Charger de façon incrémentielle les données de plusieurs tables de SQL Server sur Azure SQL Database avec PowerShell
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous créez une fabrique de données Azure Data Factory avec un pipeline qui charge les données delta provenant de plusieurs tables d’une base de données SQL Server vers Azure SQL Database.
Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Préparer les magasins de données source et de destination.
- Créer une fabrique de données.
- Créez un runtime d’intégration auto-hébergé.
- Installer le runtime d’intégration.
- créez des services liés.
- Créer des jeux de données source, récepteur et filigrane.
- Créez, exécutez et surveillez un pipeline.
- Passez en revue les résultats.
- Ajouter ou mettre à jour des données dans les tables source.
- Réexécuter et surveiller le pipeline.
- Passer en revue les résultats finaux.
Vue d’ensemble
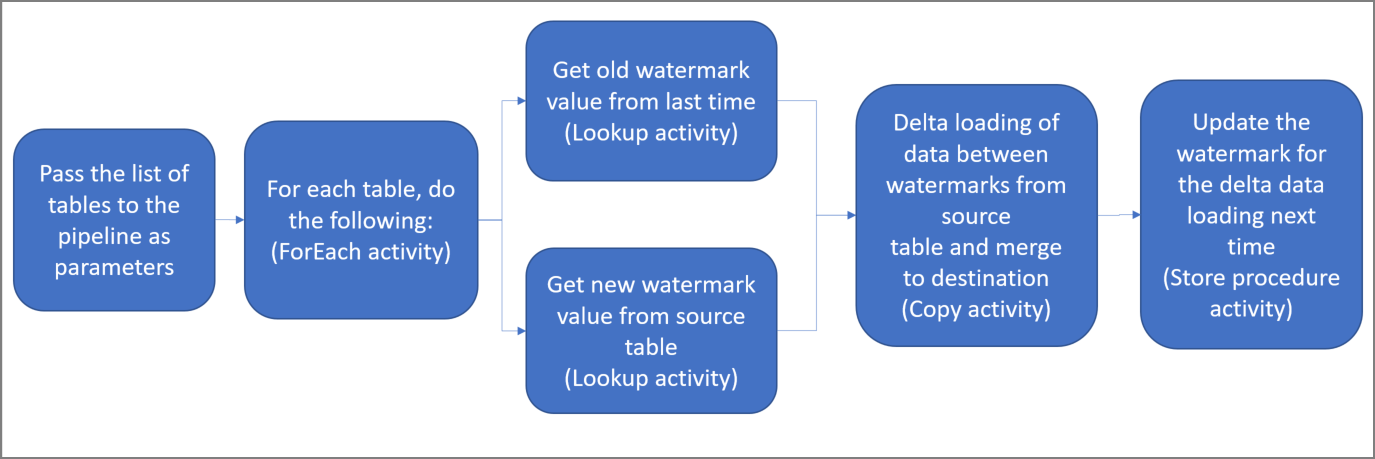
Voici les étapes importantes à suivre pour créer cette solution :
Sélectionner la colonne de limite.
Sélectionnez une colonne pour chaque table du magasin de données source, qui peut servir à identifier les enregistrements nouveaux ou mis à jour pour chaque exécution. Normalement, les données contenues dans cette colonne sélectionnée (par exemple, last_modify_time ou ID) continuent de croître à mesure que des lignes sont créées ou mises à jour. La valeur maximale de cette colonne est utilisée comme limite.
Préparer un magasin de données pour stocker la valeur de limite.
Dans ce tutoriel, la valeur de filigrane est stockée dans une base de données SQL.
Créer un pipeline avec les activités suivantes :
Créez une activité ForEach qui effectue une itération dans une liste de noms de table source qui est transmise en tant que paramètre au pipeline. Pour chaque table source, elle appelle les activités suivantes pour effectuer le chargement delta pour cette table.
Créez deux activités de recherche. Servez-vous de la première activité de recherche pour récupérer la dernière valeur de filigrane. Utilisez la deuxième activité de recherche pour récupérer la nouvelle valeur de filigrane. Ces valeurs de filigrane sont transmises à l’activité de copie.
Créez une activité de copie qui copie les lignes du magasin de données source dont la valeur de la colonne de filigrane est supérieure à l’ancienne valeur de filigrane et inférieure ou égale à la nouvelle. Elle copie ensuite les données delta du magasin de données source dans un stockage Blob Azure sous la forme d’un nouveau fichier.
Créez une activité StoredProcedure qui met à jour la valeur de filigrane pour le pipeline s’exécutant la prochaine fois.
Voici le diagramme général de la solution :
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- SQL Server. Dans le cadre de ce tutoriel, vous allez utiliser une base de données SQL Server comme magasin de données source.
- Azure SQL Database. Vous utilisez une base de données dans Azure SQL Database comme magasin de données récepteur. Si vous n’avez pas de base de données SQL, consultez Créer une base de données dans Azure SQL Database pour connaître la procédure à suivre pour en créer une.
Créer des tables sources dans votre base de données SQL Server
Ouvrez SQL Server Management Studio (SSMS) ou Azure Data Studio, puis connectez-vous à votre base de données SQL Server.
Dans Explorateur de serveurs (SSMS) ou dans le volet Connexions (Azure Data Studio) , cliquez avec le bouton droit sur la base de données, puis choisissez Nouvelle requête.
Exécutez la commande SQL suivante sur votre base de données pour créer des tables nommées
customer_tableetproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Créer des tables de destination dans votre base de données Azure SQL
Ouvrez SQL Server Management Studio (SSMS) ou Azure Data Studio, puis connectez-vous à votre base de données SQL Server.
Dans Explorateur de serveurs (SSMS) ou dans le volet Connexions (Azure Data Studio) , cliquez avec le bouton droit sur la base de données, puis choisissez Nouvelle requête.
Exécutez la commande SQL suivante sur votre base de données pour créer des tables nommées
customer_tableetproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Créer une autre table dans Azure SQL Database pour stocker la valeur de limite supérieure
Exécutez la commande SQL suivante sur votre base de données pour créer une table sous le nom
watermarktableet y stocker la valeur de limite supérieure :create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Insérer des valeurs de limite supérieure initiale pour les deux tables source dans la table de limite supérieure.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Créer une procédure stockée dans la base de données Azure SQL
Exécutez la commande suivante pour créer une procédure stockée dans votre base de données. Cette procédure stockée met à jour la valeur de filigrane après chaque exécution du pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Créer des types de données et des procédures stockées supplémentaires dans Azure SQL Database
Exécutez la requête suivante pour créer deux procédures stockées et deux types de données dans votre base de données. Ils sont utilisés pour fusionner les données des tables source dans les tables de destination.
Afin de faciliter le démarrage du parcours, nous utilisons directement ces procédures stockées en transmettant les données delta par l’intermédiaire d’une variable de table, puis nous les fusionnons dans le magasin de destination. Faites attention qu’il ne s’attende pas à ce qu’un nombre « élevé » de lignes delta (plus de 100) soient stockées dans la variable de table.
Si vous n’avez pas besoin de fusionner un grand nombre de lignes delta dans le magasin de destination, nous vous suggérons d’utiliser d’abord l’activité de copie pour copier toutes les données delta dans une table « temporaire » dans le magasin de destination, puis de créer votre propre procédure stockée sans utiliser la variable de table pour les fusionner de la table « temporaire » dans la table « finale ».
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Installez les modules Azure PowerShell les plus récents en suivant les instructions décrites dans Installation et configuration d’Azure PowerShell.
Créer une fabrique de données
Définissez une variable pour le nom du groupe de ressources que vous utiliserez ultérieurement dans les commandes PowerShell. Copiez le texte de commande suivant dans PowerShell, spécifiez un nom pour le groupe de ressources Azure entre des guillemets doubles, puis exécutez la commande. par exemple
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Si le groupe de ressources existe déjà, vous pouvez ne pas le remplacer. Attribuez une valeur différente à la variable
$resourceGroupName, puis réexécutez la commande.Définissez une variable pour l’emplacement de la fabrique de données.
$location = "East US"Pour créer le groupe de ressources Azure, exécutez la commande suivante :
New-AzResourceGroup $resourceGroupName $locationSi le groupe de ressources existe déjà, vous pouvez ne pas le remplacer. Attribuez une valeur différente à la variable
$resourceGroupName, puis réexécutez la commande.Définissez une variable pour le nom de la fabrique de données.
Important
Mettez à jour le nom de la fabrique de données pour le rendre globalement unique. Par exemple, ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Pour créer la fabrique de données, exécutez la cmdlet Set-AzDataFactoryV2 suivante :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Notez les points suivants :
Le nom de la fabrique de données doit être un nom global unique. Si vous recevez l’erreur suivante, changez le nom, puis réessayez :
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Pour créer des instances Data Factory, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit être membre des rôles Contributeur ou Propriétaire, ou administrateur de l’abonnement Azure.
Pour obtenir la liste des régions Azure dans lesquelles Data Factory est actuellement disponible, sélectionnez les régions qui vous intéressent dans la page suivante, puis développez Analytique pour localiser Data Factory : Disponibilité des produits par région. Les magasins de données (Stockage Azure, SQL Database, SQL Managed Instance, etc.) et les services de calcul (Azure HDInsight, etc.) utilisés par la fabrique de données peuvent se trouver dans d’autres régions.
Créer un runtime d’intégration auto-hébergé
Dans cette section, vous allez créer un runtime d’intégration auto-hébergé et l’associer à un ordinateur local avec la base de données SQL Server. Le runtime d’intégration auto-hébergé est le composant qui copie les données de SQL Server sur votre machine vers Azure SQL Database.
Créez une variable pour le nom du runtime d’intégration. Utilisez un nom unique et notez-le. Vous l’utiliserez ultérieurement dans ce tutoriel.
$integrationRuntimeName = "ADFTutorialIR"Créez un runtime d’intégration auto-hébergé.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameVoici l'exemple de sortie :
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRExécutez la commande suivante pour récupérer l’état du runtime d’intégration créé : Vérifiez que la valeur de la propriété État est définie sur NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusVoici l'exemple de sortie :
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Exécutez la commande suivante pour récupérer les clés d’authentification permettant d’enregistrer le runtime d’intégration auto-hébergé auprès du service Azure Data Factory dans le cloud :
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonVoici l'exemple de sortie :
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Copiez l’une des clés (sans les guillemets) pour enregistrer le runtime d’intégration auto-hébergé que vous allez installer sur votre ordinateur à l’étape suivante.
Installer l’outil Integration Runtime
Si le runtime d’intégration est déjà installé sur votre machine, désinstallez-le à l’aide de Ajouter ou supprimer des programmes.
Téléchargez le runtime d’intégration auto-hébergé sur un ordinateur Windows local. Exécutez l’installation.
Sur la page Bienvenue dans l’assistant d’installation de Microsoft Integration Runtime, cliquez sur Suivant.
Sur la page Contrat de Licence utilisateur final, acceptez les conditions et le contrat de licence, puis cliquez sur Suivant.
Sur la page Dossier de destination, cliquez sur Suivant.
Sur la page Prêt à installer Microsoft Integration Runtime, cliquez sur Installer.
Sur la page Assistant d’installation de Microsoft Integration Runtime terminé, cliquez sur Terminer.
Sur la page Inscrire le Integration Runtime (auto-hébergé) , collez la clé que vous avez enregistrée dans la section précédente, puis cliquez sur Inscrire.
Dans la page Nouveau runtime d’intégration (auto-hébergé) , sélectionnez Terminer.
Le message suivant s’affiche une fois que le runtime d’intégration auto-hébergé est bien inscrit :
Sur la page Inscrire le runtime d’intégration (auto-hébergé) , cliquez sur Lancer le Gestionnaire de configuration.
La page suivante apparaît une fois que le nœud est connecté au service cloud :
Maintenant, testez la connectivité à votre base de données SQL Server.
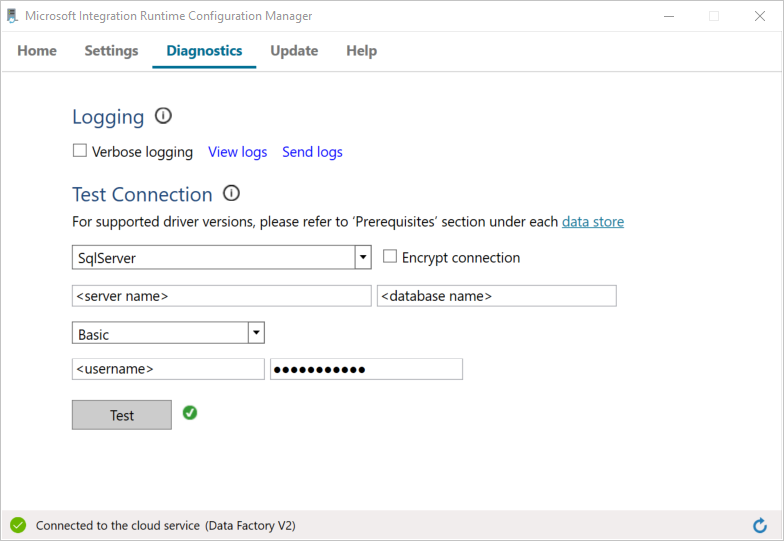
a. Sur la page Gestionnaire de configuration, accédez à l’onglet Diagnostics.
b. Sélectionnez SqlServer comme type de source de données.
c. Saisissez le nom du serveur.
d. Saisissez le nom de la base de données.
e. Sélectionnez le mode d’authentification.
f. Entrer le nom d'utilisateur.
g. Entrez le mot de passe associé au nom d’utilisateur.
h. Cliquez sur Tester pour vérifier que le runtime d’intégration se connecte à SQL Server. Une coche verte apparaît si la connexion est établie. Un message d’erreur apparaît si la connexion échoue. Corrigez les problèmes et assurez-vous que le runtime d’intégration peut se connecter au serveur SQL Server.
Notes
Notez les valeurs pour le type d’authentification, le serveur, la base de données, l’utilisateur et le mot de passe. Vous les utiliserez ultérieurement dans ce didacticiel.
Créez des services liés
Vous allez créer des services liés dans une fabrique de données pour lier vos magasins de données et vos services de calcul à la fabrique de données. Dans cette section, vous créez des services liés à votre base de données SQL Server et à votre base de données dans Azure SQL Database.
Créer le service lié SQL Server
Dans cette étape, vous liez votre base de données SQL Server à la fabrique de données.
Créez un fichier JSON nommé SqlServerLinkedService.json dans le dossier C:\ADFTutorials\IncCopyMultiTableTutorial (créez les dossiers locaux s’ils n’existent pas déjà) avec le contenu suivant. Sélectionnez la section appropriée en fonction de l’authentification utilisée pour vous connecter à SQL Server.
Important
Sélectionnez la section appropriée en fonction de l’authentification utilisée pour vous connecter à SQL Server.
Si vous utilisez l’authentification SQL, copiez la définition JSON suivante :
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Si vous utilisez l’authentification Windows, copiez la définition JSON suivante :
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Important
- Sélectionnez la section appropriée en fonction de l’authentification utilisée pour vous connecter à SQL Server.
- Remplacez <integration runtime name> par le nom de votre runtime d’intégration.
- Remplacez <servername>, <databasename>, <username> et <password> par les valeurs de votre base de données SQL Server avant d’enregistrer le fichier.
- Si vous avez besoin d’utiliser une barre oblique (
\) dans votre nom de serveur ou de compte d’utilisateur, utilisez le caractère d’échappement (\). par exemplemydomain\\myuser.
Dans PowerShell, exécutez l’applet de commande suivante pour passer au dossier C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Exécutez la cmdlet Set-AzDataFactoryV2LinkedService pour créer le service lié AzureStorageLinkedService. Dans l’exemple suivant, vous transmettez les valeurs des paramètres ResourceGroupName et DataFactoryName :
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Voici l'exemple de sortie :
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Créer le service lié SQL Database
Créez un fichier JSON nommé AzureSQLDatabaseLinkedService.json dans le dossier C:\ADFTutorials\IncCopyMultiTableTutorial avec le contenu suivant. (Créez le dossier ADF s’il n’existe pas déjà.) Remplacez <servername>, <database name>, <user name> et <password> par le nom de votre serveur de base de données SQL Server, le nom de votre base de données, le nom d’utilisateur et le mot de passe avant d’enregistrer le fichier.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }Dans PowerShell, exécutez la cmdlet Set-AzDataFactoryV2LinkedService pour créer le service lié AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Voici l'exemple de sortie :
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Créez les jeux de données
Dans cette étape, vous créez des jeux de données pour représenter la source de données, la destination des données et l’emplacement de stockage du filigrane.
Créer un jeu de données source
Créez un fichier JSON sous le nom SourceDataset.json dans le même dossier avec le contenu suivant :
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }L’activité de copie dans le pipeline utilise une requête SQL pour charger les données plutôt que de charger l’ensemble de la table.
Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Créer un jeu de données récepteur
Créez un fichier JSON nommé SinkDataset.json dans le même dossier avec le contenu suivant. L’élément tableName est défini par le pipeline de manière dynamique lors de l’exécution. L’activité ForEach du pipeline effectue une itération dans une liste de noms de table et transmet le nom de table à ce jeu de données à chaque itération.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Créer un jeu de données pour un filigrane
Dans cette étape, vous allez créer un jeu de données pour stocker une valeur de limite supérieure.
Créez un fichier JSON nommé WatermarkDataset.json dans le même dossier avec le contenu suivant :
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Exécutez la cmdlet Set-AzDataFactoryV2Dataset pour créer le jeu de données WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Voici l’exemple de sortie de l’applet de commande :
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Créer un pipeline
Ce pipeline prend une liste de noms de tables comme paramètre. L’activité ForEach effectue une itération dans la liste des noms de table et effectue les opérations suivantes :
Utilisez l’activité Rechercher pour récupérer la valeur de l’ancienne limite (la valeur initiale ou celle utilisée dans la dernière itération).
Utilisez l’activité Rechercher pour récupérer la valeur de la nouvelle limite (la valeur maximale de la colonne de limite dans la table source).
Utilisez l’activité Copier pour copier les données entre ces deux valeurs de limite depuis la base de données source vers la base de données de destination.
Utilisez l’activité StoredProcedure pour mettre à jour l’ancienne valeur de la limite à utiliser dans la première étape de l’itération suivante.
Créer le pipeline
Créez un fichier JSON nommé IncrementalCopyPipeline.json dans le même dossier avec le contenu suivant :
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Exécutez la cmdlet Set-AzDataFactoryV2Pipeline pour créer le pipeline IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Voici l'exemple de sortie :
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Exécuter le pipeline
Créez un fichier de paramètres nommé Parameters.json dans le même dossier avec le contenu suivant :
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Exécutez le pipeline IncrementalCopyPipeline en utilisant la cmdlet Invoke-AzDataFactoryV2Pipeline. Remplacez les espaces réservés par les noms de votre groupe de ressources et de votre fabrique de données.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Surveiller le pipeline
Connectez-vous au portail Azure.
Sélectionnez Tous les services, effectuez une recherche avec le mot clé Fabriques de données, puis sélectionnez Fabriques de données.
Recherchez votre fabrique de données dans la liste des fabriques de données, puis sélectionnez-la pour ouvrir la page Fabrique de données.
Dans la page Fabrique de données, sélectionnez Ouvrir sur la vignette Ouvrir Azure Data Factory Studio pour lancer Azure Data Factory dans un onglet distinct.
Dans la page d’accueil d’Azure Data Factory, sélectionnez Superviser sur le côté gauche.

Vous pouvez voir toutes les exécutions de pipeline et leurs états. Notez que dans l’exemple suivant, l’état d’exécution de pipeline est Réussite. Pour vérifier les paramètres transmis au pipeline, sélectionnez le lien dans la colonne Paramètres. Si une erreur s’est produite, un lien figure dans la colonne Erreur.

Si vous sélectionnez le lien dans la colonne Actions, vous voyez toutes les exécutions d’activité du pipeline.
Pour revenir à la vue Exécutions de pipeline, sélectionnez Toutes les exécutions de pipeline.
Passer en revue les résultats.
Dans SQL Server Management Studio, exécutez les requêtes suivantes sur la base de données SQL cible pour vérifier que les données ont été copiées à partir des tables source vers les tables de destination :
Requête
select * from customer_table
Sortie
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Requête
select * from project_table
Sortie
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Requête
select * from watermarktable
Sortie
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Notez que les valeurs de filigrane des deux tables ont été mises à jour.
Ajouter plus de données aux tables sources
Exécutez la requête suivante sur la base de données SQL Server source pour mettre à jour une ligne existante dans customer_table. Insérez une nouvelle ligne dans project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Exécutez à nouveau le pipeline
Maintenant, exécutez à nouveau le pipeline à l’aide de la commande PowerShell suivante :
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Analysez les exécutions du pipeline en suivant les instructions indiquées dans la section Surveiller le pipeline. Quand l’état du pipeline est En cours, vous voyez un autre lien d’action sous Actions pour annuler l’exécution du pipeline.
Sélectionnez Actualiser pour actualiser la liste jusqu’à ce que l’exécution du pipeline réussisse.
Sélectionnez éventuellement le lien Afficher les exécutions du pipeline sous Actions pour voir toutes les exécutions d’activité associées à l’exécution de ce pipeline.
Passer en revue les résultats finaux
Dans SQL Server Management Studio, exécutez les requêtes suivantes sur la base de données cible pour vérifier que les données nouvelles/mises à jour ont été copiées à partir des tables sources vers les tables de destination.
Requête
select * from customer_table
Sortie
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Notez les nouvelles valeurs de Name et LastModifytime pour le PersonID du numéro 3.
Requête
select * from project_table
Sortie
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Notez que l’entrée NewProject a été ajoutée à project_table.
Requête
select * from watermarktable
Sortie
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Notez que les valeurs de filigrane des deux tables ont été mises à jour.
Contenu connexe
Dans ce tutoriel, vous avez effectué les étapes suivantes :
- Préparer les magasins de données source et de destination.
- Créer une fabrique de données.
- Créer un runtime d’intégration auto-hébergé (IR).
- Installer le runtime d’intégration.
- créez des services liés.
- Créer des jeux de données source, récepteur et filigrane.
- Créez, exécutez et surveillez un pipeline.
- Passez en revue les résultats.
- Ajouter ou mettre à jour des données dans les tables source.
- Réexécuter et surveiller le pipeline.
- Passer en revue les résultats finaux.
Passez au tutoriel suivant pour en savoir plus sur la transformation des données en utilisant un cluster Spark sur Azure :