Shiny sur Azure Databricks
Shiny est un package R, disponible sur CRAN, utilisé pour générer des applications et des tableaux de bord R interactifs. Vous pouvez utiliser Shiny à l’intérieur d’un serveur RStudio hébergé sur des clusters Azure Databricks. Vous pouvez également développer, héberger et partager des applications Shiny directement à partir d’un notebook Azure Databricks.
Pour prendre en main Shiny, consultez les Tutoriels Shiny. Vous pouvez exécuter ces tutoriels sur des notebooks Azure Databricks.
Cet article explique comment exécuter des applications Shiny sur Azure Databricks et comment utiliser Apache Spark dans des applications Shiny.
Shiny dans des notebooks R
Bien démarrer avec Shiny dans des notebooks R
Le package Shiny est inclus dans Databricks Runtime. Vous pouvez développer et tester de manière interactive des applications Shiny dans des notebooks R Azure Databricks comme dans votre instance RStudio hébergée.
Effectuez d’abord ces étapes :
Créez un notebook R.
Importez le package Shiny et exécutez l’exemple d’application
01_hellocomme suit :library(shiny) runExample("01_hello")Lorsque l’application est prête, la sortie comprend l’URL de l’application Shiny sous forme de lien interactif qui ouvre un nouvel onglet. Pour partager cette application avec d’autres utilisateurs, consultez Partager l’URL de l’application Shiny.

Notes
- Les messages du journal s’affichent dans le résultat de la commande, comme le message du journal par défaut (
Listening on http://0.0.0.0:5150) illustré dans l’exemple. - Pour arrêter l’application Shiny, cliquez sur Annuler.
- L’application Shiny utilise le processus R du notebook. Si vous détachez le notebook du cluster ou annulez la cellule qui exécute l’application, l’application Shiny s’arrête. Vous ne pouvez pas exécuter d’autres cellules pendant que l’application Shiny est en cours d’exécution.
Exécuter des applications Shiny à partir des dossiers Git de Databricks
Vous pouvez exécuter des applications Shiny qui sont archivées dans les Dossiers Git de Databricks.
Exécutez l'application.
library(shiny) runApp("006-tabsets")
Exécuter des applications Shiny à partir de fichiers
Si le code de votre application Shiny fait partie d’un projet couvert par la gestion de version, vous pouvez l’exécuter à l’intérieur du notebook.
Notes
Vous devez utiliser le chemin absolu ou définir le répertoire de travail avec setwd().
Extrayez le code à partir d’un référentiel à l’aide de code de ce type :
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Pour exécuter l’application, entrez du code similaire au suivant dans une autre cellule :
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Partage de l’URL de l’application Shiny
L’URL de l’application Shiny générée au démarrage d’une application peut être partagée avec d’autres utilisateurs. Tout utilisateur Azure Databricks disposant d’une autorisation PEUT ATTACHER À sur le cluster peut afficher l’application et interagir avec l’application tant que l’application et le cluster sont en cours d’exécution.
En cas d’arrêt du cluster sur lequel s’exécute l’application, celle-ci devient inaccessible. Vous pouvez désactiver l’arrêt automatique dans les paramètres du cluster.
Si vous attachez et exécutez le notebook qui héberge l’application Shiny sur un autre cluster, l’URL Shiny change. Même si l’application est redémarrée sur le même cluster, Shiny peut choisir un autre port aléatoire. Pour garantir une URL stable, vous pouvez définir l’option shiny.port, ou spécifier l’argument port lorsque vous redémarrez l’application sur le même cluster.
Shiny sur RStudio Server hébergé
Spécifications
Important
Avec RStudio Server Pro, vous devez désactiver l’authentification par proxy.
Assurez-vous que auth-proxy=1 n’est pas présent dans /etc/rstudio/rserver.conf.
Bien démarrer avec Shiny sur RStudio Server hébergé
Ouvrez RStudio sur Azure Databricks
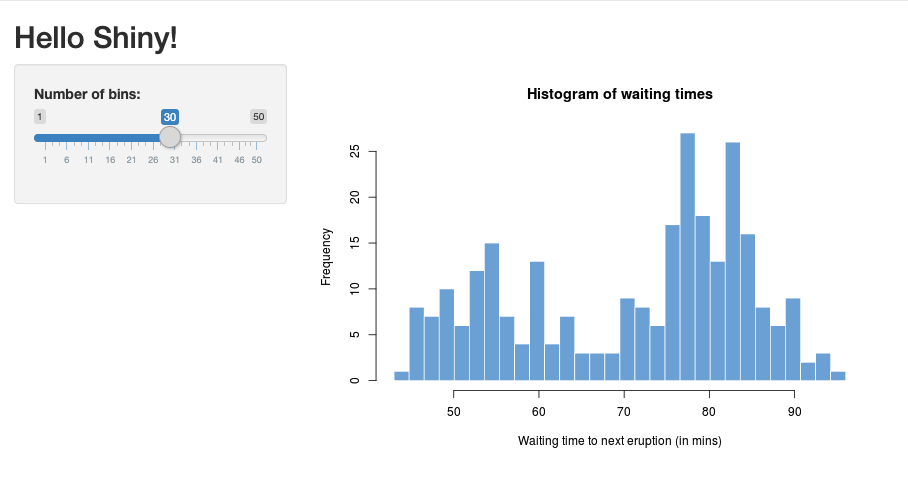
Dans RStudio, importez le package Shiny et exécutez l’exemple d’application
01_hellocomme suit :> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Une nouvelle fenêtre s’ouvre, affichant l’application Shiny.
Exécuter une application Shiny à partir d’un script R
Pour exécuter une application Shiny à partir d’un script R, ouvrez celui-ci dans l’éditeur RStudio, puis cliquez sur le bouton Exécuter l’application en haut à droite.
Utiliser Apache Spark dans des applications Shiny
Vous pouvez utiliser Apache Spark dans des applications Shiny avec SparkR ou sparklyr.
Utilisation de SparkR avec Shiny dans un notebook
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Utilisation de sparklyr avec Shiny dans un notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
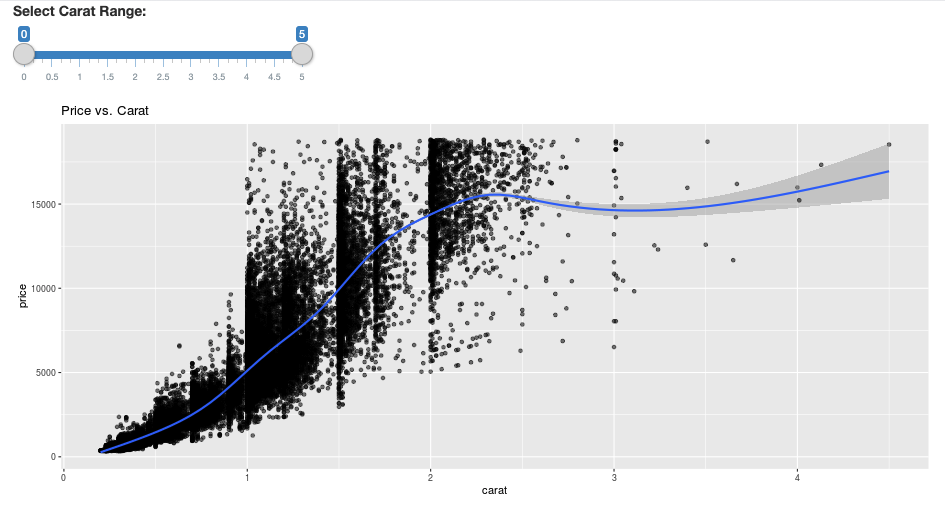
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Forum Aux Questions (FAQ)
- Pourquoi mon application Shiny s’affiche-t-elle grisée après un certain temps ?
- Pourquoi la fenêtre de ma visionneuse Shiny disparaît-elle après un certain temps ?
- Pourquoi les travaux Spark longs ne retournent-ils jamais rien ?
- Comment éviter le délai d’expiration ?
- Mon application se bloque immédiatement après son lancement, mais le code semble correct. Que se passe-t-il ?
- Combien de connexions peuvent être acceptées pour un lien d’application Shiny pendant le développement ?
- Puis-je utiliser une version du package Shiny autre que celle installée dans Databricks Runtime ?
- Comment développer une application Shiny qui peut être publiée sur un serveur Shiny et accéder aux données sur Azure Databricks ?
- Puis-je développer une application Shiny à l’intérieur d’un notebook Azure Databricks ?
- Comment puis-je enregistrer les applications Shiny que j’ai développées sur RStudio Server hébergé ?
Pourquoi mon application Shiny s’affiche-t-elle grisée après un certain temps ?
À défaut d’interaction avec l’application Shiny, la connexion à l’application se ferme après environ 4 minutes.
Pour vous reconnecter, actualisez la page d’application Shiny. L’état du tableau de bord se réinitialise.
Pourquoi la fenêtre de ma visionneuse Shiny disparaît-elle après un certain temps ?
Si la fenêtre de la visionneuse Shiny disparaît après une période d’inactivité de plusieurs minutes, cela est dû au même délai d’attente que dans le scénario d’affichage « grisé ».
Pourquoi les travaux Spark longs ne retournent-ils jamais rien ?
Cela est également dû au délai d’inactivité. Tout travail Spark dont l’exécution prend plus de temps que les délais d’attente mentionnés précédemment est incapable d’afficher son résultat, car la connexion se ferme avant que le travail retourne quoi que ce soit.
Comment éviter le délai d’expiration ?
Une solution de contournement est suggérée dans la demande de fonctionnalité qui indique de demander au client d’envoyer un message de maintien actif pour empêcher le délai d’expiration TCP sur certains équilibreurs de charge sur Github. La solution de contournement envoie des pulsations pour garder la connexion WebSocket active quand l’application est inactive. Toutefois, si l’application est bloquée par un calcul de longue durée, cette solution de contournement ne fonctionne pas.
Shiny ne prend pas en charge les tâches de longue durée. Un billet de blog Shiny recommande l’utilisation de promesses et de perspectives pour exécuter les tâches de longue durée de façon asynchrone et éviter le blocage de l’application. Voici un exemple utilisant des pulsations pour garder l’application Shiny active, et exécutant un travail Spark de longue durée dans une construction
future.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Une limite stricte de 12 heures est imposée à compter du chargement initial de la page, après quoi toute connexion, même si elle est active, est arrêtée. Vous devez actualiser l’application Shiny pour vous reconnecter dans ce cas. En revanche, la connexion WebSocket sous-jacente peut se fermer à tout moment en fonction de divers facteurs, notamment l’instabilité du réseau ou le mode veille de l’ordinateur. Databricks recommande de réécrire les applications Shiny de telle sorte qu’elles ne nécessitent pas une connexion de longue durée et ne s’appuient pas excessivement sur l’état de session.
Mon application se bloque immédiatement après son lancement, mais le code semble correct. Que se passe-t-il ?
La quantité totale de données pouvant être affichées dans une application Shiny sur Azure Databricks est limitée à 50 Mo. Si la taille totale des données de l’application dépasse cette limite, l’application se bloque immédiatement après son lancement. Pour éviter cela, Databricks recommande de réduire la taille des données, par exemple en sous-échantillonnant les données affichées ou en réduisant la résolution des images.
Combien de connexions peuvent être acceptées pour un lien d’application Shiny pendant le développement ?
Databricks en recommande jusqu’à 20.
Puis-je utiliser une version du package Shiny autre que celle installée dans Databricks Runtime ?
Oui. Consultez Corriger la version des packages R.
Comment développer une application Shiny qui peut être publiée sur un serveur Shiny et accéder aux données sur Azure Databricks ?
Bien que vous puissiez accéder aux données naturellement à l’aide de SparkR ou sparklyr pendant les phases de développement et de test sur Azure Databricks, après la publication d’une application Shiny sur un service d’hébergement autonome, l’application ne peut pas accéder directement aux données et aux tables sur Azure Databricks.
Pour permettre à votre application de fonctionner en dehors d’Azure Databricks, vous devez réécrire la manière d’accéder aux données. Voici quelques options :
- Utiliser JDBC/ODBC pour envoyer des requêtes à un cluster Azure Databricks.
- Utiliser Databricks Connect.
- Accéder aux données directement sur le stockage d’objets.
Databricks vous recommande de consulter votre équipe de solutions Azure Databricks afin de déterminer la meilleure approche pour votre architecture de données et d’analyse existante.
Puis-je développer une application Shiny à l’intérieur d’un notebook Azure Databricks ?
Oui, vous pouvez développer une application Shiny à l’intérieur d’un notebook Azure Databricks.
Comment puis-je enregistrer les applications Shiny que j’ai développées sur RStudio Server hébergé ?
Vous pouvez enregistrer votre code d’application sur DBFS ou vérifier votre code dans le contrôle de version.