Sortie Azure Stream Analytics dans Azure Cosmos DB
Azure Stream Analytics peut générer des données au format JSON pour Azure Cosmos DB. Il permet un archivage des données et des requêtes à faible latence sur des données JSON non structurées. Cet article décrit quelques bonnes pratiques pour l’implémentation de cette configuration (Stream Analytics vers Cosmos DB). Si vous n’êtes pas familiarisé avec Azure Cosmos DB, consultez la documentation Azure Cosmos DB pour commencer.
Remarque
- À ce stade, Stream Analytics prend en charge la connexion à Azure Cosmos DB uniquement via l’API SQL. Les autres API Azure Cosmos DB ne sont pas encore prises en charge. Si vous pointez Stream Analytics vers les comptes Azure Cosmos DB créés avec d’autres API, les données risquent de ne pas être correctement stockées.
- Nous vous recommandons de définir votre travail sur le niveau de compatibilité 1.2 lorsque vous utilisez Azure Cosmos DB comme sortie.
Principes de base d’Azure Cosmos DB en tant que cible de sortie
La sortie Azure Cosmos DB dans Stream Analytics vous permet d’écrire les résultats du traitement de votre flux en tant que sortie JSON dans vos conteneurs Azure Cosmos DB. Stream Analytics ne crée pas de conteneurs dans votre base de données. Au lieu de cela, vous devez les créer au préalable. Vous pouvez ensuite contrôler les coûts de facturation des conteneurs Azure Cosmos DB. Vous pouvez également régler les performances, la cohérence et la capacité de vos conteneurs directement à l’aide des API Azure Cosmos DB. Les sections suivantes détaillent certaines des options de conteneur pour Azure Cosmos DB.
Réglage de la cohérence, de la disponibilité et de la latence
Pour respecter les exigences de votre application, Azure Cosmos DB vous permet d’ajuster la base de données et les conteneurs, et de faire les meilleurs compromis entre cohérence, disponibilité, latence et débit.
Selon les niveaux de cohérence de lecture qui s’appliquent à votre scénario compte tenu de la latence de lecture et d’écriture, vous pouvez choisir un niveau de cohérence sur votre compte de base de données. Vous pouvez améliorer le débit en augmentant les unités de requête (RU) sur le conteneur. Par défaut, Azure Cosmos DB permet également une indexation synchrone sur chaque opération CRUD exécutée sur votre conteneur. Cette option aussi est utile pour contrôler les performances de lecture ou d’écriture dans Azure Cosmos DB. Pour plus d’informations, consultez l’article Modifier le niveau de cohérence des bases de données et des requêtes.
Upserts à partir de Stream Analytics
L’intégration de Stream Analytics à Azure Cosmos DB vous permet d’insérer ou mettre à jour des enregistrements dans votre conteneur à partir d’une colonne d’identification de document donnée. Cette opération est également appelée upsert. Stream Analytics utilise une approche upsert optimiste. Les mises à jour se produisent uniquement en cas d’échec d’une insertion avec un conflit d’ID de document.
Avec le niveau de compatibilité 1.0, Stream Analytics effectue cette mise à jour en tant qu’opération PATCH, ce qui permet des mises à jour partielles du document. Stream Analytics ajoute de nouvelles propriétés ou remplace une propriété existante de manière incrémentielle. Toutefois, les modifications apportées aux valeurs des propriétés du tableau dans votre document JSON ont pour effet d’écraser l’intégralité du tableau. Autrement dit, le tableau n’est pas fusionné.
Avec le niveau 1.2, le comportement de l'opération upsert est modifié pour insérer ou remplacer le document. La section ultérieure sur le niveau de compatibilité 1.2 décrit plus en détail ce comportement.
Si le document JSON entrant contient un champ ID existant, ce champ est automatiquement utilisé comme colonne ID de document dans Azure Cosmos DB. Toutes les écritures suivantes sont traitées comme telles, ce qui conduit à l’une des situations suivantes :
- Des ID uniques aboutissent à une insertion.
- Des ID dupliqués et ID du document défini sur ID aboutissent à une opération upsert.
- Des ID dupliqués et ID du document non défini aboutissent à une erreur après le premier document.
Si vous souhaitez enregistrer tous les documents, notamment ceux dont l’ID est dupliqué, renommez le champ ID dans votre requête (à l’aide du mot clé AS). Laissez Azure Cosmos DB créer le champ ID ou remplacer l’ID par la valeur d’une autre colonne (en utilisant le mot clé AS ou en utilisant le paramètre ID de document).
Partitionnement des données dans Azure Cosmos DB
Azure Cosmos DB ajuste automatiquement les partitions en fonction de votre charge de travail. Nous vous recommandons donc d’utiliser des conteneurs illimités pour le partitionnement de vos données. Pendant une opération d’écriture dans des conteneurs illimités, Stream Analytics utilise autant d’enregistreurs parallèles que l’étape de requête précédente ou le schéma de partitionnement d’entrée.
Notes
Azure Stream Analytics prend uniquement en charge un nombre illimité de conteneurs avec des clés de partition au niveau supérieur. Par exemple, la clé de partition /region est prise en charge. Les clés de partition imbriquées (par exemple, /region/name) ne sont pas prises en charge.
Selon votre choix de clé de partition, vous pourrez recevoir cet avertissement :
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Il est important de choisir une propriété de clé de partition présentant de nombreuses valeurs distinctes, et vous permettant de distribuer votre charge de travail uniformément entre ces valeurs. Conséquence inhérente du partitionnement, les demandes impliquant la même clé de partition sont limitées par le débit maximal d’une seule partition.
La taille de stockage des documents appartenant à la même valeur de clé de partition est limitée à 20 Go (la limite de taille de partition physique est de 50 Go). Une clé de partition idéale apparaît fréquemment sous forme de filtre dans vos requêtes efficaces et possède une cardinalité suffisante pour garantir la scalabilité de votre solution.
Les clés de partition utilisées pour les requêtes Stream Analytics et Azure Cosmos DB n’ont pas besoin d’être identiques. Les topologies entièrement parallèles recommandent l’utilisation d’une clé de partition d’entrée, PartitionId, comme clé de partition de la requête Stream Analytics, mais ce n’est peut-être pas le choix recommandé pour la clé de partition d’un conteneur Azure Cosmos DB.
Une clé de partition sert également de limite pour les transactions dans les procédures stockées et les déclencheurs d’Azure Cosmos DB. Vous devez choisir la clé de partition de sorte que les documents impliqués dans les mêmes transactions partagent la même valeur de clé de partition. L’article Partitionnement des données dans Azure Cosmos DB fournit des détails supplémentaires sur le choix d’une clé de partition.
Pour les conteneurs Azure Cosmos DB fixes arrivés à saturation, Stream Analytics n’offre pas de possibilité de Scale-up ou de Scale-out. Ils ont une limite maximale de 10 Go et un débit de 10 000 RU/s. Pour migrer les données d’un conteneur fixe vers un conteneur illimité (par exemple avec au moins 1 000 RU/s et une clé de partition), utilisez l’outil de migration de données ou la bibliothèque de flux de modification.
La fonctionnalité permettant d’écrire dans plusieurs conteneurs fixes est dépréciée. Nous ne la recommandons pas pour le Scale-out de votre travail Stream Analytics.
Débit amélioré avec le niveau de compatibilité 1.2
Avec le niveau de compatibilité 1.2, Stream Analytics prend en charge l’intégration native pour écrire en bloc dans Azure Cosmos DB. Cette intégration permet d’écrire efficacement dans Azure Cosmos DB tout en optimisant le débit et en gérant efficacement les requêtes de limitation.
Le mécanisme d’écriture amélioré est disponible sous un nouveau niveau de compatibilité en raison d’une différence de comportement de l’opération upsert. Avec les niveaux antérieurs au niveau 1.2, le comportement de l’opération upsert consiste à insérer ou fusionner le document. Avec le niveau 1.2, le comportement de l'opération upsert est modifié pour insérer ou remplacer le document.
Avec les niveaux antérieurs au niveau 1.2, Stream Analytics utilise une procédure stockée personnalisée pour exécuter en bloc l’opération upsert sur les documents par clé de partition dans Azure Cosmos DB. À partir de là, un lot est écrit sous la forme d’une transaction. Si un seul enregistrement se heurte à une erreur temporaire (limitation), le lot dans son intégralité doit faire l’objet d’une nouvelle tentative. Ce comportement ralentit considérablement des scénarios présentant tout de même des limitations raisonnables.
L’exemple suivant montre deux travaux Stream Analytics identiques lisant à partir de la même entrée Azure Event Hubs. Les deux travaux Stream Analytics sont entièrement partitionnés avec une requête passthrough et écrivent dans des conteneurs Azure Cosmos DB identiques. Les métriques de gauche proviennent du travail configuré avec le niveau de compatibilité 1.0. Les métriques de droite sont configurées avec le niveau 1.2. La clé de partition d’un conteneur Azure Cosmos DB est un GUID unique issu de l’événement d’entrée.
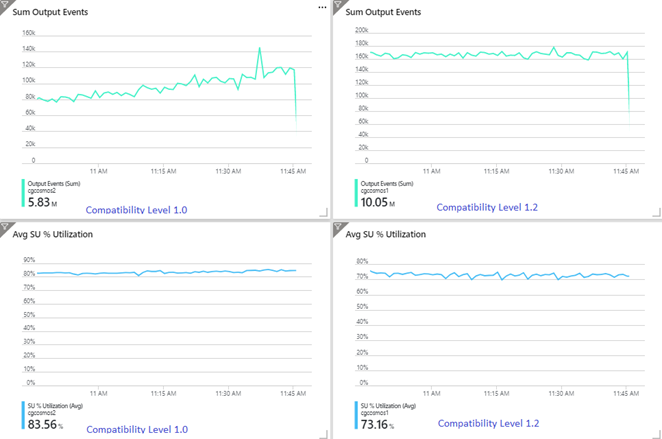
Le taux d’événements entrants dans Event Hubs est deux fois supérieur à ce que les conteneurs Azure Cosmos DB (20 000 RU) sont configurés pour recevoir, et dès lors une limitation est à prévoir dans Azure Cosmos DB. Cela étant, le travail configuré avec le niveau 1.2 écrit de manière cohérente à un débit plus élevé (événements de sortie par minute) et avec une utilisation SU% moyenne moins élevée. Dans votre environnement, cette différence dépend de quelques facteurs supplémentaires. Ces facteurs incluent le choix du format d’événement, la taille de l’événement/du message d’entrée, les clés de partition et la requête.
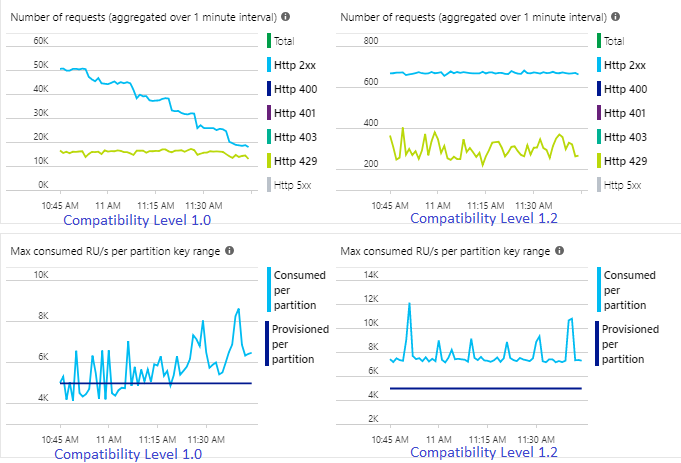
Avec le niveau de compatibilité 1.2, Stream Analytics utilise de manière plus intelligente 100 % du débit disponible dans Azure Cosmos DB, avec peu de nouvelles soumissions dues aux limitations. Ce comportement permet une meilleure expérience pour les autres charges de travail telles que les requêtes exécutées simultanément sur le conteneur. Si vous souhaitez voir le Scale-out de Stream Analytics avec Azure Cosmos DB en tant que récepteur pour 1 000 à 10 000 messages par seconde, essayez cet exemple de projet Azure.
Le débit de sortie Azure Cosmos DB est identique avec les niveaux 1.0 et 1.1. Nous vous recommandons fortement d’utiliser le niveau de compatibilité 1.2 dans Stream Analytics avec Azure Cosmos DB.
Paramètres Azure Cosmos DB pour la sortie JSON
Lorsque vous utilisez Azure Cosmos DB en tant que sortie dans Stream Analytics, vous devez fournir des informations supplémentaires, comme indiqué ci-dessous.
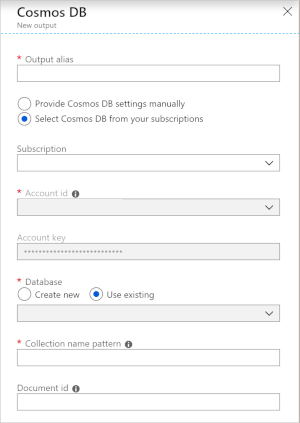
| Champ | Description |
|---|---|
| Alias de sortie | Alias référençant cette sortie dans votre requête Stream Analytics. |
| Abonnement | Abonnement Azure. |
| ID de compte | Nom ou URI de point de terminaison du compte Azure Cosmos DB. |
| Clé de compte | Clé d’accès partagé du compte Azure Cosmos DB. |
| Base de données | Nom de la base de données Azure Cosmos DB. |
| Nom du conteneur | Nom du conteneur, comme MyContainer. Un conteneur nommé MyContainer doit exister. |
| ID du document | facultatif. Nom de colonne dans les événements de sortie utilisé comme clé unique sur laquelle doivent être basées les opérations d’insertion ou de mise à jour. Si vous laissez ce champ vide, tous les événements sont insérés, sans option de mise à jour. |
Une fois la sortie Azure Cosmos DB configurée, elle peut être utilisée dans la requête en tant que cible d’une instruction INTO. Lors de l’utilisation d’une sortie Azure Cosmos DB de cette manière, une clé de partition doit être définie explicitement.
L’enregistrement de sortie doit contenir une colonne qui respecte la casse nommée d’après la clé de partition dans Azure Cosmos DB. Pour obtenir une plus grande parallélisation, l’instruction peut exiger une clause PARTITION BY utilisant la même colonne.
Voici un exemple de requête :
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Gestion des erreurs et nouvelles tentatives
En cas de panne transitoire, d’indisponibilité du service ou de limitation de bande passante lors de l’envoi d’événements à Azure Cosmos DB, Stream Analytics effectue de nouvelles tentatives indéfiniment pour mener à bien l’opération. Mais il n’effectue pas de nouvelles tentatives pour les échecs suivants :
- Unauthorized (code d’erreur HTTP 401)
- NotFound (code d’erreur HTTP 404)
- Forbidden (code d’erreur HTTP 403)
- BadRequest (code d’erreur HTTP 400)
Problèmes courants
Une contrainte d’index unique est ajoutée à la collection et les données de sortie de Stream Analytics enfreignent cette contrainte. Assurez-vous que les données de sortie de Stream Analytics ne violent pas de contraintes uniques ou supprimez les contraintes. Pour plus d’informations, consultez Contraintes de clé unique dans Azure Cosmos DB.
La colonne
PartitionKeyn’existe pas.La colonne
Idn’existe pas.