Analyser les performances dans Azure AI Recherche
Cet article décrit les outils, les comportements et les approches permettant d’analyser les performances de requête et d’indexation dans Azure AI Recherche.
Déterminer des valeurs de référence
Dans toute implémentation importante, il est essentiel d’effectuer un test d’évaluation des performances de votre service Azure AI Recherche avant de le mettre en production. Vous devez tester non seulement le chargement de la requête de recherche à laquelle vous vous attendez, mais aussi les charges de travail prévues pour l’ingestion des données (si possible, exécutez les deux charges de travail simultanément). Le fait de disposer de chiffres de référence permet de valider le niveau de recherche approprié, la configuration du service et la latence des requêtes attendue.
Pour développer des points de référence, nous vous recommandons l’outil azure-search-performance-testing (GitHub).
Pour isoler les effets d’une architecture de service distribué, essayez de tester les configurations de service d’un réplica et d’une partition.
Remarque
Pour les niveaux à stockage optimisé (L1 et L2), attendez-vous à un plus faible débit des requêtes et à une latence plus élevée que les niveaux Standard.
Utiliser la journalisation des ressources
L’outil de diagnostic le plus important à la disposition d’un administrateur est la journalisation des ressources. La journalisation des ressources est la collecte de données opérationnelles et de métriques sur votre service de recherche. La journalisation des ressources est activée par Azure Monitor. L’utilisation d’Azure Monitor et le stockage des données entraînent des coûts, mais, si vous activez la journalisation pour votre service, elle peut être utile pour étudier les problèmes de performances.
L’image suivante montre la chaîne d’événements dans une requête et la réponse à cette requête. Une période de latence peut se produire à n’importe quelle étape, que ce soit lors d’un transfert réseau, du traitement du contenu dans la couche des services d’application ou sur un service de recherche. L’un des principaux avantages de la journalisation des ressources est que les activités sont consignées du point de vue du service de recherche, ce qui signifie que le journal peut vous aider à déterminer si les problèmes de performances sont dus à des problèmes liés à la requête ou à l’indexation ou à un autre point de défaillance.
La journalisation des ressources vous permet de stocker les informations consignées. Nous vous recommandons d’utiliser Log Analytics pour pouvoir exécuter des requêtes Kusto avancées sur les données afin de répondre à de nombreuses questions sur l’utilisation et les performances.
Sur les pages du portail de votre service de recherche, vous pouvez activer la journalisation par le biais de Paramètres de diagnostic, puis émettre des requêtes Kusto sur Log Analytics en choisissant Journaux. Pour plus d’informations sur la configuration, consultez Collecter et analyser les données de journal.
Comportement de limitation
La limitation se produit lorsque le service de recherche est à pleine capacité. La limitation peut se produire pendant les requêtes ou l’indexation. Du côté client, un appel d’API génère une réponse HTTP 503 lorsqu’il a été limité. Pendant l’indexation, il est également possible de recevoir une réponse HTTP 207, qui indique qu’un ou plusieurs éléments n’ont pas pu être indexés. Cette erreur indique que le service de recherche est proche de sa capacité maximale.
En règle générale, essayez de quantifier le niveau de limitation et les modèles. Par exemple, si une requête de recherche sur 500 000 est limitée, il peut être préférable de ne pas s’en préoccuper. En revanche, si un pourcentage élevé de requêtes est limité sur une période donnée, le problème est plus important. En examinant la limitation sur une période donnée, vous pouvez également identifier les périodes où la limitation est le plus susceptible de se produire et décider de la meilleure façon d’y faire face.
Une solution simple à la plupart des problèmes de limitation consiste à fournir davantage de ressources au service de recherche (généralement des réplicas pour la limitation de requêtes ou des partitions pour la limitation de l’indexation). Toutefois, l’augmentation du nombre de réplicas ou de partitions entraîne un coût supplémentaire. C’est pourquoi il est important de connaître la raison pour laquelle la limitation se produit. L’étude des conditions à l’origine de la limitation sera expliquée dans les sections suivantes.
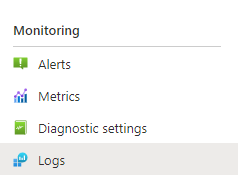
Voici un exemple de requête Kusto qui peut identifier la décomposition des réponses HTTP du service de recherche qui a été sous charge. Sur une période de 7 jours, le graphique à barres montre qu’un pourcentage relativement important des requêtes de recherche a été limité, par rapport au nombre de réponses réussies (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
L’examen de la limitation sur une période spécifique peut vous aider à identifier les moments où la limitation est la plus fréquente. Dans l’exemple ci-dessous, un graphique de série chronologique est utilisé pour montrer le nombre de requêtes limitées sur une période donnée. Dans ce cas, les requêtes limitées sont en corrélation avec les moments où le point de référence des performances a été effectué.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart

Mesurer des requêtes individuelles
Dans certains cas, il peut être utile de tester des requêtes individuelles pour voir comment elles se comportent. Pour ce faire, il est important de connaître la durée nécessaire au service de recherche pour terminer le travail, ainsi que le temps nécessaire à la requête pour faire l’aller-retour à partir du client. Les journaux de diagnostic peuvent être utilisés pour rechercher des opérations individuelles, mais il peut être plus facile de le faire à partir d’un client REST.
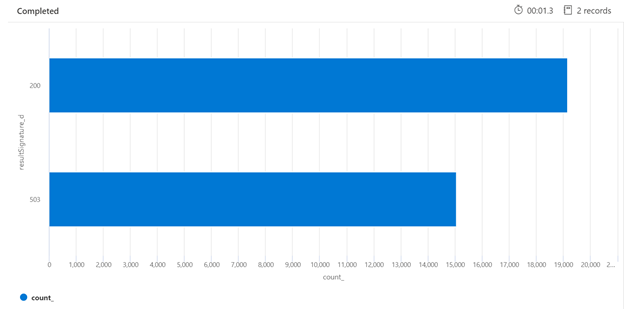
Dans l’exemple ci-dessous, une requête de recherche basée sur REST a été exécutée. Azure AI Recherche inclut dans chaque réponse le nombre de millisecondes nécessaires pour terminer la requête, visible dans l’onglet En-têtes, dans « elapsed-time ». À côté de l’état en haut de la réponse, vous trouverez la durée de l’aller-retour ; dans ce cas, 418 millisecondes (ms). Dans la section des résultats, l’onglet « En-têtes » a été choisi. En utilisant ces deux valeurs mises en évidence par un encadré rouge dans l’image ci-dessous, nous voyons que le service de recherche a mis 21 ms pour terminer la requête de recherche et que l’intégralité de la requête aller-retour du client a mis 125 ms. En soustrayant ces deux chiffres, nous pouvons déterminer qu’il a fallu 104 ms supplémentaires pour transmettre la requête de recherche au service de recherche et pour transférer les résultats de la recherche au client.
Cette technique vous aide à isoler les latences réseau d’autres facteurs impactant les performances des requêtes.
Taux de requêtes
L’une des raisons possibles pour lesquelles votre service de recherche doit limiter les requêtes est le nombre de requêtes exécutées, le volume étant exprimé en requêtes par seconde (QPS) ou en requêtes par minute (QPM). Lorsque votre service de recherche reçoit plus de QPS, il prend généralement de plus en plus de temps pour répondre à ces requêtes jusqu’à ce qu’il ne puisse plus suivre, auquel cas il renvoie une réponse HTTP 503 de limitation.
La requête Kusto suivante montre le volume de requêtes mesuré en QPM, ainsi que la durée moyenne d’une requête en millisecondes (AvgDurationMS) et le nombre moyen de documents (AvgDocCountReturned) renvoyés pour chacune d’elles.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart

Conseil
Pour révéler les données sous-jacentes à ce graphique, supprimez la ligne | render timechart, puis réexécutez la requête.
Impact de l’indexation sur les requêtes
Un facteur important à prendre en compte lors de l’examen des performances est que l’indexation utilise les mêmes ressources que les requêtes de recherche. Si vous indexez une grande quantité de contenu, vous pouvez vous attendre à observer une augmentation de la latence, car le service tente de prendre en compte les deux charges de travail.
Si les requêtes ralentissent, regardez l’heure de l’activité d’indexation pour déterminer si elle coïncide avec le moment où les requêtes se sont dégradées. Par exemple, un indexeur exécute peut-être un travail quotidien ou horaire qui correspond à la baisse des performances des requêtes de recherche.
Cette section fournit un ensemble de requêtes qui peuvent vous aider à visualiser les taux de recherche et d’indexation. Dans ces exemples, l’intervalle de temps est défini dans la requête. Veillez à indiquer Défini dans la requête lorsque vous exécutez les requêtes dans le portail Azure.
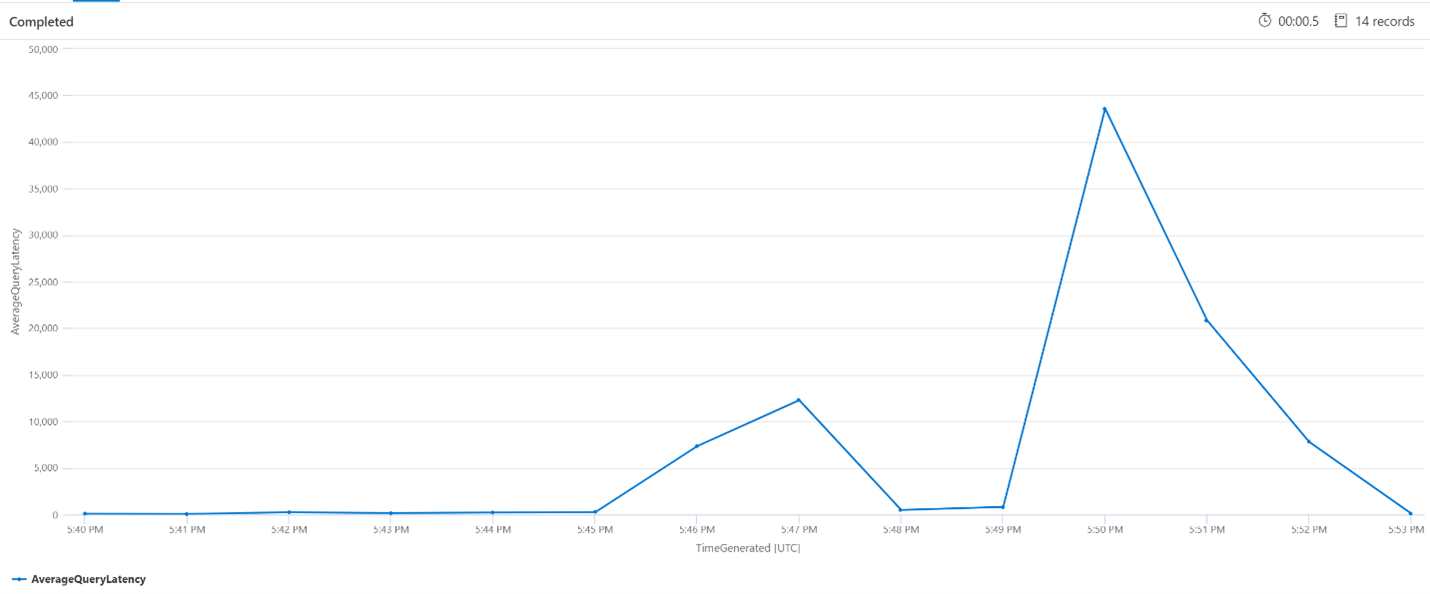
Latence moyenne des requêtes
Dans la requête ci-dessous, un intervalle d’une minute est utilisé pour montrer la latence moyenne des requêtes de recherche. Le graphique montre que la latence moyenne était faible jusqu’à 17 h 45 et a duré jusqu’à 17 h 53.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
Nombre moyen de requêtes par minute (QPM)
La requête suivante examine le nombre moyen de requêtes par minute pour vérifier que les demandes de recherche n’ont pas fait l’objet d’un pic qui aurait pu affecter la latence. Sur le graphique, nous pouvons voir qu’il y a une certaine variation, mais rien qui indique un pic dans le nombre de demandes.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart

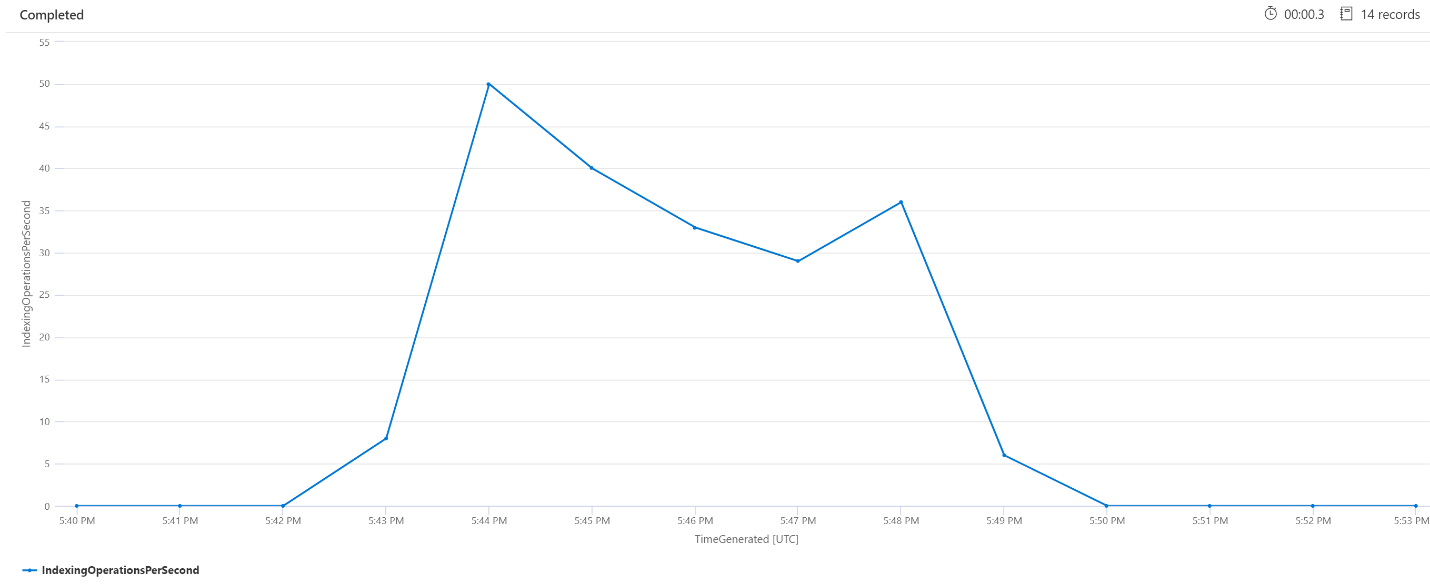
Opérations d’indexation par minute (OPM)
Nous allons examiner ici le nombre d’opérations d’indexation par minute. Le graphique montre qu’une grande quantité de données a été indexée entre 17 h 42 et 17 h 50. Cette indexation a commencé trois minutes avant que la latence des requêtes de recherche commence à augmenter et s’est terminée trois minutes avant que la latence des requêtes de recherche redevienne faible.
Cet insight nous permet de voir qu’il a fallu environ trois minutes pour que le service de recherche devienne suffisamment sollicité pour que l’indexation affecte la latence des requêtes. Nous pouvons également constater qu’une fois l’indexation terminée, il a fallu encore trois minutes au service de recherche pour terminer tout le travail dû au contenu nouvellement indexé et pour résoudre la latence des requêtes.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Traitement du service en arrière-plan
Il n’est pas rare d’observer des pics périodiques dans la latence des requêtes ou de l’indexation. Ces pics peuvent se produire en réponse à l’indexation ou à des taux de requête élevés, mais aussi lors d’opérations de fusion. Les index de recherche sont stockés dans des blocs, aussi appelés partitions. Régulièrement, le système fusionne les plus petites partitions en grandes partitions, ce qui peut aider à optimiser les performances du service. Ce processus de fusion nettoie également les documents qui ont été précédemment marqués pour être supprimés de l’index, ce qui permet de récupérer de l’espace de stockage.
La fusion de partitions est rapide, mais elle est également gourmande en ressources et peut donc potentiellement dégrader les performances du service. Si vous constatez de courtes périodes de latence des requêtes et que ces périodes coïncident avec des modifications récentes du contenu indexé, vous pouvez supposer que la latence est due aux opérations de fusion des partitions.
Étapes suivantes
Passez en revue ces articles liés à l’analyse des performances du service.