Guide des performances et du réglage du mappage de flux de données
Article
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données de mappage dans les pipelines Azure Data Factory et Synapse fournissent une interface sans code pour concevoir et exécuter des transformations de données à grande échelle. Si vous n’êtes pas familiarisé avec les flux de données de mappage, consultez Vue d’ensemble des flux de données de mappage. Cet article met en évidence différentes façons de régler et d’optimiser vos flux de données afin qu’ils soient conformes à vos points de référence en matière de performances.
Regardez la vidéo ci-dessous pour voir des exemples de minutages qui transforment les données avec des flux de données.
Supervision des performances de flux de données
Une fois que vous avez vérifié votre logique de transformation à l’aide du mode débogage, exécutez votre flux de travail de bout en bout en tant qu’activité dans un pipeline. Les flux de données sont mis en œuvre dans un pipeline à l’aide de l’activité d’exécution d’un flux de données. L’activité de flux de données offre une expérience de surveillance unique par rapport aux autres activités qui affichent un plan d’exécution détaillé et un profil de performances de la logique de transformation. Pour afficher des informations de surveillance détaillées d’un flux de données, sélectionnez l’icône de lunettes dans la sortie d’exécution de l’activité d’un pipeline. Pour plus d’informations, consultez Supervision des flux de données de mappage.
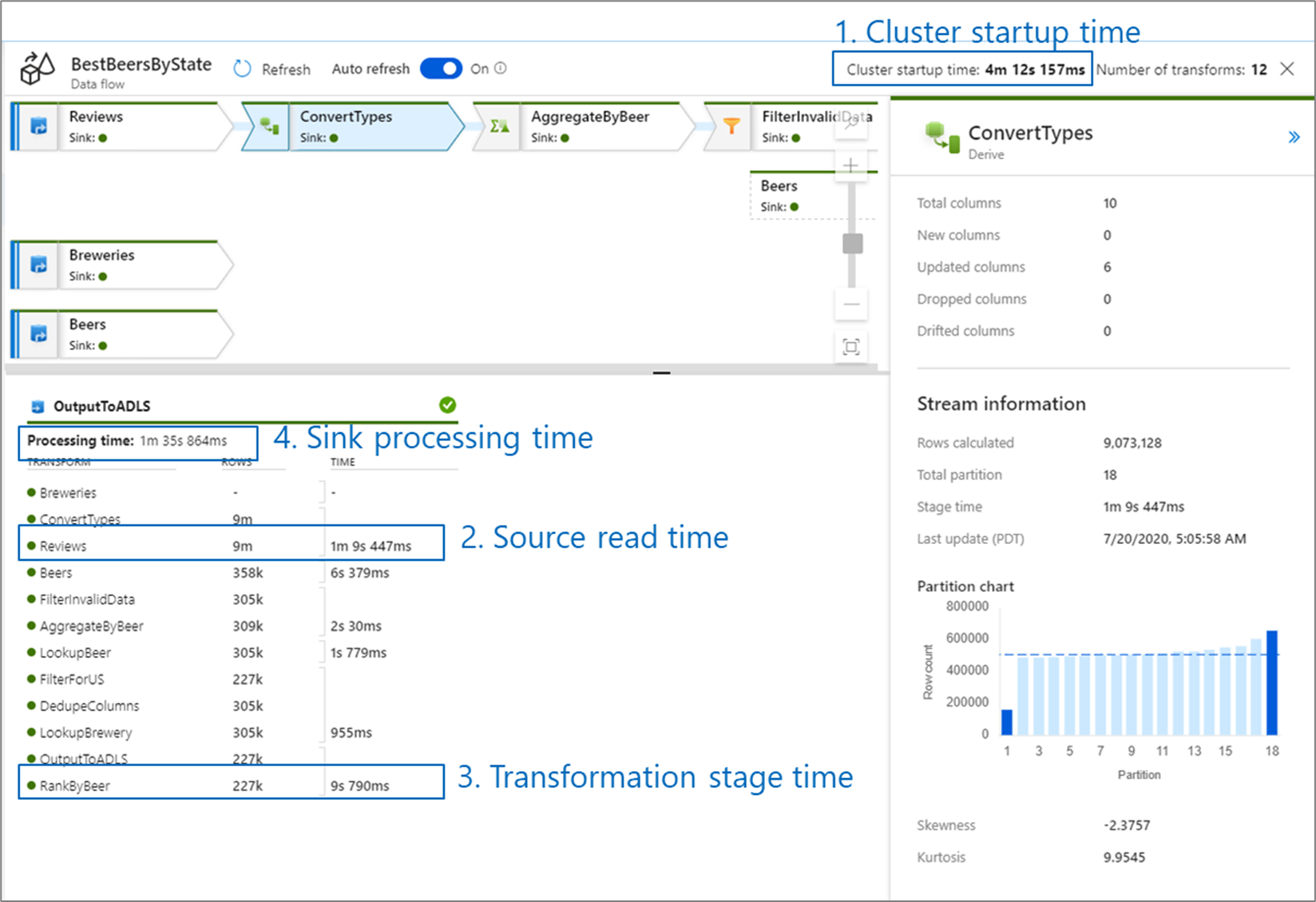
Lorsque vous surveillez les performances du flux de données, quatre goulots d’étranglement peuvent se présenter :
temps de démarrage du cluster ;
lecture à partir d’une source ;
temps de transformation ;
écriture dans un récepteur.
Le temps de démarrage du cluster est le temps nécessaire au lancement d’un cluster Apache Spark. Cette valeur se trouve dans l’angle supérieur droit de l’écran de surveillance. Les flux de données s’exécutent selon un modèle juste-à-temps, où chaque travail utilise un cluster isolé. Ce temps de démarrage est généralement de 3 à 5 minutes. Pour des travaux séquentiels, il est possible de réduire ce temps en activant une valeur de durée de vie. Pour plus d’informations, consultez la section Durée de vie dans Performance du runtime d’intégration.
Les flux de données utilisent un optimiseur Spark qui réorganise et exécute votre logique métier par « étapes » afin d’accélérer le processus. Pour chaque récepteur dans lequel votre flux de données écrit, la sortie de la surveillance indique la durée de chaque étape de transformation, ainsi que le temps nécessaire pour écrire les données dans le récepteur. La durée la plus important correspond probablement au goulot d’étranglement de votre flux de données. Si l’étape de transformation qui prend le plus de temps contient une source, vous souhaiterez peut-être optimiser davantage votre temps de lecture. Si une transformation prend beaucoup de temps, il se peut que vous deviez repartitionner ou augmenter la taille de votre runtime d’intégration. Si la durée de traitement du récepteur est importante, il se peut que vous deviez augmenter l’échelle de votre base de données ou vérifier que la sortie ne s’effectue pas dans un seul fichier.
Une fois que vous avez identifié le goulot d’étranglement de votre flux de données, utilisez les stratégies d’optimisation ci-dessous pour améliorer les performances.
Test de la logique de flux de données
Lorsque vous concevez et testez des flux de données à partir de l’interface utilisateur, le mode débogage vous permet de tester de manière interactive sur un cluster Spark en direct, ce qui vous permet d’afficher un aperçu des données et d’exécuter vos flux de données sans attendre l’initialisation d’un cluster. Pour plus d’informations, consultez Mode de débogage.
Onglet Optimiser
L’onglet Optimiser contient des paramètres pour configurer le schéma de partitionnement du cluster Spark. Cet onglet présent dans chaque transformation de flux de données spécifie si vous souhaitez repartitionner les données après la transformation. L’ajustement du partitionnement permet de contrôler la répartition de vos données entre les nœuds de calcul et les optimisations de la localisation des données qui peuvent avoir des effets tant positifs que négatifs sur les performances globales de vos flux de données.
Par défaut, l’option Utiliser le partitionnement actuel est sélectionnée, laquelle indique au service de conserver le partitionnement de sortie actuel de la transformation. Le repartitionnement des données prenant du temps, est recommandé d’utiliser le partitionnement actuel dans la plupart des scénarios. Les scénarios dans lesquels il peut être souhaitable de repartitionner vos données incluent des agrégats et des jointures qui entraînent une asymétrie considérable de vos données, ou l’utilisation d’un partitionnement de source sur une base de données SQL.
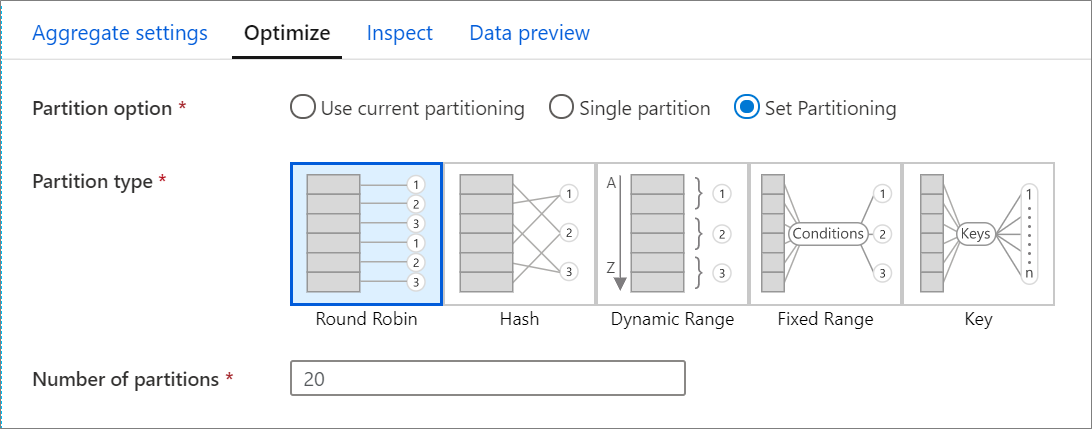
Pour changer le partitionnement de n’importe quelle transformation, sélectionnez l’onglet Optimiser, puis la case d’option Définir le partitionnement. Une série d’options de partitionnement vous est présentée. La méthode de partitionnement qui convient varie en fonction des volumes de données, des clés candidates, des valeurs null et de la cardinalité.
Important
Une partition unique combine toutes les données distribuées dans une seule partition. Il s’agit d’une opération très lente qui affecte considérablement toutes les transformations et écritures en aval. Cette option est fortement déconseillée à moins qu’il y ait une raison commerciale explicite de l’utiliser.
Les options de partitionnement suivantes sont disponibles dans chaque transformation :
Tourniquet
Un tourniquet (round robin) répartit équitablement les données entre les partitions. Utilisez un tourniquet (round robin) lorsque vous ne disposez pas des clés candidates adéquates pour implémenter une stratégie de partitionnement solide et intelligente. Vous pouvez définir le nombre de partitions physiques.
Hachage
Le service produit un hachage de colonnes pour produire des partitions uniformes, de sorte que des lignes contenant des valeurs similaires tombent dans la même partition. Lorsque vous utilisez l’option Hachage, effectuez un test pour détecter une éventuelle inclinaison de partition. Vous pouvez définir le nombre de partitions physiques.
Plage dynamique
La plage dynamique utilise des plages dynamiques Spark basées sur les colonnes ou expressions que vous fournissez. Vous pouvez définir le nombre de partitions physiques.
Plage fixe
Créez une expression qui fournit une plage fixe pour les valeurs figurant dans vos colonnes de données partitionnées. Pour éviter une inclinaison de partition, vous devez avoir une bonne compréhension de vos données avant d’utiliser cette option. Les valeurs que vous entrez pour l'expression sont utilisées dans le cadre d'une fonction de partition. Vous pouvez définir le nombre de partitions physiques.
Clé
Si vous avez une bonne compréhension de la cardinalité de vos données, une clé de partitionnement peut être une bonne stratégie. La clé de partitionnement crée des partitions pour chaque valeur unique de votre colonne. Vous ne pouvez pas définir le nombre de partitions car celui-ci dépend des valeurs uniques figurant dans les données.
Conseil
La définition manuelle du schéma de partitionnement a pour effet de remanier les données et risque d’annihiler les avantages de l’optimiseur Spark. La meilleure pratique consiste à ne pas définir manuellement le partitionnement, sauf si c’est indispensable.
Niveau de journalisation
Si vous n’avez pas besoin que chaque exécution du pipeline de vos activités de flux de données journalise entièrement tous les journaux de télémétrie détaillés, vous pouvez définir le niveau de journalisation sur « De base » ou « Aucun ». Lors de l’exécution de vos flux de données en mode « Verbose » (par défaut), vous demandez au service de journaliser entièrement l’activité à chaque niveau de partition individuel au cours de la transformation des données. Cela peut être une opération coûteuse. Par conséquent, n’activez l’option Verbose que lorsque la résolution des problèmes peut améliorer les performances globales du pipeline et du flux de données. Le mode « De base » ne consigne que les durées de transformation, tandis que le mode « Aucun » ne fournit qu’un résumé des durées.
En tant qu’ingénieur de données Fabric, vous devez disposer d’une expertise en matière de modèles de chargement de données, d’architectures de données et de processus d’orchestration.
 Azure Data Factory
Azure Data Factory