Collecter des données pour des modèles en production
S’APPLIQUE À : SDK Python azureml v1
SDK Python azureml v1
Cet article montre comment collecter des données à partir d’un modèle d’Azure Machine Learning déployé sur un cluster Azure Kubernetes service (AKS). Les données collectées sont alors stockées dans le Azure Blob.
Une fois la collecte activée, les données que vous collectez vous permettent d’effectuer les opérations suivantes :
Surveiller les dérives de données sur les données de production que vous recueillez.
Analyser les données collectées à l’aide de Power BI ou Azure Databricks
Prendre de meilleures décisions concernant le réentraînement ou l’optimisation de votre modèle
Réentraîner votre modèle avec les données collectées
Limites
- La fonctionnalité de collecte de données de modèle ne peut fonctionner qu’avec l’image Ubuntu 18.04.
Important
Depuis le 10/03/2023, l’image Ubuntu 18.04 est désormais déconseillée. La prise en charge des images Ubuntu 18.04 sera supprimée à partir de janvier 2023 quand elle atteindra sa fin de vie (EOL) le 30 avril 2023.
La fonctionnalité MDC est incompatible avec toute image autre que Ubuntu 18.04 qui n’est pas disponible une fois celle-ci dépréciée.
mPlus d’informations à laquelle vous pouvez vous reporter :
Notes
La fonctionnalité de collecte de données est actuellement en préversion. Aucune fonctionnalité d’évaluation n’est recommandée pour les charges de travail de production.
Types et destination des données collectées
Les données suivantes peuvent être collectées :
Données d’entrée de modèle issues des services web déployés dans un cluster AKS. La voix audio, les images et les vidéos ne sont pas collectés.
Prédictions de modèle utilisant des données d’entrée de production.
Notes
La préagrégation et les précalculs de ces données ne font pas partie du service de collecte.
La sortie est enregistrée dans le stockage d’objets blob. Étant donné que les données sont ajoutées au stockage d’objets blob, vous pouvez choisir votre outil favori pour exécuter l’analyse.
Le chemin des données de sortie dans l’objet blob respecte cette syntaxe :
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Notes
Dans les versions du SDK Azure Machine Learning pour Python qui sont antérieures à la version 0.1.0a16, l’argument designation se nomme identifier. Si votre code a été développé avec une version antérieure, vous devrez le mettre à jour.
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Vous devez installer un espace de travail Azure Machine Learning, un répertoire local contenant vos scripts, et le SDK Azure Machine Learning pour Python. Pour savoir comment les installer, consultez Guide pratique pour configurer un environnement de développement.
Vous devez déployer un modèle Machine Learning entraîné sur AKS. Si vous n’avez pas de modèle, consultez le tutoriel Entraîner un modèle de classification des images.
Vous avez besoin d’un cluster AKS. Pour plus d’informations sur la création et le déploiement sur celui-ci, consultez Déployer des modèles Machine Learning sur Azure.
Configurez votre environnement et installez le SDK de supervision Azure Machine Learning.
Utilisez une image Docker basée sur Ubuntu 18.04, qui est fournie avec
libssl 1.0.0, la dépendance essentielle de modeldatacollector. Vous pouvez faire référence à des images prédéfinies.
Activer la collecte des données
Vous pouvez activer la collecte de données, quel que soit le modèle que vous déployez par le biais d’Azure Machine Learning ou d’autres outils.
Pour activer la collecte de données, vous devez :
Ouvrir le fichier de scoring.
Ajoutez le code suivant au début du fichier :
from azureml.monitoring import ModelDataCollectorDéclarez vos variables de collecte de données dans votre fonction
init:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId est un paramètre facultatif. Il n’est pas obligatoire si votre modèle n’en a pas besoin. L’utilisation de CorrelationId vous permet un mappage plus facile avec d’autres données, telles que LoanNumber ou CustomerId.
Le paramètre Identifier est utilisé ultérieurement pour créer la structure de dossiers dans votre objet blob. Vous pouvez l’utiliser pour différencier les données brutes des données traitées.
Ajoutez les lignes de code suivantes à la fonction
run(input_df):data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobLa collecte de données n’est pas automatiquement définie sur true quand vous déployez un service dans AKS. Mettez à jour votre fichier de configuration, comme dans l’exemple suivant :
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Vous pouvez également activer Application Insights pour la supervision de service en modifiant cette configuration :
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Pour créer une image et déployer le modèle Machine Learning, consultez Déployer des modèles Machine Learning sur Azure.
Ajoutez le package PIP « Azure-Monitoring » aux dépendances Conda de l’environnement de service Web :
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Désactiver la collecte de données
Vous pouvez arrêter la collecte de données à tout moment. Utilisez le code Python pour désactiver la collecte de données.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Valider et analyser vos données
Vous pouvez choisir l’outil de votre choix pour analyser les données collectées dans votre stockage d’objets blob.
Accéder rapidement à vos données d’objets blob
Connectez-vous au portail Azure.
Ouvrez votre espace de travail.
Sélectionnez Stockage.

Suivez le chemin des données de sortie de l’objet blob avec cette syntaxe :
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analyser des données de modèle à l’aide de Power BI
Téléchargez et ouvrez Power BI Desktop.
Sélectionnez Obtenir des données, puis sélectionnez Stockage Blob Azure.
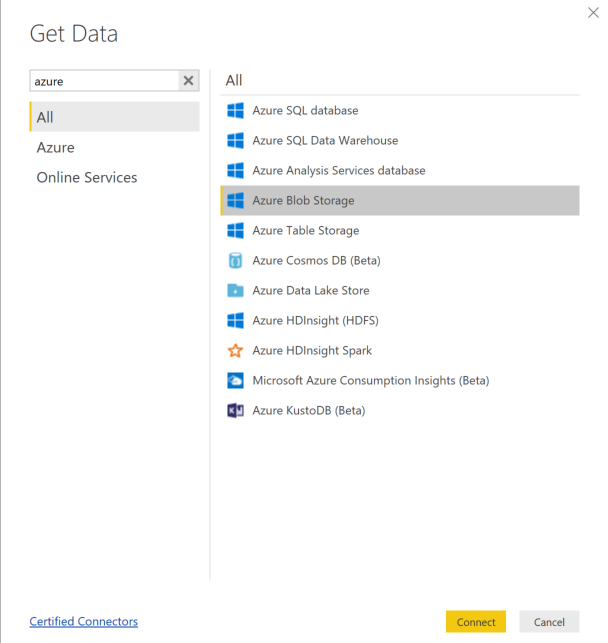
Ajoutez le nom de votre compte de stockage et entrez votre clé de stockage. Vous pouvez accéder à ces informations en sélectionnant Paramètres>Clés d’accès dans votre objet blob.
Sélectionnez le conteneur de données de modèle, puis sélectionnez Modifier.
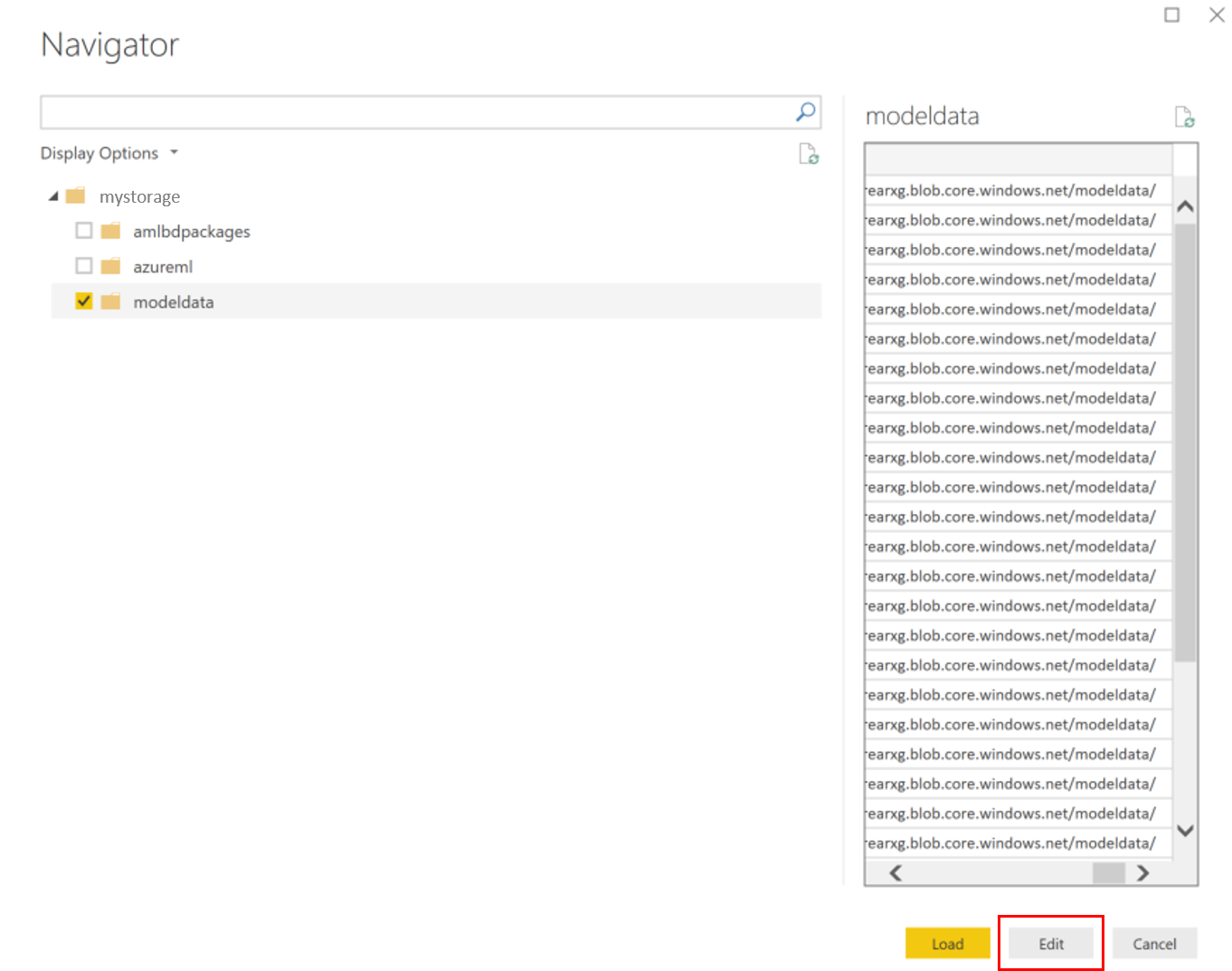
Dans l’éditeur de requête, cliquez sous la colonne Name et ajoutez votre compte de stockage.
Entrez le chemin du modèle dans le filtre. Si vous ne voulez examiner que les fichiers d’une année ou d’un mois spécifique, développez simplement le chemin du filtre. Par exemple, pour rechercher uniquement les données du mois de mars, utilisez ce chemin de filtre :
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<désignation>/<année>/3
Filtrez les données qui vous concernent en fonction des valeurs de Nom. Si vous avez stocké des prédictions et des entrées, vous devrez créer une requête pour chacune d’elles.
Sélectionnez les flèches doubles vers le bas en regard de l’en-tête de colonne Contenu pour combiner les fichiers.
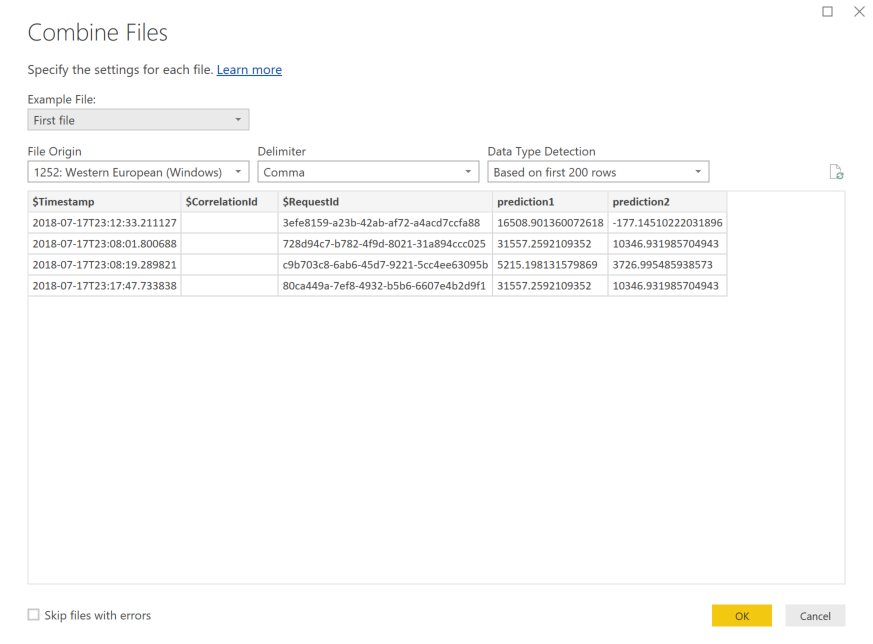
Sélectionnez OK. Les données sont préchargées.
Sélectionnez Fermer et appliquer.
Si vous avez ajouté des entrées et des prédictions, vos tables sont automatiquement classées en fonction des valeurs RequestId.
Commencez à créer vos rapports personnalisés à partir des données de votre modèle.




Analyser des données de modèle à l’aide d’Azure Databricks
Créez un espace de travail Azure Databricks.
Accédez à votre espace de travail Databricks.
Dans votre espace de travail Databricks, sélectionnez Charger des données.

Sélectionnez Créer une table, puis sélectionnez Autres sources de données>Stockage Blob Azure>Créer une table dans Notebook.
Mettez à jour l’emplacement de vos données. Voici un exemple :
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/*/*/data.csv" file_type = "csv"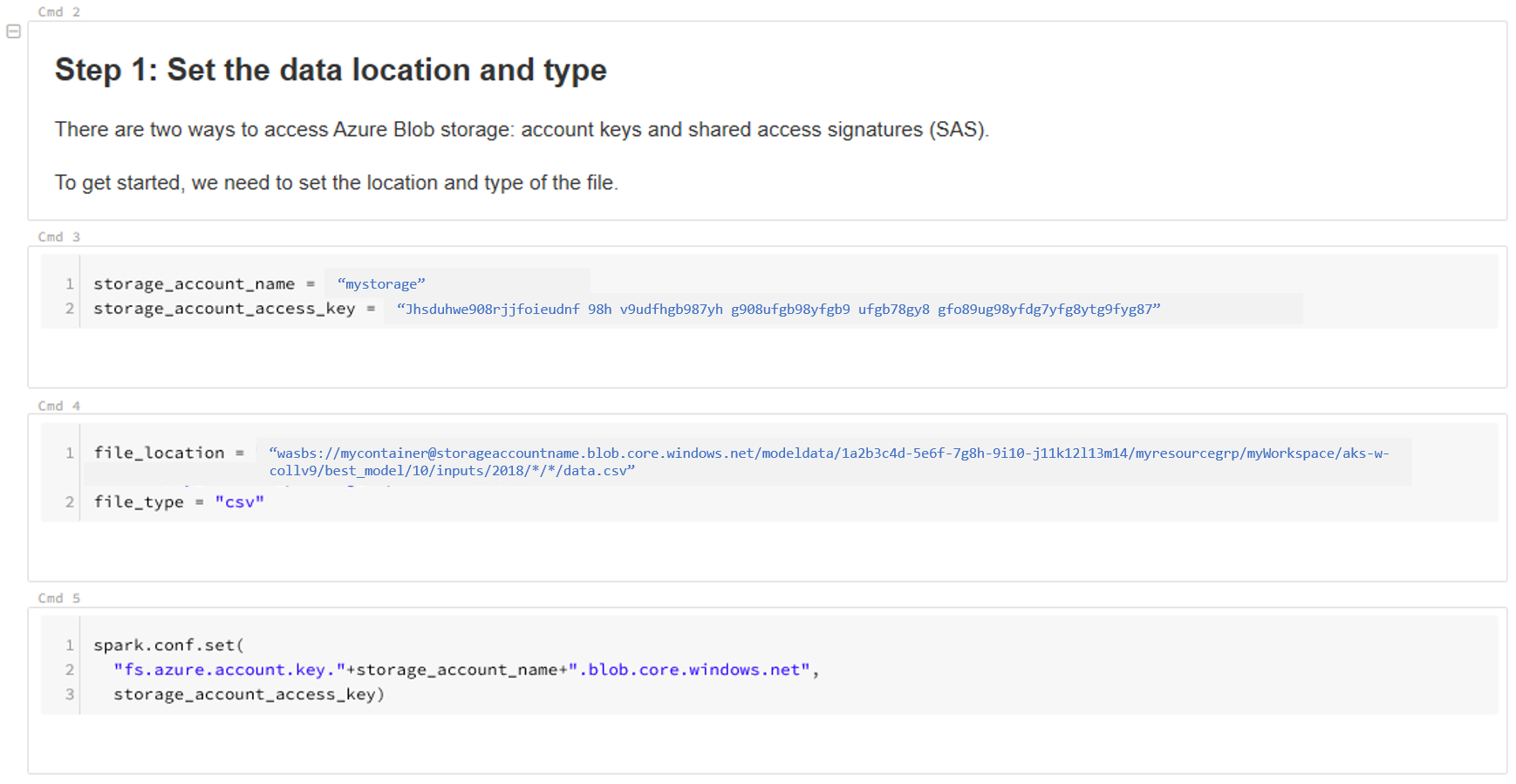
Suivez les étapes du modèle afin d’afficher et d’analyser vos données.



Étapes suivantes
Détectez la dérive des données sur les données que vous avez collectées.