Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures
Remarque
Databricks Connect vous recommande d’utiliser Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures à la place.
Databricks ne prévoit aucune nouvelle fonctionnalité pour Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures.
Databricks Connect vous permet de connecter des IDE populaires tels que Visual Studio Code et PyCharm, des serveurs de notebooks et d’autres applications personnalisées à des clusters Azure Databricks.
Cet article explique le fonctionnement de Databricks Connect, vous guide tout au long des étapes de prise en main de Databricks Connect, explique comment résoudre les problèmes qui peuvent survenir lors de l’utilisation de Databricks Connect, ainsi que décrit la différence entre l’exécution avec Databricks Connect et l’exécution dans un notebook Azure Databricks.
Vue d’ensemble
Databricks Connect est une bibliothèque de client pour Databricks Runtime. Elle vous permet d’écrire des travaux à l’aide d’API Spark et de les exécuter à distance sur un cluster Azure Databricks plutôt que dans la session Spark locale.
Par exemple, lorsque vous exécutez la commande DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() à l’aide de Databricks Connect, la représentation logique de la commande est envoyée au serveur Spark s’exécutant dans Azure Databricks pour une exécution sur le cluster distant.
Avec Databricks Connect, vous pouvez :
- Exécutez des travaux Spark à grande échelle à partir de n’importe quelle application Python, R, Scala ou Java. Partout où vous pouvez effectuer des opérations
import pyspark,require(SparkR)ouimport org.apache.spark, vous pouvez maintenant exécuter des tâches Spark directement à partir de votre application, sans avoir à installer de plug-ins IDE ou à utiliser des scripts d’envoi Spark. - Effectuer un pas à pas détaillé et déboguer du code dans votre IDE même lorsque vous travaillez avec un cluster distant.
- Effectuer des itérations rapides lors du développement de bibliothèques. Vous n’avez pas besoin de redémarrer le cluster après avoir modifié les dépendances de bibliothèque Python ou Java dans Databricks Connect, car chaque session client est isolée des autres dans le cluster.
- Arrêter les clusters inactifs sans perdre votre travail. Étant donné que l’application cliente est dissociée du cluster, elle n’est pas affectée par les redémarrages ou les mises à niveau du cluster, ce qui entraîne normalement la perte de l’ensemble des variables, jeux de données distribués résilients (RDD) et objets DataFrame définis dans un notebook.
Remarque
Pour le développement Python avec des requêtes SQL, Databricks recommande d’utiliser le connecteur Databricks SQL pour Python plutôt que Databricks Connect. Le connecteur Databricks SQL pour Python est plus facile à configurer que Databricks Connect. En outre, Databricks Connect analyse et planifie les exécutions de travaux sur votre ordinateur local, tandis que les travaux s’exécutent sur des ressources de calcul distantes. Cela peut rendre particulièrement difficile le débogage des erreurs d’exécution. Le connecteur Databricks SQL pour Python soumet des requêtes SQL directement aux ressources de calcul distantes et récupère les résultats.
Exigences
Cette section répertorie les spécifications pour Databricks Connect.
Seules les versions de Databricks Runtime suivantes sont prises en charge :
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Vous devez installer Python 3 sur votre machine de développement et la version mineure de votre installation cliente de Python doit être identique à la version Python mineure de votre cluster Azure Databricks. La table suivante indique la version de Python installée avec chaque version de Databricks Runtime.
Version de Databricks Runtime Version Python 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3.7 Databricks recommande vivement d’avoir un environnement virtuel Python activé pour chaque projet de code Python que vous utilisez avec Databricks Connect. Les environnements virtuels Python garantissent que vous utilisez les bonnes versions de Python et Databricks Connect ensemble. Cela peut aider à diminuer le temps passé à la résolution des problèmes techniques associés.
Par exemple, si vous utilisez venv sur votre ordinateur de développement et que votre cluster exécute Python 3.9, vous devez créer un environnement
venvavec cette version. L’exemple de commande suivant génère les scripts pour activer un environnementvenvavec Python 3.9, puis cette commande place ces scripts dans un dossier masqué nommé.venvdans le répertoire de travail actuel :# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvAfin d’utiliser ces scripts pour activer cet environnement
venv, consultez la page Fonctionnement des venvs.Par exemple, si vous utilisez Conda sur votre environnement de développement local et que votre cluster exécute Python 3.9, vous devez créer un environnement avec cette version, par exemple :
conda create --name dbconnect python=3.9Pour activer l’environnement Conda avec ce nom d’environnement, exécutez
conda activate dbconnect.La version de package majeure et mineure de Databricks Connect doit toujours correspondre à votre version de Databricks Runtime. Databricks vous recommande de toujours utiliser le package le plus récent de Databricks Connect qui correspond à votre version de Databricks Runtime. Par exemple, lorsque vous utilisez un cluster Databricks Runtime 12.2 LTS, vous devriez aussi utiliser le package
databricks-connect==12.2.*.Remarque
Consultez les notes de publication de Databricks Connect pour obtenir la liste des versions et des mises à jour de maintenance de Databricks Connect.
Java Runtime Environment (JRE) 8. Le client a été testé avec l’environnement OpenJDK 8 JRE. Le client ne prend pas en charge Java 11.
Remarque
Sur Windows, si vous voyez une erreur indiquant que Databricks Connect ne parvient pas à trouver winutils.exe, consultez Impossible de trouver winutils.exe sur Windows.
Configurer le client
Effectuez les étapes suivantes pour configurer le client local pour Databricks Connect.
Notes
Avant de commencer à utiliser le client Databricks Connect local, vous devez respecter les exigences pour Databricks Connect.
Étape 1 : Installer le client Databricks Connect
Une fois votre environnement virtuel activé, désinstallez PySpark, s’il est déjà installé, en exécutant la commande
uninstall. Cela est nécessaire car le packagedatabricks-connectest en conflit avec PySpark. Pour plus d’informations, consultez Installations PySpark en conflit. Pour vérifier si PySpark est déjà installé, exécutez la commandeshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkVotre environnement virtuel étant toujours activé, installez le client Databricks Connect en exécutant la commande
install. Utilisez l’option--upgradepour mettre à niveau toute installation de client existante vers la version spécifiée.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Notes
Databricks vous recommande d’ajouter la notation « point-astérisque » pour spécifier
databricks-connect==X.Y.*au lieu dedatabricks-connect=X.Yet vous assurer que le package le plus récent est installé.
Étape 2 : Configurer les propriétés de connexion
Collectez les propriétés de configuration suivantes.
URL par espace de travail Azure Databricks. Cette valeur est également identique à
https://suivie par la valeur Nom d’hôte du serveur de votre cluster. Consultez Obtenir des détails de connexion pour une ressource de calcul Azure Databricks.Votre jeton d’accès personnel Azure Databricks ou jeton Microsoft Entra ID (anciennement Azure Active Directory).
- Pour l’authentification directe des informations d’identification Azure Data Lake Storage (ADLS), vous devez utiliser un jeton Microsoft Entra ID (anciennement Azure Active Directory). L’authentification directe des informations d’identification Microsoft Entra ID est prise en charge uniquement sur les clusters Standard exécutant Databricks Runtime 7.3 LTS et versions ultérieures, et n’est pas compatible avec l’authentification du principal de service.
- Pour plus d’informations sur l’authentification avec des jetons Microsoft Entra ID, consultez Authentification avec des jetons Microsoft Entra ID.
L’ID de votre cluster. Vous pouvez obtenir l’ID du cluster à partir de l’URL. Ici, l’ID du cluster est
1108-201635-xxxxxxxx. Consultez URL et ID du cluster.
ID d’organisation unique de votre espace de travail. Consultez Obtenir des identificateurs pour les objets d’espace de travail.
Le port auquel Databricks Connect se connecte sur votre cluster. Le port par défaut est
15001. Si votre cluster est configuré pour utiliser un autre port, tel que8787qui a été fourni dans les instructions précédentes pour Azure Databricks, utilisez le numéro de port configuré.
Configurez la connexion comme suit.
Vous pouvez utiliser l’interface CLI, des configurations SQL ou des variables d’environnement. L’ordre de priorité des méthodes de configuration de la plus élevée à la plus faible est : les clés de configuration SQL, l’interface CLI et les variables d’environnement.
INTERFACE DE LIGNE DE COMMANDE
Exécuter
databricks-connect.databricks-connect configureLa licence s’affiche :
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Acceptez la licence et fournissez les valeurs de configuration. Pour Databricks Host (Hôte Databricks) et Databricks Token (Jeton Databricks), entrez l’URL de l’espace de travail et le jeton d’accès personnel que vous avez noté à l’étape 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Si vous recevez un message indiquant que le jeton Microsoft Entra ID est trop long, vous pouvez laisser le champ Jeton Databricks vide et entrer manuellement le jeton dans
~/.databricks-connect.
Configurations SQL ou variables d’environnement. Le tableau suivant répertorie les clés de configuration SQL et les variables d’environnement qui correspondent aux propriétés de configuration que vous avez notées à l’étape 1. Pour définir une clé de configuration SQL, utilisez
sql("set config=value"). Par exemple :sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Paramètre Clé de configuration SQL Nom de variable d’environnement Databricks Host spark.databricks.service.address DATABRICKS_ADDRESS Databricks Token spark.databricks.service.token DATABRICKS_API_TOKEN ID du cluster spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Org ID spark.databricks.service.orgId DATABRICKS_ORG_ID Port spark.databricks.service.port DATABRICKS_PORT
Votre environnement virtuel étant toujours activé, testez la connectivité à Azure Databricks comme suit.
databricks-connect testSi le cluster que vous avez configuré n’est pas en cours d’exécution, le test démarre le cluster qui continue de s’exécuter jusqu’à son heure de résiliation automatique configurée. Le résultat doit être semblable à ce qui suit :
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiSi aucune erreur liée à la connexion n’est affichée (les messages
WARNsont corrects), vous avez réussi à vous connecter.
Utiliser Databricks Connect
La section explique comment configurer votre IDE ou serveur de notebooks préféré pour utiliser le client pour Databricks Connect.
Dans cette section :
- JupyterLab
- Jupyter Notebook classique
- PyCharm
- SparkR et RStudio Desktop
- sparklyr et RStudio Desktop
- IntelliJ (Scala ou Java)
- PyDev avec Eclipse
- Eclipse
- SBT
- Interpréteur de commandes Spark
JupyterLab
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec JupyterLab et Python, suivez ces instructions.
Pour installer JupyterLab, avec votre environnement virtuel Python activé, exécutez la commande suivante à partir de votre terminal ou invite de commandes :
pip3 install jupyterlabPour démarrer JupyterLab dans votre navigateur web, exécutez la commande suivante à partir de votre environnement virtuel Python activé :
jupyter labSi JupyterLab n’apparaît pas dans votre navigateur web, copiez l’URL qui commence par
localhostou127.0.0.1à partir de votre environnement virtuel, puis entrez-la dans la barre d’adresse de votre navigateur web.Créez un notebook dans JupyterLab, cliquez sur Fichier > Nouveau > Notebook dans le menu principal, sélectionnez Python 3 (ipykernel), puis cliquez sur Sélectionner.
Dans la première cellule du notebook, entrez l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins instancier une instance de
SparkSession.builder.getOrCreate(), comme indiqué dans l’exemple de code.Pour exécuter le notebook, cliquez sur Exécuter > Exécuter toutes les cellules.
Pour déboguer le notebook, cliquez sur l’icône de bogue (Activer le débogueur) à côté de Python 3 (ipykernel) dans la barre d’outils du notebook. Définissez un ou plusieurs points d’arrêt, puis cliquez sur Exécuter > Exécuter toutes les cellules.
Pour arrêter JupyterLab, cliquez sur Fichier > Arrêter. Si le processus JupyterLab est toujours en cours d’exécution dans votre terminal ou invite de commandes, arrêtez ce processus en appuyant sur
Ctrl + c, puis en entrantypour confirmer.
Pour obtenir des instructions de débogage plus spécifiques, consultez Débogueur.
Jupyter Notebook classique
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Le script de configuration pour Databricks Connect ajoute automatiquement le package à la configuration de votre projet. Pour bien démarrer avec un noyau Python, exécutez :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Afin d’activer le raccourci %sql pour l’exécution et la visualisation des requêtes SQL, utilisez l’extrait de code suivant :
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec Visual Studio Code, procédez comme suit :
Vérifiez que l’extension Python est installée.
Ouvrez la palette de commandes (Commande+Maj+P sur macOS et Ctrl+Maj+P sur Windows/Linux).
Sélectionnez un interpréteur Python. Accédez à Code > Preferences > Settings (Code > Préférences > Paramètres), puis choisissez Python settings (Paramètres Python).
Exécuter
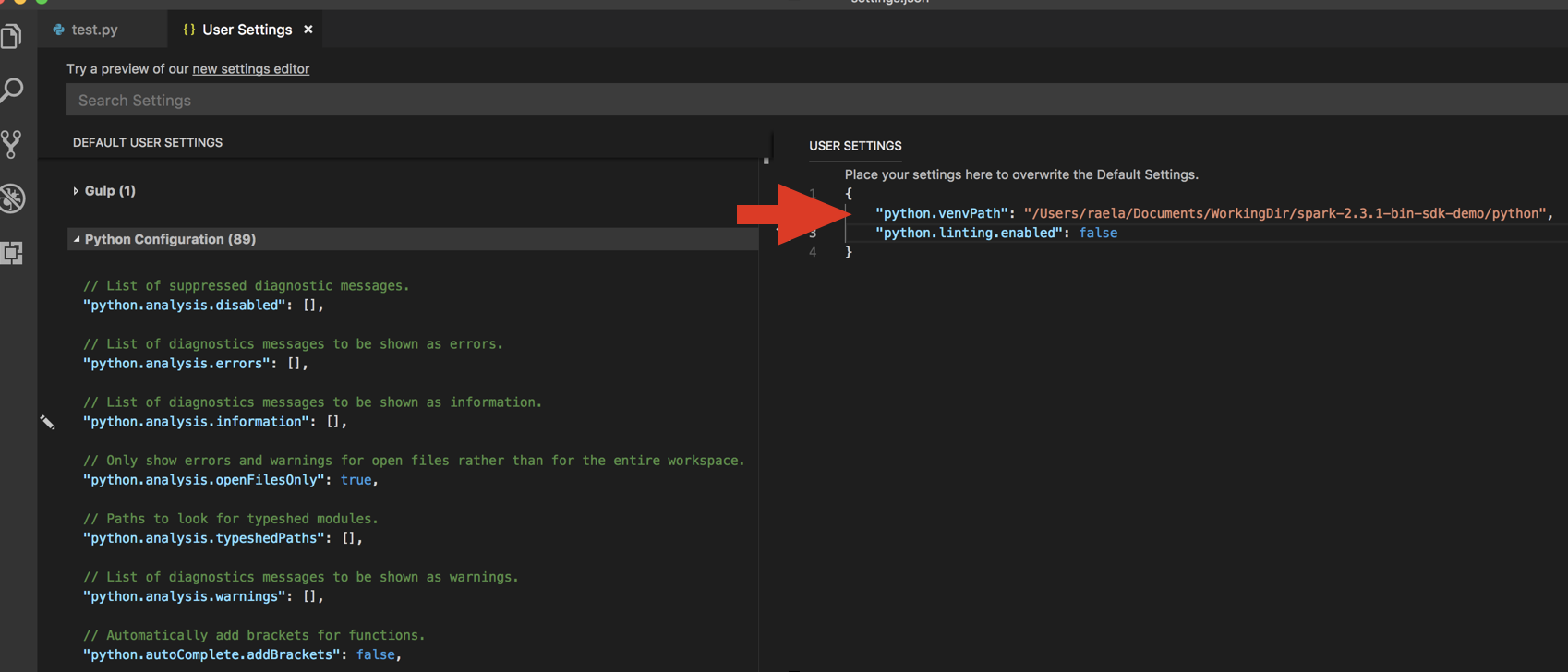
databricks-connect get-jar-dir.Ajoutez le répertoire retourné par la commande aux paramètres utilisateur JSON sous
python.venvPath. Cette valeur doit être ajoutée à la configuration Python.Désactivez le linter. Cliquez sur les points de suspension (...) situés à droite, puis modifiez les paramètres JSON. Les paramètres modifiés sont les suivants :
Si vous utilisez un environnement virtuel, ce qui est la méthode recommandée pour développer pour Python dans VS Code, dans la palette de commandes, tapez
select python interpreter, puis pointez vers votre environnement qui correspond à la version de Python de votre cluster.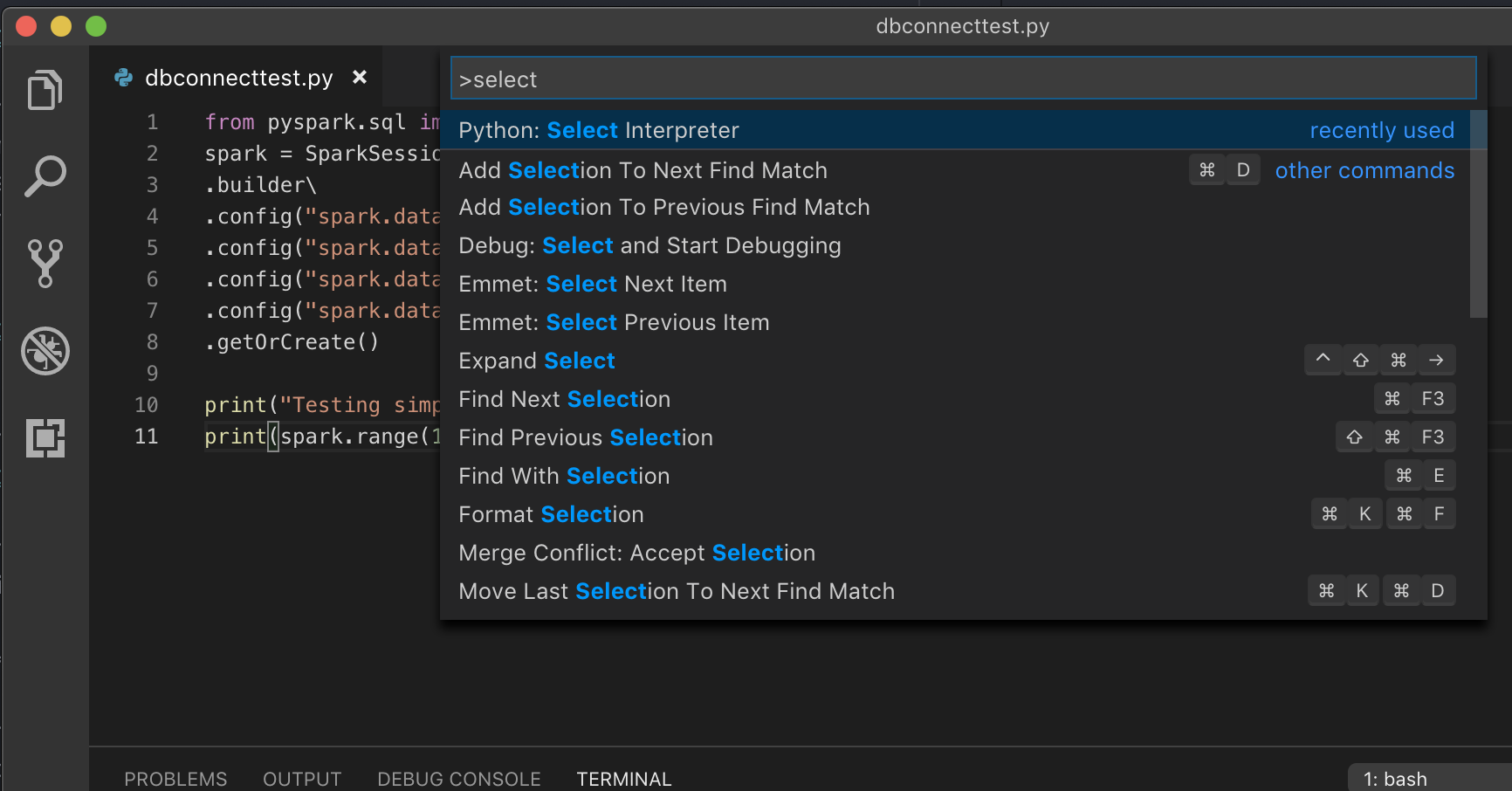
Par exemple, si votre cluster est Python 3.9, votre environnement de développement doit être Python 3.9.
PyCharm
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Le script de configuration pour Databricks Connect ajoute automatiquement le package à la configuration de votre projet.
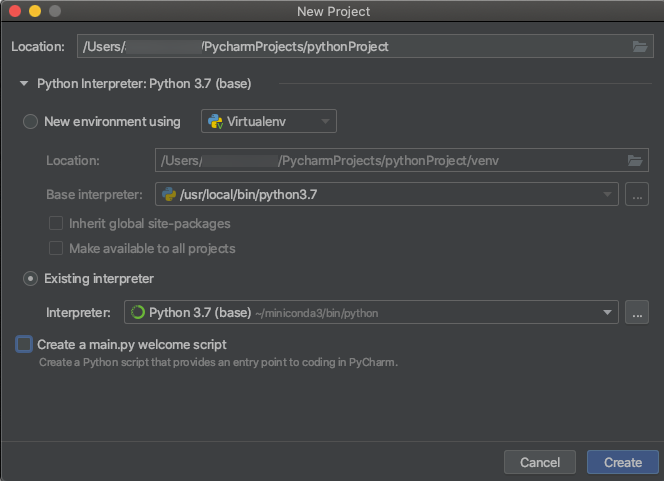
Clusters Python 3
Lorsque vous créez un projet PyCharm, sélectionnez Existing Interpreter (Interpréteur existant). Dans le menu déroulant, sélectionnez l’environnement Conda que vous avez créé (voir les Spécifications).
Accédez à Run (Exécuter) > Edit Configurations (Modifier les configurations).
Ajoutez
PYSPARK_PYTHON=python3en tant que variable d’environnement.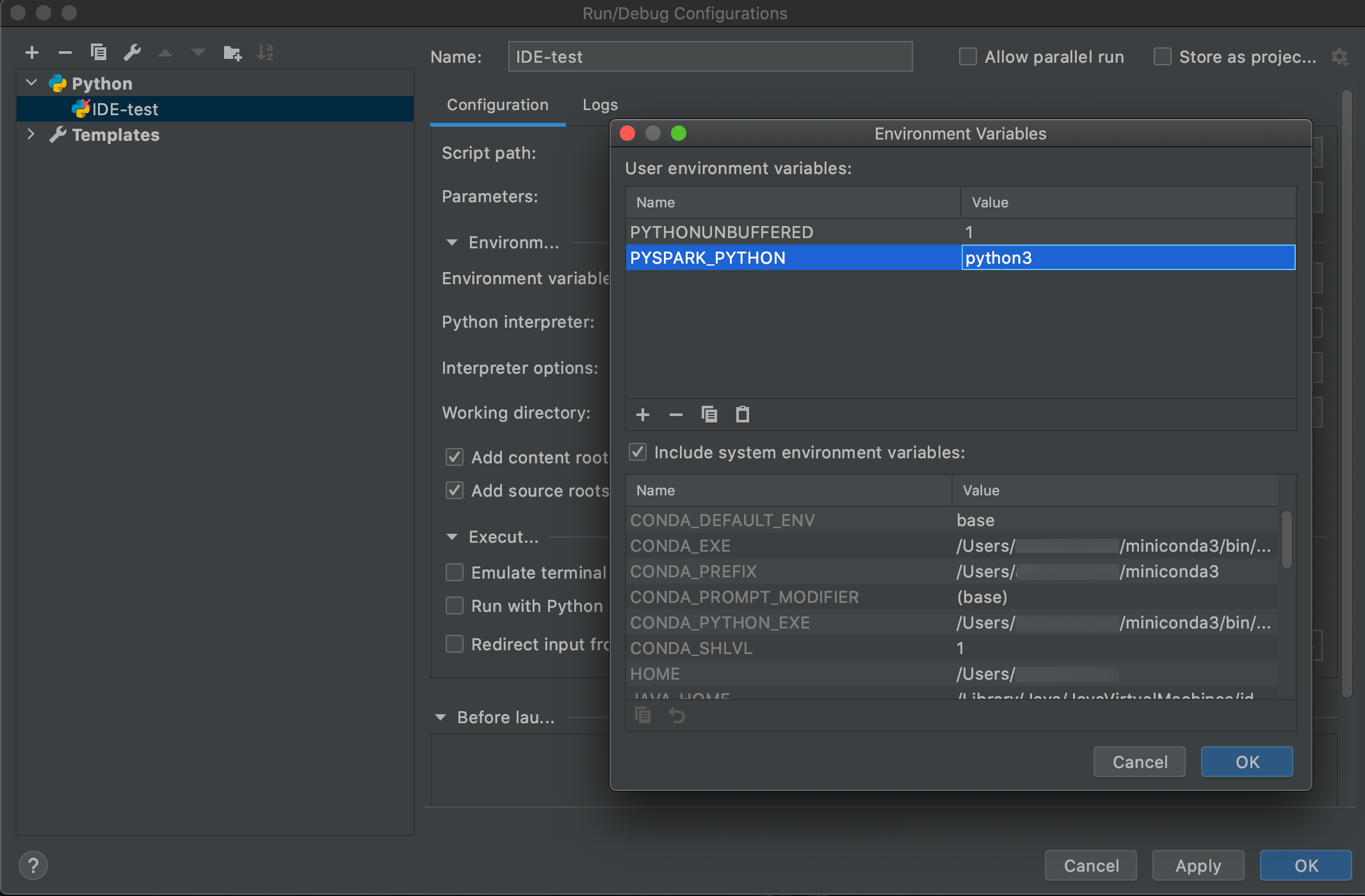
SparkR et RStudio Desktop
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec SparkR et RStudio Desktop, procédez comme suit :
Téléchargez et décompressez la distribution Spark open source sur votre ordinateur de développement. Choisissez la même version que celle de votre cluster Azure Databricks (Hadoop 2.7).
Exécuter
databricks-connect get-jar-dir. Cette commande retourne un chemin similaire à/usr/local/lib/python3.5/dist-packages/pyspark/jars. Copiez le chemin de fichier d’un répertoire situé au-dessus du chemin de fichier du répertoire JAR, par exemple/usr/local/lib/python3.5/dist-packages/pyspark, qui est le répertoireSPARK_HOME.Configurez le chemin de bibliothèque Spark et la page d’accueil Spark en les ajoutant en haut de votre script R. Définissez
<spark-lib-path>sur le répertoire dans lequel vous avez décompressé le package Spark open source à l’étape 1. Définissez<spark-home-path>sur le répertoire Databricks Connect de l’étape 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Lancez une session Spark et commencez à exécuter des commandes SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr et RStudio Desktop
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Important
Cette fonctionnalité est disponible en préversion publique.
Vous pouvez copier le code dépendant de sparklyr que vous avez développé localement à l’aide de Databricks Connect et l’exécuter dans un notebook Azure Databricks ou un serveur RStudio hébergé dans votre espace de travail Azure Databricks avec peu ou pas de modifications du code.
Dans cette section :
- Configuration requise
- Installer, configurer et utiliser sparklyr
- Ressources
- Limitations de sparklyr et de RStudio Desktop
Spécifications
- sparklyr 1.2 ou version ultérieure.
- Databricks Runtime 7.3 LTS ou version ultérieure avec la version correspondante de Databricks Connect.
Installer, configurer et utiliser sparklyr
Dans RStudio Desktop, installez sparklyr 1.2 ou une version ultérieure à partir de CRAN ou installez la dernière version maître à partir de GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Activez l’environnement Python avec la version correcte de Databricks Connect installée et exécutez la commande suivante dans le terminal pour obtenir le chemin
<spark-home-path>:databricks-connect get-spark-homeLancez une session Spark et commencez à exécuter des commandes sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countFermez la connexion.
spark_disconnect(sc)
Ressources
Pour plus d’informations, consultez le fichier LISEZ-MOI de sparklyr GitHub.
Pour obtenir des exemples de code, consultez sparklyr.
Limitations de sparklyr et de RStudio Desktop
Les fonctionnalités suivantes ne sont pas prises en charge :
- API de streaming sparklyr
- API ML sparklyr
- API boom
- Mode de sérialisation csv_file
- Envoi Spark
IntelliJ (Scala ou Java)
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec IntelliJ (Scala ou Java), procédez comme suit :
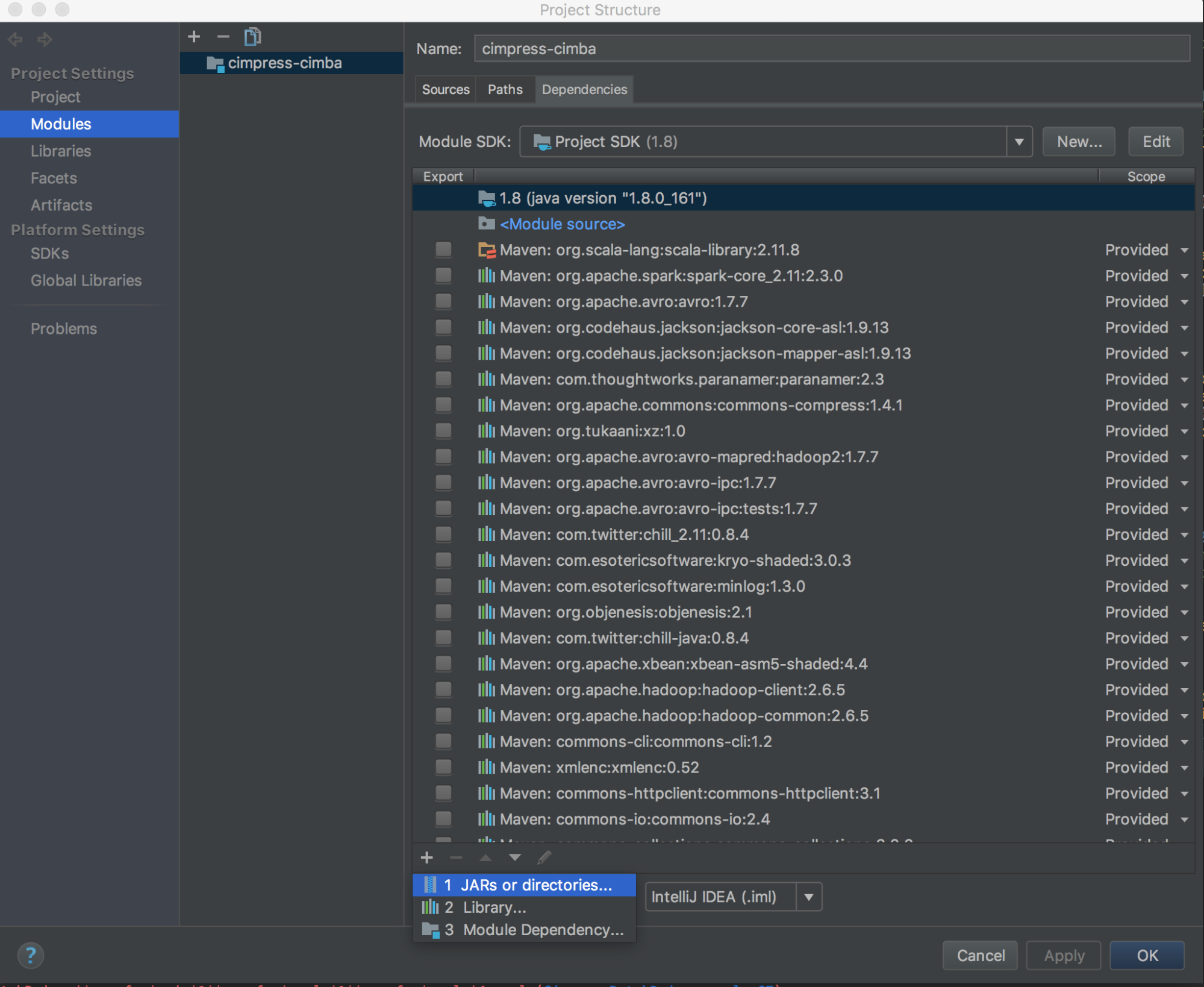
Exécuter
databricks-connect get-jar-dir.Pointez les dépendances vers le répertoire retourné par la commande. Accédez à File (Fichier) > Project Settings (Paramètres du projet) > Modules > Dependencies (Dépendances) > signe « + » > JARs or Directories (Fichiers JAR ou répertoires).
Pour éviter les conflits, nous vous recommandons vivement de supprimer toutes les autres installations Spark de votre classpath. Si ce n’est pas possible, vérifiez que les fichiers JAR que vous ajoutez se trouvent au début du classpath. En particulier, ils doivent se trouver devant toute les autres versions installées de Spark (sinon, vous allez soit utiliser l’une de ces autres versions Spark et l’exécuter localement, soit générer un
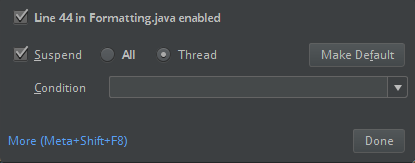
ClassDefNotFoundError).Vérifiez le paramètre de l’option de répartition dans IntelliJ. La valeur par défaut est All (Tous) et entraîne des délais d’expiration réseau si vous définissez des points d’arrêt pour le débogage. Affectez-lui la valeur Thread pour éviter d’arrêter les threads de réseau en arrière-plan.
PyDev avec Eclipse
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect et PyDev avec Eclipse, suivez ces instructions.
- Démarrez Eclipse.
- Créez un projet : cliquez sur Fichier > Nouveau > Projet > PyDev > Projet PyDev, puis cliquez sur Suivant.
- Spécifiez un nom de projet.
- Pour Contenu du projet, spécifiez le chemin d’accès à votre environnement virtuel Python.
- Cliquez sur Veuillez configurer un interpréteur avant de procéder.
- Cliquez sur Configuration manuelle.
- Cliquez sur Nouveau > Rechercher python/pypy exe.
- Recherchez et sélectionnez le chemin d’accès complet de l’Interpréteur Python qui est référencé dans l’environnement virtuel, puis cliquez sur Ouvrir.
- Dans la boîte de dialogue Sélectionner un interpréteur, cliquez sur OK.
- Dans la boîte de dialogue Sélection nécessaire, cliquez sur OK.
- Dans la boîte de dialogue Préférences, cliquez sur Appliquer et Fermer.
- Dans la boîte de dialogue Projet PyDev, cliquez sur Terminer.
- Cliquez sur Ouvrir la perspective.
- Ajoutez au projet un fichier de code Python (
.py) qui contient l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins instancier une instance deSparkSession.builder.getOrCreate(), comme indiqué dans l’exemple de code. - Une fois le fichier de code Python ouvert, définissez tous les points d’arrêt où vous voulez que votre code fasse une pause pendant l’exécution.
- Cliquez sur Exécuter > Exécuter ou Exécuter > Déboguer.
Pour obtenir des instructions d’exécution et de débogage plus spécifiques, consultez la section Exécution d’un programme.
Eclipse
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect et Eclipse, procédez comme suit :
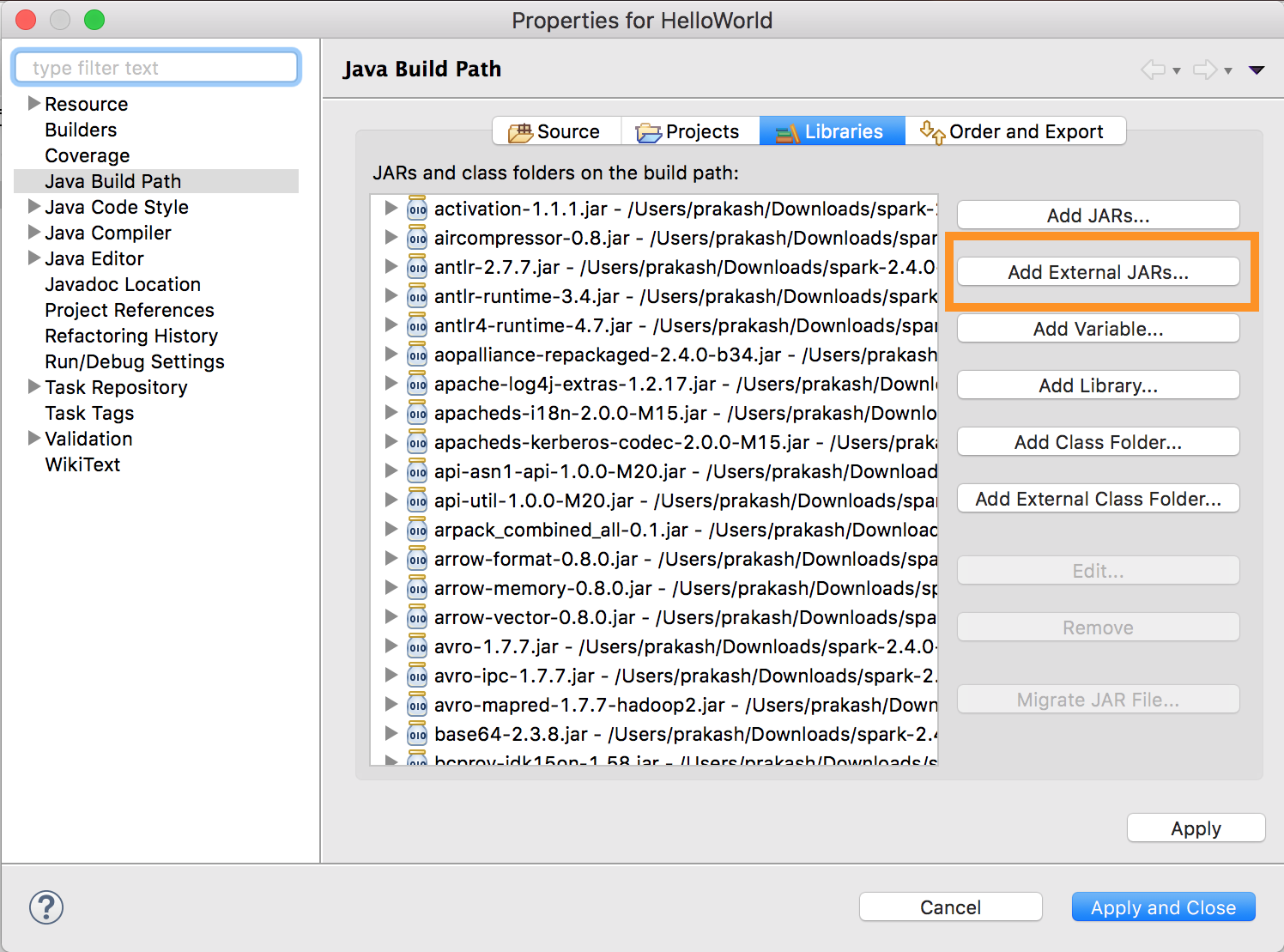
Exécuter
databricks-connect get-jar-dir.Pointez la configuration des fichiers JAR externes vers le répertoire retourné par la commande. Accédez au menu Project > Properties > Java Build Path > Libraries > Add External Jars (menu Projet > Propriétés > Chemin de build Java > Ajouter des fichiers JAR externes).
Pour éviter les conflits, nous vous recommandons vivement de supprimer toutes les autres installations Spark de votre classpath. Si ce n’est pas possible, vérifiez que les fichiers JAR que vous ajoutez se trouvent au début du classpath. En particulier, ils doivent se trouver devant toute les autres versions installées de Spark (sinon, vous allez soit utiliser l’une de ces autres versions Spark et l’exécuter localement, soit générer un
ClassDefNotFoundError).
SBT
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect, vous devez configurer votre fichier build.sbt pour établir un lien avec les fichiers JAR Databricks Connect plutôt que la dépendance de bibliothèque Spark habituelle. Pour ce faire, utilisez la directive unmanagedBase dans l’exemple de fichier de build suivant, qui suppose une application Scala ayant un objet principal com.example.Test :
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Interpréteur de commandes Spark
Remarque
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Si vous voulez utiliser Databricks Connect avec l’interpréteur de commandes Spark, Python ou Scala, suivez ces instructions.
Une fois votre environnement virtuel activé, assurez-vous que la commande
databricks-connect tests’est correctement exécutée dans Configurer le client.Une fois votre environnement virtuel activé, démarrez l’interpréteur de commandes Spark. Pour Python, exécutez la commande
pyspark. Pour Scala, exécutez la commandespark-shell.# For Python: pyspark# For Scala: spark-shellL’interpréteur de commandes Spark s’affiche, par exemple pour Python :
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Pour Scala :
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Pour plus d’informations sur l’utilisation de l’interpréteur de commandes Spark avec Python ou Scala pour exécuter les commandes sur votre cluster, consultez Analyse interactive avec l’interpréteur de commandes Spark.
Utilisez la variable
sparkintégrée pour représenterSparkSessionsur votre cluster en cours d’exécution, par exemple :>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPour Scala :
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPour arrêter l’interpréteur de commandes Spark, appuyez sur
Ctrl + douCtrl + z, ou exécutez la commandequit()ouexit()pour Python ou:qou:quitpour Scala.
Exemples de codes
Cet exemple de code simple interroge la table spécifiée, puis affiche les 5 premières lignes de la table spécifiée. Pour utiliser une autre table, ajustez l’appel sur spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Cet exemple de code plus long effectue les opérations suivantes :
- Crée un DataFrame en mémoire.
- Crée une table portant le nom
zzz_demo_temps_tabledans le schémadefault. Si la table portant ce nom existe déjà, la table est d’abord supprimée. Pour utiliser un autre schéma ou table, ajustez les appels surspark.sql,temps.write.saveAsTableou les deux. - Enregistre le contenu du DataFrame dans la table.
- Exécute une requête
SELECTsur le contenu de la table. - Affiche le résultat de la requête.
- Supprime la table.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Utiliser des dépendances
En général, votre classe principale ou votre fichier Python comprend d’autres fichiers et fichiers JAR de dépendance. Vous pouvez ajouter ces fichiers et fichiers JAR de dépendance en appelant sparkContext.addJar("path-to-the-jar") ou sparkContext.addPyFile("path-to-the-file"). Vous pouvez également ajouter des fichiers Egg et des fichiers Zip avec l’interface addPyFile(). Chaque fois que vous exécutez le code dans votre environnement IDE, les fichiers et fichiers JAR de dépendance sont installés sur le cluster.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + fonctions définies par l’utilisateur Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Accéder aux utilitaires Databricks
Cette section explique comment utiliser Databricks Connect pour accéder aux Utilitaires Databricks.
Vous pouvez utiliser les utilitaires dbutils.fs et dbutils.secrets du module de référence Databricks Utilities (dbutils).
Les commandes prises en charge sont dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
Consultez Utilitaire de système de fichiers (dbutils.fs) ou exécutez dbutils.fs.help(), et Utilitaire Secrets (dbutils.secrets) ou exécutez dbutils.secrets.help().
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Lors de l’utilisation de Databricks Runtime 7.3 LTS ou version ultérieure, pour accéder au module DBUtils d’une manière qui fonctionne à la fois localement et dans les clusters Azure Databricks, utilisez la commande get_dbutils() suivante :
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Sinon, utilisez la commande get_dbutils() suivante :
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Copie de fichiers entre des systèmes de fichiers locaux et distants
Vous pouvez utiliser dbutils.fs pour copier des fichiers entre vos systèmes de fichiers clients et distants. Le schéma file:/ fait référence au système de fichiers local sur le client.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
La taille de fichier maximale qui peut être transférée de cette façon est de 250 Mo.
Activez dbutils.secrets.get
En raison des restrictions de sécurité, la possibilité d’appeler dbutils.secrets.get est désactivée par défaut. Contactez le support technique Azure Databricks pour activer cette fonctionnalité pour votre espace de travail.
Définir des configurations Hadoop
Sur le client, vous pouvez définir des configurations Hadoop à l’aide de l’API spark.conf.set, qui s’applique aux opérations SQL et DataFrame. Les configurations Hadoop définies sur sparkContext doivent être définies dans la configuration du cluster ou à l’aide d’un notebook. Cela est dû au fait que les configurations définies sur sparkContext ne sont pas liées aux sessions utilisateur, mais s’appliquent à l’ensemble du cluster.
Dépannage
Exécutez databricks-connect test pour vérifier les problèmes de connectivité. Cette section décrit certains problèmes courants que vous pouvez rencontrer avec Databricks Connect et comment les résoudre.
Dans cette section :
- Non-concordance des versions Python
- Serveur non activé
- Installations PySpark en conflit
- En conflit
SPARK_HOME - Entrée
PATHmanquante ou en conflit pour les fichiers binaires - Paramètres de sérialisation en conflit sur le cluster
- Impossible de trouver
winutils.exesur Windows - La syntaxe du nom de fichier, du nom de répertoire ou de l’étiquette de volume est incorrecte sur Windows
Non-concordance de la version Python
Vérifiez que la version de Python que vous utilisez localement a au moins la même version mineure que la version sur le cluster (par exemple, 3.9.16 avec 3.9.15 est OK ; 3.9 avec 3.8 ne l’est pas).
Si plusieurs versions de Python sont installées localement, assurez-vous que Databricks Connect utilise la version appropriée en définissant la variable d’environnement PYSPARK_PYTHON (par exemple, PYSPARK_PYTHON=python3).
Serveur non activé
Vérifiez que le serveur Spark est activé sur le cluster avec spark.databricks.service.server.enabled true. Les lignes suivantes doivent s’afficher dans le journal des pilotes le cas échéant :
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Installations PySpark en conflit
Le package databricks-connect est en conflit avec PySpark. Si les deux sont installés, des erreurs se produisent lors de l’initialisation du contexte Spark dans Python. Cela peut se manifester de plusieurs façons, notamment des erreurs de « flux endommagé » ou de « classe introuvable ». Si PySpark est installé dans votre environnement Python, assurez-vous qu’il est désinstallé avant d’installer databricks-connect. Après la désinstallation de PySpark, veillez à réinstaller entièrement le package Databricks Connect :
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
SPARK_HOME en conflit
Si vous avez préalablement utilisé Spark sur votre ordinateur, votre environnement IDE peut être configuré pour utiliser l’une de ces autres versions de Spark plutôt que Databricks Connect Spark. Cela peut se manifester de plusieurs façons, notamment des erreurs de « flux endommagé » ou de « classe introuvable ». Vous pouvez voir la version de Spark utilisée en vérifiant la valeur de la variable d’environnement SPARK_HOME :
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Résolution
Si SPARK_HOME est défini sur une version de Spark autre que celle du client, vous devez annuler la définition de la variable SPARK_HOME et réessayer.
Vérifiez les paramètres de variables d’environnement de votre environnement IDE, votre fichier .bashrc, .zshrc ou .bash_profile, et tous les autres emplacements où des variables d’environnement peuvent être définies. Vous devrez probablement quitter et redémarrer votre environnement IDE pour vider l’ancien état, et vous devrez peut-être même créer un nouveau projet si le problème persiste.
Vous n’avez pas besoin de définir SPARK_HOME sur une nouvelle valeur ; son annulation doit être suffisante.
PATH manquante ou en conflit pour les fichiers binaires
Il est possible que votre valeur de chemin PATH soit configurée de sorte que les commandes comme spark-shell exécutent d’autres fichiers binaires précédemment installés plutôt que celui fourni avec Databricks Connect. Cela peut provoquer l’échec de databricks-connect test. Vous devez vous assurer que les fichiers binaires Databricks Connect sont prioritaires, ou supprimer ceux installés précédemment.
Si vous ne pouvez pas exécuter de commandes telles que spark-shell, il est également possible que votre chemin PATH n’ait pas été automatiquement configuré par pip3 install et que vous deviez ajouter manuellement le répertoire d’installation bin à votre chemin PATH. Il est possible d’utiliser Databricks Connect avec des IDE, même si cela n’est pas configuré. Toutefois, la commande databricks-connect test ne fonctionnera pas.
Paramètres de sérialisation en conflit sur le cluster
Si des erreurs de « flux endommagé » s’affichent lors de l’exécution de databricks-connect test, cela peut être dû à des configurations de sérialisation de cluster incompatibles. Par exemple, la définition de la configuration de spark.io.compression.codec peut être à l’origine de ce problème. Pour résoudre ce problème, envisagez de supprimer ces configurations des paramètres du cluster ou de définir la configuration dans le client Databricks Connect.
Impossible de trouverwinutils.exe sur Windows
Si vous utilisez Databricks Connect sur Windows et que vous voyez :
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
suivez les instructions permettant de configurer le chemin de Hadoop sur Windows.
La syntaxe du nom de fichier, du nom de répertoire ou du nom de volume est incorrecte sur Windows
Si vous utilisez Databricks Connect sur Windows et que vous voyez :
The filename, directory name, or volume label syntax is incorrect.
Java ou Databricks Connect a été installé dans un répertoire comportant un espace dans votre chemin. Vous pouvez contourner ce contournement en installant dans un chemin de répertoire sans espaces, ou en configurant votre chemin à l’aide de la forme de nom abrégée.
Authentification avec des jetons Microsoft Entra ID
Remarque
Les informations suivantes s’appliquent uniquement aux versions 7.3.5 à 12.2.x de Databricks Connect.
Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures ne prend pas en charge les jetons Microsoft Entra ID.
Quand vous utilisez Databricks Connect versions 7.3.5 à 12.2.x, vous pouvez vous authentifier avec un jeton Microsoft Entra ID au lieu d’un jeton d’accès personnel. Les jetons Microsoft Entra ID ont une durée de vie limitée. Quand le jeton Microsoft Entra ID expire, Databricks Connect échoue avec une erreur Invalid Token.
Pour Databricks Connect versions 7.3.5 à 12.2.x, vous pouvez fournir le jeton Microsoft Entra ID dans votre application Databricks Connect en cours d’exécution. Votre application doit obtenir le nouveau jeton d’accès et le définir sur la clé de configuration SQL spark.databricks.service.token.
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Une fois que vous avez mis à jour le jeton, l’application peut continuer à utiliser la même session SparkSession et tous les objets et états créés dans le contexte de la session. Pour éviter les erreurs intermittentes, Databricks vous recommande de fournir un nouveau jeton avant l’expiration de l’ancien jeton.
Vous pouvez étendre la durée de vie du jeton Microsoft Entra ID pour le rendre persistant pendant l’exécution de votre application. Pour ce faire, attachez un TokenLifetimePolicy avec une durée de vie suffisamment longue à l’application d’autorisation Microsoft Entra ID que vous avez utilisée pour acquérir le jeton d’accès.
Remarque
L’authentification directe Microsoft Entra ID utilise deux jetons : le jeton d’accès Microsoft Entra ID décrit précédemment que vous configurez dans Databricks Connect versions 7.3.5 à 12.2.x, et le jeton d’authentification directe ADLS pour la ressource spécifique que génère Databricks quand il traite la demande. Vous ne pouvez pas étendre la durée de vie des jetons d’authentification directe ADLS en utilisant les stratégies de durée de vie des jetons Microsoft Entra ID. Si vous envoyez une commande au cluster qui prend plus d’une heure, l’opération échoue si la commande accède à une ressource ADLS après la marque d’une heure.
Limites
Structured Streaming.
Exécution de code arbitraire qui ne fait pas partie d’un travail Spark sur le cluster distant.
Les API Scala, Python et R natives pour les opérations de table Delta (par exemple,
DeltaTable.forPath) ne sont pas prises en charge. Toutefois, l’API SQL (spark.sql(...)) avec les opérations Delta Lake et l’API Spark (par exemple,spark.read.load) sur les tables Delta sont toutes les deux prises en charge.Copier dans.
À l’aide de fonctions SQL, d’UDF Python ou Scala qui font partie du catalogue du serveur. Toutefois, les UDF Scala et Python introduites localement fonctionnent.
Apache Zeppelin 0.7.x et versions antérieures.
Connexion aux clusters avec le contrôle d’accès aux tables.
Connexion aux clusters avec l’isolation des processus activée (en d’autres termes, où
spark.databricks.pyspark.enableProcessIsolationa la valeurtrue).Commande SQL
CLONEDelta.Vues temporaires globales.
Koalas et
pyspark.pandas.Les commandes SQL
CREATE TABLE table AS SELECT ...ne fonctionnent pas toujours. Utilisez plutôtspark.sql("SELECT ...").write.saveAsTable("table").L’authentification directe des informations d’identification Microsoft Entra ID est prise en charge uniquement sur les clusters standard exécutant Databricks Runtime 7.3 LTS et versions ultérieures, et n’est pas compatible avec l’authentification du principal de service.
La référence suivante des utilitaires Databricks (dbutils) :