Référence Databricks Connect
Notes
Cet article concerne Databricks Connect pour Databricks Runtime 13.0 et ses versions ultérieures.
Pour savoir comment démarrer rapidement avec Databricks Connect pour Databricks Runtime 13,0 et versions ultérieures, consultez Databricks Connect.
Pour plus d’informations sur Databricks Connect pour les versions antérieures de Databricks Runtime, consultez Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures.
Databricks Connect vous permet de connecter des IDE populaires tels que Visual Studio Code et PyCharm, des serveurs de notebooks et d’autres applications personnalisées à des clusters Azure Databricks.
Cet article explique le fonctionnement de Databricks Connect, vous guide tout au long des étapes de prise en main de Databricks Connect et explique comment résoudre les problèmes qui peuvent se produire lors de l’utilisation de Databricks Connect.
Vue d’ensemble
Databricks Connect est une bibliothèque de client pour Databricks Runtime. Elle vous permet d’écrire des travaux à l’aide d’API Spark et de les exécuter à distance sur un cluster Azure Databricks plutôt que dans la session Spark locale.
Par exemple, lorsque vous exécutez la commande DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() à l’aide de Databricks Connect, la représentation logique de la commande est envoyée au serveur Spark s’exécutant dans Azure Databricks pour une exécution sur le cluster distant.
Avec Databricks Connect, vous pouvez :
Exécuter des travaux Spark à grande échelle à partir de n’importe quelle application Python. Partout où vous pouvez effectuer des opérations
import pyspark, vous pouvez maintenant exécuter des travaux Spark directement à partir de votre application, sans avoir à installer de plug-ins IDE ou à utiliser des scripts d’envoi Spark.Notes
Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures prend actuellement en charge l’exécution uniquement d’applications Python.
Effectuer un pas à pas détaillé et déboguer du code dans votre IDE même lorsque vous travaillez avec un cluster distant.
Effectuer des itérations rapides lors du développement de bibliothèques. Vous n’avez pas besoin de redémarrer le cluster après avoir modifié les dépendances de bibliothèque Python dans Databricks Connect, car chaque session client est isolée des autres dans le cluster.
Arrêter les clusters inactifs sans perdre votre travail. Étant donné que l’application cliente est dissociée du cluster, elle n’est pas affectée par les redémarrages ou les mises à niveau du cluster, ce qui entraîne normalement la perte de l’ensemble des variables, jeux de données distribués résilients (RDD) et objets DataFrame définis dans un notebook.
Pour Databricks Runtime 13.0 et versions ultérieures, Databricks Connect est désormais basé sur Spark Connect open source. Spark Connect introduit une architecture client-serveur découplée pour Apache Spark qui permet la connectivité à distance aux clusters Spark à l’aide de l’API DataFrame et de plans logiques non résolus comme protocole. Avec cette architecture « V2 » basée sur Spark Connect, Databricks Connect devient un client léger simple et facile à utiliser. Spark Connect peut être incorporé partout pour se connecter à Azure Databricks : dans les IDE, les notebooks et les applications, ce qui permet aux utilisateurs individuels et aux partenaires de créer de nouvelles expériences utilisateur (interactives) basées sur Databricks Lakehouse. Pour plus d’informations sur Spark Connect, consultez la page Présentation de Spark Connect.
Databricks Connect détermine où votre code s'exécute et débogue, comme illustré dans la figure suivante.
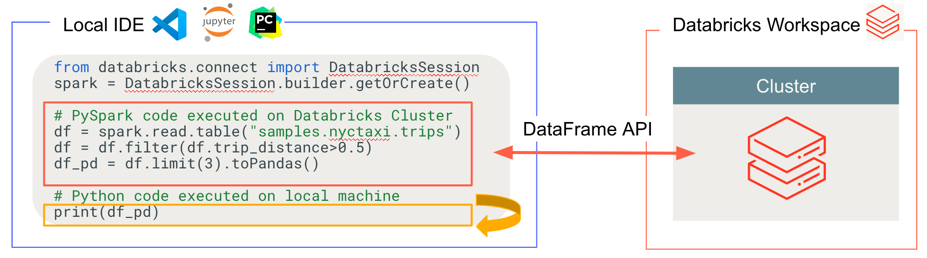
- Pour l'exécution du code : tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
- Pour le code de débogage : tout Python est débogué localement, tandis que tout le code PySpark continue de s'exécuter sur le cluster dans l'espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
Spécifications
Cette section répertorie les spécifications pour Databricks Connect.
Un espace de travail Azure Databricks et son compte correspondant activés pour Unity Catalog. Consultez la page Prise en main d’Unity Catalog et Activer un espace de travail pour Unity Catalog.
Un cluster sur lequel Databricks Runtime 13.0 ou une version ultérieure est installé.
Seuls les clusters compatibles avec Unity Catalog sont pris en charge. Ceux-ci incluent des clusters avec des modes d'accès attribués ou partagés. Voir Modes d'accès.
Vous devez installer Python 3 sur votre machine de développement et la version mineure de votre installation cliente de Python doit être identique à la version Python mineure de votre cluster Azure Databricks. La table suivante indique la version de Python installée avec chaque version de Databricks Runtime.
Version de Databricks Runtime Version Python 13.2 ML, 13.2 3.10 13.1 ML, 13.1 3.10 13.0 ML, 13.0 3.10 Notes
Si vous souhaitez utiliser les UDF PySpark, il est important que la version mineure de Python installée par votre machine de développement corresponde à la version mineure de Python installée sur le cluster et incluse avec Databricks Runtime.
Databricks recommande vivement d’avoir un environnement virtuel Python activé pour chaque projet de code Python que vous utilisez avec Databricks Connect. Les environnements virtuels Python garantissent que vous utilisez les bonnes versions de Python et Databricks Connect ensemble. Cela peut aider à diminuer ou raccourcir la résolution des problèmes techniques associés.
Par exemple, si vous utilisez venv sur votre ordinateur de développement et que votre cluster exécute Python 3.10, vous devez créer un environnement
venvavec cette version. L’exemple de commande suivant génère les scripts pour activer un environnementvenvavec Python 3.10, puis cette commande place ces scripts dans un dossier masqué nommé.venvdans le répertoire de travail actuel :# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venvAfin d’utiliser ces scripts pour activer cet environnement
venv, consultez la page Fonctionnement des venvs.La version de package majeure et mineure de Databricks Connect doit toujours correspondre à votre version de Databricks Runtime. Databricks vous recommande de toujours utiliser le package le plus récent de Databricks Connect qui correspond à votre version de Databricks Runtime. Par exemple, lorsque vous utilisez un cluster Databricks Runtime 13.1, vous devriez aussi utiliser le package
databricks-connect==13.1.*.Notes
Consultez les notes de publication de Databricks Connect pour obtenir la liste des versions et des mises à jour de maintenance de Databricks Connect.
Il n’est pas obligatoire d’utiliser le package Databricks Connect le plus récent qui correspond à votre version de Databricks Runtime. À compter de Databricks Runtime 13.0, vous pouvez utiliser le package Databricks Connect sur toutes les versions de Databricks Runtime au niveau de la version du package Databricks Connect, ou ultérieure à celle-ci. Toutefois, si vous souhaitez utiliser les fonctionnalités disponibles dans les versions ultérieures de Databricks Runtime, vous devez mettre à niveau le package Databricks Connect en conséquence.
Configurer le client
Effectuez les étapes suivantes pour configurer le client local pour Databricks Connect.
Notes
Avant de commencer à utiliser le client Databricks Connect local, vous devez respecter les exigences pour Databricks Connect.
Conseil
Si vous avez déjà installé l’extension Databricks pour Visual Studio Code, vous n’avez pas besoin de suivre ces instructions d’installation.
L’extension Databricks pour Visual Studio Code intègre déjà la prise en charge de Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures. Passez à la section Exécuter ou déboguer du code Python avec Databricks Connect dans la documentation de l’extension Databricks pour Visual Studio Code.
Étape 1 : Installer le client Databricks Connect
Une fois votre environnement virtuel activé, désinstallez PySpark, s’il est déjà installé, en exécutant la commande
uninstall. Cela est nécessaire car le packagedatabricks-connectest en conflit avec PySpark. Pour plus d’informations, consultez Installations PySpark en conflit. Pour vérifier si PySpark est déjà installé, exécutez la commandeshow.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkVotre environnement virtuel étant toujours activé, installez le client Databricks Connect en exécutant la commande
install. Utilisez l’option--upgradepour mettre à niveau toute installation de client existante vers la version spécifiée.pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Notes
Databricks vous recommande d’ajouter la notation « point-astérisque » pour spécifier
databricks-connect==X.Y.*au lieu dedatabricks-connect=X.Yet vous assurer que le package le plus récent est installé. Bien qu’il ne s’agit pas d’une exigence, cela vous permet de vous assurer que vous pouvez utiliser les dernières fonctionnalités prises en charge pour ce cluster.
Étape 2 : Configurer les propriétés de connexion
Dans cette section, vous allez configurer des propriétés pour établir une connexion entre Databricks Connect et votre cluster Azure Databricks distant. Ces propriétés comprennent des paramètres permettant d’authentifier Databricks Connect avec votre cluster.
À compter de Databricks Connect pour Databricks Runtime 13.1 et ses versions ultérieures, Databricks Connect intègre le Kit de développement logiciel (SDK) Databricks pour Python. Ce SDK implémente la norme d’authentification unifiée du client Databricks, une approche architecturale et programmatique consolidée et cohérente pour l’authentification. Cette approche permet de configurer et d’automatiser l’authentification avec Azure Databricks de façon plus centralisée et prévisible. Elle vous permet de configurer une seule fois l’authentification Azure Databricks, puis d’utiliser cette configuration sur plusieurs outils Azure Databricks et SDK sans modifier à nouveau la configuration de l’authentification.
Notes
Le SDK Databricks pour Python n’a pas encore implémenté l’authentification Azure MSI.
Databricks Connect pour Databricks Runtime 13.0 prend uniquement en charge l’authentification par jetons d’accès personnels Azure Databricks pour l’authentification.
Collectez les propriétés de configuration suivantes.
- Le nom de l’instance de l’espace de travail Azure Databricks. Il s’agit de la même valeur que la valeur Nom d’hôte du serveur de votre cluster. Consultez la page Obtenir les détails de connexion d’un cluster.
- L’ID de votre cluster. Vous pouvez obtenir l’ID du cluster à partir de l’URL. Consultez URL et ID du cluster.
- Toutes les autres propriétés nécessaires au type d'authentification Databricks que vous souhaitez utiliser, comme suit.
Configurez la connexion dans votre code. Databricks Connect recherche les propriétés de configuration dans l’ordre suivant jusqu’à ce qu’il les trouve. Une fois qu’il les a trouvées, il cesse de rechercher parmi les options restantes :
Pour l’authentification par jetons d’accès personnels Azure Databricks uniquement, configuration directe des propriétés de connexion, spécifiée via la classe
DatabricksSessionPour cette option, qui s’applique uniquement à l’authentification par jetons d’accès personnels Azure Databricks, spécifiez le nom d’instance de l’espace de travail, le jeton d’accès personnel Azure Databricks et l’ID du cluster.
Les exemples de code suivants montrent comment initialiser la classe
DatabricksSessionpour l’authentification par jetons d’accès personnel Azure Databricks.Databricks déconseille de spécifier directement ces propriétés de connexion dans votre code. Databricks recommande plutôt de configurer les propriétés par l’intermédiaire de variables d’environnement ou de fichiers de configuration, comme indiqué dans les options ultérieures. Les exemples de code suivants considèrent que vous fournissez vous-même une implémentation des fonctions
retrieve_*proposées pour obtenir les propriétés nécessaires auprès de l’utilisateur ou d’une autre banque de configuration, comme Azure KeyVault.# By setting fields in builder.remote: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.remote( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ).getOrCreate() # Or, by using the Databricks SDK's Config class: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, specify a Databricks configuration profile and # the cluster_id field separately: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( profile = "<profile-name>", cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, by setting the Spark Connect connection string in builder.remote: from databricks.connect import DatabricksSession workspace_instance_name = retrieve_workspace_instance_name() token = retrieve_token() cluster_id = retrieve_cluster_id() spark = DatabricksSession.builder.remote( f"sc://{workspace_instance_name}:443/;token={token};x-databricks-cluster-id={cluster_id}" ).getOrCreate()Pour tous les types d’authentification Azure Databricks, un nom de profil de configuration Azure Databricks, spécifié à l’aide de
profile()Pour cette option, créez ou identifiez un profil de configuration Azure Databricks contenant le champ
cluster_idet tout autre champ nécessaire pour le type d’authentification Databricks que vous souhaitez utiliser.Les champs de profil de configuration requis pour chaque type d'authentification sont les suivants :
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
hostettoken. - Pour l'authentification utilisateur-machine (U2M) OAuth:
host,azure_tenant_id,azure_client_id, etazure_client_secret. - Pour l'authentification du principal du service Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, et éventuellementazure_workspace_resource_id. - Pour l'authentification Azure CLI:
host.
Définissez ensuite le nom de ce profil de configuration via la classe
Config.Vous pouvez également spécifier
cluster_idséparément du profil de configuration. Au lieu de spécifier directement l’ID de cluster dans votre code, les exemples de code suivants considèrent que vous fournissez vous-même une implémentation des fonctionsretrieve_cluster_idproposées pour obtenir les propriétés nécessaires auprès de l’utilisateur ou d’une autre banque de configuration, comme Azure KeyVault.Par exemple :
# Specify a Databricks configuration profile that contains the # cluster_id field: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate()- Pour l’authentification par jeton d’accès personnel Azure Databricks:
Uniquement pour l’authentification par jetons d’accès personnels Azure Databricks, la variable d’environnement
SPARK_REMOTEPour cette option, qui s’applique uniquement à l’authentification par jetons d’accès personnels Azure Databricks , définissez la variable d’environnement
SPARK_REMOTEsur la chaîne suivante, en remplaçant les espaces réservés par les valeurs appropriées.sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>Puis initialisez la classe
DatabricksSessioncomme suit :from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Pour définir des variables d’environnement, consultez la documentation de votre système d’exploitation.
Pour tous les types d’authentification Azure Databricks, la variable d’environnement
DATABRICKS_CONFIG_PROFILEPour cette option, créez ou identifiez un profil de configuration Azure Databricks contenant le champ
cluster_idet tout autre champ nécessaire pour le type d’authentification Databricks que vous souhaitez utiliser.Les champs de profil de configuration requis pour chaque type d'authentification sont les suivants :
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
hostettoken. - Pour l'authentification utilisateur-machine (U2M) OAuth:
host,azure_tenant_id,azure_client_id, etazure_client_secret. - Pour l'authentification du principal du service Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, et éventuellementazure_workspace_resource_id. - Pour l'authentification Azure CLI:
host.
Attribuez à la variable d’environnement
DATABRICKS_CONFIG_PROFILEle nom de ce profil de configuration. Puis initialisez la classeDatabricksSessioncomme suit :from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Pour définir des variables d’environnement, consultez la documentation de votre système d’exploitation.
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
Pour tous les types d’authentification Azure Databricks, une variable d’environnement pour chaque propriété de connexion
Pour cette option, définissez la variable d'environnement
DATABRICKS_CLUSTER_IDainsi que les autres variables d’environnement nécessaires pour le type d’authentification Databricks que vous souhaitez utiliser.Les variables d'environnement requises pour chaque type d'authentification sont les suivantes :
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
DATABRICKS_HOSTetDATABRICKS_TOKEN. - Pour l'authentification utilisateur-machine (U2M) OAuth:
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_ID, etARM_CLIENT_SECRET. - Pour l'authentification du principal du service Azure:
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_ID,ARM_CLIENT_SECRET, et éventuellementDATABRICKS_AZURE_RESOURCE_ID. - Pour l'authentification Azure CLI:
DATABRICKS_HOST.
Puis initialisez la classe
DatabricksSessioncomme suit :from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Pour définir des variables d’environnement, consultez la documentation de votre système d’exploitation.
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
Pour tous les types d’authentification Azure Databricks, un profil de configuration Azure Databricks nommé
DEFAULTPour cette option, créez ou identifiez un profil de configuration Azure Databricks contenant le champ
cluster_idet tout autre champ nécessaire pour le type d’authentification Databricks que vous souhaitez utiliser.Les champs de profil de configuration requis pour chaque type d'authentification sont les suivants :
- Pour l’authentification par jeton d’accès personnel Azure Databricks:
hostettoken. - Pour l'authentification utilisateur-machine (U2M) OAuth:
host,azure_tenant_id,azure_client_id, etazure_client_secret. - Pour l'authentification du principal du service Azure:
host,azure_tenant_id,azure_client_id,azure_client_secret, et éventuellementazure_workspace_resource_id. - Pour l'authentification Azure CLI:
host.
Nommez ce profil de configuration
DEFAULT.Puis initialisez la classe
DatabricksSessioncomme suit :from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()- Pour l’authentification par jeton d’accès personnel Azure Databricks:
Si vous choisissez d’utiliser une authentification de type authentification par jetons d’accès personnels Azure Databricks, vous pouvez utiliser l’utilitaire
pysparkinclus pour tester la connectivité à votre cluster Azure Databricks comme suit.Votre environnement virtuel étant toujours activé, exécutez la commande suivante :
Si vous avez défini la variable d’environnement
SPARK_REMOTEprécédemment, exécutez la commande suivante :pysparkSi vous n’avez pas défini la variable d’environnement
SPARK_REMOTEprécédemment, exécutez plutôt la commande suivante :pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"L’interpréteur de commandes Spark s’affiche, par exemple :
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>À l’invite
>>>, exécutez une commande PySpark simple, telle quespark.range(1,10).show(). S’il n’y a pas d’erreur, vous vous êtes connecté.Si vous vous êtes connecté, pour arrêter l’interpréteur de commandes Spark, appuyez sur
Ctrl + douCtrl + z, ou exécutez la commandequit()ouexit().
Utiliser Databricks Connect
Ces sections expliquent comment configurer de nombreux IDE et serveurs de notebooks populaires pour utiliser le client Databricks Connect. Vous pouvez également utiliser l’interpréteur de commandes Spark intégré.
Dans cette section :
- JupyterLab avec Python
- Jupyter Notebook classique avec Python
- Visual Studio Code avec Python
- PyCharm avec Python
- Eclipse avec PyDev
- Interpréteur de commandes Spark avec Python
JupyterLab avec Python
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec JupyterLab et Python, suivez ces instructions.
Pour installer JupyterLab, avec votre environnement virtuel Python activé, exécutez la commande suivante à partir de votre terminal ou invite de commandes :
pip3 install jupyterlabPour démarrer JupyterLab dans votre navigateur web, exécutez la commande suivante à partir de votre environnement virtuel Python activé :
jupyter labSi JupyterLab n’apparaît pas dans votre navigateur web, copiez l’URL qui commence par
localhostou127.0.0.1à partir de votre environnement virtuel, puis entrez-la dans la barre d’adresse de votre navigateur web.Créez un notebook dans JupyterLab, cliquez sur Fichier > Nouveau > Notebook dans le menu principal, sélectionnez Python 3 (ipykernel), puis cliquez sur Sélectionner.
Dans la première cellule du notebook, entrez l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins initialiser
DatabricksSession, comme indiqué dans l’exemple de code.Pour exécuter le notebook, cliquez sur Exécuter > Exécuter toutes les cellules. Tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
Pour déboguer le notebook, cliquez sur l’icône de bogue (Activer le débogueur) à côté de Python 3 (ipykernel) dans la barre d’outils du notebook. Définissez un ou plusieurs points d’arrêt, puis cliquez sur Exécuter > Exécuter toutes les cellules. Tout Python est débogué localement, tandis que tout le code PySpark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
Pour arrêter JupyterLab, cliquez sur Fichier > Arrêter. Si le processus JupyterLab est toujours en cours d’exécution dans votre terminal ou invite de commandes, arrêtez ce processus en appuyant sur
Ctrl + c, puis en entrantypour confirmer.
Pour obtenir des instructions de débogage plus spécifiques, consultez Débogueur.
Jupyter Notebook classique avec Python
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect avec Jupyter Notebook classique et Python, suivez ces instructions.
Pour installer Jupyter Notebook classique, avec votre environnement virtuel Python activé, exécutez la commande suivante à partir de votre terminal ou invite de commandes :
pip3 install notebookPour démarrer Jupyter Notebook classique dans votre navigateur web, exécutez la commande suivante à partir de votre environnement virtuel Python activé :
jupyter notebookSi Jupyter Notebook classique n’apparaît pas dans votre navigateur web, copiez l’URL qui commence par
localhostou127.0.0.1à partir de votre environnement virtuel, puis entrez-la dans la barre d’adresse de votre navigateur web.Créez un notebook : dans Jupyter Notebook classique, sous l’onglet Fichiers, cliquez sur Nouveau > Python 3 (ipykernel).
Dans la première cellule du notebook, entrez l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins initialiser
DatabricksSession, comme indiqué dans l’exemple de code.Pour exécuter le notebook, cliquez sur Cellule > Exécuter tout. Tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
Pour déboguer le notebook, ajoutez la ligne de code suivante au début de votre notebook :
from IPython.core.debugger import set_tracePuis appelez
set_trace()pour entrer des instructions de débogage à ce stade de l’exécution du notebook. Tout Python est débogué localement, tandis que tout le code PySpark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.Pour arrêter Jupyter Notebook classique, cliquez sur Fichier> Fermer et arrêter. Si le processus Jupyter Notebook classique est toujours en cours d’exécution dans votre terminal ou invite de commandes, arrêtez ce processus en appuyant sur
Ctrl + c, puis en entrantypour confirmer.
Visual Studio Code avec Python
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Conseil
L’extension Databricks pour Visual Studio Code intègre déjà la prise en charge de Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures. Consultez la section Exécuter ou déboguer du code Python avec Databricks Connect dans la documentation de l’extension Databricks pour Visual Studio Code.
Pour utiliser Databricks Connect avec Visual Studio Code et Python, suivez ces instructions.
Démarrez Visual Studio Code.
Ouvrez le dossier qui contient votre environnement virtuel Python (Fichier > Ouvrir le dossier).
Dans le terminal Visual Studio Code (Afficher > Terminal), activez l’environnement virtuel.
Définissez l’interpréteur Python actuel comme l’interpréteur de référence pour l’environnement virtuel :
- Dans la palette de commandes (Afficher > Palette de commandes), tapez
Python: Select Interpreteret appuyez sur Entrée. - Sélectionnez le chemin d’accès à l’interpréteur Python référencé à partir de l’environnement virtuel.
- Dans la palette de commandes (Afficher > Palette de commandes), tapez
Ajoutez au dossier un fichier de code Python (
.py) qui contient l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins initialiserDatabricksSession, comme indiqué dans l’exemple de code.Pour exécuter le code, cliquez sur Exécuter > Exécuter sans débogage dans le menu principal. Tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
Pour déboguer le code :
- Une fois le fichier de code Python ouvert, définissez tous les points d’arrêt où vous voulez que votre code fasse une pause pendant l’exécution.
- Cliquez sur l’icône Exécuter et déboguer dans la barre latérale, ou cliquez sur Afficher > Exécuter dans le menu principal.
- Dans la vue Exécuter et déboguer, cliquez sur le bouton Exécuter et déboguer.
- Suivez les instructions à l’écran pour commencer à exécuter et déboguer le code.
Tout Python est débogué localement, tandis que tout le code PySpark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
Pour obtenir des instructions plus spécifiques sur l’exécution et le débogage, consultez Configurer et exécuter le débogueur et Débogage de Python dans VS Code.
PyCharm avec Python
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
IntelliJ IDEA Ultimate fournit également la prise en charge des plug-ins pour PyCharm avec Python. Pour plus d’informations, consultez la section Plug-in Python pour IntelliJ IDEA Ultimate.
Pour utiliser Databricks Connect avec PyCharm et Python, suivez ces instructions.
- Démarrez PyCharm.
- Créez un projet : cliquez sur Fichier > Nouveau projet.
- Pour Emplacement, cliquez sur l’icône de dossier, puis sélectionnez le chemin d’accès à votre environnement virtuel Python.
- Sélectionnez Interpréteur configuré précédemment.
- Pour Interpréteur, cliquez sur les points de suspension.
- Cliquez sur Interpréteur système.
- Pour Interpréteur, cliquez sur les points de suspension, puis sélectionnez le chemin d’accès complet de l’interpréteur Python qui est référencé dans l’environnement virtuel. Cliquez ensuite sur OK.
- Cliquez de nouveau sur OK .
- Cliquez sur Créer.
- Cliquez sur Créer à partir de sources existantes.
- Ajoutez au projet un fichier de code Python (
.py) qui contient l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins initialiserDatabricksSession, comme indiqué dans l’exemple de code. - Une fois le fichier de code Python ouvert, définissez tous les points d’arrêt où vous voulez que votre code fasse une pause pendant l’exécution.
- Pour exécuter le code, cliquez sur Exécuter > Exécuter. Tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
- Pour déboguer le code, cliquez sur Exécuter le > débogage. Tout Python est débogué localement, tandis que tout le code PySpark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
- Suivez les instructions à l’écran pour commencer à exécuter et déboguer le code.
Pour obtenir des instructions d’exécution et de débogage plus spécifiques, consultez Exécuter sans configuration préalable et Déboguer.
Eclipse avec PyDev
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
Pour utiliser Databricks Connect et Eclipse avec PyDev, suivez ces instructions.
- Démarrez Eclipse.
- Créez un projet : cliquez sur Fichier > Nouveau > Projet > PyDev > Projet PyDev, puis cliquez sur Suivant.
- Spécifiez un nom de projet.
- Pour Contenu du projet, spécifiez le chemin d’accès à votre environnement virtuel Python.
- Cliquez sur Veuillez configurer un interpréteur avant de procéder.
- Cliquez sur Configuration manuelle.
- Cliquez sur Nouveau > Rechercher python/pypy exe.
- Recherchez et sélectionnez le chemin d’accès complet de l’Interpréteur Python qui est référencé dans l’environnement virtuel, puis cliquez sur Ouvrir.
- Dans la boîte de dialogue Sélectionner un interpréteur, cliquez sur OK.
- Dans la boîte de dialogue Sélection nécessaire, cliquez sur OK.
- Dans la boîte de dialogue Préférences, cliquez sur Appliquer et Fermer.
- Dans la boîte de dialogue Projet PyDev, cliquez sur Terminer.
- Cliquez sur Ouvrir la perspective.
- Ajoutez au projet un fichier de code Python (
.py) qui contient l’exemple de code ou votre propre code. Si vous utilisez votre propre code, vous devez au moins initialiserDatabricksSession, comme indiqué dans l’exemple de code. - Une fois le fichier de code Python ouvert, définissez tous les points d’arrêt où vous voulez que votre code fasse une pause pendant l’exécution.
- Pour exécuter le code, cliquez sur Exécuter > Exécuter. Tout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
- Pour déboguer le code, cliquez sur Exécuter le > débogage. Tout Python est débogué localement, tandis que tout le code PySpark continue de s’exécuter sur le cluster dans l’espace de travail Azure Databricks distant. Le code principal du moteur Spark ne peut pas être débogué directement à partir du client.
Pour obtenir des instructions d’exécution et de débogage plus spécifiques, consultez la section Exécution d’un programme.
Interpréteur de commandes Spark avec Python
Notes
Avant de commencer à utiliser Databricks Connect, vous devez respecter les exigences et configurer le client pour Databricks Connect.
L’interpréteur de commande Spark fonctionne uniquement avec l’authentification de type authentification par jetons d’accès personnels Azure Databricks.
Si vous voulez utiliser Databricks Connect avec l’interpréteur de commandes Spark et Python, suivez ces instructions.
Pour démarrer l’interpréteur de commandes Spark et le connecter à votre cluster en cours d’exécution, exécutez l’une des commandes suivantes à partir de votre environnement virtuel Python activé :
Si vous avez défini la variable d’environnement
SPARK_REMOTEprécédemment, exécutez la commande suivante :pysparkSi vous n’avez pas défini la variable d’environnement
SPARK_REMOTEprécédemment, exécutez plutôt la commande suivante :pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"L’interpréteur de commandes Spark s’affiche, par exemple :
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.x.dev0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>Pour plus d’informations sur l’utilisation de l’interpréteur de commandes Spark avec Python pour exécuter les commandes sur votre cluster, consultez Analyse interactive avec l’interpréteur de commandes Spark.
Utilisez la variable
sparkintégrée pour représenterSparkSessionsur votre cluster en cours d’exécution, par exemple :>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsTout le code Python s'exécute localement, tandis que tout le code PySpark impliquant des opérations DataFrame s'exécute sur le cluster dans l'espace de travail Azure Databricks distant et les réponses d'exécution sont renvoyées à l'appelant local.
Pour arrêter l’interpréteur de commandes Spark, appuyez sur
Ctrl + douCtrl + z, ou exécutez la commandequit()ouexit().
Exemples de codes
Databricks fournit plusieurs exemples d'applications qui montrent comment utiliser Databricks Connect. Consultez le référentiel databricks-demos/dbconnect-examples dans GitHub.
Vous pouvez également utiliser les exemples de code plus simples suivants pour expérimenter Databricks Connect. Ces exemples supposent que vous utilisez l’authentification par défaut pour Databricks Connect.
Cet exemple de code simple interroge la table spécifiée, puis affiche les 5 premières lignes de la table spécifiée. Pour utiliser une autre table, ajustez l’appel sur spark.read.table.
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Cet exemple de code plus long effectue les opérations suivantes :
- Crée un DataFrame en mémoire.
- Crée une table portant le nom
zzz_demo_temps_tabledans le schémadefault. Si la table portant ce nom existe déjà, la table est d’abord supprimée. Pour utiliser un autre schéma ou table, ajustez les appels surspark.sql,temps.write.saveAsTableou les deux. - Enregistre le contenu du DataFrame dans la table.
- Exécute une requête
SELECTsur le contenu de la table. - Affiche le résultat de la requête.
- Supprime la table.
from databricks.connect import DatabricksSession
from pyspark.sql.types import *
from datetime import date
spark = DatabricksSession.builder.getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Migrer vers la dernière version de Databricks Connect
Suivez ces instructions pour migrer votre projet de code existant ou votre environnement de codage Python de Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures vers Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures.
Notes
Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures prend actuellement en charge uniquement les projets et les environnements de codage Python.
Installez la version correcte de Python comme indiqué dans les exigences afin qu’elle corresponde à votre cluster Azure Databricks, si elle n’est pas déjà installée localement.
Mettez à niveau votre environnement virtuel Python pour utiliser la version correcte de Python qui correspond à votre cluster, si nécessaire. Pour obtenir des instructions, consultez la documentation de votre fournisseur d’environnement virtuel.
Une fois votre environnement virtuel activé, désinstallez PySpark de votre environnement virtuel :
pip3 uninstall pysparkVotre environnement virtuel étant toujours activé, désinstallez Databricks Connect pour Databricks Runtime 12.2 LTS et versions antérieures :
pip3 uninstall databricks-connectVotre environnement virtuel étant toujours activé, installez Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures :
pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Notes
Databricks vous recommande d’ajouter la notation « point-astérisque » pour spécifier
databricks-connect==X.Y.*au lieu dedatabricks-connect=X.Yet vous assurer que le package le plus récent est installé. Bien qu’il ne s’agit pas d’une exigence, cela vous permet de vous assurer que vous pouvez utiliser les dernières fonctionnalités prises en charge pour ce cluster.Mettez à jour votre code Python pour initialiser la variable
spark(qui représente une instanciation de la classeDatabricksSession, commeSparkSessiondans PySpark). Pour obtenir des exemples de code, consultez l’Étape 2 : Configurer les propriétés de connexion.
Accéder aux utilitaires Databricks
Cette section explique comment utiliser Databricks Connect pour accéder aux Utilitaires Databricks.
Vous pouvez appeler des fonctions DBFS (Databricks File System) à partir d’un espace de travail Azure Databricks. Pour ce faire, vous utilisez la variable dbfs de la classe WorkspaceClient. Cette approche est similaire à l’appel des Utilitaires Databricks via la variable dbfs à partir d’un notebook dans un espace de travail. La classe WorkspaceClient appartient au Kit de développement logiciel (SDK) Databricks pour Python, qui est inclus dans Databricks Connect pour Databricks Runtime 13.0 et versions ultérieures.
Conseil
Vous pouvez également utiliser le SDK Databricks pour Python inclus pour accéder à n’importe quelle API REST Databricks disponible et pas seulement à l’API DBFS. Consultez la sectiondatabricks-sdk sur PyPI.
Pour initialiser WorkspaceClient, vous devez fournir suffisamment d’informations pour authentifier le Kit de développement logiciel (SDK) Databricks pour Python avec l’espace de travail. Vous pouvez par exemple :
Codez en dur l’URL de l’espace de travail et votre jeton d’accès directement dans votre code, puis initialisez
WorkspaceClientcomme suit. Bien que cette option soit prise en charge, Databricks ne recommande pas cette option, car elle peut exposer des informations sensibles, telles que des jetons d’accès, si votre code est enregistré dans le contrôle de version ou partagé d’une autre manière :w = WorkspaceClient(host = "https://<workspace-instance-name>", token = "<access-token-value")Créez ou spécifiez un profil de configuration qui contient les champs
hostettoken, puis initialisezWorkspaceClientcomme suit :w = WorkspaceClient(profile = "<profile-name>")Définissez les variables d’environnement
DATABRICKS_HOSTetDATABRICKS_TOKENde la même façon que vous les définissez pour Databricks Connect, puis initialisezWorkspaceClientcomme suit :w = WorkspaceClient()
Le Kit de développement logiciel (SDK) Databricks pour Python ne reconnaît pas la variable d’environnement SPARK_REMOTE pour Databricks Connect.
Pour obtenir des options d’authentification Azure Databricks supplémentaires pour le Kit de développement logiciel (SDK) Databricks pour Python, ainsi que pour savoir comment initialiser AccountClient dans le Kit de développement logiciel (SDK) Databricks pour Python afin d’accéder aux API REST Databricks disponibles au niveau du compte plutôt qu’au niveau de l’espace de travail, consultez databricks-sdk sur PyPI.
L’exemple suivant crée un fichier nommé zzz_hello.txt dans la racine DBFS de l’espace de travail, écrit des données dans le fichier, ferme le fichier, lit les données du fichier, puis supprime le fichier. Cet exemple suppose que les variables d’environnement DATABRICKS_HOST et DATABRICKS_TOKEN ont déjà été définies :
from databricks.sdk import WorkspaceClient
import base64
w = WorkspaceClient()
file_path = "/zzz_hello.txt"
file_data = "Hello, Databricks!"
# The data must be base64-encoded before being written.
file_data_base64 = base64.b64encode(file_data.encode())
# Create the file.
file_handle = w.dbfs.create(
path = file_path,
overwrite = True
).handle
# Add the base64-encoded version of the data.
w.dbfs.add_block(
handle = file_handle,
data = file_data_base64.decode()
)
# Close the file after writing.
w.dbfs.close(handle = file_handle)
# Read the file's contents and then decode and print it.
response = w.dbfs.read(path = file_path)
print(base64.b64decode(response.data).decode())
# Delete the file.
w.dbfs.delete(path = file_path)
Conseil
Vous pouvez également accéder aux secrets des utilitaires Databricks via w.secrets, à l’utilitaire travaux via w.jobs et à l’utilitaire bibliothèque via w.libraries.
Désactivation de Databricks Connect
Les services Databricks Connect (et Spark Connect sous-jacents) peuvent être désactivés sur n’importe quel cluster donné. Pour désactiver le service Databricks Connect, définissez la configuration Spark suivante sur le cluster.
spark.databricks.service.server.enabled false
Une fois désactivées, toutes les requêtes Databricks Connect qui atteignent le cluster sont rejetées avec un message d’erreur approprié.
Définir des configurations Hadoop
Sur le client, vous pouvez définir des configurations Hadoop à l’aide de l’API spark.conf.set, qui s’applique aux opérations SQL et DataFrame. Les configurations Hadoop définies sur sparkContext doivent être définies dans la configuration du cluster ou à l’aide d’un notebook. Cela est dû au fait que les configurations définies sur sparkContext ne sont pas liées aux sessions utilisateur, mais s’appliquent à l’ensemble du cluster.
Dépannage
Cette section décrit certains problèmes courants que vous pouvez rencontrer avec Databricks Connect et comment les résoudre.
Dans cette section :
- Erreur : StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, échec de la résolution DNS ou en-tête http2 reçu avec l’état 500
- Non-concordance des versions Python
- Installations PySpark en conflit
- Entrée
PATHmanquante ou en conflit pour les fichiers binaires - La syntaxe du nom de fichier, du nom de répertoire ou de l’étiquette de volume est incorrecte sur Windows
Erreur : StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, échec de la résolution DNS ou en-tête http2 reçu avec l’état 500
Problème : Quand vous essayez d’exécuter du code avec Databricks Connect, vous obtenez des messages d’erreur qui contiennent des chaînes de type StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, DNS resolution failed ou Received http2 header with status: 500.
Cause possible : Databricks Connect ne peut pas accéder à votre cluster.
Solutions recommandées :
- Vérifiez que le nom de l’instance de votre espace de travail est correct. Si vous utilisez des variables d’environnement, vérifiez que la variable d’environnement associée est disponible et correcte sur votre machine de développement locale.
- Vérifiez que votre ID de cluster est correct. Si vous utilisez des variables d’environnement, vérifiez que la variable d’environnement associée est disponible et correcte sur votre machine de développement locale.
- Vérifiez que votre cluster a la version de cluster personnalisée appropriée compatible avec Databricks Connect.
Non-concordance de la version Python
Vérifiez que la version de Python que vous utilisez localement a au moins la même version mineure que la version sur le cluster (par exemple, 3.10.11 avec 3.10.10 est OK ; 3.10 avec 3.9 ne l’est pas).
Si plusieurs versions de Python sont installées localement, assurez-vous que Databricks Connect utilise la version appropriée en définissant la variable d’environnement PYSPARK_PYTHON (par exemple, PYSPARK_PYTHON=python3).
Installations PySpark en conflit
Le package databricks-connect est en conflit avec PySpark. Si les deux sont installés, des erreurs se produisent lors de l’initialisation du contexte Spark dans Python. Cela peut se manifester de plusieurs façons, notamment des erreurs de « flux endommagé » ou de « classe introuvable ». Si PySpark est installé dans votre environnement Python, assurez-vous qu’il est désinstallé avant d’installer databricks-connect. Après la désinstallation de PySpark, veillez à réinstaller entièrement le package Databricks Connect :
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==13.1.*" # or X.Y.* to match your specific cluster version.
PATH manquante ou en conflit pour les fichiers binaires
Il est possible que votre valeur de chemin PATH soit configurée de sorte que les commandes comme spark-shell exécutent d’autres fichiers binaires précédemment installés plutôt que celui fourni avec Databricks Connect. Vous devez vous assurer que les fichiers binaires Databricks Connect sont prioritaires, ou supprimer ceux installés précédemment.
Si vous ne pouvez pas exécuter de commandes telles que spark-shell, il est également possible que votre chemin PATH n’ait pas été automatiquement configuré par pip3 install et que vous deviez ajouter manuellement le répertoire d’installation bin à votre chemin PATH. Il est possible d’utiliser Databricks Connect avec des IDE, même si cela n’est pas configuré.
La syntaxe du nom de fichier, du nom de répertoire ou du nom de volume est incorrecte sur Windows
Si vous utilisez Databricks Connect sur Windows et que vous voyez :
The filename, directory name, or volume label syntax is incorrect.
Databricks Connect a été installé dans un répertoire comportant un espace dans votre chemin d’accès. Vous pouvez contourner ce contournement en installant dans un chemin de répertoire sans espaces, ou en configurant votre chemin à l’aide de la forme de nom abrégée.
Limites
Databricks Connect ne prend pas en charge les fonctionnalités d’Azure Databricks et les plateformes tierces.
Limitations de l’API DataFrame PySpark
- La classe
SparkContextet ses méthodes ne sont pas disponibles. - Les jeux de données distribués résilients (RDD) et les jeux de données ne sont pas pris en charge. Seuls les DataFrames sont pris en charge.
Limitations d’Azure Databricks et de Databricks Connect
- Les requêtes d’une durée supérieure à 3 600 secondes ne sont pas prises en charge et échouent.
- La synchronisation de l’environnement de développement local avec le cluster distant n’est pas prise en charge.
- Vérifiez que la version Python et les packages Python que vous utilisez dans votre environnement de développement local correspondent autant que possible à leurs équivalents installés sur le cluster, afin de garantir la compatibilité du code et réduire les erreurs d’exécution inattendues.
- Seul Python est pris en charge. R, Scala et Java ne sont pas pris en charge.
- La formation distribué n’est pas prise en charge.
- MLflow est pris en charge, mais pas l’inférence de modèle avec
mlflow.pyfunc.spark_udf(spark, ...). Vous pouvez charger le modèle localement avecmlflow.pyfunc.load_model(<model>), ou vous pouvez l’encapsuler en tant qu’UDF Pandas personnalisé. - Vous ne pouvez pas modifier le niveau du journal Log4j via
SparkContext. - Mosaic n’est pas pris en charge.
Limitations du cluster Azure Databricks
L’utilisateur de l’espace de travail Azure Databricks associé à un jeton d’accès utilisé par Databricks Connect doit avoir les autorisations Peut attacher à ou supérieures pour le cluster cible.
Les commandes SQL
CREATE TABLE table AS SELECT ...ne fonctionnent pas toujours. Utilisez plutôtspark.sql("SELECT ...").write.saveAsTable("table").Le transfert direct des informations d’identification Azure Active Directory est pris en charge uniquement sur les clusters standard exécutant Databricks Runtime 7.3 LTS et les versions ultérieures, et n’est pas compatible avec l’authentification du principal de service.
Les jetons Azure Active Directory (AD) ne sont pas automatiquement actualisés et expirent une heure après leur génération initiale.
Les utilitaires Databricks suivants :