Produits de données d'analyse à l'échelle du cloud dans Azure
Les produits de données sont des données servies en tant que produits et calculés, enregistrés et servis par des services de persistance polyglotte, qui peuvent être requis par certains cas d’usage. Le processus de création et de service d’un produit de données peut nécessiter des services et technologies qui ne sont pas inclus dans les services principaux de la zone d’atterrissage des données . Par exemple, il s’agirait de rapports avec des exigences de niche, telles que la conformité et la déclaration fiscale.
Remarques relatives à la conception
Une zone d’atterrissage de données peut comporter plusieurs produits de données créés par ingestion des données depuis l’intérieur d’une même zone d’atterrissage de données ou à partir de plusieurs zones d’atterrissage de données. Cette situation est présentée dans le diagramme suivant.
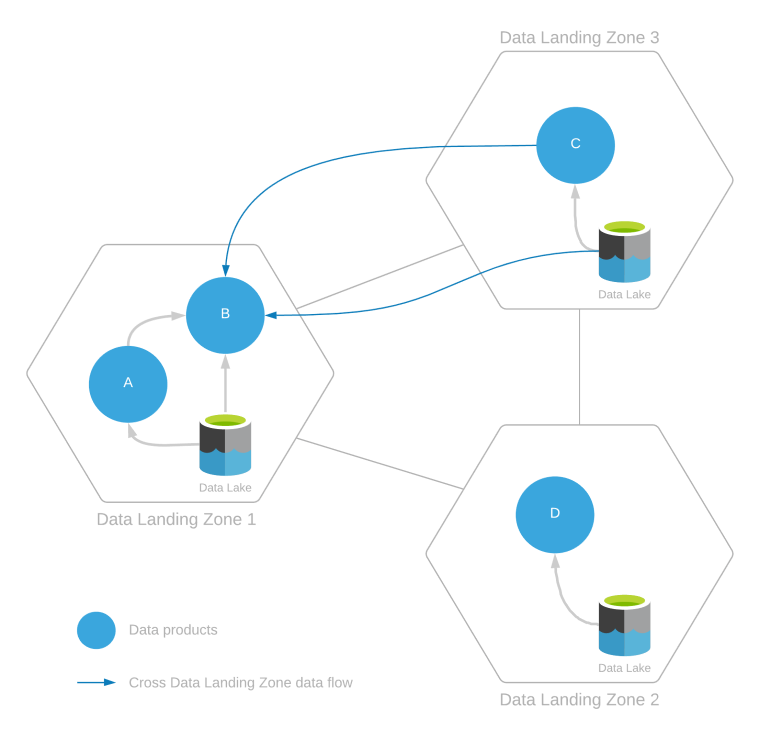
L’exemple ci-dessus montre plusieurs choses :
- Consommation de données intrazone :
- Le produit de données B consomme les données du produit de données A et d’autres données ou produits de données existants dans le lac de données dans sa propre zone d’atterrissage.
- Les produits de données C et D ne consomment que des données issues de leur propre zone d’atterrissage de données.
- Consommation de données interzone :
- Le produit B consomme également des données issues du produit de données C et des données dans le lac de données Data Landing Zone 3.
Important
Dans le cas de la consommation de données interzone, une approbation de l’équipe chargée de l’exploitation de la zone d’atterrissage de données et de l’exploitation des intégrations pour Data Landing Zone 3 est nécessaire. En effet, le produit B est créé en lisant les données de Data Landing Zone 3.
Important
Le produit de données B consomme des données issues des produits de données A et C. Il doit pour cela inscrire sa consommation d’un produit de données au moyen de contrats de partage de données. Ce contrat doit mettre à jour la traçabilité du produit de données A vers le produit de données B et du produit de données C vers le produit de données B.
Le groupe de ressources d’un produit de données inclut tous les services nécessaires à sa création et à sa maintenance. Nous pouvons appeler ce groupe de ressources une application de données. Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL Database, Azure Database pour MySQL et Azure Cosmos DB constituent des exemples de services pouvant faire partie d’une application de données. Pour plus d’informations, consultez les exemples d’applications de données.
Les produits de données ont des données provenant de sources de données READ qui ont appliqué certaines transformations de données. Il peut s’agit par exemple d’un jeu de données ou d’un rapport décisionnel réorganisé.
Recommandations de conception
Créez des produits de données au sein de votre zone d’atterrissage de données en respectant des principes de conception qui permettent d’évoluer avec la gouvernance des données. Les sections suivantes fournissent des recommandations de conception pour vous aider à planifier votre écosystème d’applications de données.
Déploiement de plusieurs groupes de ressources
Chaque application de données constitue un groupe de ressources. Comme les applications de données sont des services de persistance calculée ou polyglotte, ou les deux, ils peuvent n’être nécessaires que dans certains cas d’usage. Par conséquent, on peut les considérer comme un composant facultatif d’une zone d’atterrissage de données. Dans un cas où vous avez besoin d’applications de données, créez plusieurs groupes de ressources par application de données, comme le montre le diagramme suivant.

Définition de garde-fous
Azure Policy pilote la configuration par défaut des services au sein d’une zone d’atterrissage de données. Considérez l’analytique opérationnelle comme plusieurs groupes de ressources que votre équipe chargée des produits de données peut demander à partir d’un catalogue de services standard. Avec Azure Policy, vous pouvez configurer la limite de sécurité et l’ensemble de fonctionnalités requis.
Important
Pour favoriser la cohérence, configurez une Azure Policy pour chaque application de données.
Consommation de données à partir de nombreux emplacements
Les applications de données gèrent et organisent les données sur plusieurs ressources de données, leur donnent du sens et présentent les insights obtenus. Un produit de données est le résultat des données provenant d’une ou de plusieurs applications au sein de zones d’atterrissage de données. Autorisez vos applications de données à accéder aux données provenant de plusieurs sources et de diverses sources si nécessaire.
Mise à l’échelle en fonction des besoins
Les services qui composent des applications de données sont des déploiements incrémentiels vers la zone d’atterrissage des données. Mettez à l’échelle vos applications de données en fonction des besoins.
Activation de la recherche de données
Inscrivez automatiquement vos produits de données dans un catalogue de données tel qu’Azure Purview pour autoriser l’analyse des données.
Identification des produits de données
Lors du démarrage de la planification d’une zone d’atterrissage des données, identifiez autant de produits de données (et les applications de données qui les génèrent et les conservez) que nécessaire pour vous aider à piloter votre architecture d’application de produit de données. La conformité à la gouvernance de la plateforme implémentée doit jouer le rôle le plus important dans vos décisions.
Concentrez-vous sur la façon dont vos applications de données sont des producteurs de données et des consommateurs pour d’autres utilisateurs. Par exemple, supposons que vous avez identifié une suite de produits de données (A, B, C et D) qui sont produits et consommés. Vous avez besoin de produits de données A et D comme sources pour les données dans l’application de données B pour le produit de données B. Le produit de données B est créé à partir des données consommées par l’application de données B à partir des produits de données A et D. L’application de données B agit comme un producteur de données lui-même, et produit également des données pour le produit de données C.
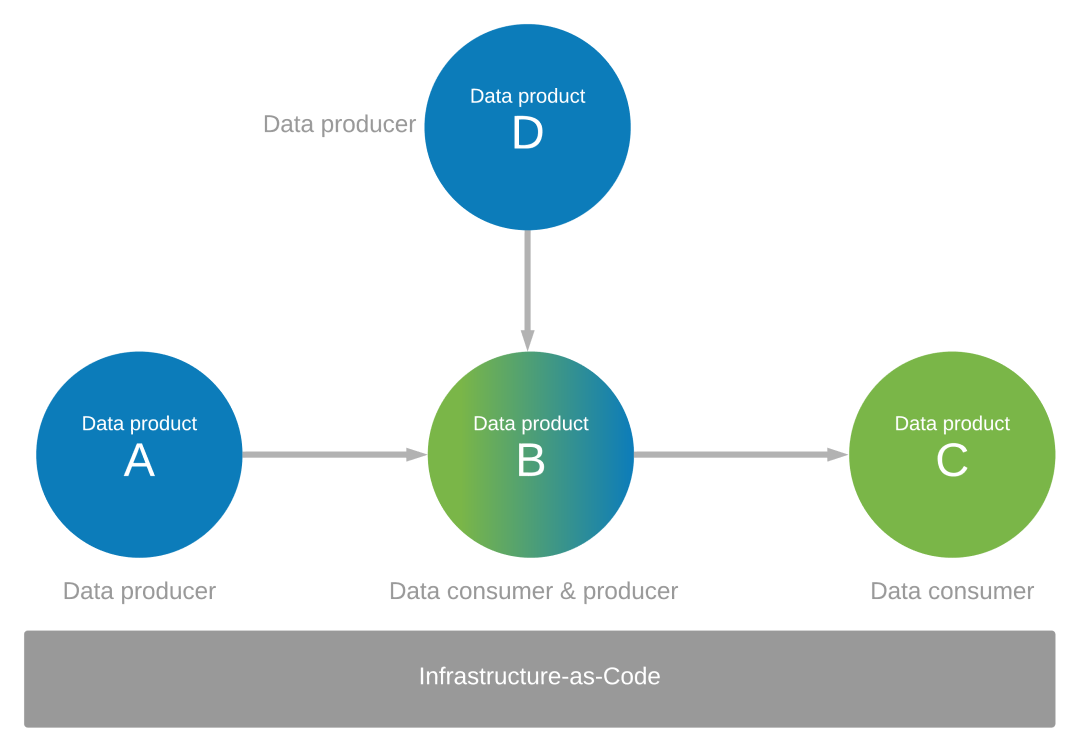
Contrôler votre environnement d’application de données avec l’infrastructure en tant que code
La gouvernance et l’infrastructure en tant que code doivent contrôler l’environnement d’application de données dans l’écosystème de vos produits de données, comme illustré dans le diagramme précédent.
Publication de modèles de données
Vos équipes chargées des produits de données doivent publier leur modèle de données dans un référentiel de modélisation.
Définition des attentes pour les utilisateurs de produits de données
Mettez à jour vos contrats de partage de données avec des contrats de niveau de service et des certifications pour vos produits de données afin de transmettre des attentes précises aux utilisateurs potentiels du produit de données.
Capture de la traçabilité
Si le produit de données B est créé à partir de données provenant de produits de données A et D, la traçabilité doit être capturée de A et D à B. Une traçabilité supplémentaire doit également être capturée pour le produit de données C, car elle est créée à l’aide des données du produit de données B. La traçabilité mise à jour doit être capturée dans une application de traçabilité des données avant chaque publication de votre produit de données.
Remarque
Azure Pipelines vous permet de créer des portes d’approbation pour appeler des fonctions visant à vérifier que les métadonnées, la traçabilité et les contrats de niveau de service sont enregistrés dans le bon service de gouvernance.
Définir l’architecture de l’application de données
Vous devez créer une architecture détaillée pour chaque produit de données qui définit entièrement sa relation avec d’autres produits de données, ses dépendances et ses exigences d’accès.
Exemple de scénario de conception
Pour comprendre le processus de définition de l’architecture, prenons l’exemple suivant d’une institution financière et de son produit de données de surveillance de crédit.
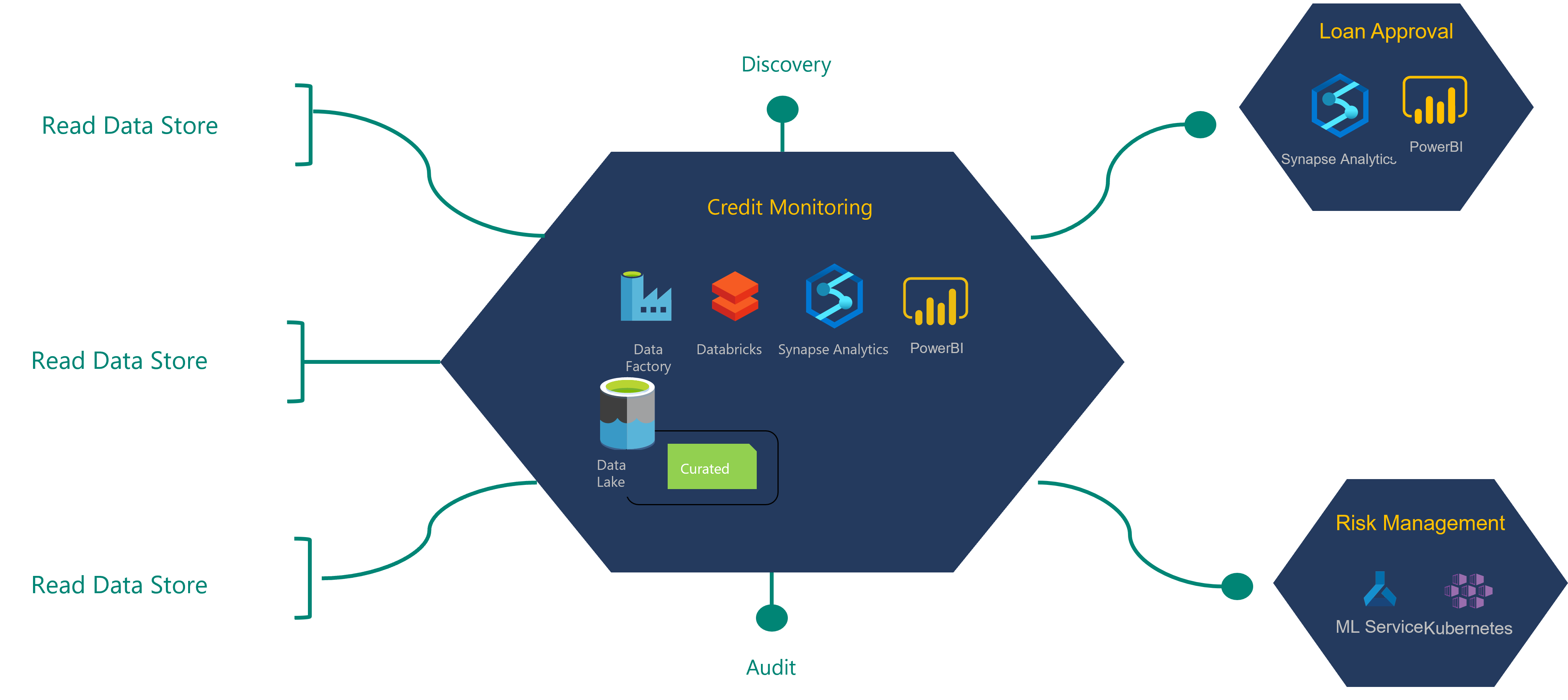
Le produit de données de surveillance de crédit présenté dans ce diagramme consomme des données provenant d’un magasin de données en lecture qui a été ingéré par l’équipe chargée de l’exploitation des intégrations. Il produit des produits de données également consommés par deux autres produits de données.
Remarque
Une source de données ou un magasin de données en lecture est également appelé source d’enregistrement de référence. Ces sources de données ont été nettoyées, mais aucune transformation n’a été appliquée.
L’équipe chargée du produit des données de surveillance de crédit demande l’accès en lecture aux magasins de données en lecture dont elle a besoin pour sa création de produit de données. Leurs demandes sont transmises aux propriétaires des données à des fins d’approbation. Une fois qu’elle reçoit l’approbation, l’équipe produit peut commencer à créer son application de données.
Les données de la source de données en lecture sont transformées dans le(s) produit(s) de données de surveillance de crédit. Tous les nouveaux produits de données sont stockés dans la couche organisée du lac de données. Ces nouveaux produits de données et la nouvelle lignée de données doivent être enregistrés dans le cadre du processus de déploiement DevOps. Une fonction peut confronter les métadonnées inscrites à la structure physique de la ressource de données. Elle doit inscrire la dépendance aux ressources de données de la source de données en lecture et les produits de données.
L’équipe chargée du produit de données d’approbation de prêt dépend de certaines des produits de données de surveillance de crédit. Ils peuvent demander l’accès en lecture aux produits de données de surveillance du crédit dont ils ont besoin pour leurs produits de données. Une fois qu’ils ont publié leur produit de données d’approbation de prêt et son application de données, toutes les ressources de produit de données, la traçabilité et les modèles doivent être inscrits dans les services de gouvernance appropriés.
Exemples d’applications de données
Les sections suivantes contiennent des exemples d’applications de données pour illustrer davantage les scénarios d’application de données.
Application de données pour l’analytique données et la science des données
Une application pour l’analytique et la science des données peut contenir les services présentés dans l’exemple d’application de produit de données product-analytics-rg.

Notes
L’application de données ci-dessus est disponible sous la forme d’un modèle qui déploie un ensemble de services que vous pouvez utiliser pour l’analytique données et la science des données. Comme tous nos modèles, ce modèle d’application de produit de données constitue un blueprint permettant de mettre rapidement en œuvre des environnements pour les équipes transverses. Les services dont vous n’avez pas besoin doivent être explicitement désactivés.
Le modèle d’analytique de produit de données contient tous les modèles de déploiement d’un produit de données pour l’analytique et la science des données à l’intérieur d’une zone d’atterrissage de scénario d’analyse à l’échelle du cloud.
Les artefacts de déploiement et de code incluent les services suivants :
- Machine Learning
- Key Vault
- Application Insights
- Stockage
- Container Registry
- Cognitive Services (facultatif)
- Data Factory (sélection entre Data Factory et Synapse)
- Synapse Workspace (choisir entre Data Factory et Synapse)
- Azure Search (facultatif)
- Pool SQL (facultatif)
- Pool BigData (facultatif)
Application des données par lot
Le modèle d’application de données par lot contient tous les modèles de déploiement d’un produit de données pour le traitement des données par lots à l’intérieur d’une zone d’atterrissage de scénario d’analytique à l’échelle du cloud.
Les artefacts de déploiement et de code incluent les services suivants :

- Key Vault
- Data Factory (sélection entre Data Factory et Synapse)
- Azure Cosmos DB (facultatif)
- Synapse Workspace (choisir entre Data Factory et Synapse)
- Base de données MySQL (facultatif)
- Base de données Azure SQL (facultatif)
- Base de données PostgreSQL (facultatif)
- Base de données MariaDB (facultatif)
- Pool SQL (facultatif)
- Serveur SQL (facultatif)
- Pool élastique SQL (facultatif)
- Pool BigData
Application de données de streaming
Le modèle d’application de données de streaming contient tous les modèles de déploiement d’un produit de données pour le traitement des données en temps réel à l’intérieur d’une zone d’atterrissage de scénario d’analytique à l’échelle du cloud
Les artefacts de déploiement et de code incluent les services suivants :

- Key Vault
- Hubs d'événements
- IoT Hub
- Stream Analytics (facultatif)
- Azure Cosmos DB (facultatif)
- Espace de travail Synapse
- Base de données Azure SQL (facultatif)
- Pool SQL (facultatif)
- Serveur SQL (facultatif)
- Pool élastique SQL (facultatif)
- Pool BigData
- Explorateur de données (facultatif)
Pour rechercher les référentiels contenant les modèles de déploiement mentionnés précédemment, reportez-vous aux modèles de déploiement pour l’analytique à l’échelle du cloud