Intégration de données avec Azure Data Factory et Azure Data Share
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
À mesure que les clients se lancent dans des projets modernes basés sur l’analytique et les entrepôts de données, ils nécessitent non seulement une plus grande quantité de données mais également une meilleure visibilité sur l’ensemble de leurs données. Cet atelier explique comment les améliorations apportées à Azure Data Factory et Azure Data Share simplifient l’intégration et la gestion des données dans Azure.
De l’activation des processus ETL/ELT sans code à la création d’une vue complète de vos données, les améliorations apportées à Azure Data Factory donnent les moyens à vos ingénieurs des données d’apporter en toute confiance davantage de données, et donc plus de valeur, à votre entreprise. Azure Data Share vous permet de faire du partage B2B (interentreprise) de manière régie.
Dans cet atelier, vous allez utiliser Azure Data Factory (ADF) pour ingérer des données provenant d’Azure SQL Database dans Azure Data Lake Storage Gen2 (ADLS Gen2). Une fois que vous avez placé les données dans le lac, vous les transformez par le biais des flux de données de mappage, le service de transformation natif de Data Factory, et vous les déposez dans Azure Synapse Analytics. Vous partagez ensuite la table contenant les données transformées avec des données supplémentaires, à l’aide d’Azure Data Share.
Les données utilisées dans ce lab sont des données relatives aux taxis de New York. Pour les importer dans votre base de données dans SQL Database, téléchargez le fichier taxi-data bacpac. Sélectionnez l’option Télécharger le fichier brut dans GitHub.
Prérequis
Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Azure SQL Database : si vous n’avez pas d’Azure SQL Database, découvrez comment créer une SQL Database.
Compte de stockage Azure Data Lake Storage Gen2 : Si vous n’avez pas de compte de stockage ADLS Gen2, découvrez comment créer un compte de stockage ADLS Gen2.
Azure Synapse Analytics : si vous n’avez pas d’espace de travail Azure Synapse Analytics, découvrez comment bien démarrer avec Azure Synapse Analytics.
Azure Data Factory : Si vous n’avez pas créé de fabrique de données, découvrez comment créer une fabrique de données.
Azure Data Share : Si vous n’avez pas créé de partage de données, découvrez comment créer un partage de données.
Configurer votre environnement Azure Data Factory
Dans cette section, vous allez découvrir comment accéder à l’expérience utilisateur ADF (Azure Data Factory) à partir du portail Azure. Une fois dans l’expérience utilisateur ADF, vous allez configurer trois services liés pour chacun des magasins de données que nous utilisons : Azure SQL Database, ADLS Gen2 et Azure Synapse Analytics.
Dans les services liés Azure Data Factory, définissez les informations de connexion aux ressources externes. Azure Data Factory prend en charge plus de 85 connecteurs.
Ouvrir l’expérience utilisateur Azure Data Factory
Ouvrez le portail Azure dans Microsoft Edge ou Google Chrome.
À l’aide de la barre de recherche en haut de la page, recherchez « Fabriques de données ».
Sélectionnez votre ressource de fabrique de données pour ouvrir ses ressources dans le volet gauche.
Sélectionnez Ouvrir Azure Data Factory Studio. Data Factory Studio est également accessible directement à adf.azure.com.
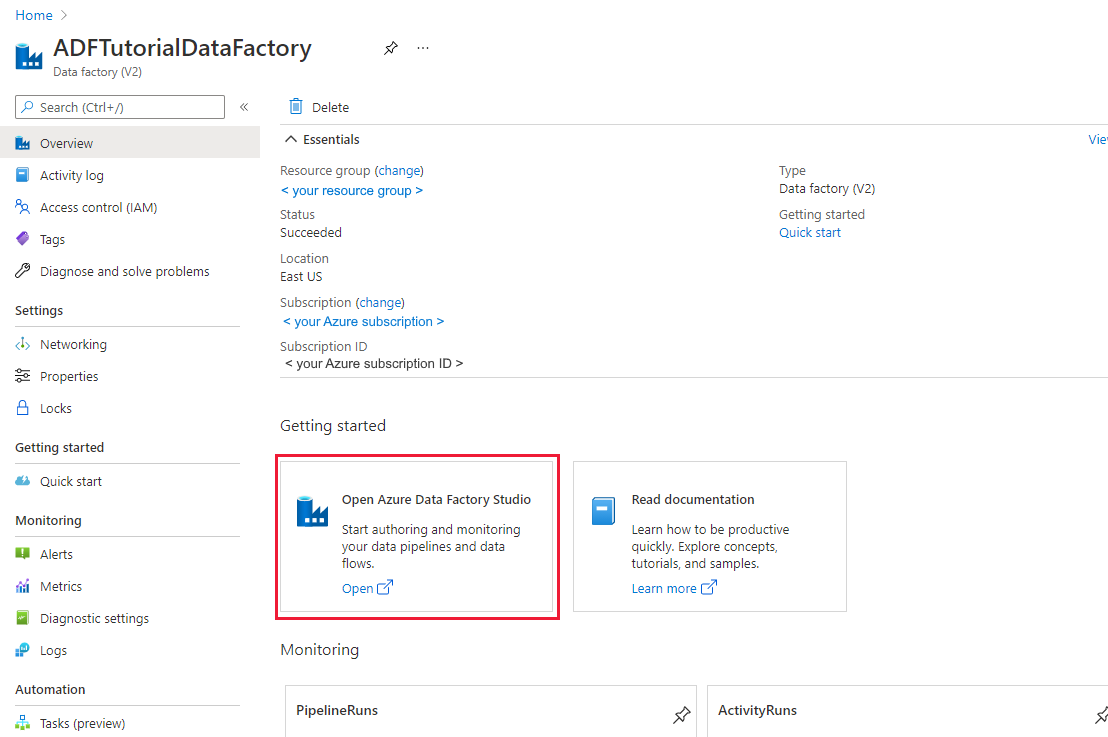
Vous êtes redirigé vers la page d’accueil d’ADF dans le portail Azure. Cette page contient des guides de démarrage rapide, des vidéos pédagogiques et des liens vers des tutoriels pour apprendre les concepts liés à la fabrique de données. Pour commencer à rédiger, sélectionnez l'icône du crayon dans la barre latérale gauche.
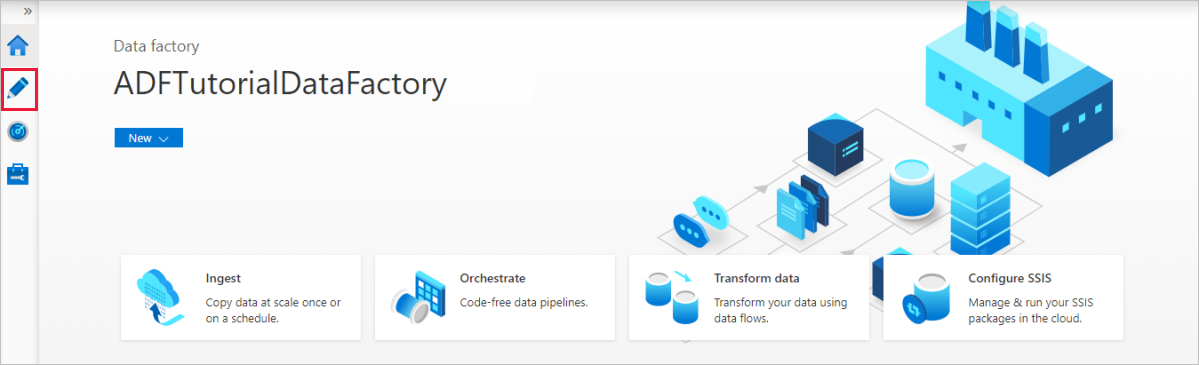


Créer un service lié Azure SQL Database
Pour créer un service lié, sélectionnez le hub de Gestion dans la barre latérale de gauche. Dans le volet Connexions, sélectionnez ensuite Services liés, puis Nouveau pour ajouter un nouveau service lié.
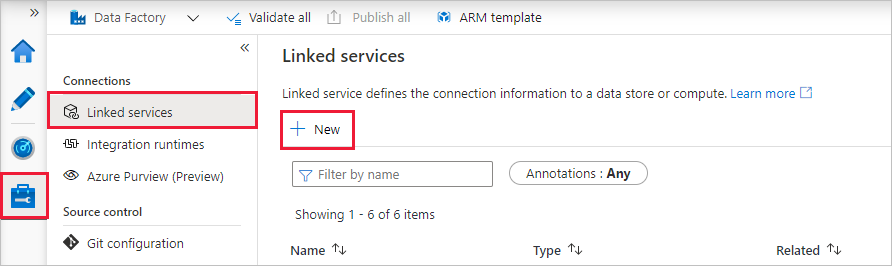
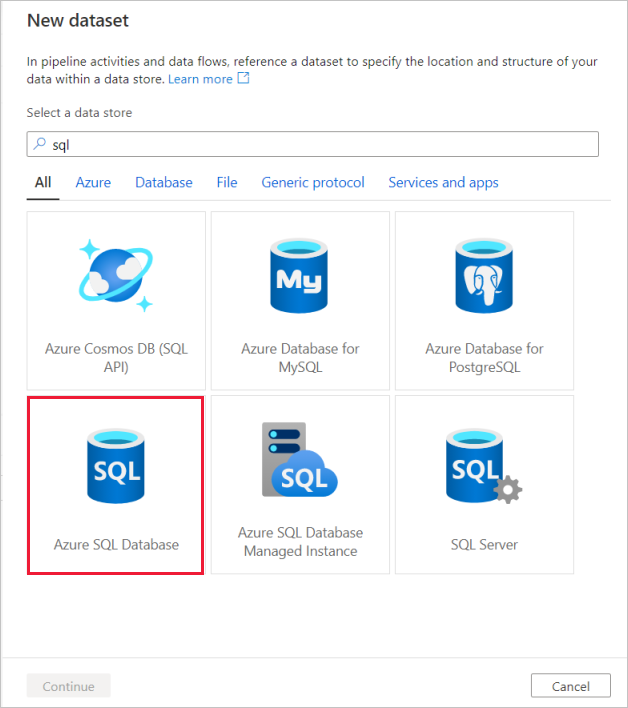
Le premier service lié que vous configurez est un service Azure SQL Database. Vous pouvez utiliser la barre de recherche pour filtrer la liste des magasins de données. Cliquez sur la vignette Azure SQL Database, puis cliquez sur Continuer.

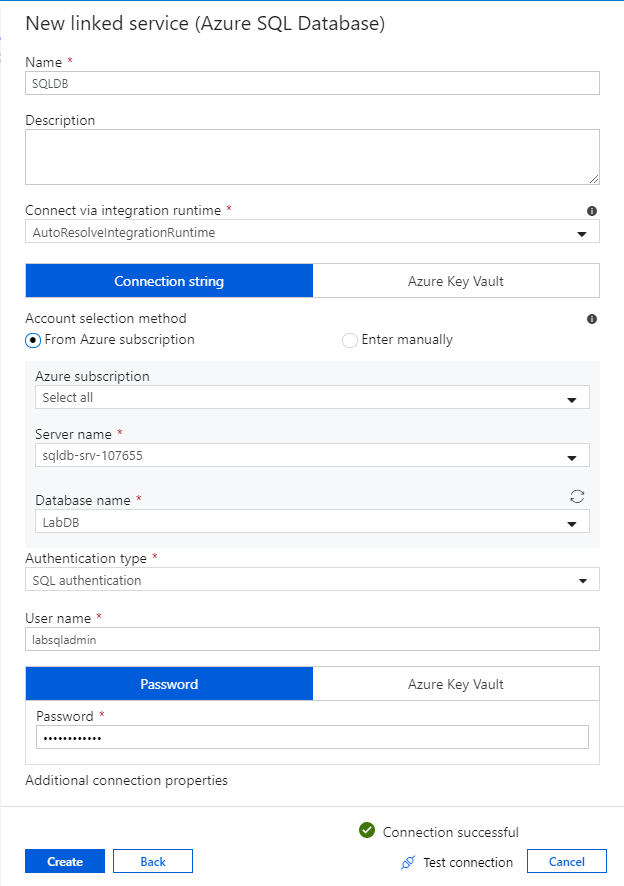
Dans le volet de configuration de SQL Database, entrez « SQLDB » en tant que nom de service lié. Entrez vos informations d’identification pour permettre à la fabrique de données de se connecter à votre base de données. Si vous utilisez l’authentification SQL, entrez le nom du serveur, la base de données, votre nom d’utilisateur et le mot de passe. Vous pouvez vérifier que vos informations de connexion sont correctes en cliquant sur Tester la connexion. Lorsque vous avez terminé, sélectionnez Créer.

Créer un service lié Azure Synapse Analytics
Répétez le même processus pour ajouter un service lié Azure Synapse Analytics. Dans l'onglet Connexions, sélectionnez Nouveau. Sélectionnez la tuile Azure Synapse Analytics et sélectionnez continuer.
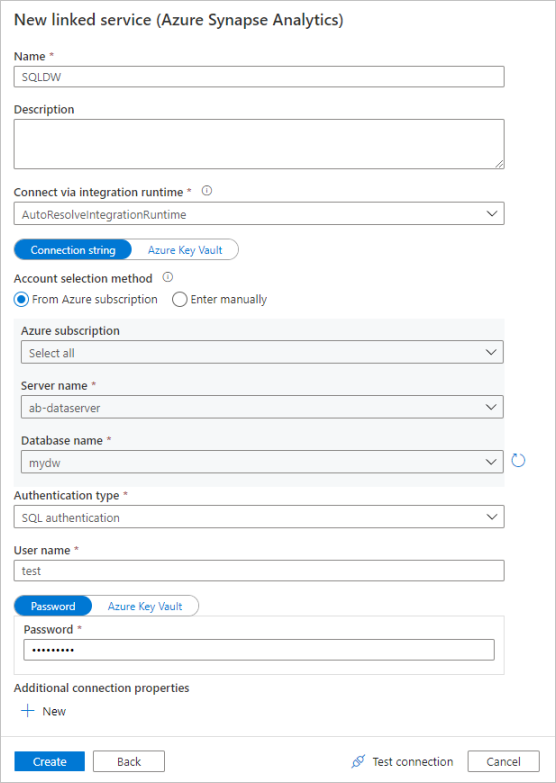
Dans le volet de configuration du service lié, entrez `SQLDW`` en tant que nom de service lié. Entrez vos informations d’identification pour permettre à la fabrique de données de se connecter à votre base de données. Si vous utilisez l’authentification SQL, entrez le nom du serveur, la base de données, votre nom d’utilisateur et le mot de passe. Vous pouvez vérifier que vos informations de connexion sont correctes en cliquant sur Tester la connexion. Lorsque vous avez terminé, sélectionnez Créer.
Créer un service lié Azure Data Lake Storage Gen2
Le dernier service lié nécessaire pour ce lab est un service Azure Data Lake Storage Gen2. Dans l'onglet Connexions, sélectionnez Nouveau. Sélectionnez la vignette Azure Data Lake Storage Gen2, puis cliquez sur Continue.
Dans le volet de configuration du service lié, entrez « ADLSGen2 » en tant que nom de service lié. Si vous utilisez l’authentification par clé de compte, sélectionnez votre compte de stockage ADLS Gen2 dans la liste déroulante Nom du compte de stockage. Vous pouvez vérifier que vos informations de connexion sont correctes en cliquant sur Tester la connexion. Lorsque vous avez terminé, sélectionnez Créer.
Activer le mode de débogage de flux de données
Dans la section Transform data using mapping data flow (Transformer les données à l’aide du flux de données de mappage), vous créez des flux de données de mappage. Parmi les bonnes pratiques relatives à la création de flux de données de mappage, il en existe une qui consiste à activer le mode débogage. Cela vous permet de tester la logique de transformation en quelques secondes sur un cluster Spark actif.
Pour activer le débogage, cliquez sur le curseur Débogage du flux de données dans la barre supérieure du canevas de flux de données ou du canevas de pipeline quand vous avez des activités de Flux de données. Sélectionnez OK lorsque la boîte de dialogue de confirmation s'affiche. Le cluster démarre en cinq à sept minutes environ. Pendant l’initialisation, passez à Ingérer des données d’Azure SQL Database dans ADLS Gen2 à l’aide de l’activité de copie.

Ingérer des données à l’aide de l’activité de copie
Dans cette section, vous créez un pipeline avec une activité de copie qui ingère une table Azure SQL Database dans un compte de stockage ADLS Gen2. Vous allez apprendre à ajouter un pipeline, à configurer un jeu de données et à déboguer un pipeline via l’expérience utilisateur ADF. Le modèle de configuration utilisé dans cette section peut s’appliquer à la copie d’un magasin de données relationnelles vers un magasin de données basées sur des fichiers.
Dans Azure Data Factory, un pipeline est un regroupement logique d’activités qui effectuent ensemble une tâche. Une activité définit une opération à effectuer sur vos données. Un jeu de données pointe vers les données à utiliser dans un service lié.
Créer un pipeline avec une activité de copie
Dans le volet des ressources de fabrique, cliquez sur l’icône représentant un signe plus pour ouvrir le nouveau menu de ressource. Sélectionnez Pipeline.
Sous l’onglet General (Général) du canevas de pipeline, donnez à votre pipeline un nom descriptif, par exemple « IngestAndTransformTaxiData ».
Dans le volet d’activités du canevas de pipeline, ouvrez l’accordéon Move and Transform (Déplacer et transformer), puis faites glisser l’activité Copy data (Copier les données) vers le canevas. Donnez à l’activité de copie un nom descriptif, par exemple « IngestIntoADLS ».
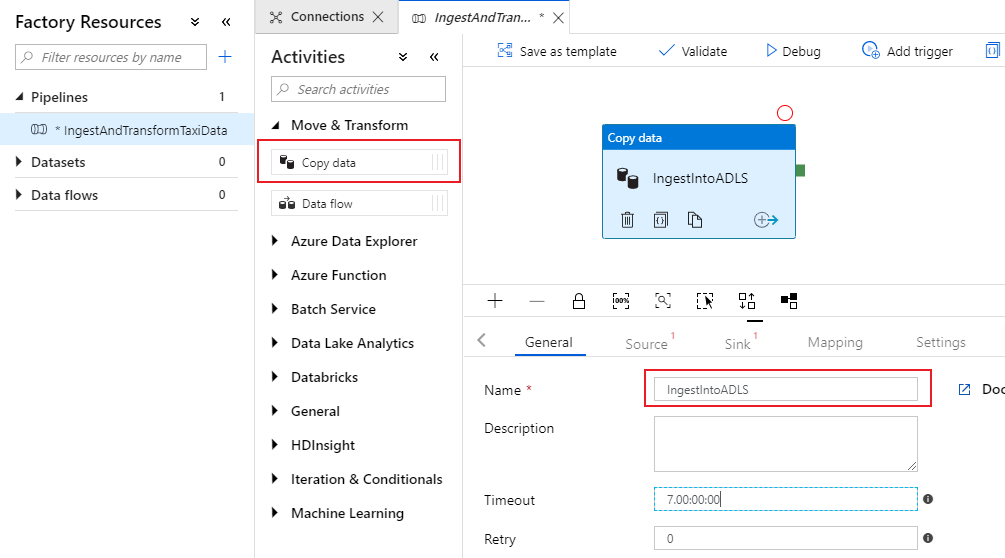


Configurer un jeu de données source Azure SQL DB
Cliquez sur l’onglet Source de l’activité de copie. Pour créer un jeu de données, sélectionnez Nouveau. Votre source est la table
dbo.TripDatasituée dans le service lié « SQLDB » configuré auparavant.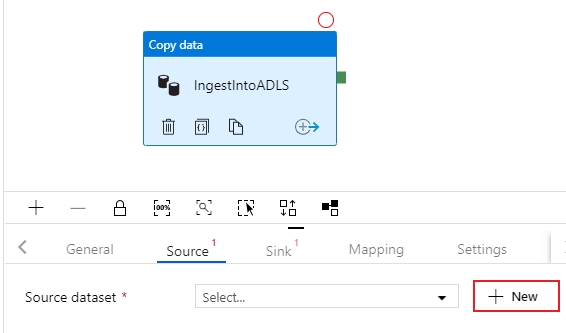
Recherchez Azure SQL Database, puis cliquez sur Continuer.
Appelez votre jeu de données « TripData ». Sélectionnez « SQLDB » en tant que service lié. Sélectionnez le nom de table
dbo.TripDatadans la liste déroulante des noms de tables. Importez le schéma à partir de la connexion/du magasin. Sélectionnez OK lorsque vous avez terminé.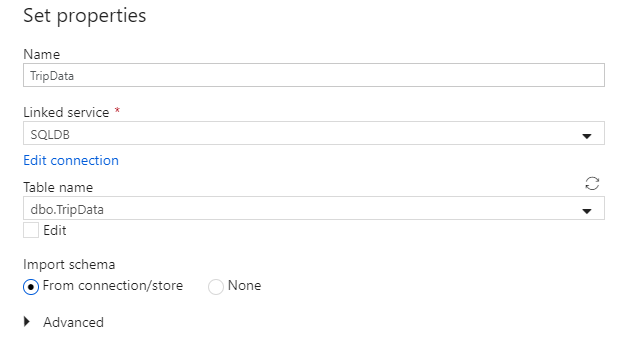
Vous avez réussi à créer votre jeu de données source. Vérifiez dans les paramètres de la source que la valeur par défaut Table est sélectionnée dans le champ d’utilisation de la requête.
Configurer le jeu de données du récepteur ADLS Gen2
Sélectionnez dans l'onglet Sink de l'activité de copie. Pour créer un jeu de données, sélectionnez Nouveau.
Recherchez Azure Data Lake Storage Gen2, puis cliquez sur Continuer.
Dans le volet de sélection du format, sélectionnez DelimitedText, car vous écrivez dans un fichier CSV. Sélectionnez Continuer.

Nommez votre jeu de données récepteur « TripDataCSV ». Sélectionnez « ADLSGen2 » en tant que service lié. Entrez l’emplacement où vous souhaitez écrire votre fichier CSV. Par exemple, vous pouvez écrire vos données dans le fichier
trip-data.csvdans le conteneurstaging-container. Affectez la valeur true à First row as header (Première ligne comme en-tête), car vous souhaitez que vos données de sortie aient des en-têtes. Dans la mesure où il n’existe pas encore de fichier à l’emplacement de destination, affectez à Import schema (Schéma d’importation) la valeur None (Aucun). Sélectionnez OK lorsque vous avez terminé.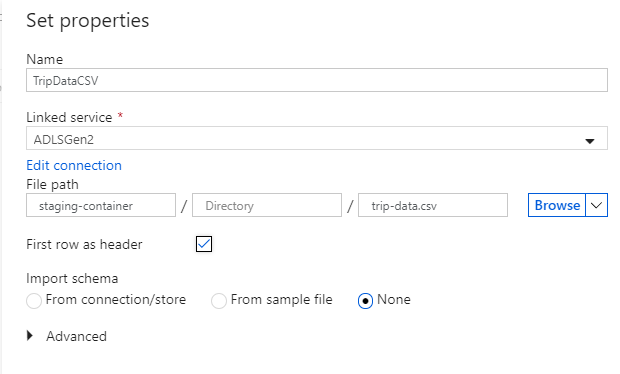
Tester l’activité de copie avec une exécution de débogage de pipeline
Pour vérifier que votre activité de copie fonctionne correctement, cliquez sur Debug (Déboguer) en haut du canevas de pipeline afin d’exécuter un débogage. Une exécution de débogage vous permet de tester votre pipeline de bout en bout, ou jusqu’à un point d’arrêt, avant de le publier sur le service de fabrique de données.
Pour superviser votre exécution de débogage, accédez à l’onglet Sortie du canevas du pipeline. L’écran de supervision est actualisé automatiquement toutes les 20 secondes, ou quand vous cliquez manuellement sur le bouton d’actualisation. L’activité de copie a une vue de supervision spéciale à laquelle vous pouvez accéder en sélectionnant l’icône représentant des lunettes dans la colonne Actions.
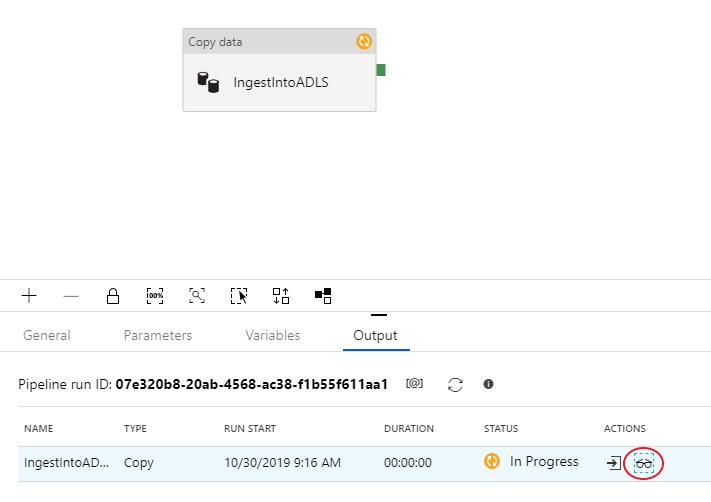
La vue de supervision de la copie donne les détails d’exécution de l’activité ainsi que les caractéristiques de performance. Vous pouvez voir des informations telles que les données lues/écrites, les lignes lues/écrites, les fichiers lus/écrits et le débit. Si vous avez tout configuré correctement, vous devez voir 49 999 lignes écrites dans un fichier de votre récepteur ADLS.
Avant de passer à la section suivante, il est suggéré de publier vos changements sur le service de fabrique de données en sélectionnant Publish all (Tout publier) dans la barre supérieure de la fabrique. Bien que cela ne soit pas abordé dans ce lab, Azure Data Factory prend en charge l’intégration complète de Git. L’intégration de Git permet la gestion de versions, l’enregistrement itératif dans un dépôt et la collaboration dans une fabrique de données. Pour plus d’informations, consultez Contrôle de code source dans Azure Data Factory.


Transformer des données avec un flux de données de mappage
Une fois que vous avez réussi à copier les données dans Azure Data Lake Storage, vous devez effectuer une jointure et une agrégation de ces données dans un entrepôt de données. Nous utilisons le flux de données de mappage, le service de transformation conçu de manière visuelle d’Azure Data Factory. Les flux de données de mappage permettent aux utilisateurs de développer une logique de transformation sans code, et d’exécuter ces flux sur des clusters Spark managés par le service ADF.
Le flux de données créé au cours de cette étape effectue une jointure interne du jeu de données « TripDataCSV » créé dans la section précédente avec une table dbo.TripFares stockée dans « SQLDB » en fonction de quatre colonnes clés. Les données sont ensuite agrégées en fonction de la colonne payment_type pour calculer la moyenne de certains champs, avant d’être écrites dans une table Azure Synapse Analytics.
Ajouter une activité de flux de données à votre pipeline
Dans le volet d’activités du canevas de pipeline, ouvrez l’accordéon Move and Transform, puis faites glisser l’activité Data flow (Flux de données) vers le canevas.
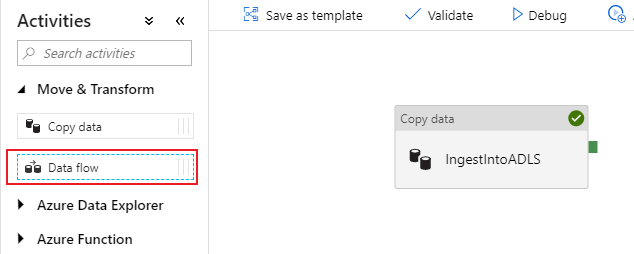
Dans le volet latéral qui s’ouvre, sélectionnez Create new data flow (Créer un flux de données), puis choisissez Mapping data flow (Flux de données de mappage). Cliquez sur OK.
Vous accédez ensuite au canevas de flux de données, où vous créez votre logique de transformation. Sous l’onglet General, nommez votre flux de données « JoinAndAggregateData ».


Configurer votre source CSV de données de trajet
La première chose à faire est de configurer vos deux transformations de sources. La première source pointe vers le jeu de données DelimitedText de « TripDataCSV ». Pour ajouter une transformation de source, cliquez sur la case Add Source (Ajouter une source) dans le canevas.
Nommez votre source « TripDataCSV », puis sélectionnez le jeu de données « TripDataCSV » dans la liste déroulante de sources. Si vous vous en souvenez, vous n’avez pas importé de schéma initialement durant la création de ce jeu de données, car il n’y avait aucune donnée. Puisque
trip-data.csvexiste maintenant, sélectionnez Editer pour aller à l'onglet des paramètres de l'ensemble de données.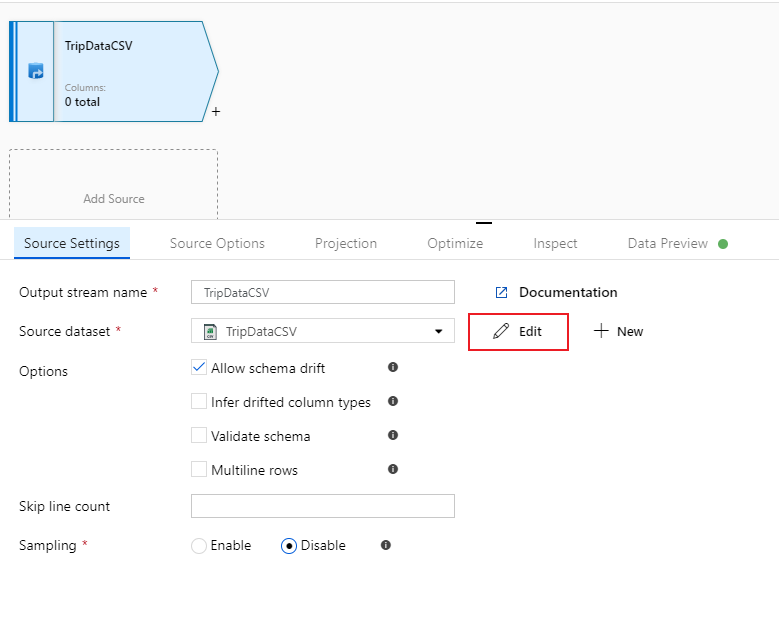
Allez dans l'onglet Schéma et sélectionnez Importer un schéma. Sélectionnez From connection/store (Depuis la connexion/le magasin) pour effectuer l’importation directement à partir du magasin de fichiers. 14 colonnes de type chaîne doivent s’afficher.
Revenez au flux de données « JoinAndAggregateData ». Si votre cluster de débogage a démarré (indiqué par un cercle vert à côté du curseur de débogage), vous pouvez obtenir une capture instantanée des données sous l’onglet Data Preview (Aperçu des données). Cliquez sur Actualiser (Actualiser) pour extraire un aperçu des données.


Remarque
L’aperçu des données n’écrit pas de données.
Configurer votre source SQL Database des tarifs de trajet
La deuxième source que vous ajoutez pointe vers la table SQL Database
dbo.TripFares. Sous votre source « TripDataCSV », il existe une autre zone Add Source (Ajouter une source). Cliquez dessus pour ajouter une nouvelle transformation de source.
Nommez cette source « TripFaresSQL ». Cliquez sur Nouveau à côté du champ du jeu de données source pour créer un jeu de données SQL Database.
Cliquez sur la vignette Azure SQL Database, puis cliquez sur Continuer. Vous remarquerez peut-être que de nombreux connecteurs de la fabrique de données ne sont pas pris en charge dans le flux de données de mappage. Pour transformer les données d’une de ces sources, ingérez-les dans une source prise en charge à l’aide de l’activité de copie.

Appelez votre jeu de données « TripFares ». Sélectionnez « SQLDB » en tant que service lié. Sélectionnez le nom de table
dbo.TripFaresdans la liste déroulante des noms de tables. Importez le schéma à partir de la connexion/du magasin. Sélectionnez OK lorsque vous avez terminé.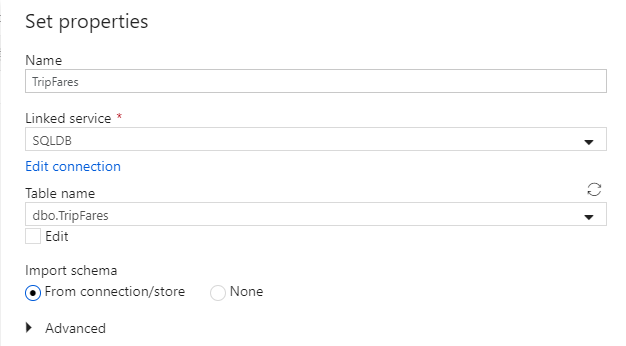
Pour vérifier vos données, extrayez un aperçu de ces dernières sous l’onglet Data Preview.


Effectuer une jointure interne de TripDataCSV et TripFaresSQL
Pour ajouter une nouvelle transformation, cliquez sur l’icône représentant un signe plus dans le coin inférieur droit de « TripDataCSV ». Sous Multiple inputs/outputs (Entrées/sorties multiples), sélectionnez Join (Créer une jointure).
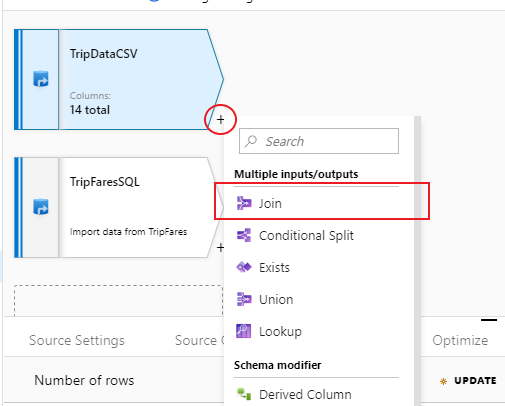
Nommez votre transformation de jointure « InnerJoinWithTripFares ». Sélectionnez « TripFaresSQL » dans la liste déroulante de flux de droite. Sélectionnez le type de jointure Inner (Interne). Pour en savoir plus sur les différents types de jointure dans le flux de données de mappage, consultez Types de jointure.
Sélectionnez les colonnes auxquelles vous souhaitez faire correspondre chaque flux via la liste déroulante Join conditions (Conditions de jointure). Pour ajouter une condition de jointure supplémentaire, cliquez sur l’icône représentant un signe plus à côté d’une condition existante. Par défaut, toutes les conditions de jointure sont associées à un opérateur AND, ce qui signifie que toutes les conditions doivent être remplies pour avoir une correspondance. Dans ce lab, nous souhaitons faire correspondre les colonnes
medallion,hack_license,vendor_idetpickup_datetime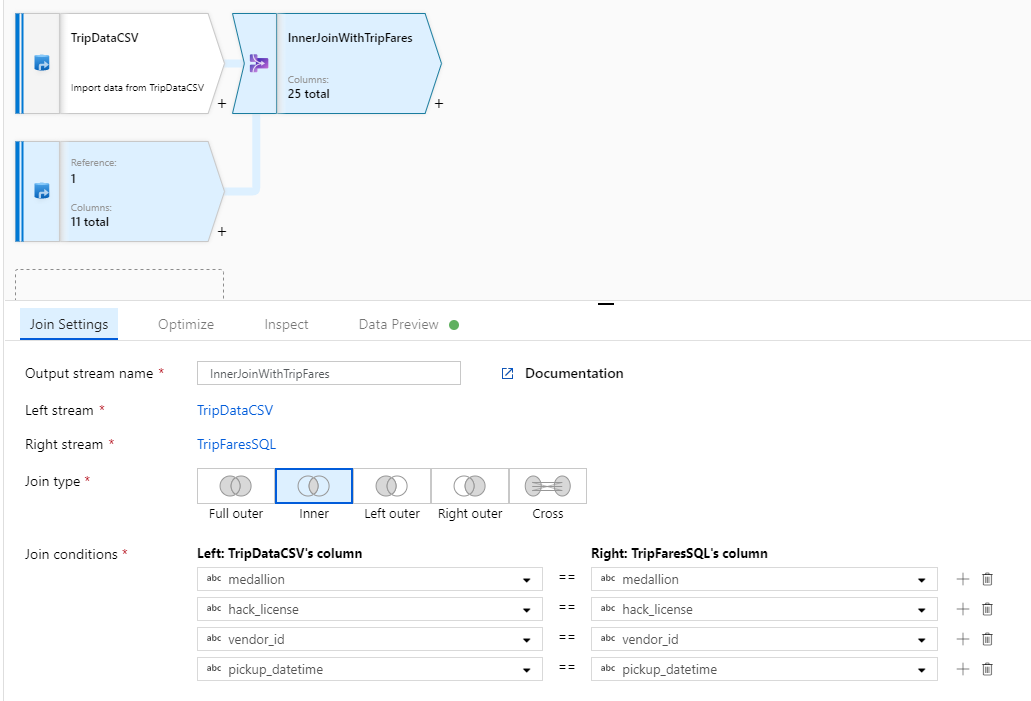
Vérifiez que vous avez correctement effectué la jointure de 25 colonnes à l’aide d’un aperçu des données.
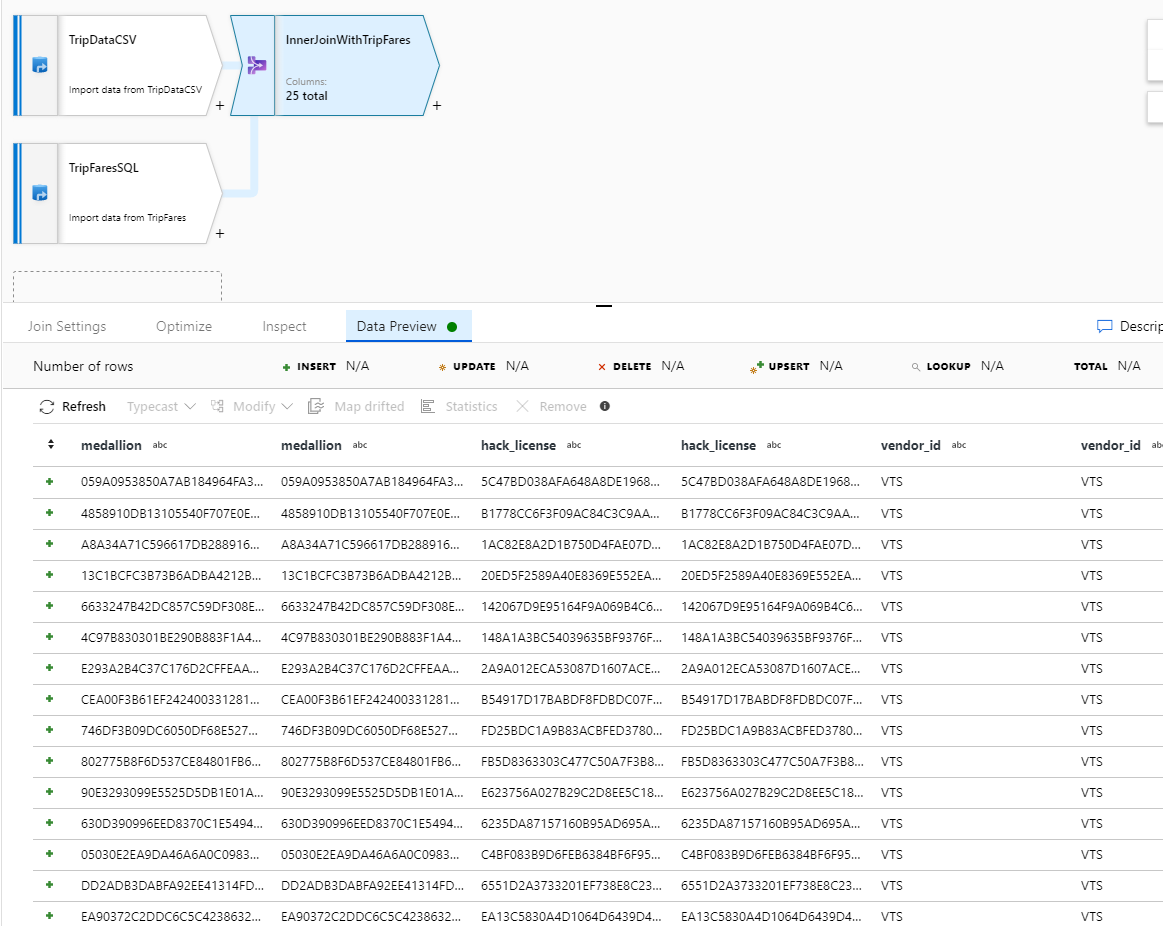


Agréger par payment_type
Une fois que vous avez fini d’effectuer votre transformation de jointure, ajoutez une transformation d’agrégat en sélectionnant l’icône représentant un signe plus à côté de InnerJoinWithTripFares. Choisissez Aggregate (Agrégat) sous Schema modifier (Modificateur de schéma).
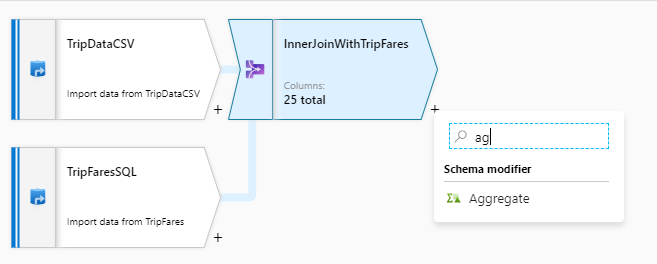
Nommez votre transformation d’agrégat « AggregateByPaymentType ». Sélectionnez
payment_typeen tant que colonne de regroupement.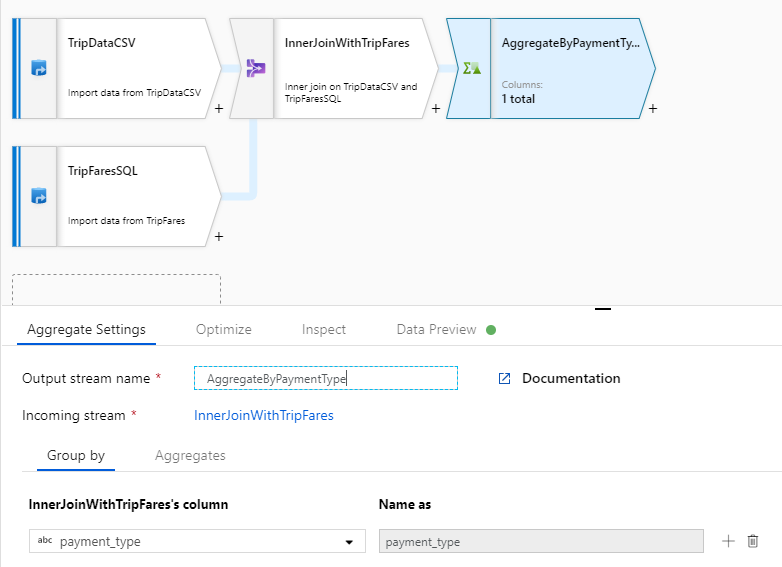
Accédez à l’onglet Agrégats. Spécifiez deux agrégations :
- Le tarif moyen regroupé par type de paiement
- La distance totale du trajet regroupée par type de paiement
Pour commencer, vous allez créer l’expression correspondant au tarif moyen. Dans la zone de texte intitulée Add or select a column (Ajouter ou sélectionner une colonne), entrez « average_fare ».
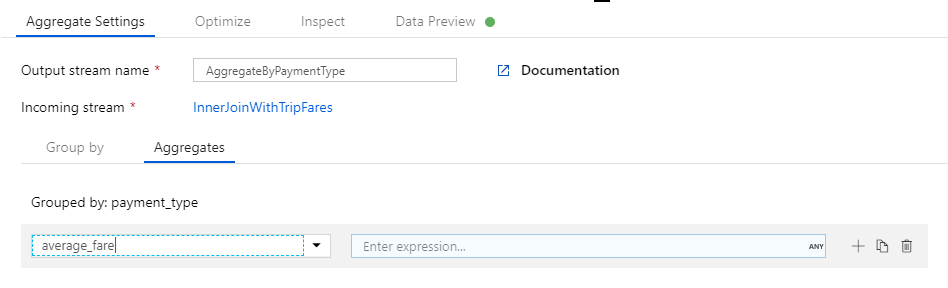
Pour entrer une expression d’agrégation, sélectionnez la zone bleue intitulée Entrer une expression, ce qui ouvre le Générateur d’expressions de flux de données, un outil utilisé pour créer visuellement des expressions de flux de données à l’aide d’un schéma d’entrée, de fonctions et d’opérations intégrées ainsi que de paramètres définis par l’utilisateur. Pour plus d’informations sur les fonctionnalités du Générateur d’expressions, consultez la documentation du Générateur d’expressions.
Pour obtenir le tarif moyen, utilisez la fonction d’agrégation
avg()afin d’agréger le cast de la colonnetotal_amounten entier avectoInteger(). En langage d’expression de flux de données, cela est défini sous la formeavg(toInteger(total_amount)). Une fois que vous avez fini, cliquez sur Enregistrer et terminer.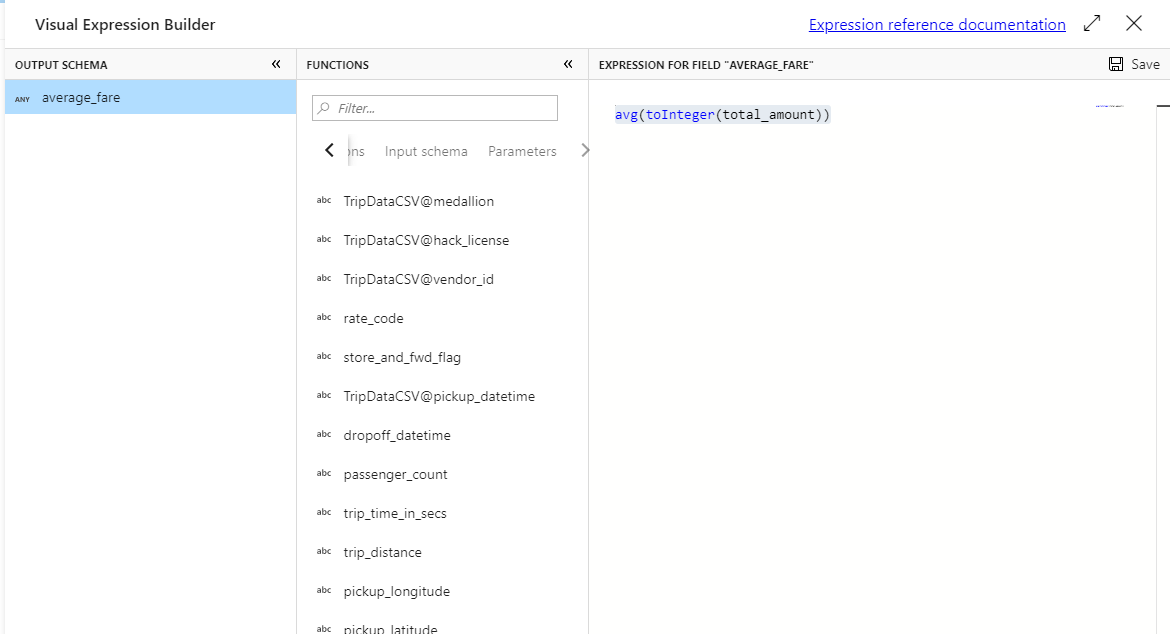
Pour ajouter une expression d’agrégation supplémentaire, cliquez sur l’icône représentant un signe plus à côté de
average_fare. Sélectionnez Add column (Ajouter une colonne).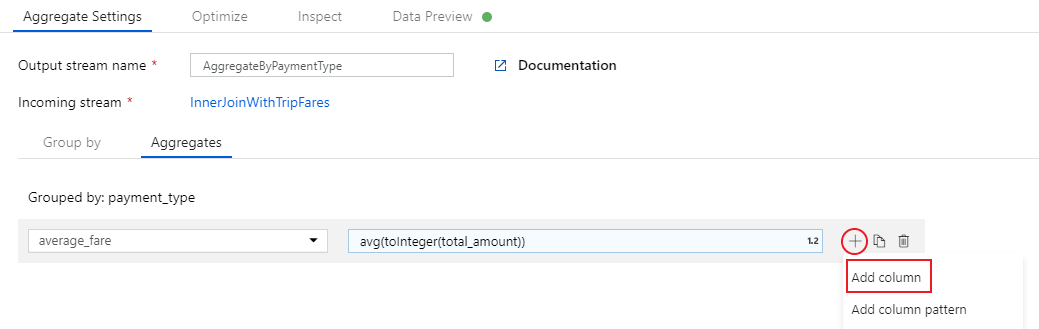
Dans la zone de texte intitulée Add or select a column (Ajouter ou sélectionner une colonne), entrez « total_trip_distance ». Comme à la dernière étape, ouvrez le Générateur d’expressions pour entrer l’expression.
Pour obtenir la distance totale du trajet, utilisez la fonction d’agrégation
sum()afin d’agréger le cast de la colonnetrip_distanceen entier avectoInteger(). En langage d’expression de flux de données, cela est défini sous la formesum(toInteger(trip_distance)). Une fois que vous avez fini, cliquez sur Enregistrer et terminer.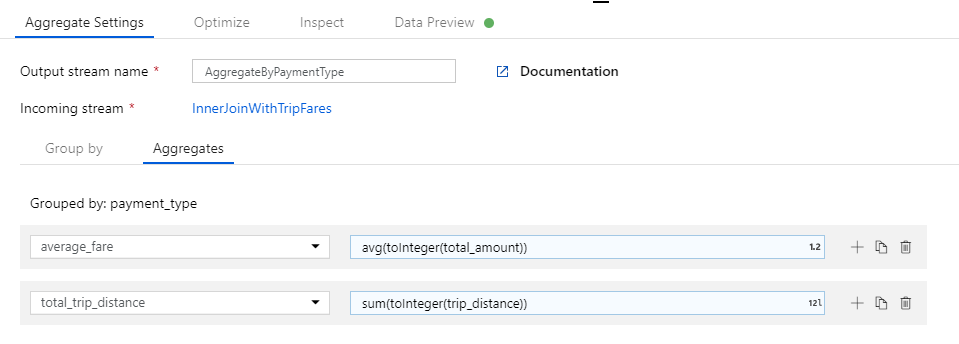
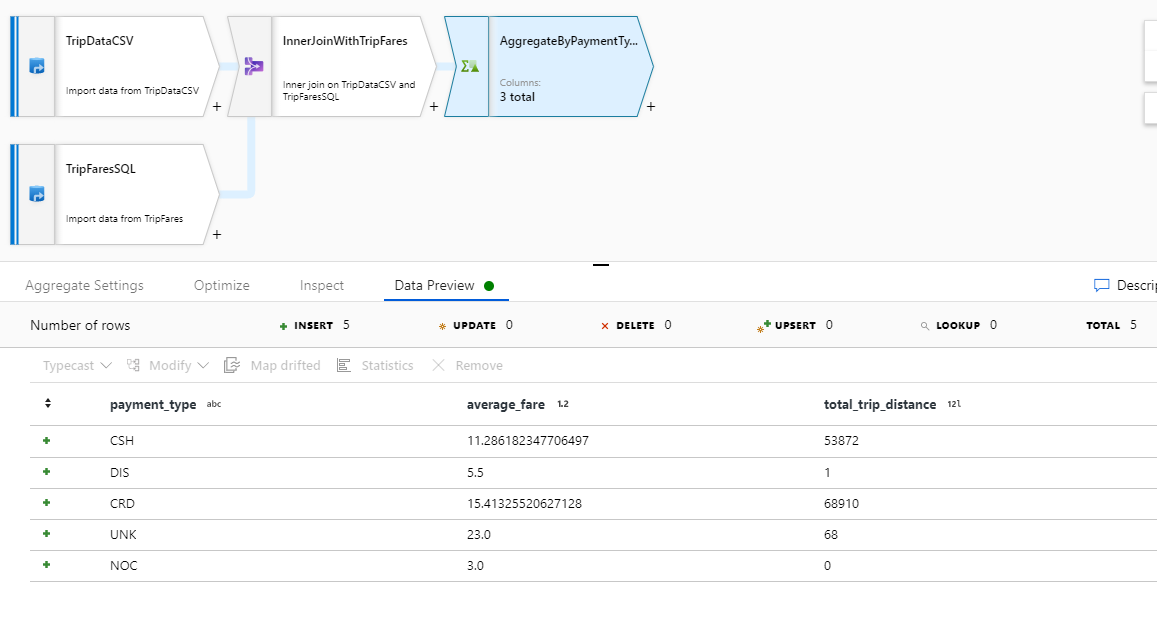
Testez votre logique de transformation sous l’onglet Data Preview. Comme vous pouvez le voir, il existe beaucoup moins de lignes et de colonnes qu’auparavant. Seules les trois colonnes de regroupement et d’agrégation définies dans cette transformation se poursuivent en aval. Comme il n’existe que cinq groupes de types de paiement dans l’exemple, seules cinq lignes sont générées.





Configurer votre récepteur Azure Synapse Analytics
Une fois que nous avons fini de travailler sur la logique de transformation, nous sommes prêts à créer un récepteur de nos données dans une table Azure Synapse Analytics. Ajoutez une transformation de récepteur sous la section Destination.
Nommez votre récepteur « SQLDWSink ». Cliquez sur Nouveau à côté du champ de jeu de données récepteur pour créer un jeu de données Azure Synapse Analytics.
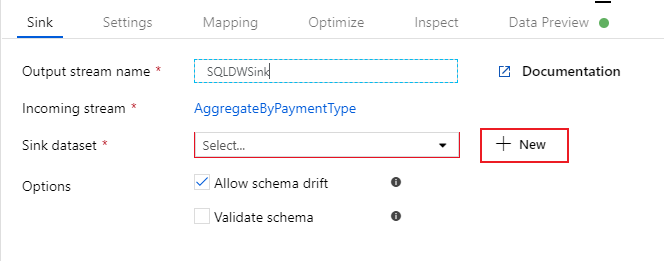
Sélectionnez la tuile Azure Synapse Analytics et sélectionnez continuer.
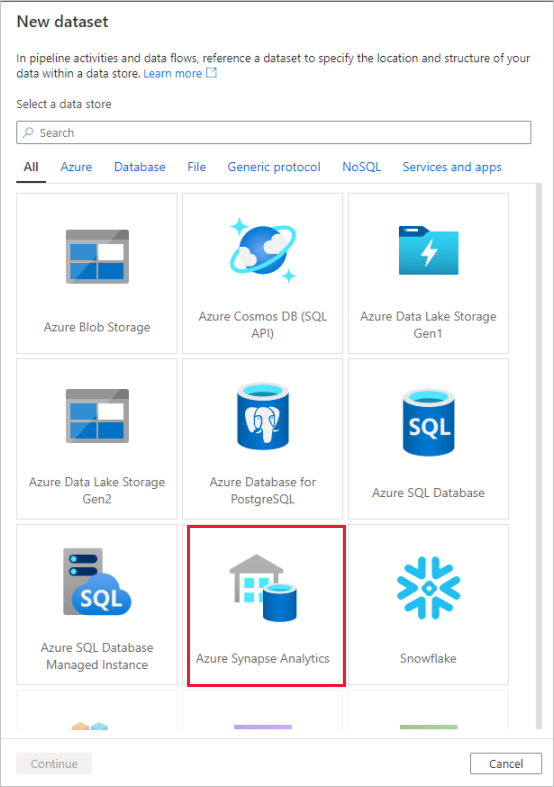
Appelez votre jeu de données « AggregatedTaxiData ». Sélectionnez « SQLDW » en tant que service lié. Sélectionnez Create new table (Créer une table), puis nommez la nouvelle table
dbo.AggregateTaxiData. Lorsque vous avez terminé, sélectionnez OK.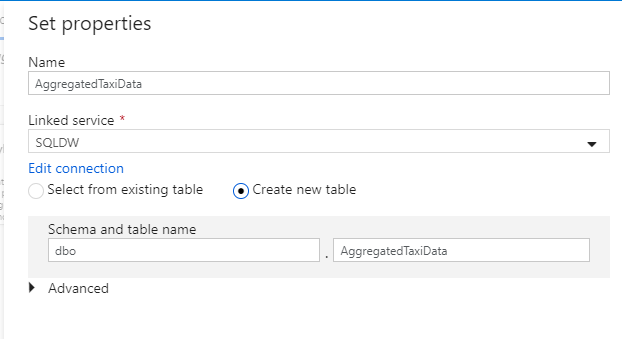
Accédez à l’onglet Settings (Paramètres) du récepteur. Comme nous créons une table, nous devons sélectionner Recreate table (Recréer la table) sous l’action de table. Décochez Enable staging (Activer la préproduction), qui nous permet de passer de l’insertion ligne par ligne à l’insertion par lot, et inversement.
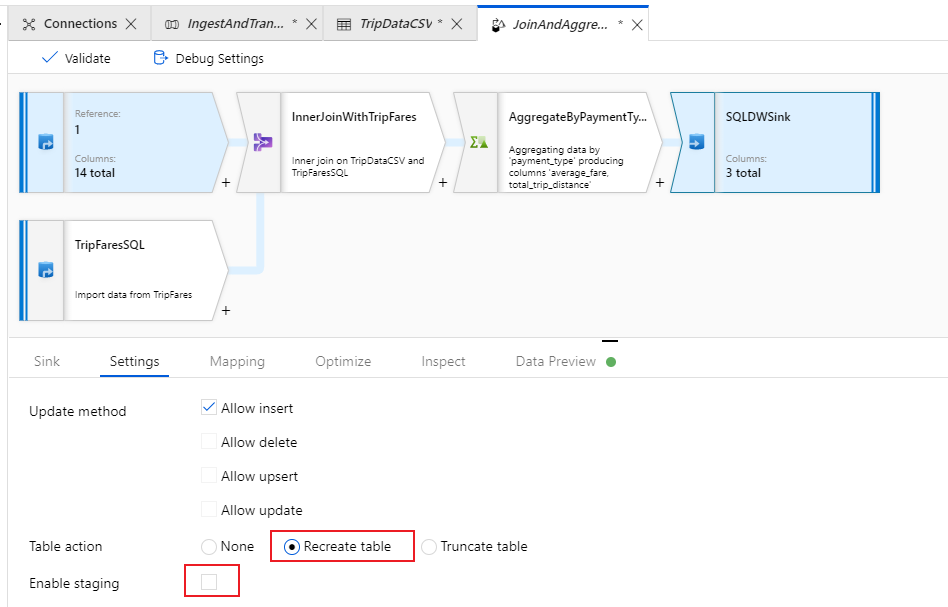


Vous avez réussi à créer votre flux de données. Il est temps maintenant de l’exécuter dans une activité de pipeline.
Déboguer votre pipeline de bout en bout
Revenez à l’onglet du pipeline IngestAndTransformData. Notez la zone verte dans l’activité de copie « IngestIntoADLS ». Faites-la glisser vers l’activité de flux de données « JoinAndAggregateData ». Cela entraîne la création d’un élément « en cas de réussite », qui déclenche l’exécution de l’activité de flux de données uniquement si la copie est réussie.
Comme nous l’avons fait pour l’activité de copie, cliquez sur Debug pour effectuer une exécution de débogage. Pour les exécutions de débogage, l’activité de flux de données utilise le cluster de débogage actif au lieu de démarrer un nouveau cluster. L’exécution de ce pipeline prend un peu plus d’une minute.
Tout comme l’activité de copie, le flux de données a une vue de supervision spéciale, accessible via l’icône de lunettes à la fin de l’activité.
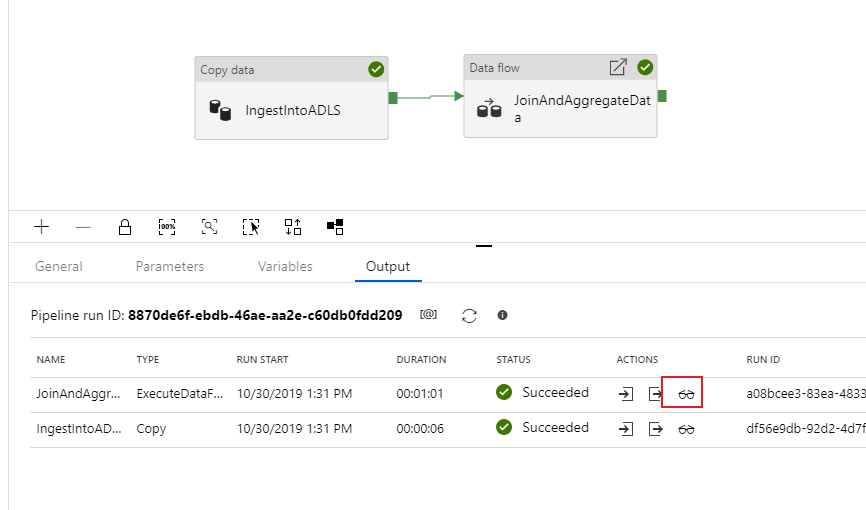
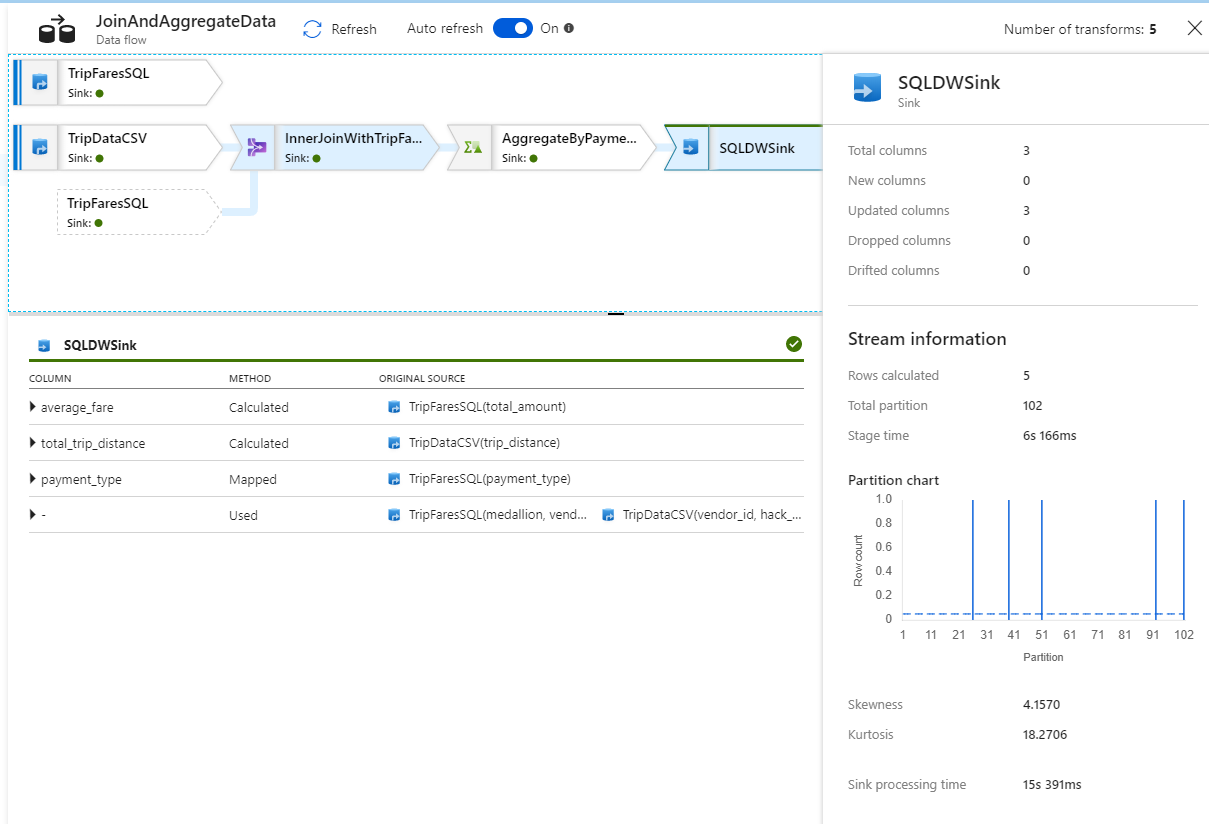
Dans la vue de supervision, vous pouvez voir un graphe de flux de données simplifié avec les temps d’exécution et les lignes à chaque étape d’exécution. Si tout est correct, vous devez avoir agrégé 49 999 lignes en cinq lignes dans cette activité.

Vous pouvez cliquer sur une transformation pour obtenir des détails supplémentaires sur son exécution, par exemple les informations de partitionnement ainsi que les colonnes nouvelles/mises à jour/supprimées.




Vous avez fini à présent la partie fabrique de données de ce lab. Publiez vos ressources si vous souhaitez les faire fonctionner avec des déclencheurs. Vous avez réussi à exécuter un pipeline qui a ingéré des données d’Azure SQL Database vers Azure Data Lake Storage à l’aide de l’activité de copie, puis vous avez agrégé ces données dans Azure Synapse Analytics. Vous pouvez vérifier que les données ont été correctement écrites en examinant le serveur SQL Server lui-même.
Partagez des données avec Azure Data Share
Dans cette section, vous apprenez à configurer un nouveau partage de données à l’aide du portail Azure. Cela implique la création d’un partage de données qui contient des jeux de données provenant d’Azure Data Lake Storage Gen2 et d’Azure Synapse Analytics. Vous allez configurer ensuite une planification d’instantanés, qui permettra aux consommateurs de données d’actualiser automatiquement les données partagées avec eux. Vous allez ensuite inviter des destinataires à accéder à votre partage de données.
Une fois que vous avez créé un partage de données, vous changez de rôle et devenez le consommateur de données. En tant que consommateur de données, vous suivez le flux de l’acceptation d’une invitation à un partage de données, en configurant l’emplacement où vous souhaitez que les données soient reçues et en mappant les jeux de données à différents emplacements de stockage. Vous allez ensuite déclencher une capture instantanée, qui va copier les données partagées avec vous dans la destination spécifiée.
Partager des données (flux du fournisseur de données)
Ouvrez le portail Azure dans Microsoft Edge ou Google Chrome.
À l’aide de la barre de recherche en haut de la page, recherchez Partages de données
Sélectionnez le compte de partage de données qui contient « Provider » (Fournisseur) dans son nom. Par exemple, DataProvider0102.
Sélectionnez Start sharing your data (Commencer à partager vos données)
Sélectionnez +Create (+Créer) pour commencer à configurer votre nouveau partage de données.
Sous Share name (Nom du partage), indiquez le nom de votre choix. Il s’agit du nom de partage visible par votre consommateur de données. Veillez donc à lui donner un nom descriptif, par exemple TaxiData.
Sous Description, entrez une phrase qui décrit le contenu du partage de données. Le partage de données contient des données relatives aux trajets de taxi dans le monde entier. Ces données sont stockées dans une variété de magasins, notamment Azure Synapse Analytics et Azure Data Lake Storage.
Sous Conditions d’utilisation, spécifiez un ensemble de conditions auxquelles vous souhaitez que votre consommateur de données adhère. Certains exemples incluent « Do not distribute this data outside your organization » (Ne pas diffuser ces données en dehors de votre organisation) ou « Refer to legal agreement » (Se référer à l’accord juridique).
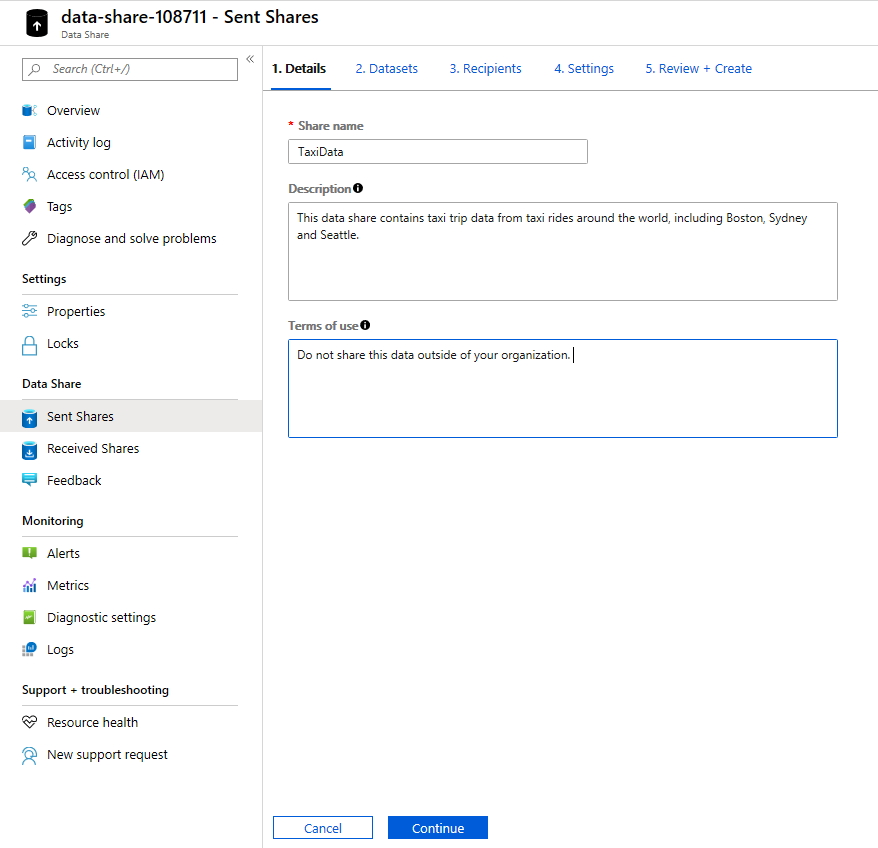
Sélectionnez Continuer.
Sélectionnez Ajouter des jeux de données
Sélectionnez Azure Synapse Analytics pour sélectionner une table Azure Synapse Analytics où vos transformations ADF ont été placées.
Vous recevez un script à exécuter pour pouvoir continuer. Le script fourni crée un utilisateur dans la base de données SQL pour permettre au MSI Azure Data Share de s’authentifier en son nom.
Important
Avant d’exécuter le script, vous devez vous définir en tant qu’administrateur Active Directory pour le serveur SQL Server logique de l’Azure SQL Database.
Ouvrez un nouvel onglet, puis accédez au portail Azure. Copiez le script fourni pour créer un utilisateur dans la base de données dont vous souhaitez partager des données. Pour ce faire, connectez-vous à la base de données EDW à l’aide de l’Éditeur de requête dans le portail Azure en utilisant l’authentification Microsoft Entra. Vous devez modifier l’utilisateur dans l’exemple de script suivant :
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Revenez à Azure Data Share, où vous ajoutez des jeux de données à votre partage de données.
Sélectionnez EDW, puis sélectionnez AggregatedTaxiData pour la table.
Sélectionnez Ajouter un Dataset
Nous avons désormais une table SQL qui fait partie de notre jeu de données. Nous allons ensuite ajouter d’autres jeux de données à partir d’Azure Data Lake Storage.
Sélectionnez Ajouter un jeu de données, puis Azure Data Lake Storage Gen2
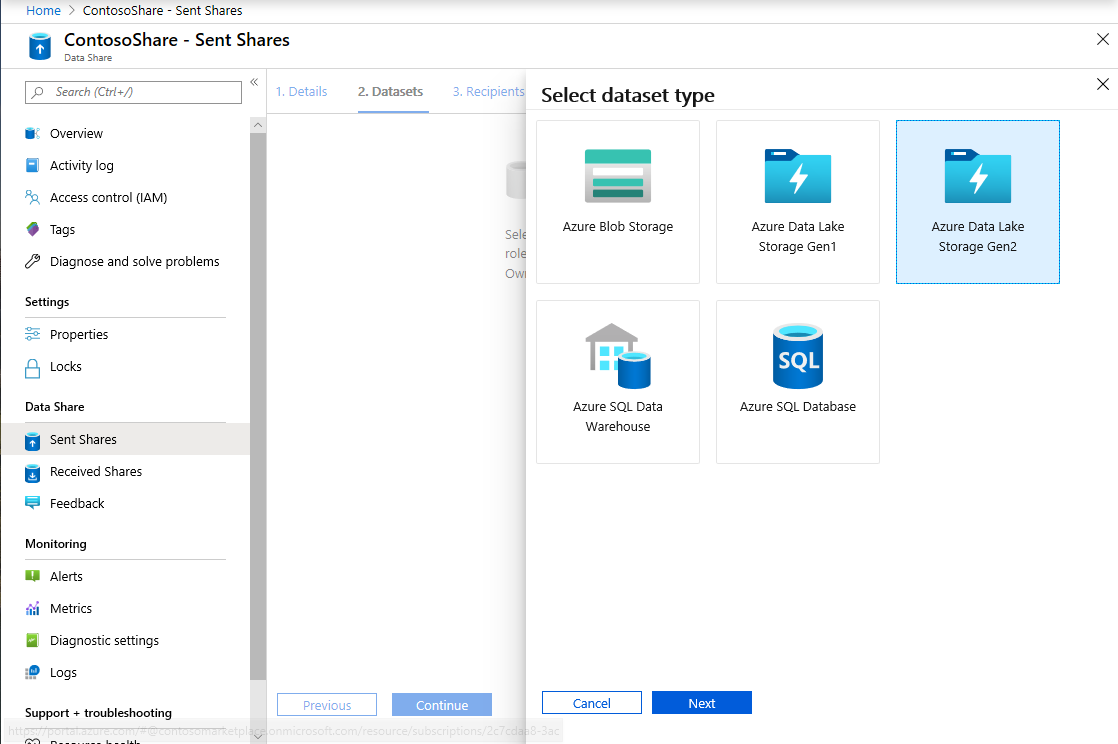
Sélectionnez Suivant.
Développez wwtaxidata. Développez Boston Taxi Data (Données sur les taxis de Boston). Vous pouvez effectuer un partage au niveau du fichier.
Sélectionnez le dossier Boston Taxi Data (Données sur les taxis de Boston) pour ajouter l’intégralité du dossier à votre partage de données.
Sélectionnez Ajouter des jeux de données
Passez en revue les jeux de données qui ont été ajoutés. Vous devez avoir ajouté une table SQL et un dossier ADLS Gen2 à votre partage de données.
Sélectionnez Continue (Continuer)
Dans cet écran, vous pouvez ajouter des destinataires à votre partage de données. Les destinataires que vous ajoutez vont recevoir des invitations à votre partage de données. Dans le cadre de ce lab, vous devez ajouter deux adresses e-mail :
L’adresse e-mail de l’abonnement Azure dans lequel vous vous trouvez.
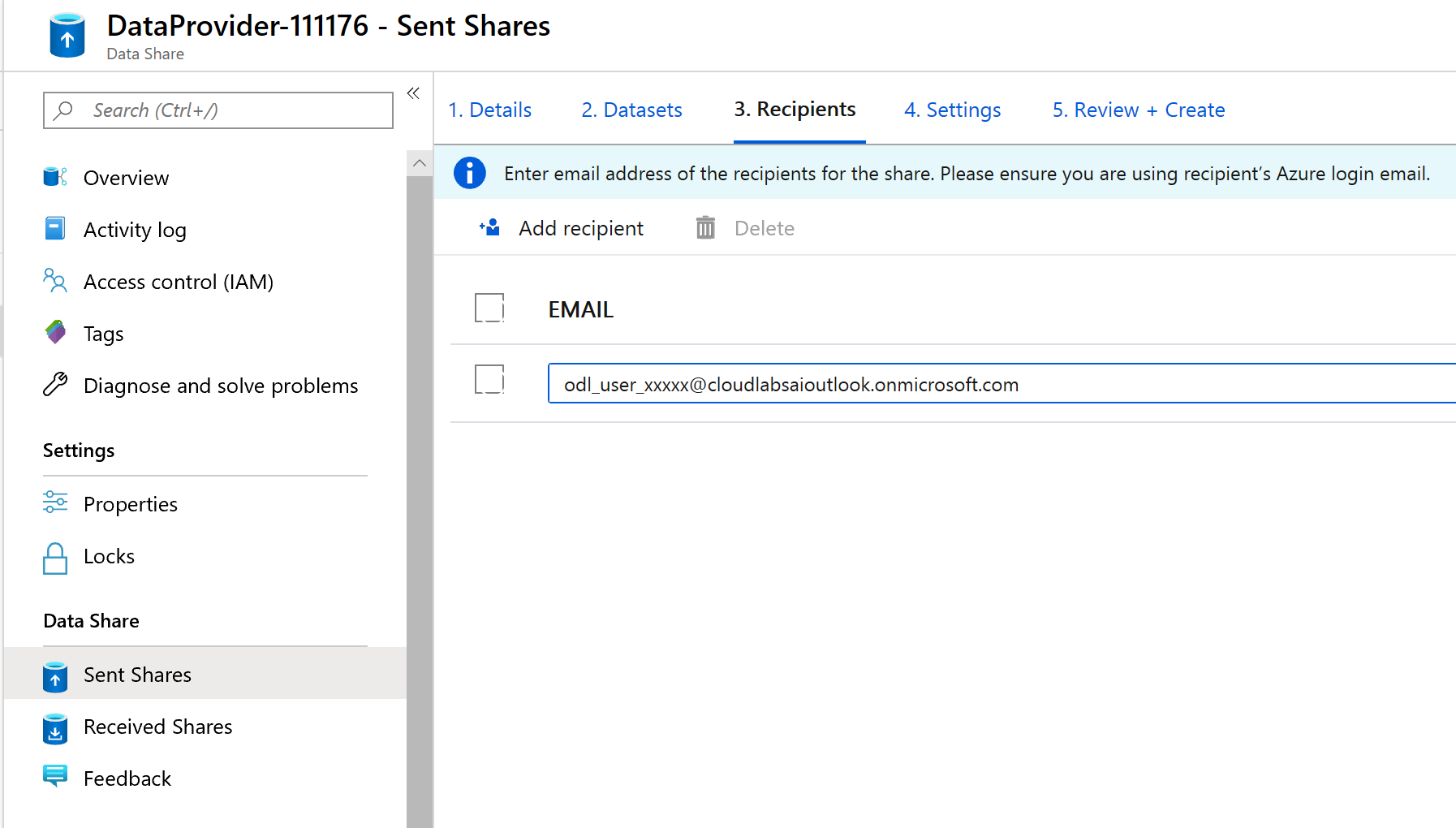
Ajoutez le consommateur de données fictives nommé janedoe@fabrikam.com .
Dans cet écran, vous pouvez configurer un paramètre de capture instantanée pour votre consommateur de données. Cela lui permet de recevoir des mises à jour régulières de vos données selon un intervalle que vous avez défini.
Consultez Planification d’instantanés, puis configurez une actualisation toutes les heures de vos données à l’aide de la liste déroulante Périodicité.
Sélectionnez Créer.
Vous avez désormais un partage de données actif. Permet de passer en revue ce que vous pouvez voir en tant que fournisseur de données quand vous créez un partage de données.
Sélectionnez le partage de données que vous avez créé, et qui s’intitule DataProvider. Vous pouvez y accéder en sélectionnant Partages envoyés dans Partage de données.
Cliquez sur Planification d’instantanés. Vous pouvez désactiver la planification d’instantanés, si vous le souhaitez.
Sélectionnez ensuite l’onglet Jeux de données. Vous pouvez ajouter des jeux de données supplémentaires à ce partage de données après sa création.
Sélectionnez l’onglet Partager des abonnements. Il n’existe aucun abonnement de partage, car votre consommateur de données n’a pas encore accepté votre invitation.
Accédez à l’onglet Invitations. Ici, vous voyez s’afficher une liste des invitations en attente.
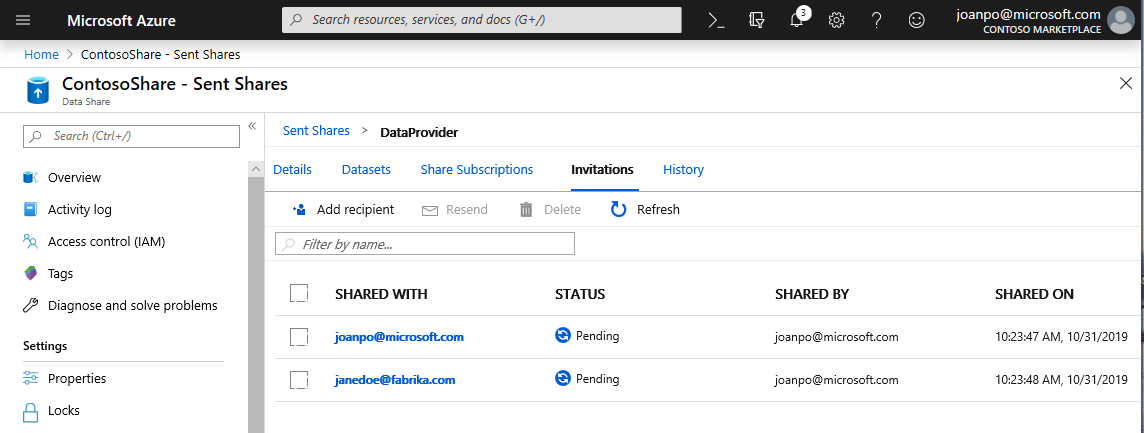
Sélectionnez l’invitation à janedoe@fabrikam.com . Sélectionnez Supprimer. Si votre destinataire n’a pas encore accepté l’invitation, il ne pourra plus le faire.
Sélectionnez l'onglet Historique . Rien ne s’affiche pour l’instant, car votre consommateur de données n’a pas encore accepté votre invitation et déclenché une capture instantanée.






Réception de données (flux du consommateur de données)
Une fois que nous avons passé en revue notre partage de données, nous sommes prêts à changer de contexte et à endosser le rôle de consommateur de données.
Vous devez maintenant avoir une invitation Azure Data Share dans votre boîte de réception en provenance de Microsoft Azure. Lancez l’Accès web Outlook (outlook.com), puis connectez-vous à l’aide des informations d’identification fournies pour votre abonnement Azure.
Dans l’e-mail que vous devez avoir reçu, cliquez sur « Afficher l’invitation> ». À ce stade, vous allez simuler l’expérience du consommateur de données qui accepte une invitation des fournisseurs de données à accéder à leur partage de données.

Vous pouvez être invité à sélectionner un abonnement. Veillez à sélectionner l’abonnement que vous avez utilisé pour ce lab.
Cliquez sur l’invitation intitulée DataProvider.
Dans cet écran Invitation, vous pouvez noter divers détails relatifs au partage de données que vous avez configuré en tant que fournisseur de données. Passez en revue les détails, puis acceptez les conditions d’utilisation, le cas échéant.
Sélectionnez l’abonnement et le groupe de ressources qui existent déjà pour votre lab.
Pour Data share account (Compte de partage de données), sélectionnez DataConsumer. Vous pouvez également créer un compte de partage de données.
À côté de Received share name (Nom de partage reçu), notez que le nom de partage par défaut est le nom spécifié par le fournisseur de données. Donnez au partage un nom convivial qui décrit les données que vous allez recevoir, par exemple TaxiDataShare.
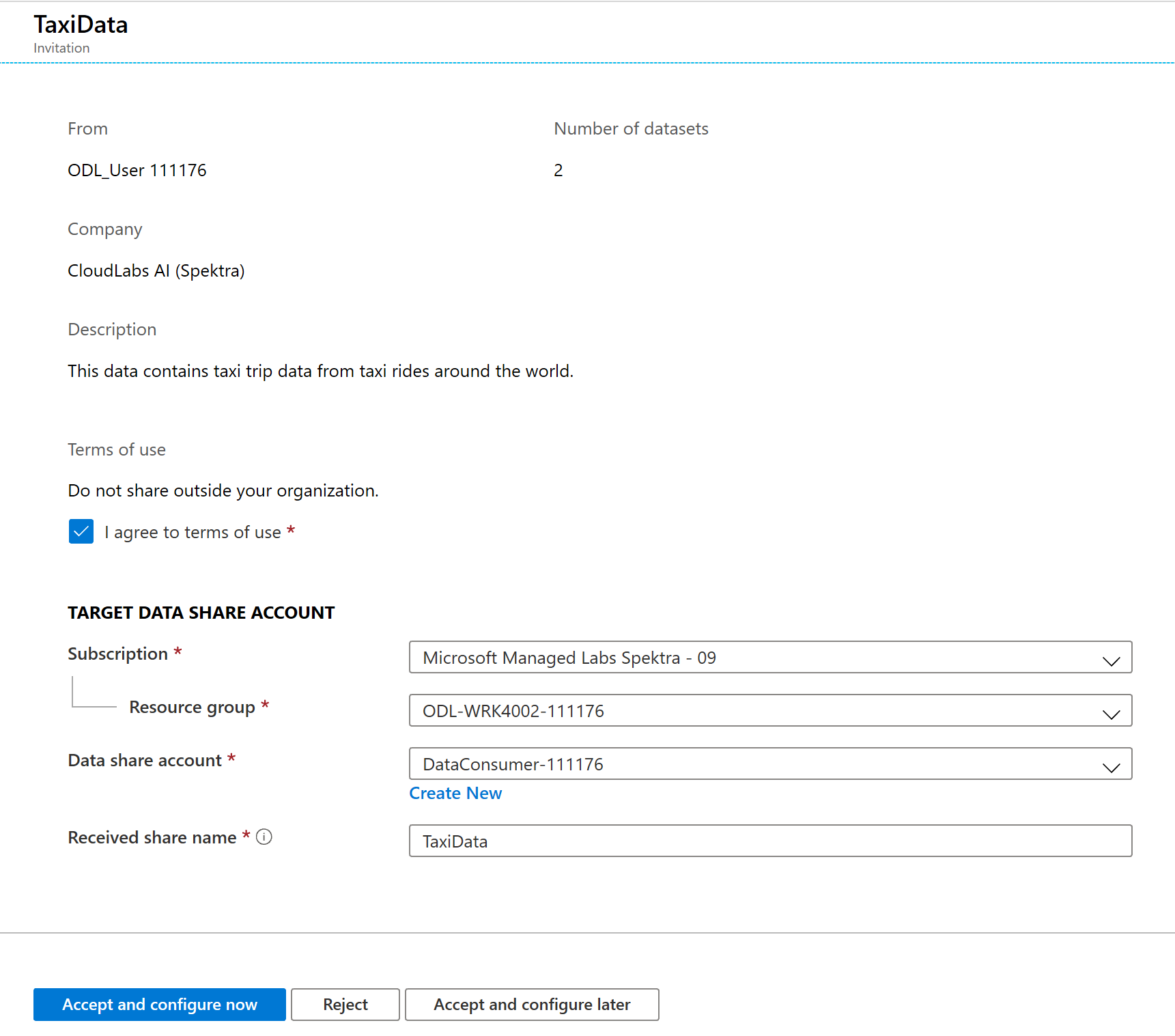
Vous pouvez choisir Accept and configure now (Accepter et configurer maintenant) ou Accept and configure later (Accepter et configurer plus tard). Si vous choisissez d’accepter l’invitation et d’effectuer la configuration maintenant, vous spécifiez un compte de stockage dans lequel toutes les données doivent être copiées. Si vous choisissez d’accepter l’invitation et d’effectuer la configuration plus tard, les jeux de données du partage ne sont pas mappés, et vous devez les mapper manuellement. Nous allons choisir cette option plus tard.
Sélectionnez Accept and configure later.
Lorsque cette option est configurée, un abonnement de partage est créé, mais il n’existe aucun emplacement de destination pour les données, car aucune destination n’a été mappée.
Nous allons ensuite configurer les mappages de jeux de données pour le partage de données.
Sélectionnez le partage reçu (le nom spécifié à l’étape 5).
Instantané de déclencheur est grisé mais le partage est actif.
Sélectionnez l’onglet Jeux de données. Chaque jeu de données est non mappé, ce qui signifie qu’il n’existe aucune destination vers laquelle copier les données.
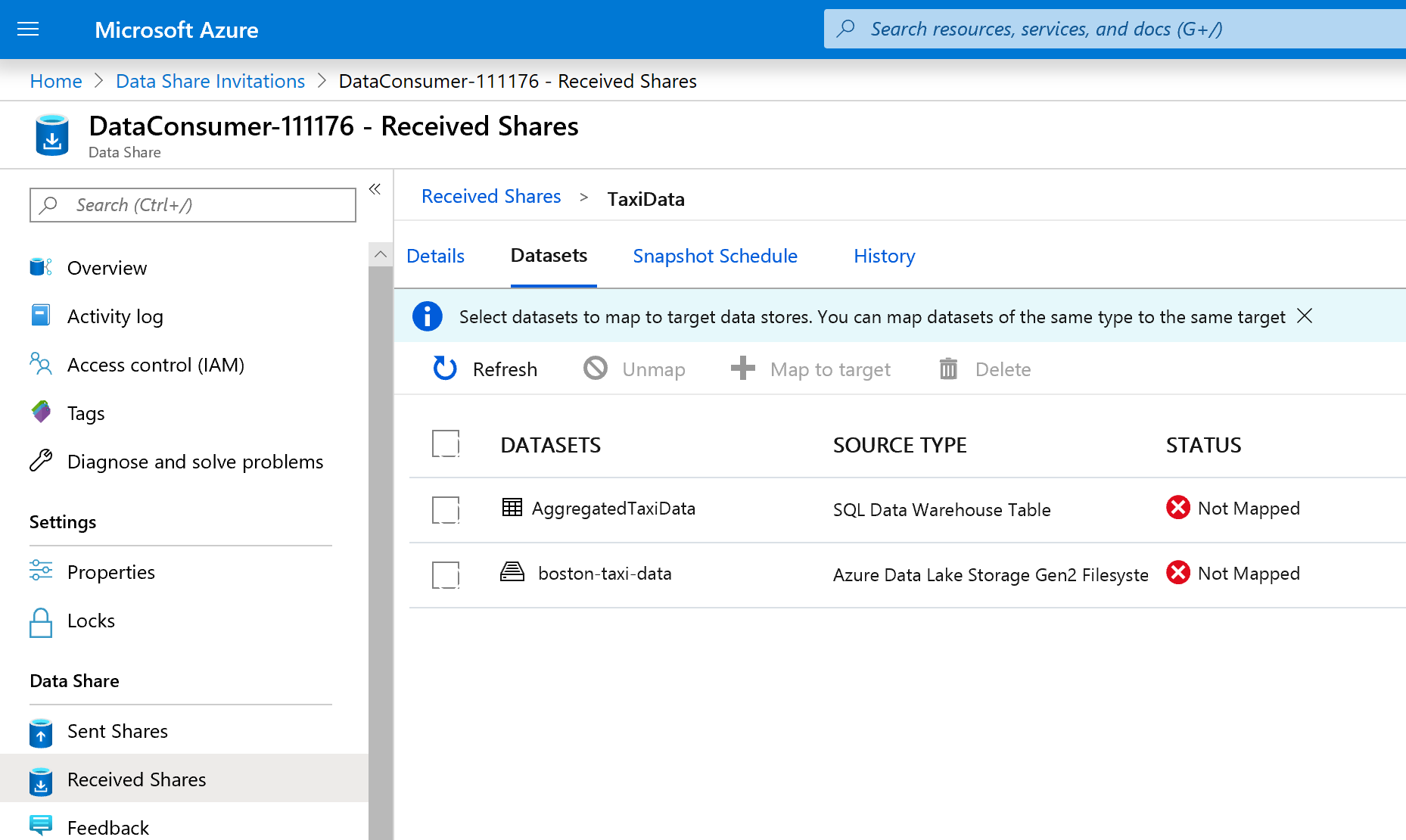
Sélectionnez la table Azure Synapse Analytics, puis sélectionnez + Mapper à la cible.
Dans la partie droite de l’écran, sélectionnez la liste déroulante Type de données cible.
Vous pouvez mapper les données SQL à un large éventail de magasins de données. Dans le cas présent, nous allons effectuer un mappage à une base de données Azure SQL Database.
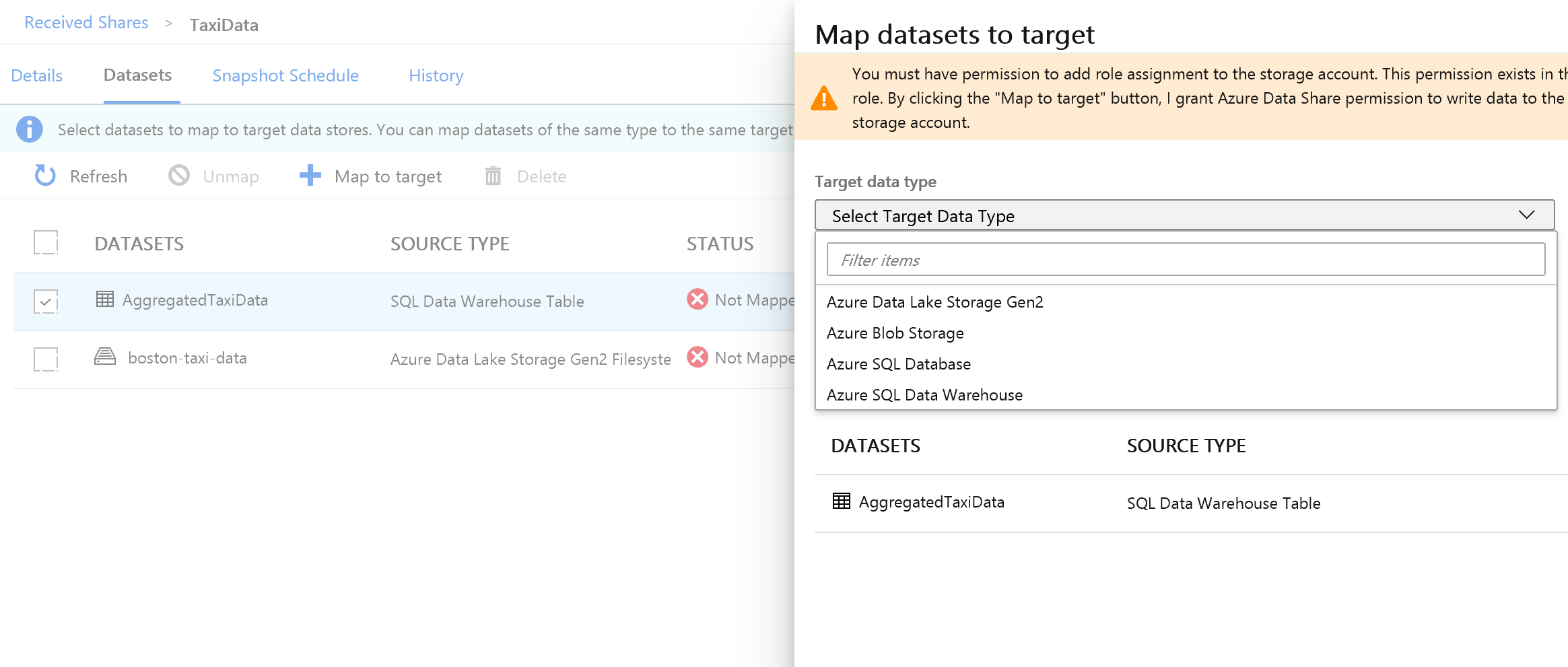
(Facultatif) Sélectionnez Azure Data Lake Storage Gen2 en tant que type de données cible.
(Facultatif) Sélectionnez l’abonnement, le groupe de ressources et le compte de stockage que vous avez utilisés.
(Facultatif) Vous pouvez choisir de recevoir les données dans votre lac de données au format CSV ou Parquet.
À côté de Type de données cible, sélectionnez Azure SQL Database.
Sélectionnez l’abonnement, le groupe de ressources et le compte de stockage que vous avez utilisés.
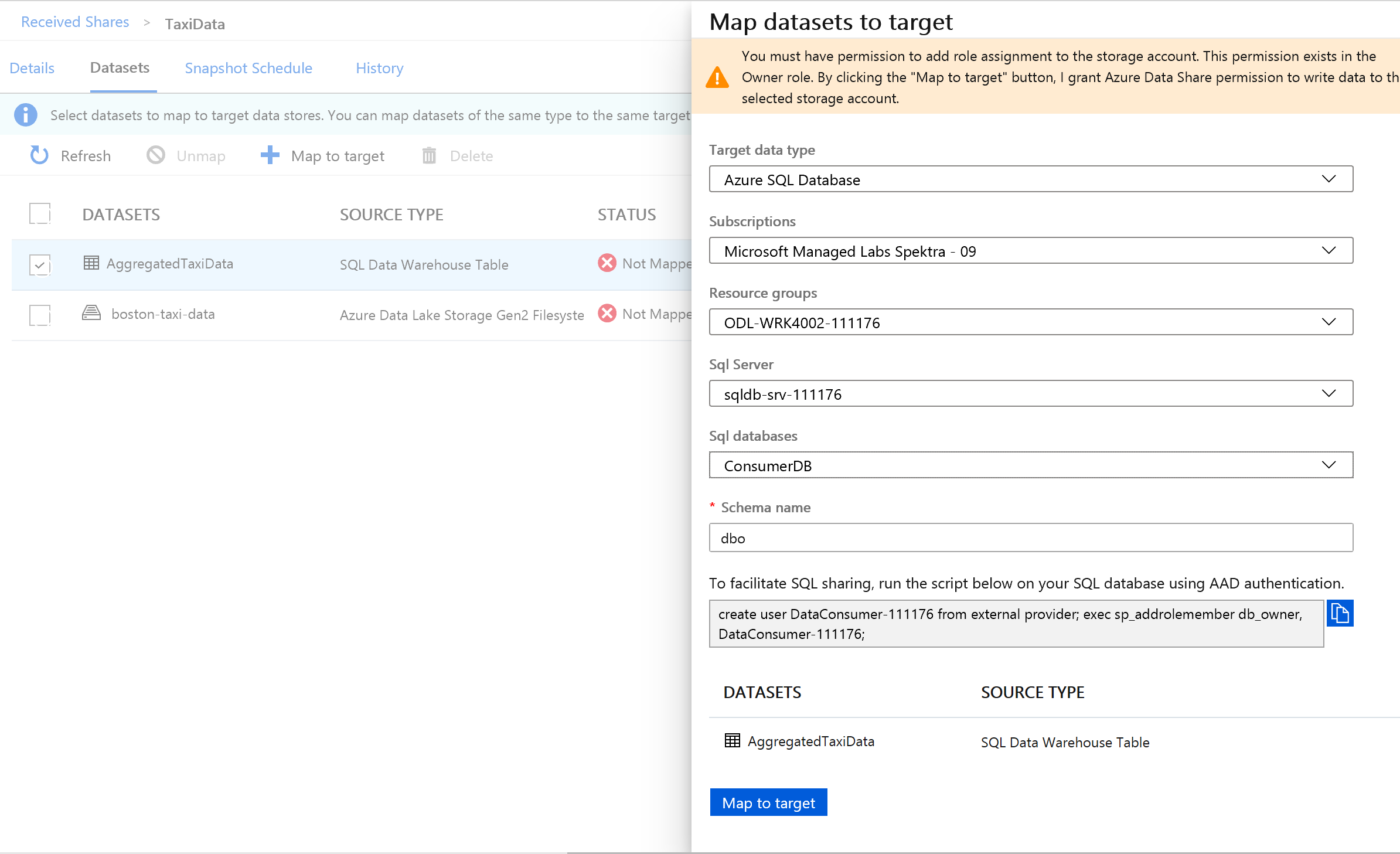
Pour pouvoir continuer, vous devez créer un utilisateur dans SQL Server en exécutant le script fourni. Tout d’abord, copiez le script fourni dans le Presse-papiers.
Ouvrez un nouvel onglet de portail Azure. Ne fermez pas votre onglet existant, car vous devrez y revenir dans quelques instants.
Sous le nouvel onglet que vous avez ouvert, accédez à Bases de données SQL.
Sélectionnez la base de données SQL (il ne doit y en avoir qu’une seule dans votre abonnement). Veillez à ne pas sélectionner l’entrepôt de données.
Sélectionnez Éditeur de requêtes (préversion)
Utilisez l’authentification Microsoft Entra pour vous connecter à l’éditeur de requête.
Exécutez la requête fournie dans votre partage de données (copiée dans le Presse-papiers à l’étape 14).
Cette commande permet au service Azure Data Share d’utiliser les identités managées pour les services Azure afin de s’authentifier auprès du serveur SQL Server et d’y copier des données.
Revenez à l’onglet d’origine, puis sélectionnez Mapper à la cible.
Sélectionnez ensuite le dossier Azure Data Lake Storage Gen2 faisant partie du jeu de données, et mappez-le à un compte Stockage Blob Azure.
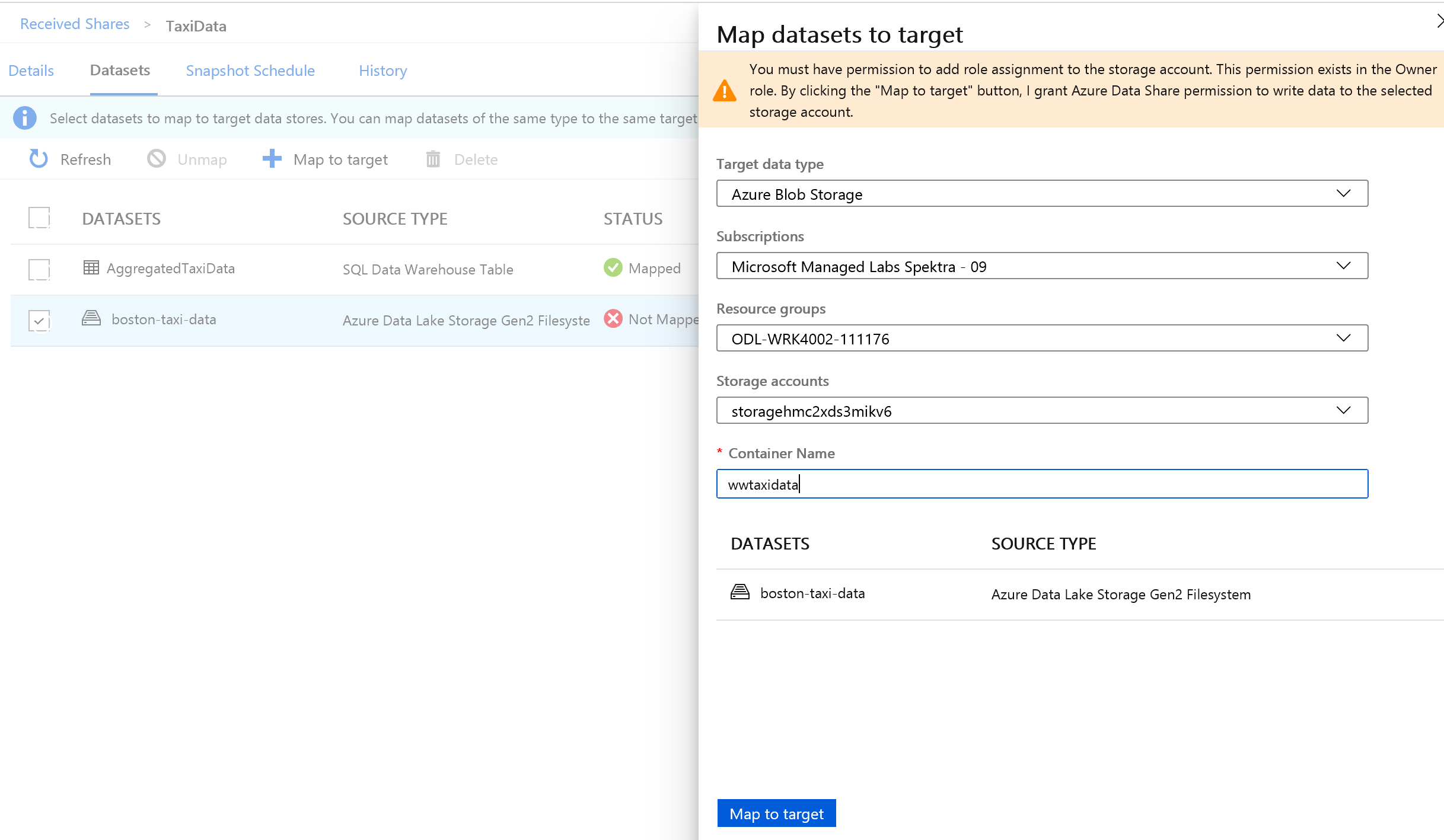
Une fois tous les jeux de données mappés, vous êtes prêt à recevoir les données du fournisseur de données.
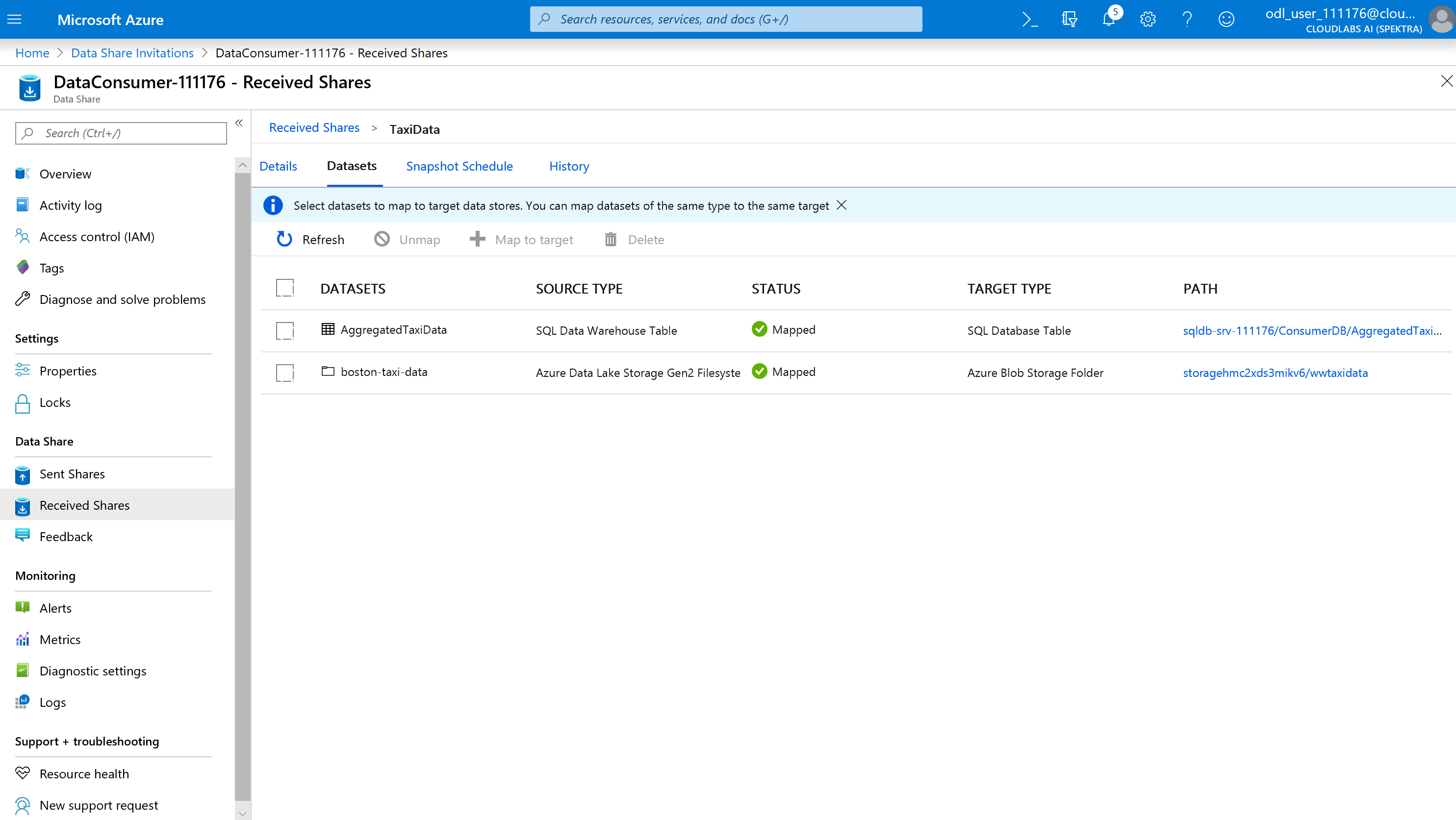
Sélectionnez Details (Détails).
Instantané de déclencheur n’est plus grisé, car le partage de données a désormais des destinations de copie.
Sélectionnez Instantané de déclencheur - >Copie complète.
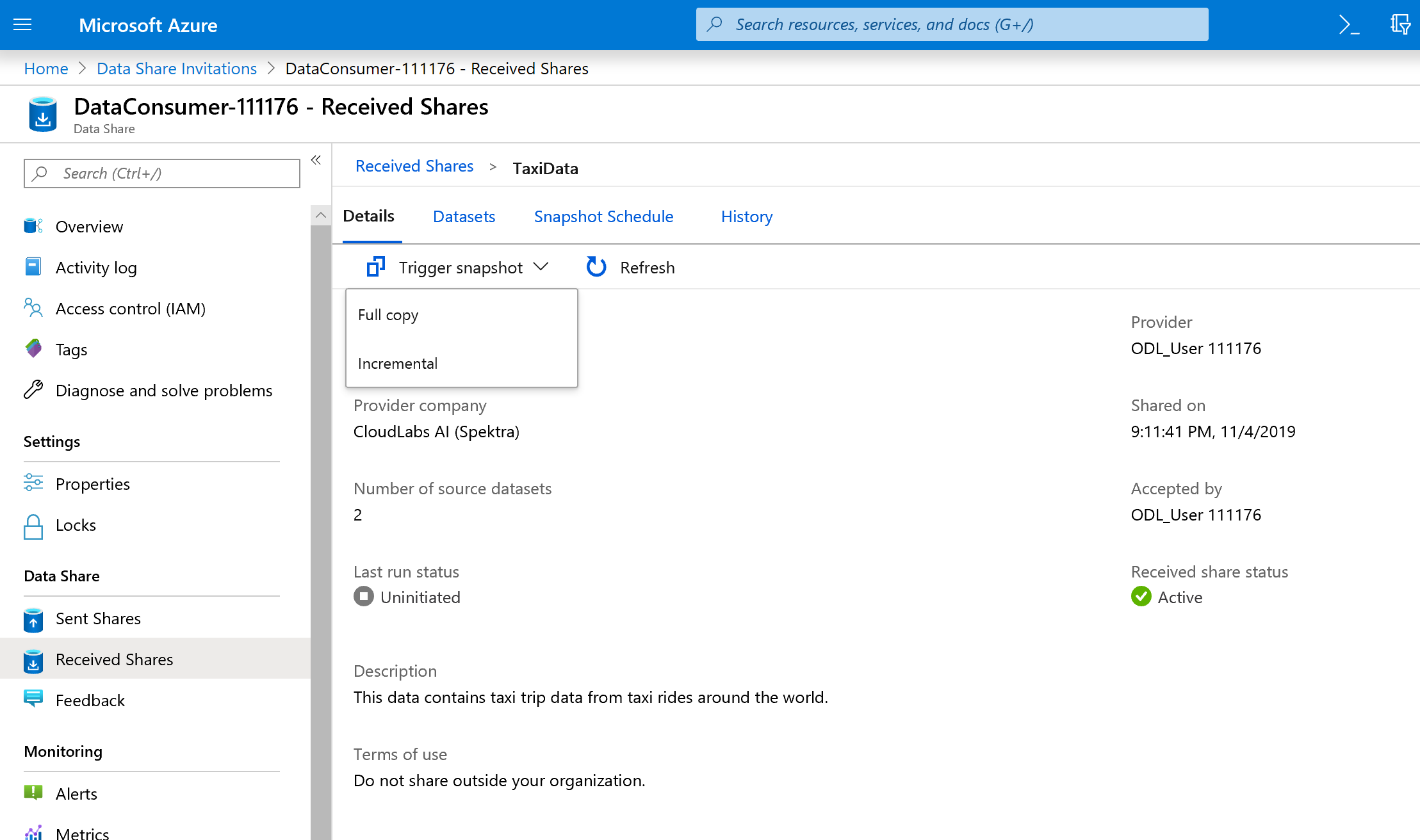
Cela déclenche la copie des données vers votre nouveau compte de partage de données. Dans un scénario réel, ces données proviennent d’un tiers.
Il faut environ 3 à 5 minutes pour que les données soient transmises. Vous pouvez superviser la progression en sélectionnant l’onglet Historique.
Pendant l’attente, accédez au partage de données d’origine (DataProvider), et affichez l’état des onglets Partager des abonnements et Historique. Il existe désormais un abonnement actif. En tant que fournisseur de données, vous pouvez également superviser le moment où le consommateur de données commence à recevoir les données partagées.
Revenez au partage de données du consommateur de données. Une fois que le déclencheur est à l’état de réussite, accédez à la base de données SQL et au lac de données de destination. Vous pouvez constater que les données sont parvenues dans les magasins respectifs.







Félicitations, vous avez fini le lab !