Qu’est-ce que Databricks Connect ?
Remarque
Cet article traite de Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures.
Pour plus d’informations sur la version héritée de Databricks Connect, consultez Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures.
- Pour ignorer cet article et commencer à utiliser Databricks Connect pour Python immédiatement, consultez Databricks Connect pour Python.
- Pour ignorer cet article et commencer à utiliser Databricks Connect pour R immédiatement, consultez Databricks Connect pour R.
- Pour ignorer cet article et commencer à utiliser Databricks Connect pour Scala immédiatement, consultez Databricks Connect pour Scala.
Vue d’ensemble
Databricks Connect vous permet de connecter des IDE populaires tels que Visual Studio Code, PyCharm, RStudio Desktop et IntelliJ IDEA ainsi que des serveurs de notebooks et d’autres applications personnalisées aux clusters Azure Databricks. Cet article explique le fonctionnement de Databricks Connect.
Databricks Connect est une bibliothèque de client pour Databricks Runtime. Cela vous permet d’écrire du code à l’aide d’API Spark et de l’exécuter à distance sur un cluster Azure Databricks plutôt que dans la session Spark locale.
Par exemple, lorsque vous exécutez la commande DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() à l’aide de Databricks Connect, la représentation logique de la commande est envoyée au serveur Spark s’exécutant dans Azure Databricks pour une exécution sur le cluster distant.
Avec Databricks Connect, vous pouvez :
Exécuter du code Spark à grande échelle à partir de n’importe quelle application Python, R ou Scala. Partout où vous pouvez utiliser
import pysparkpour Python oulibrary(sparklyr)pour R ouimport org.apache.sparkpour Scala, vous pouvez désormais exécuter du code Spark directement à partir de votre application, sans avoir à installer de plug-ins d’IDE ni à utiliser de scripts d’envoi Spark.Remarque
Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures prend en charge l’exécution des applications Python. R et Scala sont pris en charge uniquement dans Databricks Connect pour Databricks Runtime 13.3 LTS et versions ultérieures.
Effectuer un pas à pas détaillé et déboguer du code dans votre IDE même lorsque vous travaillez avec un cluster distant.
Effectuer des itérations rapides lors du développement de bibliothèques. Vous n’avez pas besoin de redémarrer le cluster après avoir changé les dépendances de bibliothèque Python ou Scala dans Databricks Connect, car chaque session cliente est isolée des autres dans le cluster.
Arrêter les clusters inactifs sans perdre votre travail. Étant donné que l’application cliente est dissociée du cluster, elle n’est pas affectée par les redémarrages ou les mises à niveau du cluster, ce qui entraîne normalement la perte de l’ensemble des variables, jeux de données distribués résilients (RDD) et objets DataFrame définis dans un notebook.
Pour Databricks Runtime 13.3 LTS et versions ultérieures, Databricks Connect repose désormais sur l’application open source Spark Connect. Spark Connect introduit une architecture client-serveur découplée pour Apache Spark qui permet la connectivité à distance aux clusters Spark à l’aide de l’API DataFrame et de plans logiques non résolus comme protocole. Avec cette architecture « V2 » basée sur Spark Connect, Databricks Connect devient un client léger simple et facile à utiliser. Spark Connect peut être incorporé partout pour se connecter à Azure Databricks : dans les IDE, les notebooks et les applications, ce qui permet aux utilisateurs et aux partenaires de créer individuellement de nouvelles expériences utilisateur (interactives) basées sur la plateforme Databricks. Pour plus d’informations sur Spark Connect, consultez la page Présentation de Spark Connect.
Databricks Connect détermine où votre code s'exécute et débogue, comme illustré dans la figure suivante.
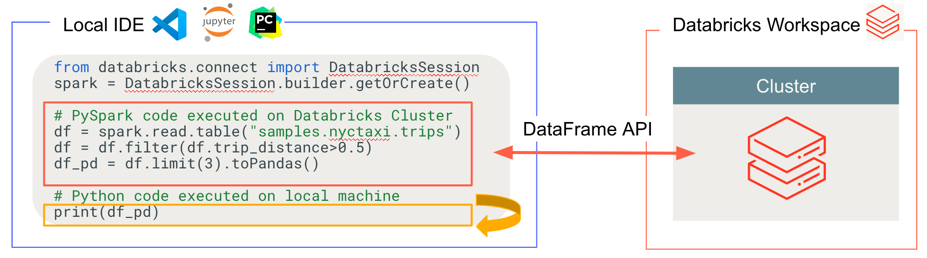
Pour l’exécution du code : tout le code s’exécute localement, tandis que tout le code impliquant des opérations DataFrame s’exécute sur le cluster dans l’espace de travail Azure Databricks distant et les réponses d’exécution sont renvoyées à l’appelant local.
Pour le débogage du code : tout le code est débogué localement, tandis que tout le code Spark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
Étapes suivantes
- Pour commencer à développer des solutions Databricks Connect avec Python, commencez par le tutoriel Databricks Connect pour Python.
- Pour commencer à développer des solutions Databricks Connect avec R, commencez par le tutoriel Databricks Connect pour R.
- Pour commencer à développer des solutions Databricks Connect avec Scala, commencez par le tutoriel Databricks Connect pour Scala.