Détecter un problème les problèmes de performance avec Intelligent Insights : Azure SQL Database et Azure SQL Managed Instance
S’applique à : ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cette page fournit des informations sur les problèmes de performances liés à Azure SQL Database et Azure SQL Managed Instance détectés par le biais du journal de ressources Intelligent Insights. Les métriques et journaux de ressources peuvent être transmis en streaming aux journaux Azure Monitor, à Azure Event Hubs, au Stockage Azure ou à une solution tierce afin de bénéficier de fonctionnalités d’alertes et de rapports DevOps personnalisées.
Notes
Pour appréhender rapidement la résolution des problèmes de performances à l’aide d’Intelligent Insights, consultez l’organigramme Flux de résolution des problèmes recommandé dans le présent document.
Intelligent Insights est une fonctionnalité en préversion qui n’est pas disponible dans les régions suivantes : Europe Ouest, Europe Nord, USA Ouest 1 et USA Est 1.
Modèles de performances de base de données détectables
Intelligent Insights détecte automatiquement les problèmes de performances en fonction des temps d’attente d’exécution des requêtes, des erreurs ou des expirations de délais d’attente. Intelligent Insights génère les modèles de performance détectés dans le journal des ressources. Les modèles de performances détectables sont résumés dans le tableau ci-dessous.
| Modèles de performances détectables | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Atteinte des limites de ressources | La consommation des ressources disponibles (DTU), les threads de travail de base de données ou les sessions de connexion de base de données disponibles sur l’abonnement surveillé ont atteint leurs limites de ressources. Cela affecte les performances. | La consommation des ressources de l’UC atteint les limites de ressources. Ce phénomène affecte les performances de la base de données. |
| Augmentation de la charge de travail | Une augmentation de la charge de travail ou une accumulation continue de la charge de travail sur la base de données a été détectée. Cela affecte les performances. | Une augmentation de la charge de travail a été détectée. Ce phénomène affecte les performances de la base de données. |
| Sollicitation de la mémoire | Les rôles de travail qui ont demandé des allocations de mémoire doivent attendre celles-ci pendant des périodes statistiquement importantes, faute de quoi les demandes d’allocations de mémoire des rôles de travail ne cessent de s’accumuler. Cela affecte les performances. | Les threads de travail qui ont demandé des allocations de mémoire attendent pendant un intervalle de temps statistiquement important. Ce phénomène affecte les performances de la base de données. |
| Verrouillage | Un verrouillage excessif de la base de données a été détecté, ce qui affecte les performances. | Un verrouillage excessif de la base de données a été détecté, ce qui affecte les performances de la base de données. |
| Augmentation de MAXDOP | L’option relative au degré maximal de parallélisme (MAXDOP) a été modifiée, ce qui affecte l’efficacité de l’exécution des requêtes. Cela affecte les performances. | L’option relative au degré maximal de parallélisme (MAXDOP) a été modifiée, ce qui affecte l’efficacité de l’exécution des requêtes. Cela affecte les performances. |
| Contention de verrous de page | Plusieurs threads tentent simultanément d’accéder aux mêmes pages de tampon de données en mémoire, ce qui augmente les temps d’attente et entraîne la contention de verrous de page. Cela affecte les performances. | Plusieurs threads tentent simultanément d’accéder aux mêmes pages de tampon de données en mémoire, ce qui augmente les temps d’attente et entraîne la contention de verrous de page. Ce phénomène affecte les performances de la base de données. |
| Index manquant | L’absence d’index a été détectée, ce qui affecte les performances. | L’absence d’index a été détectée, ce qui affecte les performances de la base de données. |
| Nouvelle requête | Une nouvelle requête a été détectée, ce qui affecte les performances. | Une nouvelle requête a été détectée, ce qui affecte les performances de la base de données. |
| Augmentation des statistiques d’attente | Une augmentation des temps d’attente de base de données a été détectée, ce qui affecte les performances. | Une augmentation des temps d’attente de base de données a été détectée, ce qui affecte les performances de la base de données. |
| Contention de tempDB | Plusieurs threads essaient d’accéder à la même ressource tempdb, ce qui provoque un goulet d’étranglement. Cela affecte les performances. |
Plusieurs threads essaient d’accéder à la même ressource tempdb, ce qui provoque un goulet d’étranglement. Ce phénomène affecte les performances de la base de données. |
| Pénurie de DTU du pool élastique | La pénurie de eDTU disponibles dans le pool élastique affecte les performances. | Non disponible pour Azure SQL Managed Instance, car c’est le modèle vCore qui est utilisé. |
| Régression de plan | Un nouveau plan ou une modification de la charge de travail d’un plan existant ont été détectés. Cela affecte les performances. | Un nouveau plan ou une modification de la charge de travail d’un plan existant ont été détectés. Ce phénomène affecte les performances de la base de données. |
| Modification de la valeur de configuration à l’échelle de la base de données | Une modification de configuration apportée à la base de données a été détectée, ce qui affecte les performances de la base de données. | Une modification de configuration apportée à la base de données a été détectée, ce qui affecte les performances de la base de données. |
| Client lent | Un client d’application lent est incapable de consommer la sortie de la base de données assez rapidement. Cela affecte les performances. | Un client d’application lent est incapable de consommer la sortie de la base de données assez rapidement. Ce phénomène affecte les performances de la base de données. |
| Rétrogradation à un niveau tarifaire inférieur | Le passage à un niveau tarifaire inférieur a diminué les ressources disponibles. Cela affecte les performances. | Le passage à un niveau tarifaire inférieur a diminué les ressources disponibles. Ce phénomène affecte les performances de la base de données. |
Conseil
Pour optimiser en continu les performances des bases de données, activez le paramétrage automatique. Cette fonctionnalité unique de l’intelligence intégrée surveille en permanence votre base de données, paramètre automatiquement les index et applique les corrections du plan d’exécution de requêtes.
La section suivante décrit plus en détail les modèles de performances détectables.
Atteinte des limites de ressources
Ce qui se passe
Ce modèle de performances détectables combine les problèmes de performances liés à l’atteinte des limites de ressources, de threads de travail et de sessions disponibles. Une fois que ce problème de performances a été détecté, un champ de description du journal de diagnostic indique si le problème est lié aux limites de ressources, de threads de travail ou de sessions.
Les ressources sur Azure SQL Database sont généralement appelées ressources DTU ou vCore, et les ressources sur Azure SQL Managed Instance sont appelées ressources vCore. Le modèle lié à l’atteinte des limites de ressources est reconnu quand une détérioration des performances de requête est détectée et qu’elle est due à l’atteinte de l’une des limites de ressources mesurées.
La ressource relative aux limites de sessions indique le nombre de connexions simultanées disponibles à la base de données. Ce modèle de performances est reconnu lorsque des applications connectées à des bases de données ont atteint le nombre de connexions simultanées disponibles à la base de données. Si les applications essaient d’utiliser plus de sessions que le nombre disponible sur une base de données, les performances des requêtes sont affectées.
L’atteinte des limites de threads de travail est un cas spécifique d’atteinte des limites de ressources dans la mesure où les threads de travail disponibles ne sont pas comptabilisés dans l’utilisation des DTU ou des vCore. L’atteinte des limites de threads de travail sur une base de données peut entraîner une augmentation des temps d’attente propres aux ressources, ce qui mène à une détérioration des performances des requêtes.
Dépannage
Le journal de diagnostic génère les codes de hachage des requêtes qui ont affecté les performances et les pourcentages de consommation de ressources. Vous pouvez utiliser ces informations comme point de départ de l’optimisation de la charge de travail de votre base de données. En particulier, vous pouvez optimiser les requêtes qui détériorent les performances en ajoutant des index. Vous pouvez également optimiser les applications avec une distribution de charge de travail plus homogène. Si vous ne pouvez pas réduire les charges de travail ou effectuer des optimisations, augmentez éventuellement le niveau tarifaire de votre abonnement de base de données pour accroître la quantité de ressources disponibles.
Si vous avez atteint les limites de sessions disponibles, vous pouvez optimiser vos applications en réduisant le nombre de connexions à la base de données. Si vous ne parvenez pas à réduire le nombre de connexions de vos applications à la base de données, augmentez éventuellement le niveau tarifaire de votre abonnement de base de données. Vous pouvez également fractionner et déplacer votre base de données vers plusieurs bases de données pour obtenir une distribution plus équilibrée de la charge de travail.
Pour plus de suggestions sur la résolution des problèmes liés aux limites de sessions, consultez Guide pratique pour traiter les limites de connexions maximales. Pour plus d'informations sur les limites au niveau du serveur et de l'abonnement, consultez Vue d'ensemble des limites de ressources sur un serveur.
Augmentation de la charge de travail
Ce qui se passe
Ce modèle de performances identifie les problèmes provoqués par une augmentation de la charge de travail, ou dans sa forme la plus grave, par une accumulation de la charge de travail.
Cette détection s’effectue en combinant plusieurs métriques. La mesure de base détecte une augmentation de la charge de travail par rapport à la base de référence de la charge de travail passée. L’autre forme de détection repose sur la mesure d’une augmentation importante de la charge de travail des threads de travail actifs, suffisamment élevée pour affecter les performances des requêtes.
Dans sa forme la plus grave, la charge de travail s’accumule en permanence en raison de l’incapacité d'une base de données à la gérer. Ainsi, la taille de la charge de travail ne cesse d’augmenter, ce qui correspond à une situation d’accumulation. En raison de cette situation, le temps d’attente pour l’exécution de la charge de travail augmente. Cela représente l’un des problèmes de performances de base de données les plus graves. Vous pouvez détecter ce problème en surveillant l’augmentation du nombre de threads de travail abandonnés.
Dépannage
Le journal de diagnostic génère le nombre de requêtes dont l’exécution a augmenté, ainsi que le code de hachage de la requête qui contribue le plus à l’augmentation de la charge de travail. Vous pouvez utiliser ces informations comme point de départ pour l’optimisation de la charge de travail. Plus précisément, vous pouvez utiliser la requête identifiée comme étant celle qui contribue le plus à l’augmentation de la charge de travail.
Distribuez éventuellement les charges de travail de façon plus homogène à la base de données. De même, rien ne vous empêche d’optimiser la requête qui affecte les performances en ajoutant des index. Vous pouvez également distribuer votre charge de travail entre plusieurs bases de données. Si ces solutions ne sont pas viables, augmentez éventuellement le niveau tarifaire de votre abonnement de base de données pour accroître la quantité de ressources disponibles.
Sollicitation de la mémoire
Ce qui se passe
Ce modèle de performances indique une détérioration des performances de la base de données actuelle due à une sollicitation de la mémoire, ou dans sa forme la plus grave, à une situation d’accumulation de mémoire par rapport à la base de référence des performances des sept jours précédents.
La sollicitation de la mémoire est une situation où il existe un nombre élevé de threads de travail qui demandent des allocations de mémoire. Ce volume important entraîne une utilisation intensive de la mémoire, c’est-à-dire un cas de figure où la base de données ne peut pas allouer efficacement de la mémoire à tous les threads de travail qui en font la demande. L’une des raisons les plus courantes de ce problème est liée à la quantité de mémoire disponible pour la base de données. L’autre raison la plus fréquente est liée à l’augmentation de la charge de travail qui entraîne une augmentation du nombre de threads de travail et de la sollicitation de la mémoire.
La forme la plus grave de sollicitation de la mémoire est la situation d’accumulation de mémoire. Cette situation indique que le nombre de threads de travail qui demandent des allocations de mémoire est plus élevé que le nombre de requêtes qui libèrent de la mémoire. Ce nombre de threads de travail demandant des allocations de mémoire peut aussi augmenter en continu (c’est-à-dire s’accumuler), car le moteur de base de données ne peut pas allouer de mémoire de manière suffisamment efficace pour répondre à la demande. La situation d’accumulation de mémoire représente l’un des problèmes de performances de base de données les plus graves.
Dépannage
Le journal de diagnostic génère des détails sur le magasin d’objets mémoire avec le régisseur (c’est-à-dire le thread de travail) marqué en tant que raison la plus importante de l’utilisation élevée de la mémoire, ainsi que les horodatages concernés. Vous pouvez utiliser ces informations comme base pour la résolution des problèmes.
Vous pouvez optimiser ou supprimer les requêtes liées aux régisseurs dont l’utilisation de la mémoire est la plus élevée. Vous pouvez aussi vérifier que vous interrogez uniquement les données que vous prévoyez d’utiliser. Une bonne pratique consiste à toujours utiliser une clause WHERE dans vos requêtes. De plus, nous vous recommandons de créer des index non cluster pour rechercher les données, au lieu de les analyser.
Vous pouvez également réduire la charge de travail en l’optimisant ou en la distribuant entre plusieurs bases de données. De même, rien ne vous empêche de distribuer simplement votre charge de travail entre plusieurs bases de données. Si ces solutions ne sont pas viables, augmentez éventuellement le niveau tarifaire de votre base de données pour accroître la quantité de ressources mémoire disponibles pour la base de données.
Pour des suggestions de dépannage supplémentaires, consultez le billet de blog Memory grants meditation: The mysterious SQL Server memory consumer with many names. Pour plus d’informations sur les erreurs de mémoire insuffisante dans Azure SQL Database, consultez Résoudre les erreurs de mémoire insuffisante avec Azure SQL Database.
Verrouillage
Ce qui se passe
Ce modèle de performances indique une détérioration des performances de la base de données actuelle, où un verrouillage excessif de la base de données est détecté par rapport à la base de référence des performances des sept jours précédents.
Dans un SGBDR (Système de Gestion de Base de Données Relationnelle) moderne, le verrouillage est essentiel pour implémenter les systèmes multithreads dans lesquels les performances sont maximisées par l’exécution simultanée de plusieurs threads de travail et plusieurs transactions de bases de données parallèles, quand cela est possible. Dans ce contexte, le verrouillage fait référence au mécanisme d’accès intégré dans lequel une seule transaction peut accéder exclusivement aux lignes, pages, tables et fichiers nécessaires sans entrer en concurrence avec une autre transaction concernant des ressources. Quand la transaction qui a verrouillé les ressources à utiliser n’en a plus besoin, le verrou posé sur ces ressources est libéré, ce qui permet à d’autres transactions d’accéder aux ressources nécessaires. Pour plus d’informations sur le verrouillage, consultez Verrouillage dans le moteur de base de données.
Si les transactions exécutées par le moteur SQL attendent très longtemps pour accéder à des ressources verrouillées pour cause d’utilisation, ce temps d’attente entraîne un ralentissement des performances d’exécution de la charge de travail.
Dépannage
Le journal de diagnostic génère des détails sur le verrouillage que vous pouvez utiliser comme base pour la résolution des problèmes. Vous pouvez analyser les requêtes bloquantes signalées, c’est-à-dire les requêtes qui introduisent une détérioration des performances liée au verrouillage, et les supprimer. Dans certains cas, vous pouvez réussir à optimiser les requêtes bloquantes.
La façon la plus simple et la plus sûre d’atténuer ce problème consiste à préférer des transactions courtes et à réduire l’empreinte de verrou des requêtes les plus coûteuses. Vous pouvez décomposer un grand lot d’opérations en opérations plus petites. Une bonne pratique consiste à réduire l’empreinte de verrou des requêtes en les rendant les plus efficaces possible. Réduisez les analyses de grande taille, car elles augmentent le risque d’interblocages et ont un impact négatif sur les performances globales de la base de données. Pour les requêtes identifiées qui entraînent un verrouillage, vous pouvez créer des index ou ajouter des colonnes à l’index existant afin d’éviter les analyses de tables.
Pour d’autres suggestions, consultez les pages suivantes :
- Compréhension et résolution des problèmes bloquants Azure SQL
- Guide pratique pour résoudre les problèmes bloquants provoqués par l’escalade de verrous dans SQL Server
Augmentation de MAXDOP
Ce qui se passe
Ce modèle de performances détectables indique une situation dans laquelle le plan d’exécution de requêtes choisi a été mis en parallèle au-delà du strict nécessaire. L’optimiseur de requête peut améliorer les performances de la charge de travail en exécutant les requêtes en parallèle pour accélérer les choses quand cela est possible. Dans certains cas, les threads de travail parallèles qui traitent une requête passent plus de temps à s’attendre les uns les autres pour synchroniser et fusionner les résultats que la même requête s’exécutant avec moins de threads de travail parallèles voire, parfois, un seul thread de travail.
Le système expert analyse les performances de la base de données actuelle par rapport à la période servant de base de référence. Il détermine si une requête en cours d’exécution va moins vite qu’avant en raison d’un plan d’exécution de requêtes plus parallélisé que nécessaire.
L’option de configuration de serveur MAXDOP est utilisée pour contrôler le nombre de cœurs d’UC pouvant être utilisés pour exécuter la même requête en parallèle.
Dépannage
Le journal de diagnostic génère les codes de hachage des requêtes dont la durée d’exécution a augmenté en raison d’une parallélisation trop importante. Le journal génère également des temps d’attente CXP. Ce temps représente la durée pendant laquelle un thread organisateur/coordinateur unique (thread 0) attend que tous les autres threads aient terminé avant de fusionner les résultats et de continuer. De plus, le journal de diagnostic génère les temps d’attente d’exécution globale des requêtes peu performantes. Vous pouvez utiliser ces informations comme base pour la résolution des problèmes.
Commencez par optimiser ou simplifier les requêtes complexes. Une bonne pratique consiste à diviser les longs programmes de traitement par lots en plus petits programmes. De plus, vérifiez que vous avez créé des index pour prendre en charge vos requêtes. Vous pouvez également appliquer manuellement l’option MAXDOP (degré maximal de parallélisme) à une requête identifiée comme étant peu performante. Pour configurer cette opération à l’aide de T-SQL, consultez Configurer l’option de configuration de serveur MAXDOP.
Si la valeur zéro (0) est affectée à l’option de configuration de serveur MAXDOP en tant que valeur par défaut, cela indique que la base de données peut utiliser tous les cœurs d’UC disponibles pour paralléliser les threads afin d’exécuter une seule requête. Si la valeur un (1) est affectée à MAXDOP, cela indique qu’un seul cœur peut être utilisé pour l’exécution d’une seule requête. En pratique, cela signifie que le parallélisme est désactivé. En fonction de votre situation, du nombre de cœurs disponibles pour la base de données et des informations du journal de diagnostic, vous pouvez paramétrer l’option MAXDOP sur le nombre de cœurs à utiliser pour une exécution parallèle optimale des requêtes.
Contention de verrous de page
Ce qui se passe
Ce modèle de performances indique que la détérioration des performances de la charge de travail de la base de données actuelle est due à une contention de verrous de page par rapport à la base de référence de la charge de travail des sept jours précédents.
Les verrous sont des mécanismes de synchronisation légers utilisés pour activer le multithreading. Ils garantissent la cohérence des structures en mémoire, notamment des index, des pages de données et d’autres structures internes.
Il existe de nombreux types de verrou disponibles. Pour des raisons de simplicité, les verrous de mémoire tampon sont utilisés pour protéger les pages en mémoire dans le pool de mémoires tampons. Les verrous d’E/S sont utilisés pour protéger les pages qui ne sont pas encore chargées dans le pool de mémoires tampons. Chaque fois que des données sont écrites ou lues à partir d’une page dans le pool de mémoires tampons, un thread de travail doit d’abord acquérir un verrou de mémoire tampon pour la page. Chaque fois qu’un thread de travail tente d’accéder à une page qui n’est pas déjà disponible dans le pool de mémoires tampons en mémoire, une requête d’E/S est effectuée pour charger les informations nécessaires à partir du stockage. Cette séquence d’événements indique une forme plus grave de détérioration des performances.
Une contention des verrous de page se produit quand plusieurs threads tentent simultanément d’acquérir des verrous sur la même structure en mémoire, ce qui allonge le temps d’attente d’exécution des requêtes. En cas de contention d’E/S de verrous de page, quand des données ont besoin d’être accessibles à partir du stockage, ce temps d’attente est encore plus important. Il peut donc considérablement affecter les performances de la charge de travail. La contention de verrous de page constitue le scénario le plus courant dans lequel des threads s’attendent les uns les autres et entrent en concurrence pour obtenir des ressources sur plusieurs systèmes de processeur.
Dépannage
Le journal de diagnostic génère des détails sur la contention de verrous de page. Vous pouvez utiliser ces informations comme base pour la résolution des problèmes.
Comme un verrou de page est un mécanisme de contrôle interne, il est possible de déterminer automatiquement quand ils doivent être utilisés. Les décisions d’application, notamment la conception de schéma, peuvent affecter le comportement des verrous de page en raison du comportement déterministe des verrous.
Vous pouvez gérer la contention de verrous en remplaçant une clé d’index séquentielle par une clé non séquentielle pour distribuer uniformément les insertions dans une plage d’index. En règle générale, une colonne de début dans l’index permet de distribuer la charge de travail proportionnellement. Une autre méthode à prendre en compte est le partitionnement de tables. La création d’un schéma de partitionnement de hachage avec une colonne calculée sur une table partitionnée constitue une approche courante pour atténuer une contention de verrous excessive. En cas de contention d’E/S de verrous de page, l’introduction d’index permet d’atténuer ce problème de performances.
Pour plus d’informations, consultez Diagnostiquer et résoudre une contention de verrous sur SQL Server (téléchargement PDF).
Index manquant
Ce qui se passe
Ce modèle de performances indique une détérioration des performances de la charge de travail de la base de données actuelle par rapport à la base de référence des sept jours précédents en raison d’un index manquant.
Un index est utilisé pour accélérer les performances des requêtes. Il fournit un accès rapide aux données de table en réduisant le nombre de pages de jeux de données à visiter ou à analyser.
Les requêtes spécifiques responsables d’une détérioration des performances sont identifiées via cette détection pour laquelle la création d’index permet d’accroître les performances.
Dépannage
Le journal de diagnostic génère les codes de hachage des requêtes qui affectent les performances de la charge de travail. Vous pouvez créer des index pour ces requêtes. Vous pouvez également optimiser ou supprimer ces requêtes, si elles ne sont pas nécessaires. Pour ménager les performances, il est préférable d’éviter d’interroger les données que vous n’utilisez pas.
Conseil
Saviez-vous que l’intelligence intégrée est capable de gérer automatiquement les index les plus performants de vos bases de données ?
Pour optimiser en continu les performances, nous vous recommandons d’activer le paramétrage automatique. Cette fonctionnalité unique de l’intelligence intégrée surveille en permanence votre base de données. Elle peut également créer et paramétrer automatiquement les index de vos bases de données.
Nouvelle requête
Ce qui se passe
Ce modèle de performances indique qu’une nouvelle requête est détectée, qu’elle n’est pas très efficace et qu’elle affecte les performances de la charge de travail par rapport à la base de référence des performances des sept jours précédents.
Parfois, l’écriture d’une requête efficace est une tâche difficile. Pour plus d’informations sur l’écriture des requêtes, consultez Écriture des requêtes SQL. Pour optimiser les performances des requêtes existantes, consultez Paramétrage des requêtes.
Dépannage
Le journal de diagnostic génère des informations sur deux nouvelles requêtes, au maximum, parmi celles qui consomment le plus d’UC, avec notamment leurs codes de hachage. Dans la mesure où la requête détectée affecte les performances de la charge de travail, vous pouvez optimiser votre requête. Il est conseillé de récupérer uniquement les données que vous devez utiliser. Nous vous recommandons également d’utiliser les requêtes avec une clause WHERE. Nous vous recommandons également de simplifier les requêtes complexes et de les décomposer en requêtes plus petites. Il est conseillé de fractionner les requêtes de traitement par lots volumineuses en requêtes plus petites. Introduire des index pour les nouvelles requêtes constitue généralement une bonne pratique pour atténuer ce problème de performances.
Dans Azure SQL Database, utilisez éventuellement Query Performance Insight.
Augmentation des statistiques d’attente
Ce qui se passe
Ce modèle de performances détectables indique une détérioration des performances de la charge de travail où les requêtes peu performantes sont identifiées par rapport à la base de référence de la charge de travail des sept jours précédents.
Dans ce cas, le système ne peut pas classer les requêtes peu performantes dans une autre catégorie de performances détectables standard. Toutefois, il a détecté les statistiques d’attente responsables de la régression. Il les considère donc comme des requêtes qui connaissent une augmentation des statistiques d’attente. De plus, les statistiques d’attente responsables de la régression sont également exposées.
Dépannage
Le journal de diagnostic génère des informations détaillées sur l’augmentation des temps d’attente et les codes de hachage des requêtes affectées.
Dans la mesure où le système n’a pas pu identifier correctement la cause racine des requêtes peu performantes, les informations de diagnostic représentent un bon point de départ pour une résolution manuelle des problèmes. Vous pouvez optimiser les performances de ces requêtes. Respectez les bonnes pratiques suivantes : extrayez uniquement les données dont vous avez besoin, simplifiez et décomposez les requêtes complexes en requêtes plus petites.
Pour plus d’informations sur l’optimisation des performances des requêtes, consultez Paramétrage des requêtes.
Contention de TempDB
Ce qui se passe
Ce modèle de performances détectables indique un problème au niveau des performances de base de données, car il existe un goulot d’étranglement pour les threads qui tentent d’accéder aux ressources tempdb. (Cette situation n’est pas liée aux E/S.) Le scénario classique de ce problème de performances implique des centaines de requêtes simultanées qui créent, utilisent, puis suppriment toutes des petites tables tempdb. Le système a détecté que le nombre de requêtes simultanées qui utilisent les mêmes tables tempdb a augmenté et qu’il présente une pertinence statistique suffisante pour affecter les performances de la base de données par rapport à la base de référence des performances des sept jours précédents.
Résolution des problèmes
Le journal de diagnostic génère des détails sur la contention de tempdb. Vous pouvez utiliser ces informations comme point de départ pour la résolution des problèmes. Il existe deux choses que vous pouvez faire pour limiter ce genre de contention et augmenter le débit de la charge de travail globale : Tout d’abord, vous pouvez arrêter d’utiliser les tables temporaires. Ensuite, vous pouvez utiliser des tables à mémoire optimisée.
Pour plus d’informations, consultez Introduction aux tables à mémoire optimisée.
Pénurie de DTU du pool élastique
Ce qui se passe
Ce modèle de performances détectables indique une détérioration des performances de la charge de travail de la base de données actuelle par rapport à la base de référence des sept jours précédents. Cela est dû à un manque de DTU disponibles dans le pool élastique de votre abonnement.
Les ressources du pool élastique Azure sont utilisées comme pool de ressources disponibles partagées entre plusieurs bases de données à des fins de mise à l’échelle. Quand les ressources eDTU disponibles dans le pool élastique ne sont pas suffisantes pour prendre en charge toutes les bases de données du pool, un problème de performances lié à une pénurie de DTU dans le pool élastique est détecté par le système.
Dépannage
Le journal de diagnostic génère des informations sur le pool élastique, liste les bases de données qui consomment le plus de DTU et fournit un pourcentage des ressources DTU du pool utilisées par la base de données la plus consommatrice.
Comme ces performances sont liées au fait que plusieurs bases de données utilisent le même pool d’eDTU dans le pool élastique, les étapes de résolution de problème sont concentrées sur les bases de données qui consomment le plus de DTU. Vous pouvez réduire la charge de travail des bases de données les plus consommatrices, par exemple en optimisant les requêtes les plus consommatrices de ces bases de données. Vous pouvez également vérifier que vous interrogez uniquement les données que vous prévoyez d’utiliser. Une autre approche consiste à optimiser les applications en utilisant les bases de données les plus consommatrices de DTU et en redistribuant la charge de travail entre plusieurs bases de données.
Si la réduction et l’optimisation de la charge de travail actuelle de vos bases de données les plus consommatrices de DTU n’est pas possible, augmentez le niveau tarifaire de votre pool élastique. Une telle augmentation entraîne celle des DTU disponibles dans le pool élastique.
Régression de plan
Ce qui se passe
Ce modèle de performances détectables indique une situation dans laquelle la base de données utilise un plan d’exécution de requêtes qui n’est pas optimal. Ce plan non optimal entraîne généralement une exécution accrue des requêtes, ce qui allonge les temps d’attente des requêtes actives et des autres requêtes.
Le moteur de base de données détermine le plan d’exécution de requêtes qui coûte le moins à l’exécution des requêtes. Au fur et à mesure que le type des requêtes et des charges de travail change, les plans existants ne sont parfois plus efficaces, ou le moteur de base de données n’a peut-être pas effectué une évaluation correcte. À titre de correction, vous pouvez forcer manuellement les plans d’exécution des requêtes.
Ce modèle de performances détectables combine trois cas différents de régression de plan : régression de nouveau plan, régression de plan antérieur et régression de la charge de travail liée à des changements de plans existants. Le type précis de régression de plan utilisé est indiqué dans la propriété détails du journal de diagnostic.
La régression de nouveau plan fait référence à un état dans lequel le moteur de base de données commence à exécuter un nouveau plan d’exécution de requêtes qui n’est pas aussi efficace que le plan antérieur. La régression de plan antérieur fait référence à l’état où le moteur de base de données passe de l’utilisation d’un nouveau plan, plus efficace, à celle du plan antérieur, qui est moins efficace que le nouveau plan. La régression de la charge de travail liée à des changements de plans existants fait référence à l’état dans lequel deux plans, un plan antérieur et un nouveau plan, ne cessent d’alterner, avec une tendance pour le plan le moins performant.
Pour plus d’informations sur les régressions de plans, consultez Qu’est-ce que la régression de plan dans SQL Server ?.
Dépannage
Le journal de diagnostic génère les codes de hachage des requêtes, l’ID du plan approprié, l’ID du plan inapproprié et les ID de requêtes. Vous pouvez utiliser ces informations comme base pour la résolution des problèmes.
Vous pouvez déterminer quel est le plan le plus performant pour vos requêtes spécifiques en les identifiant à l’aide des codes de hachage des requêtes fournis. Une fois que vous avez défini le plan qui fonctionne le mieux pour vos requêtes, vous pouvez le forcer manuellement.
Pour plus d’informations sur les régressions de plans, consultez Découvrir comment SQL Server empêche les régressions de plans.
Conseil
Saviez-vous que la fonctionnalité de l'intelligence intégrée est capable de gérer automatiquement les plans d’exécution des requêtes les plus performants de vos bases de données ?
Pour optimiser en continu les performances, nous vous recommandons d’activer le paramétrage automatique. La fonctionnalité de l'intelligence intégrée surveille en permanence votre base de données. Elle peut également créer et paramétrer automatiquement les plans d’exécution de requêtes les plus performants pour vos bases de données.
Changement de la valeur de configuration à l’échelle de la base de données
Ce qui se passe
Ce modèle de performances détectables indique une situation dans laquelle un changement de configuration à l’échelle de la base de données entraîne une régression des performances par rapport au comportement de la charge de travail de la base de données pendant les sept jours précédents. Ce modèle indique qu’un changement de configuration récent à l’échelle de la base de données ne semble pas être bénéfique pour les performances de votre base de données.
Vous pouvez apporter un changement de configuration à l’échelle de la base de données pour chaque base de données. Cette configuration est utilisée au cas par cas pour optimiser les performances individuelles de votre base de données. Vous pouvez configurer les options suivantes pour chaque base de données : MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES et CLEAR PROCEDURE_CACHE.
Dépannage
Le journal de diagnostic génère les changements de configuration à l’échelle de la base de données qui ont été apportés récemment et qui ont provoqué la détérioration des performances par rapport au comportement de la charge de travail pendant les sept jours précédents. Vous pouvez restaurer les changements de configuration aux valeurs antérieures. Vous pouvez paramétrer chaque valeur jusqu’à ce que le niveau de performance souhaité soit atteint. Vous pouvez copier les valeurs de configuration à l’échelle de la base de données à partir d’une base de données similaire dont les performances sont satisfaisantes. Si vous n’arrivez pas à résoudre les problèmes de performances, restaurez les valeurs par défaut, puis essayez de les paramétrer de manière plus précise à partir de cette base de référence.
Pour plus d’informations sur l’optimisation de la configuration à l’échelle de la base de données et sur la syntaxe T-SQL utilisée pour changer la configuration, consultez Changer la configuration à l’échelle de la base de données (Transact-SQL).
Client lent
Ce qui se passe
Ce modèle de performances détectables indique une situation dans laquelle le client qui utilise la base de données ne peut pas consommer la sortie de la base de données à la vitesse où cette dernière envoie les résultats. Comme la base de données ne stocke pas les résultats des requêtes exécutées en mémoire tampon, il ralentit et attend que le client consomme les résultats de requête transmis avant de continuer. Cette situation peut également être liée à un réseau qui n’est pas assez rapide pour transmettre les résultats de la base de données au client consommateur.
Cette situation est générée uniquement si une régression des performances est détectée par rapport au comportement de la charge de travail de la base de données pendant les sept jours précédents. Ainsi, ce problème de performances est détecté uniquement s’il existe une détérioration des performances statistiquement significative par rapport au comportement antérieur des performances.
Dépannage
Ce modèle de performances détectables indique un problème côté client. Vous devez résoudre les problèmes au niveau de l’application côté client ou du réseau côté client. Le journal de diagnostic génère les codes de hachage des requêtes et les temps d’attente les plus longs par rapport à la consommation du client au cours des deux dernières heures. Vous pouvez utiliser ces informations comme base pour la résolution des problèmes.
Vous pouvez optimiser les performances de votre application pour la consommation de ces requêtes. Vous pouvez également rechercher d’éventuels problèmes de latence réseau. Dans la mesure où le problème de détérioration des performances provient d’un changement de la base de référence des performances au cours des sept derniers jours, vous pouvez rechercher d’éventuelles modifications apportées récemment aux applications ou au réseau, et qui peuvent avoir déclenché cet événement de régression des performances.
Rétrogradation à un niveau tarifaire inférieur
Ce qui se passe
Ce modèle de performances détectables indique une situation dans laquelle le niveau tarifaire de votre abonnement de base de données a été passé à un niveau inférieur. En raison de la réduction des ressources (DTU) disponibles pour la base de données, le système a détecté une baisse des performances de la base de données actuelle par rapport à la base de référence des sept jours précédents.
De plus, il existe peut-être une situation dans laquelle le niveau tarifaire de votre abonnement de base a été passé à un niveau inférieur, puis repassé à un niveau supérieur sur une courte période. La détection de cette détérioration temporaire des performances est indiquée dans la section des détails du journal de diagnostic sous la forme d’une baisse et d’une augmentation du niveau tarifaire.
Dépannage
Si vous avez réduit votre niveau tarifaire, et donc les DTU disponibles, et si vous êtes satisfait des performances, vous n’avez rien à faire. Si vous avez réduit le niveau tarifaire et si vous n’êtes pas satisfait des performances de votre base de données, réduisez vos charges de travail de base de données, ou passez à un niveau tarifaire supérieur.
Flux de résolution des problèmes recommandé
Suivez l’organigramme et découvrez l’approche recommandée pour la résolution des problèmes de performances à l’aide d’Intelligent Insights.
Accédez à Intelligent Insights via le portail Azure et Azure SQL Analytics. Essayez de localiser l’alerte de performances entrante, puis sélectionnez-la. Identifiez ce qui se passe dans la page des détections. Examinez l’analyse fournie pour la cause racine du problème, le texte de requête, les tendances des temps de requête et l’évolution de l’incident. Tentez de résoudre le problème en utilisant la recommandation donnée par Intelligent Insights pour atténuer le problème de performances.
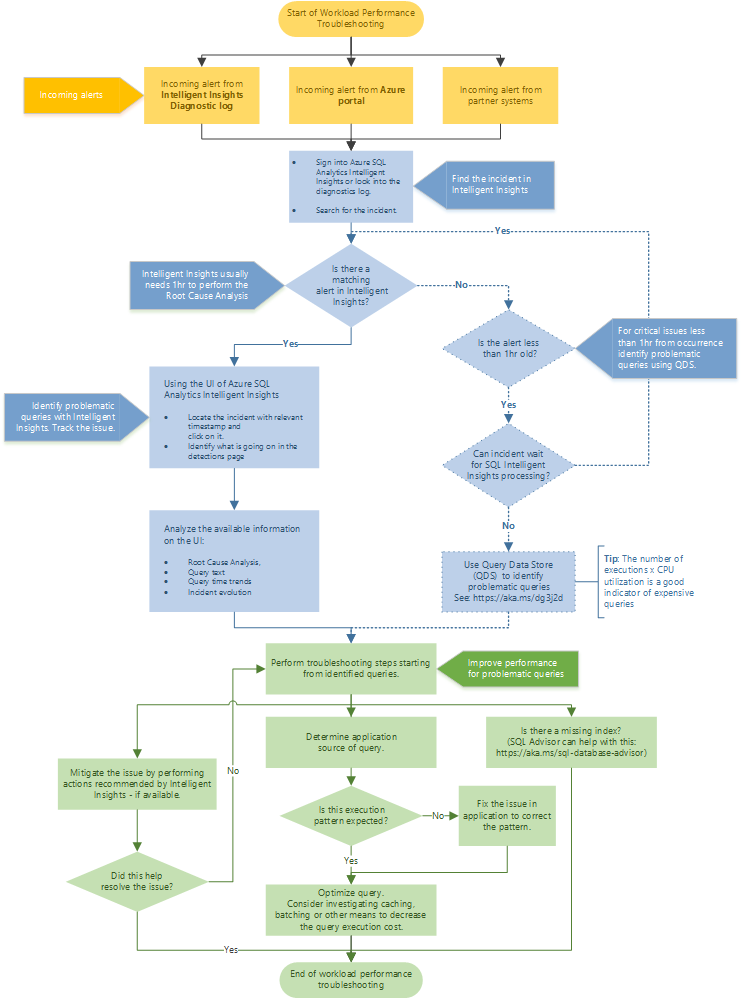
Conseil
Sélectionnez l’organigramme pour télécharger sa version PDF.
Intelligent Insights a généralement besoin d’une heure pour effectuer l’analyse de la cause racine du problème de performances. Si vous ne parvenez pas à localiser votre problème dans Intelligent Insights et s’il s’agit d’un problème critique, utilisez le Magasin des requêtes pour identifier manuellement la cause racine du problème de performances. (En règle générale, ces problèmes ont moins d’une heure.) Pour plus d’informations, consultez Analyser les performances à l’aide du Magasin des requêtes.
Étapes suivantes
- Découvrez les concepts Intelligent Insights.
- Utilisez le journal de diagnostic des performances Intelligent Insights.
- Supervisez l'utilisation d'Azure SQL Analytics.
- Découvrez comment collecter et consommer les données des journaux de vos ressources Azure.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour