Transformer des données à l’aide de l’activité de procédure stockée SQL Server dans Azure Data Factory ou Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Vous utilisez des activités de transformation dans un pipeline Data Factory ou Synapse pour transformer et traiter des données brutes en prévisions et en analyses. L’activité de procédure stockée est l’une des activités de transformation prises en charge par les pipelines. Cet article s’ajoute à l’article Transformer des données qui présente une vue d’ensemble de la transformation de données et des activités de transformation prises en charge.
Notes
Si vous découvrez Azure Data Factory, lisez la présentation d’Azure Data Factory et suivez le tutoriel : Tutoriel : Transformer des données avant de lire cet article. Pour en savoir plus sur Synapse Analytics, consultez Qu’est-ce qu’Azure Synapse Analytics.
Vous pouvez utiliser l’activité de procédure stockée pour appeler une procédure stockée dans l’une des banques de données suivantes dans votre entreprise ou sur une machine virtuelle Azure :
- Azure SQL Database
- Azure Synapse Analytics
- Base de données SQL Server Si vous utilisez SQL Server, installez le runtime d’intégration auto-hébergé sur l’ordinateur qui héberge la base de données ou sur un autre ordinateur ayant accès à la base de données. Le runtime d’intégration auto-hébergé est un composant qui connecte des sources de données locales ou se trouvant sur une machine virtuelle Azure à des services cloud de manière gérée et sécurisée. Pour plus d’informations, consultez l’article Runtime d’intégration auto-hébergé.
Important
Lorsque vous copiez des données dans Azure SQL Database ou SQL Server, vous pouvez configurer l’élément SqlSink dans l’activité de copie pour appeler une procédure stockée en utilisant la propriété sqlWriterStoredProcedureName. Pour plus d’informations sur la propriété, consultez les articles suivants sur les connecteurs : Azure SQL Database, SQL Server. L’appel d’une procédure stockée lors de la copie de données dans Azure Synapse Analytics à l’aide d’une activité de copie n’est pas pris en charge. Toutefois, vous pouvez utiliser l’activité de procédure stockée pour appeler une procédure stockée dans Azure Synapse Analytics.
Lors de la copie de données à partir d’Azure SQL Database, de SQL Server ou d’Azure Synapse Analytics, vous pouvez configurer SqlSource dans l’activité de copie pour appeler une procédure stockée afin de lire les données à partir de la base de données source en utilisant la propriété sqlReaderStoredProcedureName. Pour plus d’informations, consultez les articles suivants sur les connecteurs : Azure SQL Database, SQL Server, Azure Synapse Analytics
Lorsque la procédure stockée a des paramètres de sortie, au lieu d’utiliser l’activité de procédure stockée, utilisez l’activité de recherche et l’activité de script. L’activité de procédure stockée ne prend pas encore en charge l’appel de procédures stockées avec un paramètre de sortie.
Si vous appelez une procédure stockée avec des paramètres de sortie à l’aide d’une activité de procédure stockée, l’erreur suivante se produit.
Échec de l’exécution sur SQL Server. Contactez l’équipe SQL Server si vous avez besoin d’un support supplémentaire. Numéro d'erreur SQL : 201. Message d’erreur : La procédure ou la fonction « nom_procédure_stockée » attend le paramètre « @nom_paramètre_sortie », qui n’a pas été fourni.
Créer une activité de procédure stockée avec l’interface utilisateur
Pour utiliser une activité de procédure stockée dans un pipeline, effectuez les étapes suivantes :
Recherchez Procédure stockée dans le volet Activités du pipeline, puis faites glisser une activité de procédure stockée vers le canevas du pipeline.
Sélectionnez la nouvelle activité de procédure stockée pour le canevas si elle ne l’est pas déjà, et son onglet Paramètres pour en modifier les détails.
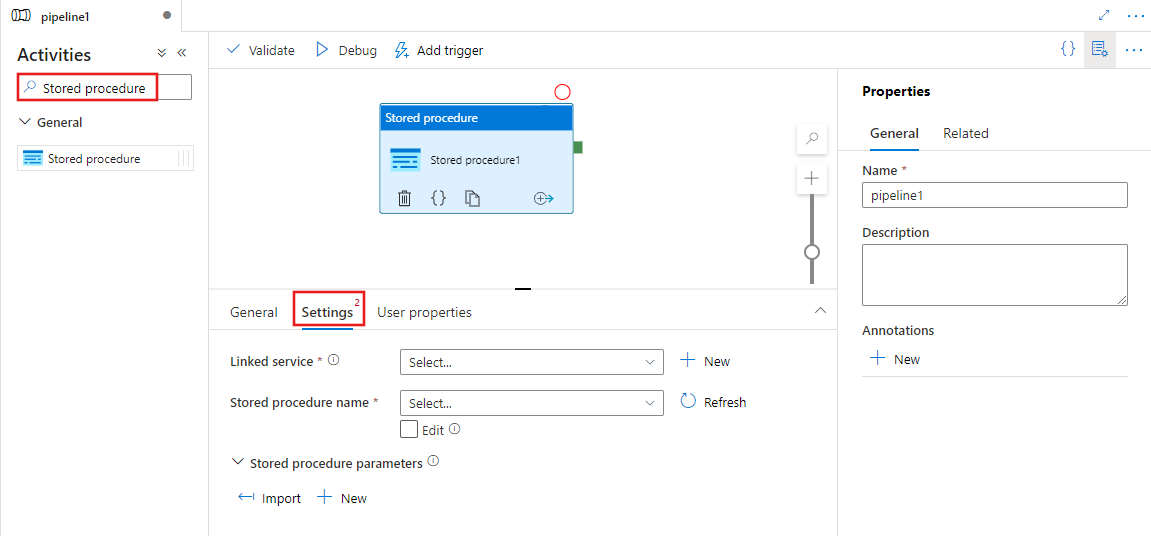
Sélectionnez un service lié existant ou créez un service lié à Azure SQL Database, Azure Synapse Analytics ou SQL Server.
Choisissez une procédure stockée et fournissez tous les paramètres pour son exécution.
Détails de la syntaxe
Voici le format JSON pour la définition d’une activité de procédure stockée :
{
"name": "Stored Procedure Activity",
"description":"Description",
"type": "SqlServerStoredProcedure",
"linkedServiceName": {
"referenceName": "AzureSqlLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"storedProcedureName": "usp_sample",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
Le tableau suivant décrit ces paramètres JSON :
| Propriété | Description | Obligatoire |
|---|---|---|
| name | Nom de l’activité | Oui |
| description | Texte décrivant la raison motivant l’activité. | Non |
| type | Pour l’activité de procédure stockée, le type d’activité est SqlServerStoredProcedure. | Oui |
| linkedServiceName | Référence au service Azure SQL Database, Azure Synapse Analytics ou SQL Server enregistré en tant que service lié dans Data Factory. Pour en savoir plus sur ce service lié, consultez l’article Services liés de calcul. | Oui |
| storedProcedureName | Spécifiez le nom de la procédure stockée à appeler. | Oui |
| storedProcedureParameters | Spécifiez les valeurs des paramètres de procédure stockée. Utilisez "param1": { "value": "param1Value","type":"param1Type" } pour transmettre les valeurs des paramètres et leur type pris en charge par la source de données. Pour passer la valeur Null en paramètre, utilisez "param1": { "value": null } (tout en minuscules). |
Non |
Mappage du type de données du paramètre
Le type de données que vous spécifiez pour le paramètre est le type de service interne correspondant à celui de la source de données que vous utilisez. Vous trouverez les mappages de types de données pour votre source de données décrits dans la documentation relative aux connecteurs. Par exemple :
- Azure Synapse Analytics
- Mappage de types de données Azure SQL Database
- Mappage de types de données Oracle
- Mappages de types de données SQL Server
Contenu connexe
Consultez les articles suivants qui expliquent comment transformer des données par d’autres moyens :