Composant Évaluer le modèle
Cet article décrit un composant dans le concepteur Azure Machine Learning.
Utilisez ce composant pour mesurer la précision d’un modèle formé. Vous fournissez un jeu de données qui contient les scores générés à partir d’un modèle et le composant Évaluer le modèle calcule un ensemble de métriques d’évaluation standard du secteur.
Les métriques retournées par Évaluer le modèle varient selon le type de modèle que vous évaluez :
- Modèles de classification
- Modèles de régression
- Modèles de clustering
Conseil
Si vous ne connaissez pas l’évaluation du modèle, nous vous recommandons la série de vidéos du Dr. Stephen Elston, dans le cadre du cours de Machine Learning à partir d’EdX.
Comment utiliser le modèle Evaluate
Connectez la sortie du Jeu de données noté du module Noter un modèle ou la sortie du Jeu de données de résultats du module Attribuer des données à des clusters au port d’entrée de gauche du module Évaluer le modèle.
Notes
Si vous utilisez des composants tels que « Sélectionner des colonnes dans le jeu de données » pour sélectionner une partie du jeu de données d’entrée, vérifiez que la colonne « Étiquette réelle » (utilisée dans l’apprentissage), la colonne « Probabilités notées » et la colonne « Étiquettes notées » existent pour calculer les métriques telles que l’AUC, la précision pour la classification binaire et la détection des anomalies. Les colonnes « Étiquette réelle » et « Étiquettes notées » existent pour calculer les métriques pour la classification/régression multiclasse. Les colonnes « Attributions », « DistancesToClusterCenter no.X » (X est l’index des centroïdes, qui est compris entre 0, ..., le nombre de centroïdes-1) existent pour calculer les métriques de clustering.
Important
- Pour évaluer les résultats, le jeu de données de sortie doit contenir des noms de colonnes de score spécifiques, qui répondent aux exigences du composant Evaluate Model (Évaluer le modèle).
- La colonne
Labelssera considérée comme des étiquettes réelles. - Pour la tâche de régression, le jeu de données à évaluer doit avoir une colonne, nommée
Regression Scored Labels, qui représente les étiquettes associées à un score. - Pour la tâche de classification binaire, le jeu de données à évaluer doit avoir deux colonnes, nommées
Binary Class Scored Labels,Binary Class Scored Probabilities, qui représentent respectivement les étiquettes associées à un score et les probabilités. - Pour la tâche de classification multiple, le jeu de données à évaluer doit avoir une colonne, nommée
Multi Class Scored Labels, qui représente les étiquettes associées à un score. Si les sorties du composant en amont ne contiennent pas ces colonnes, vous devez les modifier conformément à la configuration requise ci-dessus.
[Facultatif] Connectez la sortie du Jeu de données noté du module Noter un modèle ou la sortie du Jeu de données de résultats du module Attribuer des données à des clusters au port d’entrée du second modèle de droite du module Évaluer le modèle. Vous pouvez facilement comparer les résultats de deux modèles différents sur les mêmes données. Les deux algorithmes d'entrée doivent être du même type. Vous pouvez également comparer les scores de deux exécutions différentes sur les mêmes données avec des paramètres différents.
Notes
Le type d’algorithme fait référence à 'Classification double classe', 'Classification multiclasse', 'Régression', 'Clustering' sous 'Algorithmes de Machine Learning'.
Envoyez le pipeline pour générer les notes d'évaluation.
Résultats
Après avoir exécuté Évaluer le modèle, sélectionnez le composant pour ouvrir le volet de navigation Évaluer le modèle à droite. Ensuite, choisissez l’onglet Sorties + journaux, puis, sous cet onglet, la section Sorties de données comporte plusieurs icônes. L’icône Visualiser contient une icône de graphique à barres et est une première façon de voir les résultats.
Pour la classification binaire, après avoir cliqué sur l’icône Visualiser, vous pouvez visualiser la matrice de confusion binaire. Pour la multiclassification, vous trouverez le fichier de tracé de la matrice de confusion sous l’onglet Sorties + journaux comme suit :
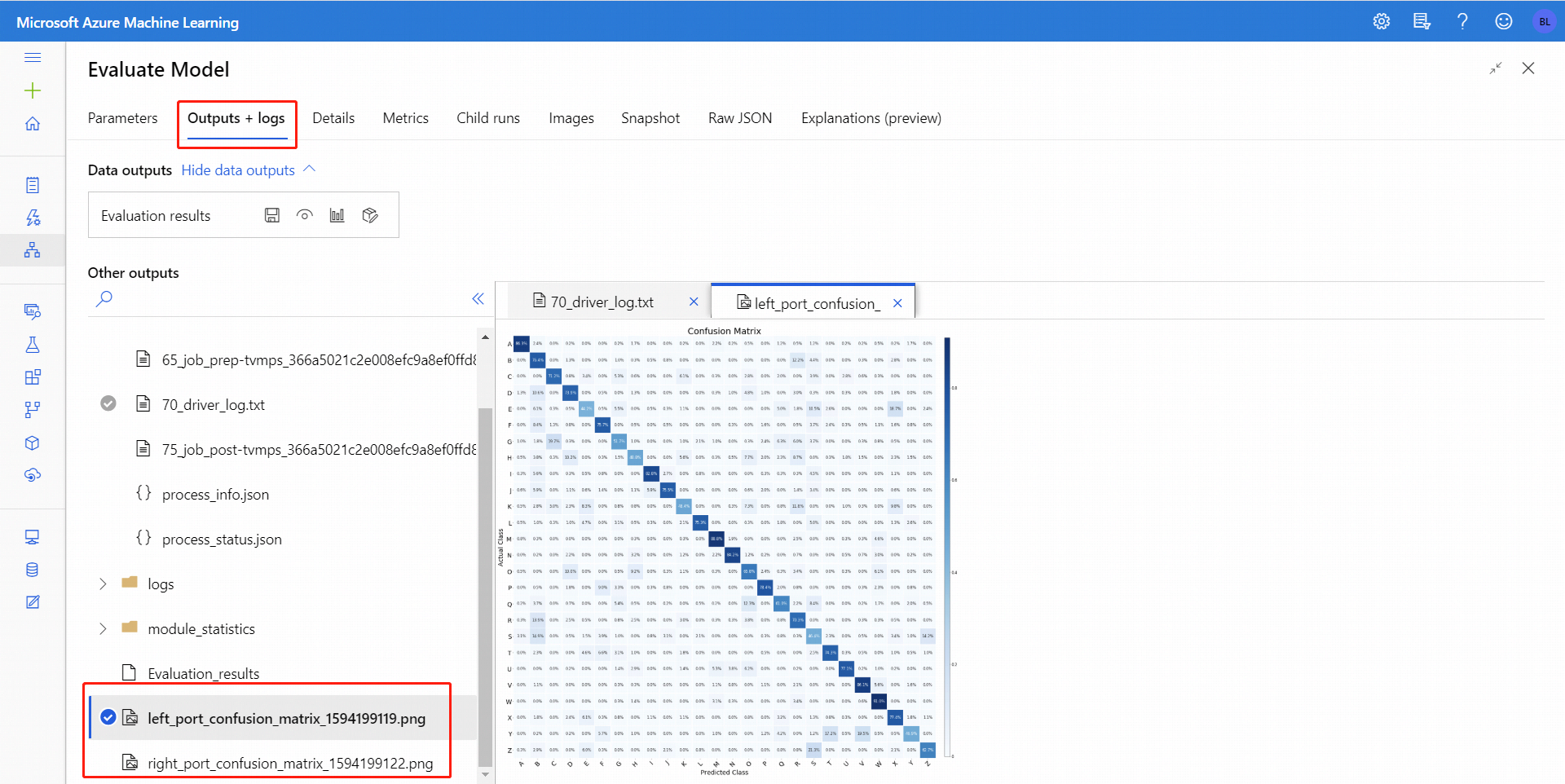
Si vous connectez des jeux de données aux deux entrées du module Évaluer le modèle, les résultats contiennent des métriques pour les deux jeux de données ou les deux modèles. Le modèle ou les données associés au port de gauche apparaissent en premier dans le rapport, suivis des métriques pour le jeu de données ou le modèle associé au port de droite.
Par exemple, l’image suivante représente une comparaison des résultats de deux modèles de clustering qui ont été créés sur les mêmes données, mais avec des paramètres différents.
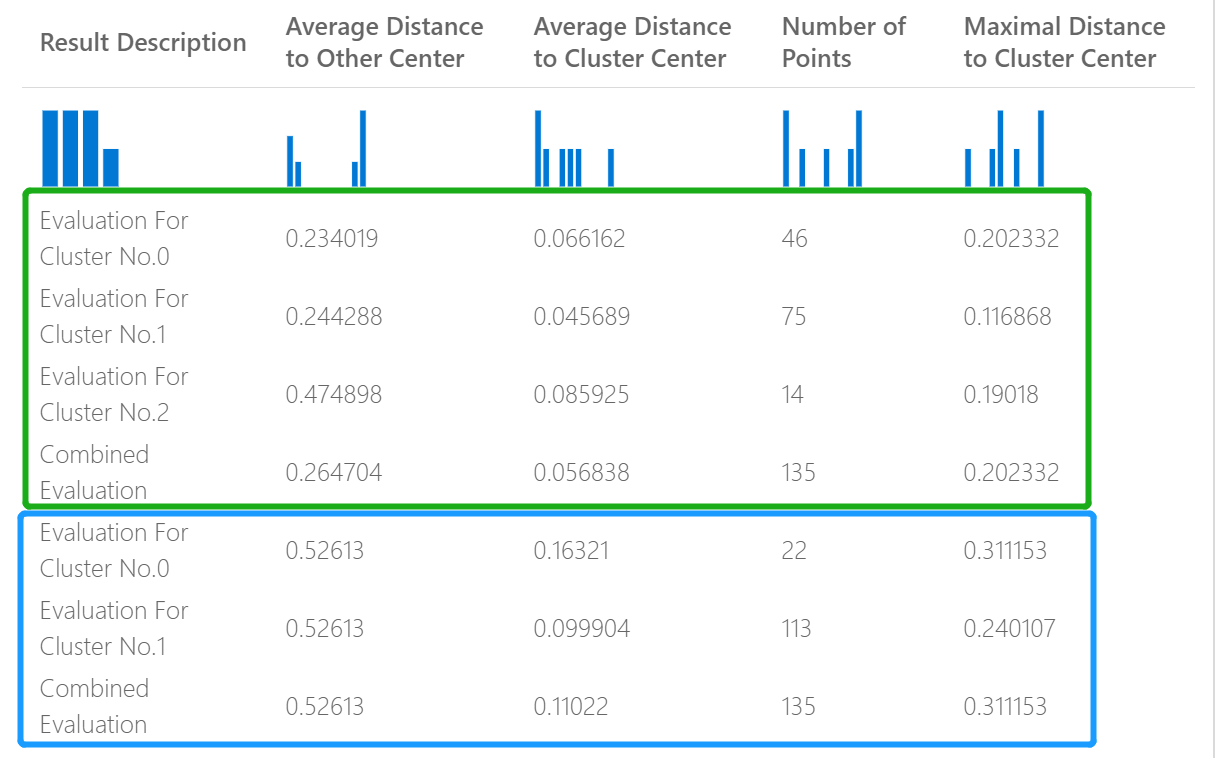
Comme il s’agit d’un modèle de clustering, les résultats de l’évaluation sont différents de ceux obtenus si vous aviez comparé les scores de deux modèles de régression ou comparé deux modèles de classification. La présentation globale est toutefois la même.
Mesures
Cette section décrit les métriques retournées pour les types spécifiques de modèles pris en charge avec Évaluer le modèle :
Métriques pour les modèles de classification
Les métriques suivantes sont rapportées lors de l’évaluation de modèles de classification binaire.
L’exactitude mesure l’adéquation d’un modèle de classification sous forme de proportion de résultats réels sur le nombre total de cas.
La précision correspond à la proportion de résultats réels sur tous les résultats positifs. Précision = TP/(TP+FP)
Le Rappel est la fraction de la quantité totale d’instances pertinentes qui ont été réellement récupérées. Rappel = TP/(TP+FN)
Le score F1 est calculé comme la moyenne pondérée de précision et de rappel comprise entre 0 et 1, la valeur de score F1 idéale étant 1.
AUC mesure la zone sous la courbe tracée avec les vrais positifs sur l’axe y et les faux positifs sur l’axe x. Cette métrique est utile car elle fournit un nombre unique qui vous permet de comparer les modèles de types différents. AUC est un invariant de seuil de classification. Il mesure la qualité des prédictions du modèle, quel que soit le seuil de classification choisi.
Métriques pour les modèles de régression
Les métriques retournées pour les modèles de régression sont conçues pour estimer la quantité d’erreurs. Un modèle est jugé correctement adapté aux données si la différence entre valeurs observées et prévues est faible. Toutefois, l’observation du modèle des résidus (la différence entre n’importe quel point prédit et sa valeur réelle correspondante) peut vous en apprendre beaucoup sur un éventuel décalage dans le modèle.
Les métriques suivantes sont signalées pour l’évaluation des modèles de régression linéaire. D’autres modèles de ré gression tels que la régression de quantile de forêt rapide peuvent avoir des métriques différentes.
L’erreur absolue moyenne (MAE) mesure la précision des prédictions par rapport aux résultats réels ; un score inférieur est donc préférence.
La racine carrée de l’erreur quadratique moyenne (RMSE) crée une valeur unique qui résume l’erreur dans le modèle. En mettant la différence au carré, la métrique ne tient pas compte de la différence entre sur-prédiction et sous-prédiction.
L’erreur absolue relative (RAE) est la différence absolue relative entre valeurs prévues et réelles ; elle est relative car la différence moyenne est divisée par la moyenne arithmétique.
L’erreur quadratique relative (RSE) normalise de manière similaire l’erreur quadratique totale des valeurs prévues en divisant par l’erreur quadratique totale des valeurs réelles.
Le coefficient de détermination, généralement appelé R2, représente la puissance prédictive du modèle sous la forme d’une valeur comprise entre 0 et 1. Zéro signifie que le modèle est aléatoire ; 1 signifie qu’il convient parfaitement. Soyez toutefois vigilant dans l’interprétation de valeurs R2 car des valeurs faibles peuvent être totalement normales et des valeurs élevées peuvent être suspectes.
Mesures pour les modèles de clustering
Étant donné que les modèles de clustering diffèrent considérablement des modèles de classification et de régression à de nombreux égards, Évaluer le modèle retourne également un ensemble différent de statistiques pour les modèles de clustering.
Les statistiques retournées pour un modèle de clustering décrivent le nombre de points de données attribués à chaque cluster, le degré de séparation entre les clusters et le degré de regroupement des points de données dans chaque cluster.
Les statistiques du modèle de clustering sont calculées par rapport à la moyenne de l’ensemble du jeu de données, avec des lignes supplémentaires contenant les statistiques par cluster.
Les mesures suivantes sont rapportées lors de l’évaluation de modèles de clustering.
Les scores de la colonne Average Distance to Other Center (distance moyenne à un autre centre) représentent la proximité moyenne de chaque point dans le cluster par rapport aux centroïdes de tous les autres clusters.
Les scores de la colonne Average Distance to Cluster Center (distance moyenne au centre du cluster) représentent la proximité de tous les points d’un cluster par rapport au centroïde de ce cluster.
La colonne Number of Points (Nombre de points) indique le nombre de points de données attribués à chaque cluster, ainsi que le nombre total de points de données dans chaque cluster.
Si le nombre de points de données attribués aux clusters est inférieur au nombre total de points de données disponibles, cela signifie que les points de données n’ont pas pu être attribués à un cluster.
Les scores de la colonne Maximal Distance to Cluster Center (Distance maximale au centre du cluster) représentent le maximum des distances entre chaque point et le centroïde du cluster de ce point.
Si ce nombre est élevé, cela peut signifier que le cluster est très dispersé. Vous devez examiner cette statistique en même temps que la distance moyenne au centre du cluster pour déterminer la répartition du cluster.
Le score Combined Evaluation (Évaluation combinée) en bas de chaque section de résultats répertorie les scores moyens pour les clusters créés dans ce modèle particulier.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.