Tests d’évaluation des performances de Recherche Azure AI
Important
Ces points de référence s’appliquent aux services de recherche créés avant le 3 avril 2024. De plus, ils s’appliquent uniquement aux charges de travail non vectorielles. Les mises à jour sont en attente pour les services et les charges de travail sur les nouvelles limites.
Les points de référence sont utiles pour estimer les performances potentielles dans des configurations similaires. Les performances réelles dépendent de divers facteurs, notamment la taille de votre service de recherche et des types de requêtes que vous envoyez.
Pour vous aider à estimer la taille du service de recherche nécessaire à votre charge de travail, nous avons exécuté plusieurs points de référence afin de documenter les performances des différents services de recherche et configurations.
Pour couvrir un maximum de cas d’utilisation différents, nous avons exécuté des tests d’évaluation pour deux scénarios principaux :
- Recherche e-commerce : ce test d’évaluation émule un véritable scénario e-commerce et est basé sur la société de commerce électronique nordique CDON.
- Recherche de documents : ce scénario se compose d’une recherche par mot clé sur des documents de texte intégral provenant de Semantic Scholar. Elle émule une solution de recherche de documents classique.
Bien que ces scénarios reflètent des cas d’utilisation différents, chaque scénario est unique. Nous recommandons donc toujours de tester les performances de votre charge de travail individuelle. Nous avons publié une solution de test des performances à l’aide de JMeter pour vous permettre d’exécuter des tests similaires sur votre propre service.
Méthodologie de test
Pour évaluer les performances de Recherche Azure AI, nous avons exécuté des tests pour deux scénarios différents dans différentes combinaisons de niveaux et de réplicas/partitions.
Pour créer ces tests d’évaluation, la méthodologie suivante a été utilisée :
- Le test commence à
Xrequêtes par seconde (RPS) pendant 180 secondes. Nous avons généralement utilisé 5 ou 10 RPS. - Les RPS sont ensuite augmentées de
Xet exécutées pendant une durée supplémentaire de 180 secondes - Toutes les 180 secondes, le test augmente les RPS de
Xjusqu’à ce que la latence moyenne passe au-dessus de 1000 ms ou que moins de 99 % des requêtes réussissent.
Le graphique suivant donne un exemple visuel de la charge en requêtes du test :
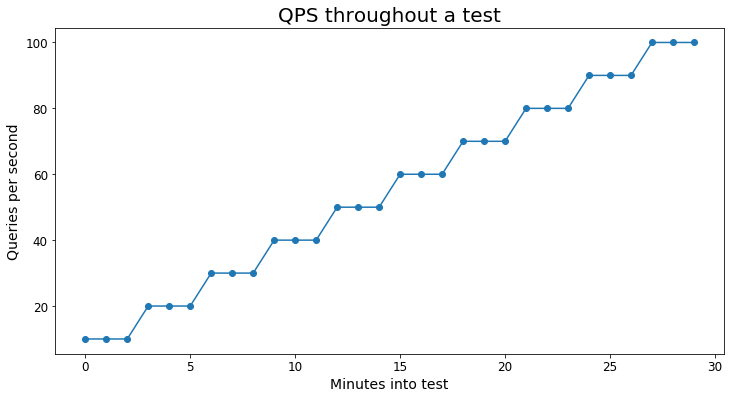
Chaque scénario a utilisé au moins 10 000 requêtes uniques pour éviter que les tests soient trop faussés par la mise en cache.
Important
Ces tests incluent uniquement des charges de travail de requête. Si vous envisagez de disposer d’un volume élevé d’opérations d’indexation, veillez à les factoriser dans vos tests d’estimation et de performances. Vous trouverez des exemples de code pour simuler l’indexation dans ce tutoriel.
Définitions
Nombre maximal de RPS : le nombre maximal de RPS est basé sur le nombre de RPS le plus élevé atteint dans un test où 99 % des requêtes se sont terminées avec succès sans limitation et la latence moyenne est restée sous 1 000 ms.
Pourcentage du nombre maximal de RPS : un pourcentage du nombre maximal de RPS atteint pour un test particulier. Par exemple, si un test donné a atteint un maximum de 100 RPS, 20 % du nombre maximal de RPS serait de 20 RPS.
Latence : la latence du serveur pour une requête. Ces chiffres ne comprennent pas le délai d’aller-retour (RTT). Les valeurs sont exprimées en millisecondes (ms).
Exclusion de responsabilité concernant les tests
Le code que nous avons utilisé pour exécuter ces tests d’évaluation est disponible dans le référentiel azure-search-performance-testing. Il est à noter que nous avons observé des niveaux de RPS légèrement inférieurs avec la solution de test de performances JMeter que dans les tests. Les différences peuvent être attribuées aux différences dans le style des tests. Cela implique l’importance de vous assurer que vos tests de performances sont similaires à votre charge de travail de production.
Important
Ces tests ne garantissent en aucun cas un certain niveau de performances de votre service, mais peuvent vous aider à vous faire une idée des performances que vous pouvez attendre sur la base de votre scénario.
N’hésitez pas à nous contacter à l’adresse azuresearch_contact@microsoft.com si vous avez des questions ou des préoccupations.
Test 1 : Recherche e-commerce
![]()
Ce test d’évaluation a été créé en partenariat avec la société d’e-commerce CDON, le plus grand marché en ligne de la région nordique, avec des opérations en Suède, en Finlande, en Norvège et au Danemark. Par le biais de ses 1 500 commerçants, CDON offre un assortiment large qui inclut plus de 8 millions de produits. En 2020, CDON a eu plus de 120 millions de visiteurs et 2 millions de clients actifs. Vous pouvez en apprendre plus sur l’utilisation de Recherche Azure AI par CDON dans cet article.
Pour exécuter ces tests, nous avons utilisé un instantané de l’index de recherche de production de CDON et de milliers de requêtes uniques à partir de leur site web.
Détails sur le scénario
- Nombre de documents : 6 000 000
- Taille de l’index : 20 Go
- Schéma d’index : un index étendu avec 250 champs au total, 25 champs pouvant faire l’objet d’une recherche et 200 champs étant à choix multiples/filtrables
- Types de requêtes : requêtes de recherche en texte intégral incluant des choix multiples, des filtres, des commandes et des profils de scoring
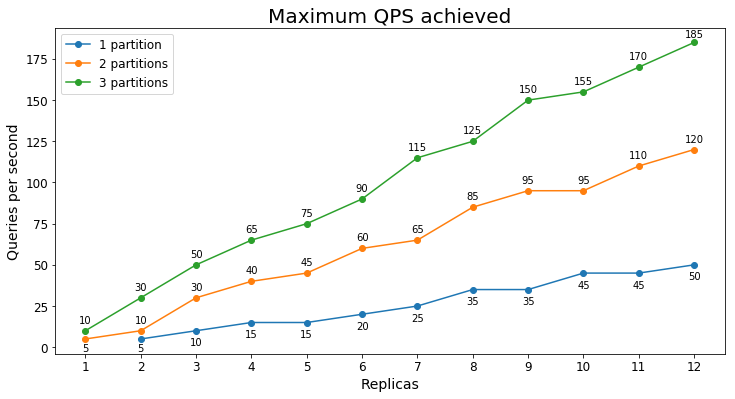
Performances S1
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).
Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 104 ms | 35 ms | 115 ms | 177 ms | 257 ms | 738 ms |
| 50 % | 140 ms | 47 ms | 144 ms | 241 ms | 400 ms | 1175 ms |
| 80 % | 239 ms | 77 ms | 248 ms | 466 ms | 763 ms | 1752 ms |
Performances S2
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).

Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 56 ms | 21 ms | 68 ms | 106 ms | 132 ms | 210 ms |
| 50 % | 71 ms | 26 ms | 83 ms | 132 ms | 177 ms | 329 ms |
| 80 % | 140 ms | 47 ms | 153 ms | 293 ms | 452 ms | 924 ms |
Performances S3
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).
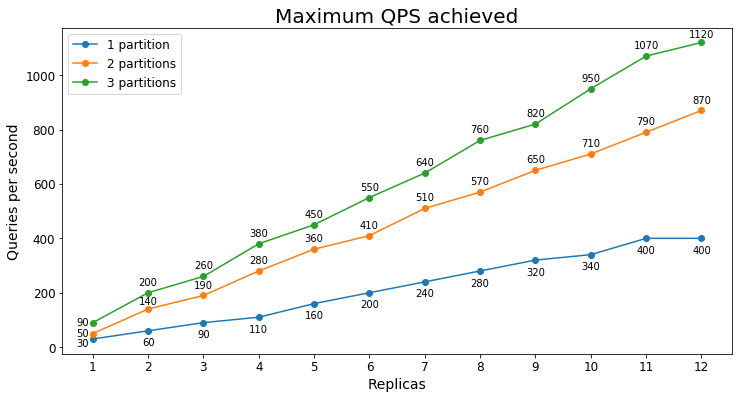
Dans ce cas, nous constatons que l’ajout d’une deuxième partition augmente considérablement le nombre maximal de RPS, mais l’ajout d’une troisième partition permet de réduire le nombre de retours marginaux. L’amélioration plus modeste est probablement due au fait que toutes les données sont déjà extraites dans la mémoire active de S3 avec seulement deux partitions.
Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 50 ms | 20 ms | 64 ms | 83 ms | 98 ms | 160 ms |
| 50 % | 62 ms | 24 ms | 80 ms | 107 ms | 130 ms | 253 ms |
| 80 % | 115 ms | 38 ms | 121 ms | 218 ms | 352 ms | 828 ms |
Test 2 : Recherche de documents
Détails sur le scénario
- Nombre de documents : 7,5 millions
- Taille de l’index : 22 Go
- Schéma d’index : 23 champs, 8 pouvant faire l’objet d’une recherche, 10 filtrables/à choix multiples
- Types de requêtes : recherches par mot clé avec choix multiple et mise en surbrillance des correspondances
Performances S1
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).

Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 67 ms | 44 ms | 77 ms | 103 ms | 126 ms | 216 ms |
| 50 % | 93 ms | 59 ms | 110 ms | 150 ms | 184 ms | 304 ms |
| 80 % | 150 ms | 96 ms | 184 ms | 248 ms | 297 ms | 424 ms |
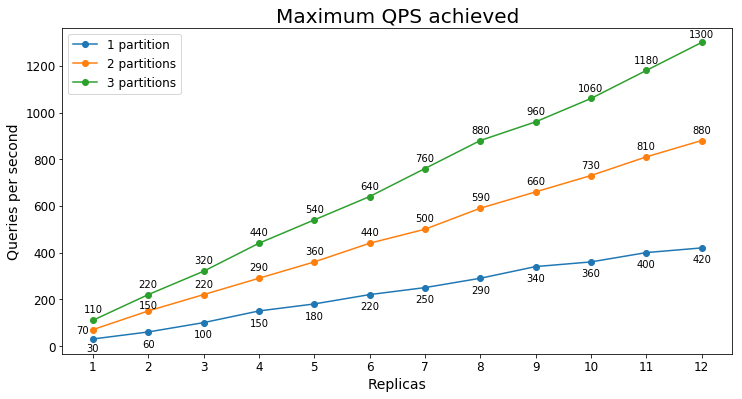
Performances S2
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).
Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 45 ms | 31 ms | 55 ms | 73 ms | 84 ms | 109 ms |
| 50 % | 63 ms | 39 ms | 81 ms | 106 ms | 123 ms | 163 ms |
| 80 % | 115 ms | 73 ms | 145 ms | 191 ms | 224 ms | 291 ms |
Performances S3
Requêtes par seconde
Le tableau suivant montre la charge de requêtes la plus élevée qu’un service peut traiter pendant une période prolongée en requêtes par seconde (RPS).
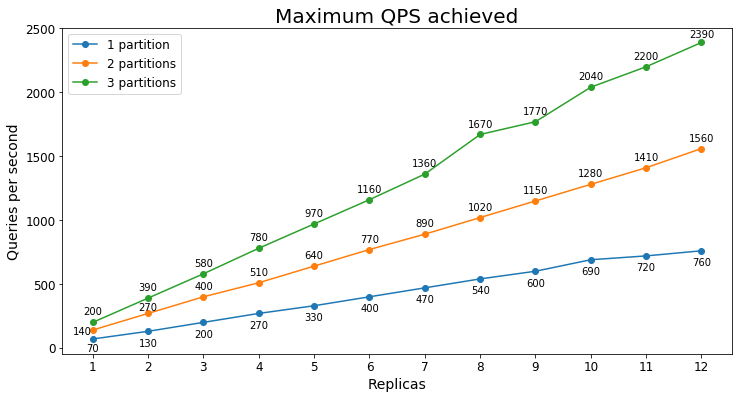
Latence des requêtes
La latence des requêtes varie en fonction de la charge du service, et les services soumis à une forte sollicitation ont une latence moyenne de requête plus élevée. Le tableau suivant montre les 25e, 50e, 75e, 90e, 95e et 99e centiles de la latence des requêtes pour trois niveaux d’utilisation différents.
| Pourcentage du nombre maximal de RPS | Latence moyenne | 25 % | 75 % | 90 % | 95 % | 99 % |
|---|---|---|---|---|---|---|
| 20 % | 43 ms | 29 ms | 53 ms | 74 ms | 86 ms | 111 ms |
| 50 % | 65 ms | 37 ms | 85 ms | 111 ms | 128 ms | 164 ms |
| 80 % | 126 ms | 83 ms | 162 ms | 205 ms | 233 ms | 281 ms |
Éléments importants à retenir
Grâce à ces tests, vous pouvez vous faire une idée des performances de Recherche Azure AI. Vous pouvez également voir la différence entre les services à différents niveaux.
Voici quelques-uns des points à retenir de ces tests :
- S2 peut généralement gérer au moins quatre fois le volume de requêtes par rapport à S1
- S2 présente généralement une latence inférieure à celle de S1 à des volumes de requêtes comparables
- À mesure que vous ajoutez des réplicas, le nombre de RPS qu’un service peut gérer est généralement mis à l’échelle de manière linéaire (par exemple, si un réplica peut gérer 10 RPS, alors cinq réplicas peuvent généralement gérer 50 RPS)
- Plus la charge sur le service est élevée, plus la latence moyenne est élevée
Vous pouvez également voir que les performances peuvent varier considérablement entre les scénarios. Si vous n’obtenez pas les performances attendues, consultez les conseils pour obtenir de meilleures performances.
Étapes suivantes
Maintenant que vous avez vu les tests de performances, vous pouvez en apprendre plus sur l’analyse des performances et les facteurs clés de Recherche Azure AI qui influencent les performances.