Bonnes pratiques de configuration de la HADR (SQL Server sur des machines virtuelles Azure)
S’applique à :![]() SQL Server sur la machine virtuelle Azure
SQL Server sur la machine virtuelle Azure
Un cluster de basculement Windows Server est utilisé pour la haute disponibilité et la reprise d’activité (HADR) avec SQL Server sur des machines virtuelles Azure.
Cet article présente les meilleures pratiques en matière de configuration de cluster pour les instances (FCI) de cluster de basculement et les groupes de disponibilité lorsque vous les utilisez avec SQL Server sur des machines virtuelles Azure.
Pour plus d’informations, consultez les autres articles de cette série : Liste de vérification, Taille de machine virtuelle, Stockage, Sécurité, Configuration HADR et Collecter une ligne de base.
Check-list
Consultez la check-list suivante pour obtenir une vue d’ensemble des bonnes pratiques liées à la HADR, présentées plus en détail dans le reste de l’article.
Les fonctionnalités de haute disponibilité et récupération d’urgence (HADR), telles que le groupe de disponibilité Always On et l’instance de cluster de basculement, reposent sur la technologie de cluster de basculement Windows Server sous-jacente. Examinez les meilleures pratiques pour modifier vos paramètres HADR afin de mieux prendre en charge l’environnement cloud.
Pour votre cluster Windows, prenez en compte les meilleures pratiques suivantes :
- Déployez vos machines virtuelles SQL Server sur plusieurs sous-réseaux quand cela est possible afin d’éviter de dépendre d’Azure Load Balancer ou d’un nom de réseau distribué (DNN) pour acheminer le trafic vers votre solution HADR.
- Définissez des paramètres moins agressifs pour le cluster afin d’éviter les pannes inattendues dues à des défaillances momentanées du réseau ou à la maintenance de la plateforme Azure. Pour plus d’informations, consultez les paramètres de pulsation et de seuil. Pour Windows Server 2012 et les versions ultérieures, utilisez les valeurs recommandées suivantes :
- SameSubnetDelay : 1 seconde
- SameSubnetThreshold : 40 pulsations
- CrossSubnetDelay : 1 seconde
- CrossSubnetThreshold : 40 pulsations
- Placez vos machines virtuelles dans un groupe à haute disponibilité ou dans différentes zones de disponibilité. Pour plus d’informations, consultez les paramètres de disponibilité des machines virtuelles.
- Utilisez une seule carte réseau par nœud de cluster.
- Configurez le vote de quorum du cluster pour utiliser trois votes ou plus (toujours par nombre impair). N’attribuez pas de votes à des régions de reprise d’activité.
- Surveillez attentivement les limites de ressources pour éviter les redémarrages ou les basculements inattendus dus à des contraintes de ressources.
- Assurez-vous que le système d’exploitation, les pilotes et SQL Server disposent de la version la plus récente.
- Optimisez les performances de SQL Server sur les machines virtuelles Azure. Consultez les autres sections de cet article pour en savoir plus.
- Réduisez ou répartissez la charge de travail pour éviter d’atteindre les limites de ressources.
- Passez à une machine virtuelle ou à un disque dont les limites sont plus élevées pour éviter les contraintes.
Pour votre groupe de disponibilité SQL Server ou votre instance de cluster de basculement, tenez compte des meilleures pratiques suivantes :
- Si vous rencontrez fréquemment des échecs inattendus, suivez les meilleures pratiques en matière de performances décrites dans la suite de cet article.
- Si l’optimisation des performances de la machine virtuelle SQL Server ne résout pas vos basculements inattendus, envisagez de relâcher la supervision pour le groupe de disponibilité ou l’instance du cluster de basculement. Toutefois, cela ne résout pas la source sous-jacente du problème et peut masquer les symptômes en réduisant la probabilité d’échec. Vous devrez peut-être encore examiner et résoudre la cause racine sous-jacente. Pour Windows Server 2012 ou les versions ultérieures, utilisez les valeurs recommandées suivantes :
- Délai d’expiration du bail : Utilisez cette équation pour calculer la valeur maximale du délai d’expiration du bail :
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Commencez par 40 secondes. Si vous utilisez les valeurs assouplies deSameSubnetThresholdetSameSubnetDelayqui ont été recommandées précédemment, ne dépassez pas 80 secondes pour la valeur du délai d’expiration du bail. - Nombre maximal d’échecs au cours d’une période spécifiée : Définissez cette valeur sur 6.
- Délai d’expiration du bail : Utilisez cette équation pour calculer la valeur maximale du délai d’expiration du bail :
- Quand vous utilisez le nom de réseau virtuel (VNN) et Azure Load Balancer pour vous connecter à votre solution HADR, spécifiez
MultiSubnetFailover = truedans la chaîne de connexion, même si votre cluster s’étend sur un seul sous-réseau.- Si le client ne prend pas en charge
MultiSubnetFailover = True, il peut être nécessaire de définirRegisterAllProvidersIP = 0etHostRecordTTL = 300pour mettre en cache les informations d’identification du client pour des durées plus courtes. Toutefois, cela peut entraîner des requêtes supplémentaires sur le serveur DNS.
- Si le client ne prend pas en charge
- Pour vous connecter à votre solution HADR à l’aide du nom réseau distribué (DNN), tenez compte des points suivants :
- Vous devez utiliser un pilote client qui prend en charge
MultiSubnetFailover = True, et ce paramètre doit figurer dans la chaîne de connexion. - Utilisez un port DNN unique dans la chaîne de connexion lorsque vous vous connectez à l’écouteur DNN pour un groupe de disponibilité.
- Vous devez utiliser un pilote client qui prend en charge
- Utilisez une chaîne de connexion de mise en miroir de bases de données pour un groupe de disponibilité de base afin de contourner le besoin d’un équilibreur de charge ou d’un DNN.
- Validez la taille de secteur de vos disques durs virtuels avant de déployer votre solution de haute disponibilité pour éviter les E/S mal alignées. Pour plus d’informations, voir KB3009974.
- Si le moteur de base de données SQL Server, l’écouteur de groupe de disponibilité Always On ou la sonde d'intégrité de l’instance de cluster de basculement sont configurés pour utiliser un port entre 49 152 et 65 536 (la plage de port dynamique par défaut pour le protocole TCP/IP), ajoutez une exclusion pour chaque port. Cela empêche ainsi que le même port soit attribué dynamiquement à d’autres systèmes. L’exemple suivant crée une exclusion pour le port 59 999 :
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Pour comparer la liste de contrôle HADR aux autres meilleures pratiques, consultez la Liste de contrôle des meilleures pratiques relatives aux performances.
Paramètres de disponibilité de machine virtuelle
Pour atténuer l’effet des temps d’arrêt, prenez en compte les paramètres de disponibilité de machine virtuelle optimaux présentés ci-après :
- Pour une latence minimale, utilisez des groupes de placement de proximité avec l’accélération réseau.
- Placez les nœuds de cluster de machines virtuelles dans des zones de disponibilité distinctes pour une protection contre les défaillances au niveau du centre de données ou dans un groupe à haute disponibilité unique pour une redondance à plus faible latence au sein du même centre de données.
- Utilisez un système d’exploitation et des disques de données managés Premium pour les machines virtuelles dans un groupe à haute disponibilité.
- Configurez chaque couche Application dans des groupes à haute disponibilité distincts.
Quorum
Bien qu’un cluster à deux nœuds fonctionne sans ressource de quorum, les clients sont strictement tenus d’utiliser une ressource de quorum pour prendre en charge la production. La validation du cluster ne transmet pas de cluster sans ressource quorum.
Techniquement, un cluster à trois nœuds peut survivre à la perte d’un nœud (jusqu’à deux nœuds) sans ressource de quorum, mais dès que le cluster perd deux nœuds, en cas d’autre perte de nœud ou d’échec de communication, il y a un risque que les ressources clusterisées passent hors connexion pour empêcher un scénario Split-Brain. La configuration d’une ressource de quorum permet au cluster de continuer en ligne avec un seul nœud en ligne.
Le témoin de disque est l’option de quorum la plus résiliente, mais pour utiliser un témoin de disque sur SQL Server sur une machine virtuelle Azure, vous devez utiliser un disque partagé Azure, qui impose certaines limitations à la solution de haute disponibilité. Par conséquent, utilisez un témoin de disque lorsque vous configurez votre instance de cluster de basculement avec des disques partagés Azure ; sinon, utilisez un témoin de cloud dans la mesure du possible.
Le tableau suivant liste les options de quorum disponibles pour SQL Server sur les machines virtuelles Azure :
| Témoin cloud | Témoin de disque | Témoin de partage de fichiers | |
|---|---|---|---|
| Systèmes d’exploitation pris en charge | Windows Server 2016+ | Tous | Tous |
- Le témoin de cloud est idéal pour les déploiements sur plusieurs sites, dans plusieurs zones et plusieurs régions. Utilisez un témoin de cloud dans la mesure du possible sauf si vous utilisez une solution de cluster avec stockage partagé.
- Le témoin de disque est l’option de quorum la plus résiliente. Elle est privilégiée pour tous les clusters qui utilisent des disques partagés Azure (ou toute solution de disque partagé comme SCSI, iSCSI ou SAN Fiber Channel partagé). Un volume partagé en cluster ne peut pas être utilisé comme témoin de disque.
- Le témoin de partage de fichiers est approprié quand le témoin de disque et le témoin de cloud ne sont pas des options disponibles.
Pour bien démarrer, consultez Configurer un quorum de cluster.
Vote du quorum
Il est possible de changer le vote de quorum d’un nœud participant à un cluster de basculement Windows Server.
Lors de la modification des paramètres de vote de nœud, suivez ces instructions :
| Instructions relatives au vote de quorum |
|---|
| Commencez avec des nœuds qui n’ont pas de vote par défaut. Chaque nœud ne doit avoir un vote qu’avec une justification explicite. |
| Activez les votes pour les nœuds de cluster qui hébergent le réplica principal d’un groupe de disponibilité, ou les propriétaires préférés d’une instance de cluster de basculement. |
| Activez les votes pour les propriétaires de basculement automatique. Chaque nœud susceptible d’héberger un réplica principal ou une instance de cluster de basculement suite à un basculement automatique doit disposer d’un vote. |
| Si un groupe de disponibilité a plusieurs réplicas secondaires, activez uniquement les votes pour les réplicas qui ont un basculement automatique. |
| Désactivez les votes pour les nœuds qui se trouvent dans des sites de reprise d’activité après sinistre secondaires. Les nœuds des sites secondaires ne doivent pas contribuer à la décision de mettre un cluster hors connexion s’il n’y a aucun problème au niveau du site principal. |
| Faites en sorte d’avoir un nombre impair de votes, avec trois votes de quorum au minimum. Ajoutez un témoin de quorum pour disposer d’un vote supplémentaire si nécessaire dans un cluster à deux nœuds. |
| Réévaluez les affectations de vote après le basculement. Il n’est pas souhaitable de basculer dans une configuration de cluster qui ne prend pas en charge un quorum sain. |
Connectivité
Pour correspondre à l’expérience locale de connexion à votre écouteur de groupe de disponibilité ou instance de cluster de basculement, déployez vos machines virtuelles SQL Server sur plusieurs sous-réseaux au sein du même réseau virtuel. Quand vous avez plusieurs réseaux, vous n’avez pas besoin d’une dépendance supplémentaire sur Azure Load Balancer ni d’un nom de réseau distribué pour acheminer votre trafic vers votre écouteur.
Pour simplifier votre solution HADR, déployez vos machines virtuelles SQL Server sur plusieurs sous-réseaux quand cela est possible. Pour plus d’informations, consultez Groupe de disponibilité à plusieurs sous-réseaux et Instance de cluster de basculement à plusieurs sous-réseaux.
Si vos machines virtuelles SQL Server se trouvent dans un seul sous-réseau, il est possible de configurer un nom de réseau virtuel (VNN) et Azure Load Balancer, ou un nom de réseau distribué (DNN) à la fois pour les instances de cluster de basculement et les écouteurs de groupe de disponibilité.
Le nom de réseau distribué est l’option de connectivité recommandée quand elle est disponible :
- La solution de bout en bout est plus robuste, car vous n’avez plus à gérer la ressource d’équilibreur de charge.
- L’élimination des sondes de l’équilibreur de charge réduit la durée du basculement.
- Le DNN simplifie l’approvisionnement et la gestion de l’instance de cluster de basculement ou de l’écouteur de groupe de disponibilité avec SQL Server sur des machines virtuelles Azure.
Tenez compte des limitations suivantes :
- Le pilote client doit prendre en charge le paramètre
MultiSubnetFailover=True. - La fonctionnalité DNN est disponible à partir de SQL Server 2016 SP3, SQL Server 2017 CU25 et SQL Server 2019 CU8 sur Windows Server 2016 et versions ultérieures.
Pour en savoir plus, consultez Vue d’ensemble du cluster de basculement Windows Server.
Pour configurer la connectivité, consultez les articles suivants :
- Groupe de disponibilité : Configurer le DNN, Configurer le VNN
- Instance de cluster de basculement : Configurer le DNN, Configurer le VNN.
La plupart des fonctionnalités SQL Server fonctionnent de manière transparente avec les FCI et les groupes de disponibilité lors de l’utilisation du DNN, mais certaines fonctionnalités peuvent nécessiter une attention particulière. Pour en savoir plus, consultez Interopérabilité FCI et DNN et Interopérabilité AG et DNN.
Conseil
Définissez le paramètre MultiSubnetFailover sur = true dans la chaîne de connexion, même pour les solutions HADR qui s’étendent sur un seul sous-réseau afin de prendre en charge la répartition ultérieure de sous-réseaux sans qu’il soit nécessaire de mettre à jour les chaînes de connexion.
Pulsation et seuil
Assouplissez le paramétrage de la pulsation et du seuil du cluster. Les paramètres de pulsation et de seuil du cluster par défaut sont conçus pour les réseaux locaux optimisés et ne tiennent pas compte de l’augmentation potentielle de la latence dans un environnement cloud. Le réseau de pulsation est géré avec le protocole UDP 3343, qui est traditionnellement beaucoup moins fiable que le protocole TCP et plus sujet aux conversations incomplètes.
Ainsi, quand vous exécutez des nœuds de cluster pour SQL Server sur des solutions haute disponibilité de machine virtuelle Azure, modifiez les paramètres du cluster pour assouplir la supervision afin d’éviter les défaillances temporaires dues au risque accru de latence ou d’échec du réseau, à la maintenance Azure ou à l’apparition de goulots d’étranglement des ressources.
Les paramètres de délai et de seuil ont un effet cumulatif sur la détection d’intégrité totale. Par exemple, si vous définissez CrossSubnetDelay pour envoyer une pulsation toutes les 2 secondes et CrossSubnetThreshold sur 10 pulsations manquées avant de procéder à la récupération, le cluster peut avoir une tolérance réseau totale de 20 secondes avant que l’action de récupération soit effectuée. En général, il est préférable de continuer à envoyer des pulsations fréquentes, mais avec des seuils plus élevés.
Pour garantir qu’une récupération est effectuée en cas de panne réelle tout en bénéficiant d’une plus grande tolérance pour les problèmes temporaires, assouplissez vos paramètres de délai et de seuil en appliquant les valeurs recommandées détaillées dans le tableau suivant :
| Paramètre | Windows Server 2012 ou version ultérieure | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 seconde | 2 secondes |
| SameSubnetThreshold | 40 pulsations | 10 pulsations (max.) |
| CrossSubnetDelay | 1 seconde | 2 secondes |
| CrossSubnetThreshold | 40 pulsations | 20 pulsations (max.) |
Utilisez PowerShell pour modifier les paramètres de votre cluster :
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Utilisez PowerShell pour vérifier vos modifications :
get-cluster | fl *subnet*
Tenez compte des éléments suivants :
- Cette modification est immédiate. Le redémarrage du cluster ou de ressources n’est pas nécessaire.
- Les valeurs d’un même sous-réseau ne doivent pas être supérieures à celles de plusieurs sous-réseaux.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Choisissez des valeurs souples en fonction des temps d’arrêt tolérables et du délai avant exécution d’une action corrective selon votre application, vos besoins métier et votre environnement. Si vous ne pouvez pas dépasser les valeurs par défaut de Windows Server 2019, vous devez au moins essayer de les appliquer :
Le tableau suivant détaille les valeurs par défaut pour référence :
| Paramètre | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 seconde | 1 seconde | 1 seconde |
| SameSubnetThreshold | 20 pulsations | 10 pulsations | 5 pulsations |
| CrossSubnetDelay | 1 seconde | 1 seconde | 1 seconde |
| CrossSubnetThreshold | 20 pulsations | 10 pulsations | 5 pulsations |
Pour en savoir plus, consultez Réglage des seuils réseau de cluster de basculement.
Supervision assouplie
Si le réglage des paramètres de pulsation et de seuil de votre cluster, tel qu’il est recommandé, n’offre pas une tolérance suffisante et que vous constatez toujours des basculements dus à des problèmes temporaires plutôt qu’à de véritables pannes, vous pouvez configurer votre surveillance AG ou FCI pour qu’elle soit plus détente. Dans certains scénarios, il peut être avantageux d’assouplir la supervision pendant un certain temps en fonction du niveau d’activité. Par exemple, vous pouvez assouplir la supervision quand vous exécutez des charges de travail gourmandes en E/S : sauvegardes de base de données, maintenance d’index, DBCC CHECKDB, etc. Une fois l’activité terminée, définissez votre supervision sur des valeurs moins souples.
Avertissement
La modification de ces paramètres peut masquer un problème sous-jacent et doit être utilisée comme solution temporaire pour réduire, plutôt qu’éliminer, la probabilité de défaillance. Les problèmes sous-jacents doivent tout de même être investigués et traités.
Commencez par augmenter les paramètres suivants par rapport aux valeurs par défaut pour une supervision assouplie et ajustez-les si nécessaire :
| Paramètre | Valeur par défaut | Valeur assouplie | Description |
|---|---|---|---|
| Délai d’attente de contrôle d’intégrité | 30000 | 60000 | Détermine l’intégrité du nœud ou du réplica principal. La DLL de ressource de cluster sp_server_diagnostics retourne les résultats à un intervalle correspondant à 1/3 du seuil du délai d’attente de contrôle d’intégrité. Si sp_server_diagnostics est lent ou ne retourne aucune information, la DLL de ressource attend la fin de l’intervalle du seuil du délai d’attente de contrôle d’intégrité avant de déterminer que la ressource ne répond pas et d’initier un basculement automatique, si elle est configurée à cet effet. |
| Niveau de condition d'échec | 3 | 2 | Conditions qui déclenchent un basculement automatique. Il existe cinq niveaux de condition d’échec, allant du moins restrictif (niveau 1) au plus restrictif (niveau 5). |
Utilisez T-SQL (Transact-SQL) pour modifier le délai d’attente de contrôle d’intégrité et les conditions d’échec pour les groupes de disponibilité et les FCI.
Pour les groupes de disponibilité :
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Pour les instances de cluster de basculement :
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Commencez avec les paramètres recommandés suivants en fonction des groupes de disponibilité et ajustez-les si nécessaire :
| Paramètre | Valeur par défaut | Valeur assouplie | Description |
|---|---|---|---|
| Délai d’expiration du bail | 20000 | 40000 | Empêche le Split-Brain. |
| Délai d’expiration de session | 10000 | 20000 | Vérifie les problèmes de communication entre les réplicas. Le délai d’expiration de session est une propriété de réplica qui contrôle le temps (en secondes) durant lequel un réplica de disponibilité attend une réponse ping d’un réplica connecté avant de considérer que la connexion a échoué. Par défaut, un réplica attend une réponse ping pendant 10 secondes. Cette propriété de réplica s’applique uniquement à la connexion entre un réplica secondaire donné et le réplica principal du groupe de disponibilité. |
| Nombre maximal d’échecs dans la période spécifiée | 2 | 6 | Permet d’éviter le déplacement indéfini d’une ressource clusterisée dans le cadre de plusieurs défaillances de nœud. Une valeur trop faible peut entraîner un état d’échec du groupe de disponibilité. Augmentez la valeur pour éviter les interruptions courtes dues à des problèmes de performances, car une valeur trop faible peut entraîner un état d’échec du groupe de disponibilité. |
Avant d’apporter des modifications, tenez compte des points suivants :
- Ne définissez pas les valeurs de délai d’expiration en dessous de leur valeur par défaut.
- Utilisez cette équation pour calculer la valeur maximale du délai d’expiration du bail :
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Commencez par 40 secondes. Si vous utilisez les valeurs assouplies deSameSubnetThresholdetSameSubnetDelayqui ont été recommandées précédemment, ne dépassez pas 80 secondes pour la valeur du délai d’expiration du bail. - Pour les réplicas avec validation synchrone, la définition du délai d’expiration de session sur une valeur élevée peut augmenter les temps d’attente HADR_sync_commit.
Délai d’expiration du bail
Utilisez le Gestionnaire du cluster de basculement pour modifier les paramètres de délai d’expiration du bail pour votre groupe de disponibilité. Consultez documentation sur le contrôle d’intégrité de bail de groupe de disponibilité avec SQL Server pour obtenir des étapes détaillées.
Délai d’expiration de session
Utilisez T-SQL (Transact-SQL) pour modifier le délai d’expiration de session pour un groupe de disponibilité :
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Nombre maximal d’échecs dans la période spécifiée
Utilisez le Gestionnaire du cluster de basculement pour modifier la valeur Nombre maximal d’échecs dans la période spécifiée :
- Dans le volet de navigation, sélectionnez Rôles.
- Sous Rôles, cliquez avec le bouton droit sur la ressource clusterisée et choisissez Propriétés.
- Sélectionnez l’onglet Basculement et augmentez la valeur Nombre maximal d’échecs dans la période spécifiée selon vos besoins.
Limites des ressources
Les limites de machine virtuelle ou de disque peuvent entraîner un goulot d’étranglement des ressources qui impacte l’intégrité du cluster et perturbe le contrôle d’intégrité. Si vous rencontrez des problèmes avec les limites de ressources, tenez compte des points suivants :
- Assurez-vous que le système d’exploitation, les pilotes et SQL Server disposent de la version la plus récente.
- Optimisez SQL Server sur l’environnement de machine virtuelle Azure comme décrit dans les instructions relatives aux performances pour SQL Server sur machines virtuelles Azure.
- Diminuez ou répartissez la charge de travail pour réduire l’utilisation sans dépasser les limites de ressources.
- Ajustez la charge de travail SQL Server si vous en avez la possibilité, notamment :
- Ajoutez des index ou optimisez-les.
- Mettez à jour les statistiques si nécessaire et, si possible, avec une analyse complète.
- Utilisez des fonctionnalités telles que Resource Governor (à partir de SQL Server 2014, Entreprise uniquement) pour limiter l’utilisation des ressources pendant des charges de travail spécifiques telles que les sauvegardes ou la maintenance d’index.
- Passez à une machine virtuelle ou à un disque dont les limites sont plus élevées, répondant aux exigences de votre charge de travail ou les dépassant.
Mise en réseau
Déployez vos machines virtuelles SQL Server sur plusieurs sous-réseaux quand cela est possible afin d’éviter de dépendre d’Azure Load Balancer ou d’un nom de réseau distribué (DNN) pour acheminer le trafic vers votre solution HADR.
Utilisez une seule carte réseau (NIC) par serveur (nœud de cluster). Les réseaux Azure intègrent une redondance physique, ce qui rend inutiles les cartes réseau supplémentaires sur un cluster invité de machine virtuelle Azure. Le rapport de validation du cluster vous avertit que les nœuds sont accessibles uniquement sur un seul réseau. Vous pouvez ignorer cet avertissement sur les clusters de basculement invités de machines virtuelles Azure.
Les limites de bande passante pour une machine virtuelle particulière sont partagées entre les cartes réseau et l’ajout d’une carte réseau supplémentaire n’améliore pas les performances des groupes de disponibilité pour SQL Server sur les machines virtuelles Azure. Par conséquent, il n’est pas nécessaire d’ajouter une deuxième carte réseau.
Le service DHCP non compatible RFC dans Azure peut provoquer l’échec de la création de certaines configurations de cluster de basculement. Cet échec se produit car une adresse IP dupliquée est affectée au nom réseau du cluster, par exemple la même adresse IP que l’un des nœuds du cluster. Cela constitue un problème quand vous utilisez des groupes de disponibilité, qui dépendent de la fonctionnalité Cluster de basculement Windows.
Examinez le scénario où un cluster à deux nœuds est créé et mis en ligne :
- Le cluster est en ligne, puis NODE1 demande une adresse IP assignée dynamiquement pour le nom du réseau de clusters.
- Le service DHCP ne fournit aucune adresse IP autre que celle de NODE1, car il reconnaît que la demande provient de NODE1.
- Windows détecte qu’une adresse en double est affectée à NODE1 et au nom réseau de cluster de basculement, et le groupe de cluster par défaut n’est pas mis en ligne.
- Le groupe dr cluster par défaut est déplacé vers NODE2. NODE2 traite l’adresse IP de NODE1 comme adresse IP du cluster et met le groupe de cluster par défaut en ligne.
- Quand NODE2 tente d’établir la connexion avec NODE1, les paquets dirigés vers NODE1 ne quittent jamais NODE2, car il résout l’adresse IP de NODE1 en lui-même. NODE2 ne peut pas établir la connexion avec NODE1, puis perd le quorum et arrête le cluster.
- NODE1 peut envoyer des paquets à NODE2, mais NODE2 ne peut pas répondre. NODE1 perd le quorum et arrête le cluster.
Vous pouvez éviter ce scénario en affectant une adresse IP statique inutilisée au nom réseau du cluster afin de mettre le nom réseau de cluster en ligne et d’ajouter l’adresse IP à Azure Load Balancer.
Si le moteur de base de données SQL Server, l’écouteur de groupe de disponibilité Always On, la sonde d’intégrité de l’instance de cluster de basculement, le point de terminaison de mise en miroir de bases de données, la ressource IP principale du cluster ou toute autre ressource SQL est configuré pour utiliser un port compris entre 49 152 et 65 536 (plage de port dynamique par défaut pour TCP/IP), ajoutez une exclusion pour chaque port. De cette façon, d’autres processus système ne se voient pas affecter dynamiquement le même port. L’exemple suivant crée une exclusion pour le port 59 999 :
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Il est important de configurer l’exclusion de port quand le port n’est pas utilisé. Dans le cas contraire, la commande échoue avec un message du type « Le processus ne peut pas accéder au fichier, car il est utilisé par un autre processus ».
Pour confirmer que les exclusions ont été configurées correctement, utilisez la commande suivante : netsh int ipv4 show excludedportrange tcp.
La définition de cette exclusion pour le port de sonde IP du rôle de groupe de disponibilité doit empêcher des événements comme ID d’événement : 1069 avec l’état 10048. Cet événement est visible dans les événements du cluster de basculement Windows avec le message suivant :
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Cela peut être dû à un processus interne prenant le même port défini comme port de sonde. N’oubliez pas que le port de sonde est utilisé pour vérifier l’état d’une instance de pool de back-ends à partir d’Azure Load Balancer.
Si la sonde d’intégrité ne parvient pas à obtenir une réponse d’une instance de back-end, aucune nouvelle connexion n’est envoyée à cette instance de back-end tant que la sonde d’intégrité ne réussit pas à nouveau.
Problèmes connus
Passez en revue les résolutions de certains problèmes et erreurs courants.
La contention de ressources (E/S en particulier) entraîne le basculement
Si la capacité d’E/S ou du processeur de la machine virtuelle est insuffisante, cela peut entraîner le basculement de votre groupe de disponibilité. La méthode la plus fiable pour identifier la cause du basculement automatique consiste à déterminer la contention qui se produit juste avant le basculement. Supervisez les machines virtuelles Azure afin d’examiner les métriques d’utilisation des E/S de stockage pour comprendre la latence au niveau de la machine virtuelle ou du disque.
Pour passer en revue l’événement global de E/S insuffisants de la machine virtuelle Azure, procédez comme suit :
Accédez à votre machine virtuelle dans le portail Azure, et non aux machines virtuelles SQL.
Sélectionnez Métriques sous Supervision pour ouvrir la page Métriques.
Sélectionnez Heure locale pour spécifier l’intervalle de temps qui vous intéresse et le fuseau horaire local de la machine virtuelle ou UTC (temps universel coordonné)/GMT.
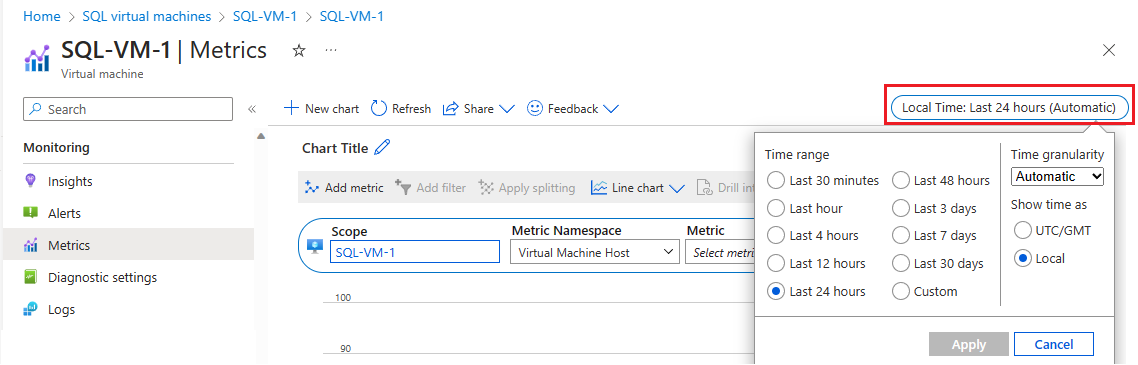
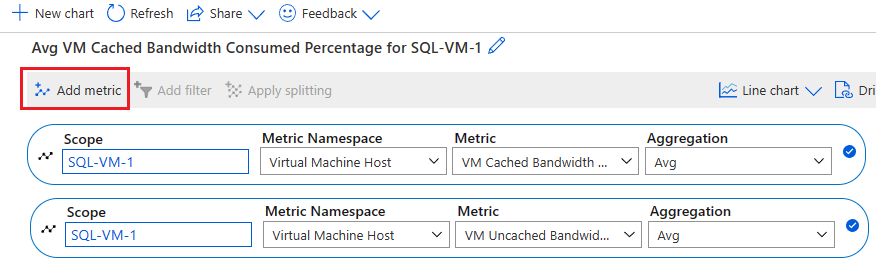
Sélectionnez Ajouter une métrique pour ajouter les deux métriques suivantes afin d’afficher le graphique :
- Pourcentage de bande passante en cache consommée par la machine virtuelle
- Pourcentage de bande passante non mise en cache consommée par la machine virtuelle
HostEvents de la machine virtuelle Azure provoque le basculement
Il est possible qu’un HostEvent de machine virtuelle Azure entraîne le basculement de votre groupe de disponibilité. Si vous pensez qu’un HostEvent de machine virtuelle Azure a entraîné un basculement, vous pouvez vérifier le journal d’activité Azure Monitor et la vue d’ensemble Resource Health de la machine virtuelle Azure.
Le journal d’activité Azure Monitor est un journal de plateforme, dans Azure, qui fournit des insights pour tous les événements de niveau abonnement. Le journal d’activité inclut des informations telles que le moment auquel une ressource a été modifiée ou une machine virtuelle démarrée. Vous pouvez afficher le journal d’activité dans le portail Azure, ou récupérer des entrées avec PowerShell et Azure CLI.
Pour vérifier le journal d’activité Azure Monitor, procédez comme suit :
Accéder à votre machine virtuelle dans le portail Azure
Sélectionnez Journal d’activité dans le volet Machine virtuelle
Sélectionnez Intervalle de temps, puis choisissez le délai d’exécution au cours duquel votre groupe de disponibilité a basculé. Sélectionnez Apply.

Si Azure dispose d’informations supplémentaires sur la cause racine d’une indisponibilité lancée par la plateforme, ces informations peuvent être publiées à la page Machine virtuelle Azure VM – Vue d’ensemble de Resource Health jusqu’à 72 heures après l’indisponibilité initiale. Ces informations ne sont disponibles que pour les machines virtuelles pour le moment.
- Accéder à votre machine virtuelle dans le portail Azure
- Sélectionnez Resource Health sous le volet Intégrité.
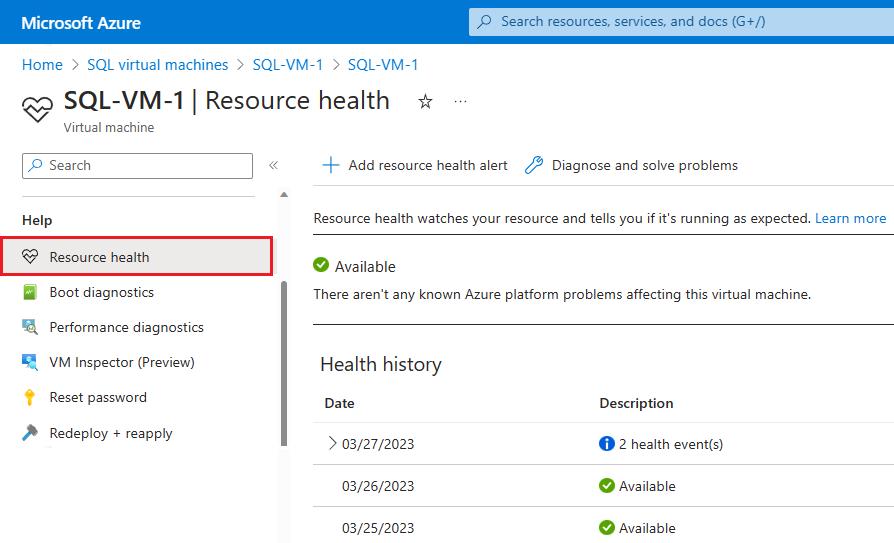
Vous pouvez également configurer des alertes en fonction des événements d’intégrité sur cette page.
Nœud de cluster supprimé de l’appartenance
Si les paramètres de pulsation et de seuil de cluster de Windows sont trop agressifs pour votre environnement, le message suivant peut apparaître fréquemment dans le journal des événements système.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Pour plus d’informations, consultez Résolution d’un problème de cluster avec l’ID d’événement 1135.
Le bail a expiré / le bail n’est plus valide
Une supervision trop agressive pour votre environnement peut entraîner des redémarrages, des échecs ou des basculements fréquents des groupe de disponibilité et des instances de cluster de basculement. En outre, pour les groupes de disponibilité, vous pouvez voir les messages suivants dans le journal des erreurs SQL Server :
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Délai de connexion
Si le délai d’expiration de session est trop agressif pour votre environnement de groupe de disponibilité, vous pouvez voir les messages suivants fréquemment :
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Pas de basculement du groupe
Si la valeur Nombre maximal d’échecs dans la période spécifiée est trop faible et que vous rencontrez des échecs intermittents dus à des problèmes temporaires, votre groupe de disponibilité peut se retrouver en état d’échec. Augmentez cette valeur pour tolérer davantage d’échecs temporaires.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Événement 1196 : la ressource de nom réseau n’a pas pu inscrire un nom DNS associé
- Vérifiez les paramètres de carte réseau pour chacun de vos nœuds de cluster afin de vous assurer qu’aucun enregistrement DNS externe n’est présent.
- Vérifiez que l’enregistrement A de votre cluster existe sur vos serveurs DNS internes. Si ce n’est pas le cas, créez un enregistrement A manuellement dans le serveur DNS pour l’objet du contrôle d’accès aux clusters et cochez la case Autoriser tout utilisateur identifié à mettre à jour les enregistrements DNS avec le même nom de propriétaire.
- Mettez hors connexion la ressource « Nom du cluster » avec la ressource IP et corrigez-la.
Événement 157 : le disque a été supprimé de manière inattendue.
Cela peut se produire si la propriété Espaces de stockage AutomaticClusteringEnabled est définie sur True pour un environnement de groupes de disponibilité. Remplacez-le par False. De plus, l’exécution d’un rapport de validation avec l’option de stockage peut déclencher l’événement de suppression inattendue ou de réinitialisation du disque. La limitation du système de stockage peut également déclencher l’événement de suppression inattendue du disque.
Événement 1206 : la ressource de nom de réseau en cluster ne peut pas être mise en ligne.
L’objet ordinateur associé à la ressource n’a pas pu être mis à jour dans le domaine. Assurez-vous que vous disposez des autorisations appropriées sur le domaine
Erreurs de clustering Windows
Vous pouvez rencontrer des problèmes lors de la configuration d’un cluster de basculement Windows ou de sa connectivité si vous n’avez pas de ports de service de cluster ouverts pour la communication.
Si vous êtes sur Windows Server 2019 et que vous ne voyez pas d’adresse IP de cluster Windows, vous avez configuré un nom de réseau distribué, qui est uniquement pris en charge sur SQL Server 2019. Si vous avez des versions antérieures de SQL Server, vous pouvez supprimer et recréer le cluster à l’aide d’un nom réseau.
Consultez les autres erreurs d’événements de clustering de basculement Windows et leurs solutions ici
Étapes suivantes
Pour en savoir plus, consultez :
- Paramètres HADR pour SQL Server sur des machines virtuelles Azure
- Cluster de basculement Windows Server avec SQL Server sur des machines virtuelles Azure
- Groupes de disponibilité Always On avec SQL Server sur les machines virtuelles Azure
- Cluster de basculement Windows Server avec SQL Server sur des machines virtuelles Azure
- Instances de cluster de basculement avec SQL Server sur des machines virtuelles Azure
- Vue d’ensemble des instances de cluster de basculement
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour