l’historique de chaque modification dans une table d’historique distincte. Vous pouvez interroger les données d’historique en ajoutant une clause FOR SYSTEM_TIME à une requête. En interne, le moteur de base de données interroge la table d’historique, mais cette opération est transparente pour l’application.
Notes
Pour les versions antérieures de SQL Server, vous pouvez utiliser la fonction Capture des changements de données (CDC). Cette approche est moins pratique que les tables temporelles, car vous devez interroger une table de modifications distincte, et les modifications font l’objet d’un suivi par numéro séquentiel dans le journal plutôt que par horodatage.
Les tables temporelles sont utiles pour les données de dimension, qui peuvent changer au fil du temps. Les tables de faits représentent généralement une transaction immuable, comme une vente. De ce fait, il n’est pas utile de conserver l’historique des versions du système. Au lieu de cela, les transactions incluent généralement une colonne qui représente la date de transaction, qui peut être utilisée en tant que la valeur de filigrane. Par exemple, dans la base de données OLTP Wide World Importers, les tables Sales.Invoices et Sales.InvoiceLines incluent un champ LastEditedWhen dont la valeur par défaut est sysdatetime().
Voici le flux général du pipeline ELT :
Pour chaque table de la base de données source, effectuez le suivi de l’heure de coupure lors de l’exécution du dernier travail ELT. Stockez ces informations dans l’entrepôt de données. (Lors de la configuration initiale, toutes les heures sont définies sur « 1-1-1900 ».)
Lors de l’étape d’exportation des données, l’heure de coupure est transmise sous la forme d’un paramètre à un ensemble de procédures stockées dans la base de données source. Ces procédures stockées demandent au système tous les enregistrements ayant été modifiés ou créés après l’heure de coupure. Pour la table de faits Sales, la colonne
LastEditedWhenest utilisée. Dans le cas des données de dimension, les tables temporelles de système par version sont utilisées.Lorsque la migration des données est terminée, mettez à jour la table qui stocke les heures de coupure.
Il est également utile d’enregistrer un lignage pour chaque processus ELT exécuté. Pour un enregistrement donné, le lignage associe cet enregistrement avec le processus ELT exécuté qui a produit les données. Pour chaque exécution du processus ETL, un enregistrement de lignage est créé pour chaque table, montrant les heures de début et de fin du chargement. Les clés de lignage pour chaque enregistrement sont stockées dans les tables de dimension et de faits.
Lorsqu’un nouveau lot de données est chargé dans l’entrepôt de données, actualisez le modèle Analysis Services tabulaire. Voir Actualisation asynchrone avec l’API REST.
Nettoyage des données
Le nettoyage des données doit faire partie du processus ELT. Dans cette architecture de référence, la table incluant la population urbaine fournit des données incorrectes, car certaines villes sont associées à une population égale à zéro, sans doute parce qu’aucune donnée n’est disponible. Lors du traitement, le pipeline ELT supprime ces villes de la table incluant la population urbaine. Effectuez le nettoyage des données sur les tables de mise en lots plutôt que sur les tables externes.
Sources de données externes
Souvent, les entrepôts de données consolident les données provenant de plusieurs sources. Par exemple, une source de données externe qui contient des données démographiques. Ce jeu de données est disponible dans le stockage d’objets blob Azure associé à l’exemple WorldWideImportersDW.
Azure Data Factory peut copier directement les données depuis le stockage d’objets blob, à l’aide du connecteur de stockage d’objets blob. Toutefois, ce connecteur nécessite une chaîne de connexion ou d’une signature d’accès partagé, afin qu’elle ne puisse être utilisée pour copier un objet blob avec un accès en lecture public. Pour résoudre ce problème, vous pouvez utiliser PolyBase pour créer une table externe sur le stockage d’objets blob, puis copier les tables externes dans Azure Synapse.
Gestion de données binaires volumineuses
Dans la base de données source, la table Ville inclut une colonne Emplacement qui présente un type de données spatiales de zone géographique. Azure Synapse ne prend pas en charge le type geography en mode natif. Ce champ est donc converti en type varbinary pendant le chargement. (Voir Utilisation de solutions de contournement pour les types de données non pris en charge.)
Toutefois, PolyBase prend en charge une taille de colonne maximale de varbinary(8000), ce qui signifie que certaines données peuvent être tronquées. Pour résoudre ce problème, vous pouvez scinder les données en segments pendant l’exportation, puis les réassembler, comme suit :
Créez une table de mise en lots temporaire pour la colonne Location.
Pour chaque ville, fractionnez les données de localisation en segments de 8000 octets, ce qui entraîne la création de 1 à N lignes pour chaque ville.
Pour les réassembler, convertissez les lignes en colonnes avec l’opérateur T-SQL PIVOT, puis concaténez les valeurs des colonnes pour chaque ville.
La difficulté, c’est que chaque ville peut être scindée en un nombre de lignes spécifique, selon la taille des données géographiques. Pour que l’opérateur PIVOT fonctionne, chaque ville doit présenter le même nombre de lignes. À cette fin, la requête T-SQL s’efforce de remplir les lignes avec des valeurs vides, afin que chaque ville présente le même nombre de colonnes après l’exécution de l’opérateur PIVOT. La requête obtenue s’avère beaucoup plus rapide qu’un bouclage dans les lignes, au cas par cas.
La même approche est utilisée pour les données d’image.
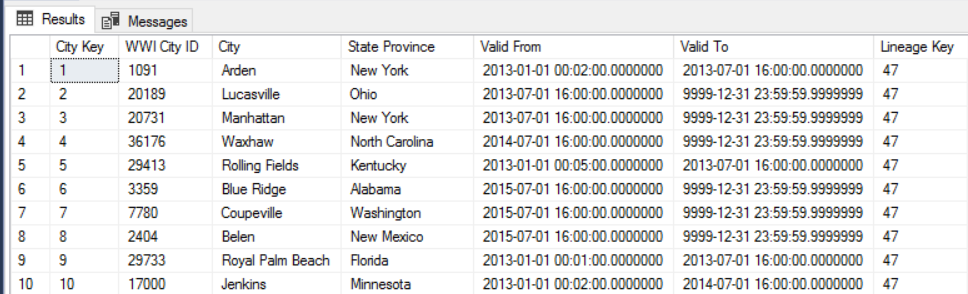
Dimensions à variation lente
Les données de dimension sont relativement statiques, mais elle peuvent changer. Par exemple, un produit peut être réaffecté à une autre catégorie. Il existe plusieurs approches permettant de gérer les dimensions à variation lente. Une technique courante, appelée Type 2, consiste à ajouter un nouvel enregistrement chaque fois qu’une dimension est modifiée.
Pour implémenter l’approche Type 2, les tables de dimension requièrent des colonnes supplémentaires, qui spécifient la plage de dates effective d’un enregistrement donné. En outre, les clés primaires de la base de données source sont dupliquées, donc la table de dimension doit avoir une clé primaire artificielle.
Par exemple, l’image suivante montre la table Dimension.City. La colonne WWI City ID est la clé primaire provenant de la base de données source. La colonne City Key est une clé artificielle générée lors du pipeline ETL. Notez également que la table inclut des colonnes Valid From et Valid To, qui définissent la plage lorsque chaque ligne était valide. Les valeurs actuelles incluent un paramètre Valid To égal à « 9999-12-31 ».
L’avantage de cette approche est qu’elle conserve les données d’historique, qui peuvent être utiles pour l’analyse. Toutefois, cela signifie également que la même entité sera associée à plusieurs lignes. Par exemple, voici les enregistrements qui correspondent à la valeur WWI City ID = 28561 :
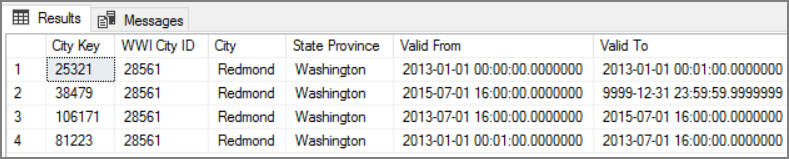
Associez chaque fait de la table Sales avec une ligne unique de la table de dimension City correspondant à la date de la facture.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Pour renforcer la sécurité, vous pouvez utiliser des points de terminaison de service de réseau virtuel pour sécuriser les ressources du service Azure à votre réseau virtuel. Cela supprime complètement tout accès Internet public à ces ressources, en autorisant le trafic uniquement à partir de votre réseau virtuel.
Grâce à cette approche, vous créez un réseau virtuel dans Azure, puis créez des points de terminaison de service privés pour les services Azure. Ces services sont ensuite limités au trafic à partir de ce réseau virtuel. Vous pouvez également y accéder à partir de votre réseau local, via une passerelle.
Notez les limitations suivantes :
Si les points de terminaison de service sont activés pour le stockage Azure, PolyBase ne peut pas copier des données à partir du stockage vers Azure Synapse. Il existe une atténuation pour ce problème. Pour en savoir plus, voir Impact de l’utilisation des points de terminaison de service de réseau virtuel avec le stockage Azure.
Pour déplacer des données locales vers le stockage Azure, vous devrez autoriser les adresses IP publiques de votre système local ou associées à ExpressRoute. Pour en savoir plus, voir Sécurisation des services Azure pour des réseaux virtuels.
Pour permettre à Analysis Services de lire les données à partir d’Azure Synapse, déployez une machine virtuelle Windows sur le réseau virtuel qui contient le point de terminaison de service Azure Synapse. Installez la passerelle de données locale Azure sur cette machine virtuelle. Ensuite, connectez votre service Azure Analysis à la passerelle de données.
DevOps
Créez des groupes de ressources distincts pour les environnements de production, de développement et de test. Des groupes de ressources distincts simplifient la gestion des déploiements, la suppression des déploiements de tests et l’attribution des droits d’accès.
Placez chaque charge de travail dans un modèle de déploiement distinct et stockez les ressources dans des systèmes de contrôle de code source. Vous pouvez déployer les modèles ensemble ou individuellement dans le cadre d'un processus CI/CD pour faciliter le processus d'automatisation.
Cette architecture comprend trois charges de travail principales :
- Le serveur d'entrepôt de données, Analysis Services, et ressources connexes.
- Azure Data Factory.
- Un scénario simulé de site local vers le cloud.
Chaque charge de travail possède son propre modèle de déploiement.
L'installation et la configuration du serveur d'entrepôt de données s'effectue à l'aide de commandes Azure CLI qui suivent l'approche impérative de la pratique IaC. Envisagez d'utiliser des scripts de déploiement et de les intégrer dans le processus d'automatisation.
Envisagez d'échelonner vos charges de travail. Déployez à différentes étapes et effectuez des vérifications de la validation à chaque étape avant de passer à l'étape suivante. Vous pourrez ainsi envoyer (push) les mises à jour de vos environnements de production de manière hautement contrôlée et limiter les problèmes de déploiement imprévus. Utilisez les stratégies Déploiement Blue-Green et Mises en production Canary pour mettre à jour les environnements de production.
Bénéficiez d'une bonne stratégie de restauration pour gérer les déploiements qui ont échoué. Par exemple, vous pouvez automatiquement relancer un déploiement antérieur réussi à partir de votre historique de déploiement. Voir le paramètre --rollback-on-error dans Azure CLI.
Azure Monitor est l'option recommandée pour analyser les performances de votre entrepôt de données et de l'ensemble de la plateforme Azure Analytics pour une expérience de supervision intégrée. Azure Synapse Analytics fournit une expérience de supervision sur le portail Azure pour présenter des insights à la charge de travail de votre entrepôt de données. Le portail Azure est l'outil recommandé pour superviser votre entrepôt de données car il offre des périodes de conservation configurables, des alertes, des suggestions, ainsi que des graphiques et des tableaux de bord personnalisables pour les métriques et les journaux d'activité.
Pour plus d'informations, consultez la section DevOps de Microsoft Azure Well-Architected Framework.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utiliser la calculatrice de prix Azure pour estimer les coûts. Les considérations suivantes s'appliquent aux services utilisés dans cette architecture de référence.
Azure Data Factory
Azure Data Factory automatise le pipeline ELT. Ce pipeline déplace les données d’une base de données SQL Server locale vers Azure Synapse. Les données sont ensuite transformées en un modèle tabulaire à des fins d’analyse. Pour ce scénario, la tarification commence à des exécutions d’activités de 0,001 $ par mois, notamment les exécutions d’activités, de déclencheur et de débogage. Ce prix est la facturation de base pour l’orchestration uniquement. Vous êtes également facturé pour les activités d’exécution, telles que la copie de données, les recherches et les activités externes. Chaque activité est facturée individuellement. Vous êtes également facturé pour les pipelines sans déclencheur associé ou les exécutions au cours du mois. Toutes les activités sont calculées au prorata par minute et arrondies vers le haut.
Exemple d’analyse des coûts
Prenons l’exemple d’un cas d’usage où deux activités de recherche proviennent de deux sources différentes. L’une d’entre elles prend 1 minute et 2 secondes (arrondies à 2 minutes), tandis que l’autre prend 1 minute, ce qui donne une durée totale de 3 minutes. Une activité de copie de données prend 10 minutes. Une activité de procédure stockée prend 2 minutes. Nombre total d’exécutions d’activités pendant 4 minutes. Cette valeur se calcule comme suit :
Exécutions d’activités : 4 * 0,001 $ = 0,004 $
Recherches : 3 * (0,005 $/60) = 0,00025 $
Procédure stockée : 2 * (0,00025 $/60) = 0,000008 $
Copie de données : 10 * (0,25 $/60) * 4 unités d’intégration de données (DIU) = 0,167 $
- Coût total par exécution de pipeline : 0,17 $.
- Exécuter une fois par jour pendant 30 jours : 5,1 $ mois.
- Exécuter une fois par jour par 100 tables pendant 30 jours : 510 $
Chaque activité a un coût associé. Comprenez le modèle de tarification et utilisez la calculatrice de prix ADF pour obtenir une solution optimisée non seulement pour les performances, mais également pour le coût. Pour gérer vos coûts, démarrez, arrêtez, suspendez et mettez à l’échelle vos services.
Azure Synapse
Azure Synapse est idéal pour des charges de travail intensives nécessitant des performances d'interrogation et des besoins de scalabilité de calcul plus importants. Vous pouvez choisir le modèle Paiement à l'utilisation ou utiliser des plans réservés d'un an (37 % d'économies) ou de 3 ans (65 % d'économies).
Le stockage de données est facturé séparément. D'autres services tels que la récupération d'urgence et la détection des menaces sont également facturés séparément.
Pour plus d'informations, consultez Tarification d'Azure Synapse.
Analysis Services
La tarification d'Azure Analysis Services dépend du niveau de service. L'implémentation de référence de cette architecture utilise le niveau Développeur, qui est recommandé pour les scénarios d'évaluation, de développement et de test. Les autres niveaux incluent le niveau De base, recommandé pour les petits environnements de production, et le niveau Standard, qui convient aux applications de production stratégiques. Pour plus d'informations, consultez Le niveau approprié, quand vous en avez besoin.
Aucuns frais ne s'appliquent lorsque vous suspendez votre instance.
Pour en savoir plus, consultez Tarification d’Azure Analysis Services.
Stockage Blob
Envisagez d'utiliser la fonctionnalité de capacité réservée Stockage Azure pour réduire les coûts de stockage. Avec ce modèle, vous bénéficiez d'une remise si vous vous engagez à réserver une capacité de stockage fixe pendant un ou trois ans. Pour plus d'informations, consultez Optimiser les coûts de stockage d'objets blob avec une capacité réservée.
Pour plus d'informations, consultez la section Coûts de Microsoft Azure Well-Architected Framework.
Étapes suivantes
- Présentation d’Azure Synapse Analytics
- Bien démarrer avec Azure Synapse Analytics
- Présentation du service Azure Data Factory
- Présentation d’Azure Data Factory
- Tutoriels Azure Data Factory
Ressources associées
Vous pouvez consulter les exemples de scénarios Azure suivants, qui décrivent des solutions spécifiques utilisant certaines de ces technologies :