Utiliser Azure Data Factory pour migrer des données d’Amazon S3 vers le stockage Azure
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Factory fournit un mécanisme performant, robuste et rentable pour migrer des données à l’échelle d’Amazon S3 vers le stockage Blob Azure ou Azure Data Lake Storage Gen2. Cet article fournit les informations suivantes à l’attention des ingénieurs et des développeurs de données :
- Performances
- Résilience de copie
- Sécurité du réseau
- Architecture de solution de haut niveau
- Meilleures pratiques en matière d’implémentation
Performances
ADF offre une architecture serverless qui autorise le parallélisme à différents niveaux, ce qui permet aux développeurs de créer des pipelines pour utiliser pleinement la bande passante de votre réseau, ainsi que les IOPS et la bande passante de stockage pour maximiser le débit de déplacement de données pour votre environnement.
Les clients ont réussi à migrer des pétaoctets de données constitués de centaines de millions de fichiers d’Amazon S3 vers le stockage d’objets Blob Azure, avec un débit soutenu de 2 Gbits/s et plus.
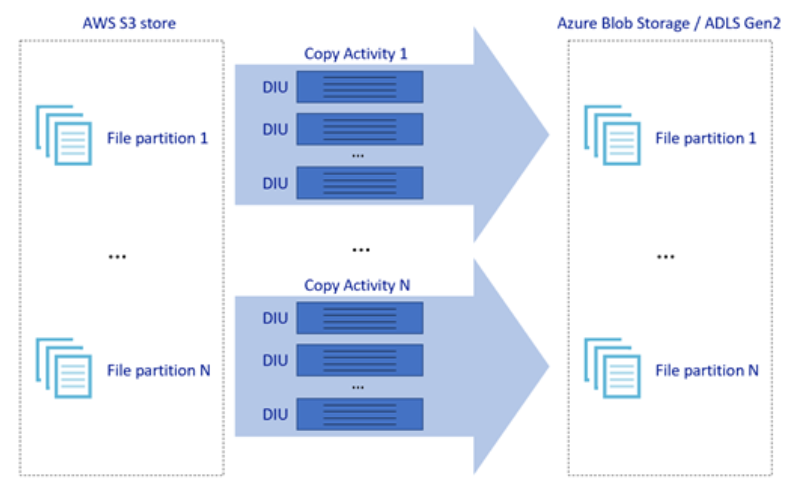
L’image ci-dessus montre comment vous pouvez obtenir des vitesses de déplacement de données exceptionnelles à travers différents niveaux de parallélisme:
- Une seule activité de copie peut tirer parti des ressources de calcul évolutives : lorsque vous utilisez Azure Integration Runtime, vous pouvez spécifier jusqu'à 256 DIUs pour chaque activité de copie serverless ; lorsque vous utilisez des Integration Runtime auto-hébergés, vous pouvez effectuer un scale-up de la machine ou un scale-out vers plusieurs machines (jusqu’à quatre nœuds), et une seule activité de copie partitionnera son jeu de fichiers sur tous les nœuds.
- Une activité de copie unique lit et écrit dans le magasin de données à l’aide de plusieurs conversations.
- Le flux de contrôle ADF peut démarrer plusieurs activités de copie en parallèle, par exemple Pour chaque boucle.
Résilience
Dans une exécution d’activité de copie unique, ADF intègre un mécanisme de nouvelle tentative qui permet de gérer un certain niveau d’échecs temporaires dans les magasins de données ou dans le réseau sous-jacent.
Lors de la copie binaire de S3 vers un objet Blob et de S3 vers ADLS Gen2, ADF effectue automatiquement des points de contrôle. Si l’exécution d’une activité de copie a échoué ou a expiré, lors d’une nouvelle tentative, la copie reprend à partir du dernier point d’échec au lieu de commencer depuis le début.
Sécurité du réseau
Par défaut, ADF transfère les données d’Amazon S3 vers le stockage Blob Azure ou Azure Data Lake Storage Gen2 à l’aide d’une connexion chiffrée sur le protocole HTTPS. Le protocole HTTPS assure le chiffrement des données en transit et empêche les écoutes clandestines et les attaques de l’intercepteur.
En revanche, si vous ne souhaitez pas que les données soient transférées via l’internet public, vous pouvez obtenir une sécurité accrue en transférant des données via un lien de peering privé entre le service de connexion directe AWS et Azure Express Route. Reportez-vous à l’architecture de la solution dans la section suivante pour savoir comment procéder.
Architecture de solution
Migrer des données sur l’Internet public :

- Dans cette architecture, les données sont transférées en toute sécurité à l’aide du protocole HTTPS sur l’Internet public.
- La source Amazon S3 et les destinations de Stockage Blob Azure ou Azure Data Lake Storage Gen2 sont configurées pour autoriser le trafic à partir de toutes les adresses IP du réseau. Reportez-vous à la deuxième architecture mentionnée ci-après pour savoir comment limiter l’accès réseau à une plage d’adresses IP spécifique.
- Vous pouvez facilement augmenter la quantité de puissance serverless pour utiliser pleinement votre réseau et votre bande passante de stockage, de manière à obtenir le meilleur débit pour votre environnement.
- La migration des instantanés initiaux et la migration des données Delta peuvent être réalisées à l’aide de cette architecture.
Migrer des données via un lien privé :
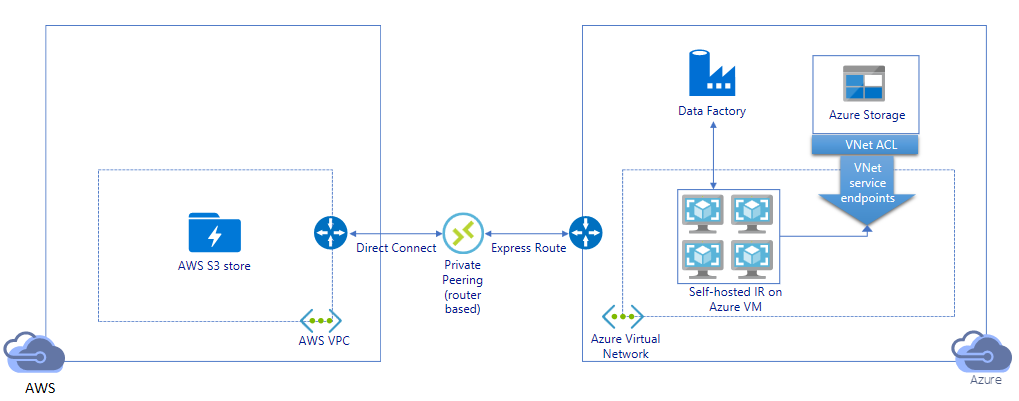
- Dans cette architecture, la migration des données s’effectue via un lien de peering privé entre AWS Direct Connect et Azure Express Route, de telle sorte que les données ne transitent jamais sur l’Internet public. Cela nécessite l'utilisation de AWS VPC et du réseau virtuel Azure.
- Vous devez installer le runtime d'intégration ADF auto-hébergé sur une machine virtuelle Windows au sein de votre réseau virtuel Azure pour réaliser cette architecture. Vous pouvez effectuer un scale-up manuel de vos machines virtuelles IR auto-hébergées ou effectuer un scale-out sur plusieurs machines virtuelles (jusqu’à quatre nœuds) pour utiliser pleinement votre réseau et vos IOPS/bande passante de stockage.
- Cette architecture permet à la fois la migration initiale des données instantanées et la migration des données delta.
Meilleures pratiques en matière d’implémentation
Authentification et gestion des informations d’identification
- Pour vous authentifier sur un compte Amazon S3, vous devez utiliser la clé d’accès pour le compte IAM.
- Plusieurs types d’authentification sont pris en charge pour la connexion à Azure Blob Storage. L’utilisation d’identités managées pour les ressources Azure est fortement recommandée : basée sur une identification ADF automatiquement managée dans Microsoft Entra ID, elle vous permet de configurer des pipelines sans fournir d’informations d’identification dans la définition Service lié. Vous pouvez également vous authentifier auprès de Azure Blob Storage à l’aide du Principal de service, de la signature d’accès partagé ou de la clé de compte de stockage.
- Plusieurs types d’authentification sont également pris en charge pour la connexion à Azure Data Lake Storage Gen2. L’utilisation d’identités gérées pour les ressources Azure est fortement recommandée, bien que le principal de service ou la clé de compte de stockage puissent également être utilisés.
- Lorsque vous n’utilisez pas d’identités gérées pour les ressources Azure, il est vivement recommandé de stocker les informations d’identification dans Azure Key Vault pour faciliter la gestion et la rotation des clés sans modifier les services liés ADF. Il s’agit également de l'une des meilleures pratiques pour CI/CD.
Migration initiale des données d’instantané
La partition de données est recommandée en particulier lors de la migration de plus de 100 To de données. Pour partitionner les données, utilisez le paramètre « Prefix » pour filtrer les dossiers et les fichiers d’Amazon S3 par nom, puis chaque travail de copie ADF peut copier une partition à la fois. Vous pouvez exécuter plusieurs tâches de copie ADF simultanément pour un meilleur débit.
Si l’un des travaux de copie échoue en raison d’un problème temporaire de réseau ou de magasin de données, vous pouvez réexécuter la tâche de copie ayant échoué pour recharger à nouveau cette partition spécifique à partir de AWS S3. Tous les autres travaux de copie qui chargent d’autres partitions ne seront pas affectés.
Migration des données Delta
La méthode la plus efficace pour identifier les fichiers nouveaux ou modifiés à partir de AWS S3 est d’utiliser une convention d’affectation de noms partitionnée : lorsque les données de l’AWS S3 ont été partitionnées avec les informations de tranche de temps dans le nom de fichier ou de dossier (par exemple,/yyyy/mm/dd/file.csv), votre pipeline peut facilement identifier les fichiers/dossiers à copier de façon incrémentielle.
En guise d’alternative, si vos données de AWS S3 ne sont pas partitionnées, ADF peut identifier les fichiers nouveaux ou modifiés par leur paramètre LastModifiedDate. La façon de procéder est la suivante : ADF analyse tous les fichiers de AWS S3 et copie uniquement le nouveau fichier mis à jour dont la date de dernière modification est supérieur à une certaine valeur. Si vous avez un grand nombre de fichiers en S3, l’analyse de fichiers initiale peut prendre beaucoup de temps, quel que soit le nombre de fichiers correspondant à la condition de filtre. Dans ce cas, vous avez la possibilité de partitionner les données en premier, en utilisant le même paramètre de préfixe pour la migration initiale des instantanés, afin que l’analyse des fichiers puisse se produire en parallèle.
Pour les scénarios qui requièrent le runtime d’intégration auto-hébergé sur une machine virtuelle Azure
Si vous migrez des données via un lien privé ou si vous souhaitez autoriser une plage d’adresses IP spécifiques sur un pare-feu Amazon S3, vous devez installer le runtime d’intégration auto-hébergé sur une machine virtuelle Windows Azure.
- La configuration de démarrage recommandée pour chaque machine virtuelle Azure est Standard_D32s_v3 avec des processeurs virtuels 32 et 128 Go de mémoire. Vous pouvez conserver à surveiller l’utilisation du processeur et de la mémoire de la machine virtuelle IR pendant la migration des données afin de déterminer si vous devez augmenter la taille de la machine virtuelle pour améliorer les performances ou réduire la taille de la machine virtuelle pour réduire les coûts.
- Vous pouvez également effectuer un scale-out en associant jusqu’à quatre nœuds de machine virtuelle à un seul runtime d’intégration auto-hébergé. Une seule tâche de copie exécutée sur un runtime d’intégration auto-hébergé partitionne automatiquement le jeu de fichiers et utilise tous les nœuds de machine virtuelle pour copier les fichiers en parallèle. Pour une haute disponibilité, il est recommandé de commencer par deux nœuds de machine virtuelle pour éviter un point de défaillance unique pendant la migration des données.
Limitation du débit
Il est recommandé de procéder à un examen des performances avec un exemple de jeu de données représentatif, afin de pouvoir déterminer la taille de partition appropriée.
Commencez avec une seule partition et une seule activité de copie avec le paramètre DIU par défaut. Augmentez progressivement le paramètre DIU jusqu'à atteindre la limite de bande passante de votre réseau ou la limite IOPS/bande passante des magasins de données, ou vous avez atteint le nombre maximal de 256 DIU autorisé pour une activité de copie unique.
Ensuite, augmentez progressivement le nombre d’activités de copie simultanées jusqu’à ce que vous atteigniez les limites de votre environnement.
Lorsque vous rencontrez des erreurs de limitation signalées par l'activité de copie de l'ADF, réduisez le paramètre d'accès simultané ou DIU dans l'ADF ou envisagez d'augmenter les limites de bande passante/IOPS des magasins de données et du réseau.
Estimation du coût
Notes
Il s’agit d’un exemple de tarification hypothétique. Vos tarifs réels dépendent du débit réel dans votre environnement.
Considérez le pipeline suivant construit pour la migration de données de S3 vers le Stockage Blob Azure :
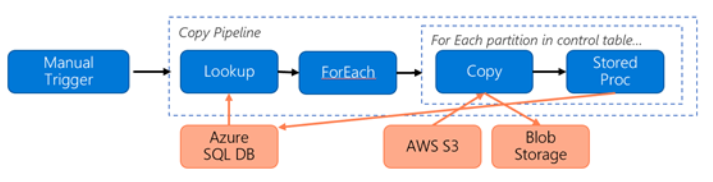
Prenons l’exemple suivant :
- Le volume total de données est de 2 Po
- Migration de données via HTTPS à l’aide de la première architecture de solution
- 2 Po est divisé en partitions de 1Ko et chaque copie déplace une partition
- Chaque copie est configurée avec DIU = 256 et atteint un débit de 1 Gbit/s.
- L’accès concurrentiel ForEach est défini sur 2 et le débit agrégé est de 2 Gbits/s
- Au total, il faut 292 heures pour terminer la migration
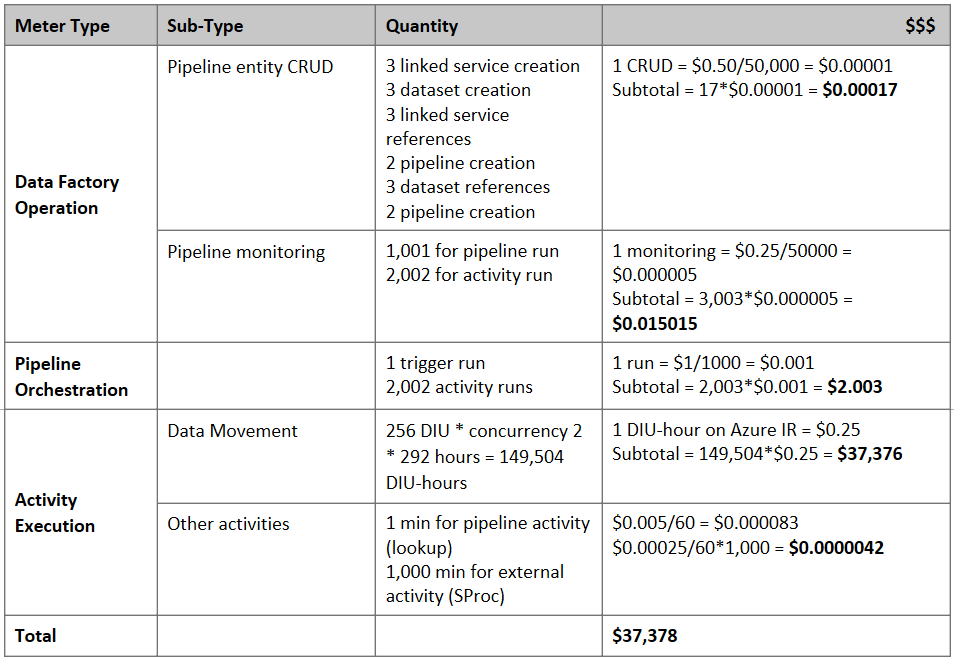
Voici le prix estimé selon les hypothèses ci-dessus :
Références supplémentaires
- Connecteur Amazon Simple Storage Service
- Connecteur Stockage Blob Azure
- Connecteur Azure Data Lake Storage Gen2
- Guide sur les performances et le réglage de l’activité de copie
- Créer et configurer un runtime d’intégration auto-hébergé
- Extensibilité et haute disponibilité du runtime d’intégration auto-hébergé
- Considérations relatives à la sécurité des déplacements de données
- Stocker les informations d’identification dans Azure Key Vault
- Copier le fichier de façon incrémentielle en fonction du nom de fichier partitionné
- Copier les fichiers nouveaux et modifiés basés sur LastModifiedDate
- Page de tarification ADF
Modèle
Voici le modèle avec lequel commencer pour migrer des pétaoctets de données composées de centaines de millions de fichiers d’Amazon S3 vers Azure Data Lake Storage Gen2.