Bonnes pratiques d’utilisation d’Azure Data Lake Storage Gen2
Cet article présente les bonnes pratiques qui vous permettent d’optimiser les performances, de réduire les coûts et de sécuriser votre compte de stockage Azure compatible avec Data Lake Storage Gen2.
Pour obtenir des suggestions générales concernant la structure d’un lac de données, consultez les articles suivants :
- Vue d’ensemble d’Azure Data Lake Storage pour le scénario de gestion et d’analytique des données
- Provisionner trois comptes Azure Data Lake Storage Gen2 pour chaque zone d’atterrissage des données
Rechercher de la documentation
Azure Data Lake Storage Gen2 n’est ni un type de compte ni un service dédié. Il s’agit d’un ensemble de fonctionnalités qui prennent en charge des charges de travail analytiques à débit élevé. La documentation Data Lake Storage Gen2 présente les bonnes pratiques et des conseils pour l’utilisation de ces fonctionnalités. Pour tous les autres aspects de la gestion des comptes, tels que la configuration de la sécurité réseau, la conception pour la haute disponibilité et la récupération d’urgence, consultez le contenu de la documentation sur le stockage d’objets blob.
Évaluer la prise en charge des fonctionnalités et problèmes connus
Utilisez le modèle suivant lorsque vous configurez votre compte de manière à utiliser les fonctionnalités de stockage d’objets Blob.
Consultez l’article Prise en charge des fonctionnalités de stockage Blob dans les comptes de stockage Azure pour déterminer si une fonctionnalité est entièrement prise en charge dans votre compte. Certaines fonctionnalités ne sont pas encore prises en charge ou bénéficient d’une prise en charge partielle dans les comptes compatibles avec Data Lake Storage Gen2. La prise en charge des fonctionnalités est en constante évolution. Veillez donc à consulter régulièrement cet article pour découvrir les mises à jour.
Consultez l’article Problèmes connus avec Azure Data Lake Storage Gen2 pour déterminer s’il existe des limitations ou des conseils spécifiques relatifs à la fonctionnalité que vous envisagez d’utiliser.
Recherchez des articles sur les fonctionnalités pour obtenir des conseils spécifiques aux comptes compatibles avec Data Lake Storage Gen2.
Comprendre les termes utilisés dans la documentation
En passant d’un ensemble de contenu à l’autre, vous remarquez quelques légères différences terminologiques. Par exemple, le contenu proposé dans la Documentation Stockage Blobutilise le terme blob au lieu de fichier. Techniquement, les fichiers que vous ingérez dans votre compte de stockage deviennent des objets Blob dans votre compte. Par conséquent, le terme est correct. Toutefois, le terme blob peut prêter à confusion si vous êtes habitué au terme fichier. Vous verrez également le terme conteneur, utilisé pour faire référence à un système de fichiers. Considérez ces termes comme des synonymes.
Envisager Premium
Si vos charges de travail nécessitent une latence faible et cohérente et/ou nécessitent un nombre élevé d’opérations d’entrée/sorties par seconde (IOP), envisagez d’utiliser un compte de stockage d’objets blob de blocs Premium. Ce type de compte rend les données disponibles à l’aide de matériel hautes performances. Les données sont stockées sur des disques SSD optimisés pour une latence faible. Les disques SSD offrent un débit plus élevé que les disques durs traditionnels. Les coûts de stockage des performances Premium sont plus élevés, mais les coûts des transactions sont inférieurs. Donc, si vos charges de travail exécutent un grand nombre de transactions, il peut être économique d’opter pour un compte d’objet blob de blocs Premium.
Si votre compte de stockage doit être utilisé pour l’analytique, nous vous recommandons vivement d’utiliser Azure Data Lake Storage Gen2 avec un compte de stockage d’objets blob de blocs Premium. Cette combinaison d’utilisation de comptes de stockage d’objets blob de blocs Premium avec un compte Data Lake Storage activé est appelée niveau Premium pour Azure Data Lake Storage.
Optimiser pour l’ingestion de données
Lors de l’ingestion de données à partir d’un système source, le matériel source, le matériel réseau source ou la connectivité réseau à votre compte de stockage peut être un goulot d’étranglement.
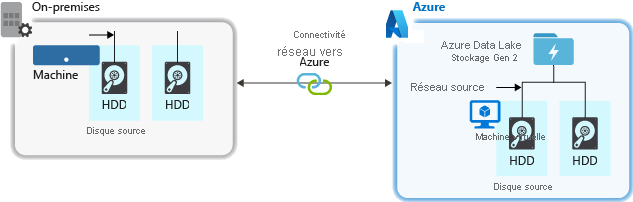
Matériel source
Que vous utilisiez des machines locales ou des machines virtuelles dans Azure, veillez à sélectionner soigneusement le matériel approprié. Pour le matériel de disque, envisagez d’utiliser des disques SSD (Solid State Drive) et de sélectionner le matériel de disque avec des unités plus rapides. Pour le matériel réseau, utilisez les contrôleurs d’interface réseau (NIC) les plus rapides possible. Sur Azure, nous vous recommandons des machines virtuelles Azure D14 qui sont équipées du disque et du matériel de mise en réseau suffisamment puissants.
Vérification de la connectivité réseau au compte de stockage
La connectivité réseau entre vos données sources et votre compte de stockage peut parfois être un goulot d’étranglement. Lorsque vos données sources sont locales, envisagez d’utiliser une liaison dédiée avec Azure ExpressRoute. Si vos données sources sont dans Azure, les performances seront meilleures si les données sont dans la même région Azure que le compte Data Lake Storage Gen2.
Configurer les outils d’ingestion des données pour une parallélisation maximale
Pour obtenir des performances optimales, utilisez tout le débit disponible en effectuant autant de lectures et d’écritures que possible.
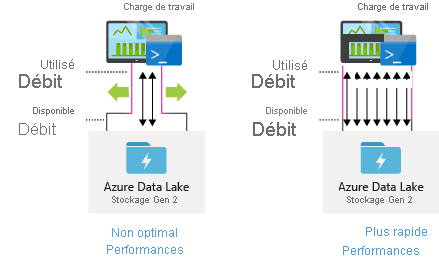
Le tableau suivant résume les paramètres principaux pour plusieurs outils d’ingestion populaires.
| Outil | Paramètres |
|---|---|
| DistCp | -m (mappeur) |
| Azure Data Factory. | parallelCopies |
| Sqoop | fs.azure.block.size, -m (mappeur) |
Notes
Les performances globales de vos opérations d’ingestion dépendent d’autres facteurs spécifiques à l’outil que vous utilisez pour ingérer des données. Pour obtenir l’aide la plus récente, consultez la documentation de chaque outil que vous envisagez d’utiliser.
Votre compte peut être mis à l’échelle afin de fournir le débit nécessaire pour tous les scénarios d’analyse. Par défaut, un compte Data Lake Storage Gen2 fournit suffisamment de débit dans sa configuration par défaut pour répondre aux besoins d’une vaste catégorie de cas d’usage. Si vous utilisez la limite par défaut, le compte peut être configuré pour fournir davantage de débit en contactant le support Azure.
Structurer des jeux de données
Envisagez de planifier préalablement la structure de vos données. Le format de fichier, la taille de fichier et la structure de répertoires peuvent tous avoir un impact sur les performances et les coûts.
Formats de fichiers
Les données peuvent être ingérées sous différents formats. Les données peuvent apparaître dans des formats lisibles par l’homme, tels que JSON, CSV ou XML, ou dans des formats binaires compressés, comme .tar.gz. Les données peuvent également être de différentes tailles. Les données peuvent être composées de fichiers volumineux (quelques téraoctets), tels que les données provenant d’une exportation d’une table SQL à partir de vos systèmes locaux. Les données peuvent également se présenter sous la forme d’un grand nombre de fichiers minuscules (quelques kilo-octets), tels que les données d’événements en temps réel provenant d’une solution Internet des objets (IoT). Vous pouvez optimiser l’efficacité et les coûts en choisissant un format de fichier et une taille de fichier appropriés.
Hadoop prend en charge un ensemble de formats de fichier qui sont optimisés pour le stockage et le traitement des données structurées. Certains formats courants sont Avro, Parquet et le format ORC (Optimized Row Columnar). Tous ces formats sont des formats de fichiers binaires lisibles par un ordinateur. Ils sont compressés pour vous aider à gérer la taille des fichiers. Ils ont un schéma incorporé dans chaque fichier, ce qui leur permet de se décrire de manière autonome. La différence entre les formats réside dans la façon dont les données sont stockées. Avro stocke les données dans un format en lignes, alors que les formats Parquet et ORC stockent des données dans format en colonnes.
Envisagez d’utiliser le format de fichier Avro dans les cas où vos modèles d’E/S sont plus lourds en écriture ou que les modèles de requête favorisent l’extraction de plusieurs lignes d’enregistrements dans leur intégralité. Par exemple, le format Avro fonctionne bien avec un bus de messages, comme Event Hub ou Kafka, qui écrit plusieurs événements/messages à la suite.
Envisagez les formats de fichier Parquet et ORC lorsque les modèles d’E/S sont plus axés sur la lecture ou que les modèles de requête sont concentrés sur un sous-ensemble de colonnes dans les enregistrements Les transactions de lecture peuvent être optimisées pour récupérer des colonnes spécifiques au lieu de lire la totalité de l’enregistrement.
Apache Parquet est un format de fichier Open source qui est optimisé pour les pipelines d’analyse volumineux en lecture. La structure de stockage en colonnes de Parquet vous permet d’ignorer les données non pertinentes. Vos requêtes sont bien plus efficaces, car elles permettent d’étendre de manière étroite les données à envoyer du stockage au moteur d’analyse. En outre, étant donné que les types de données similaires (pour une colonne) sont stockés ensemble, Parquet prend en charge des schémas efficaces de compression et d’encodage des données qui peuvent réduire les coûts de stockage de données. Les services tels que Azure Synapse Analytics, Azure Databricks et Azure Data Factory ont des fonctionnalités natives qui tirent parti des formats de fichiers Parquet.
Taille du fichier
Des fichiers plus volumineux entraînent de meilleures performances et réduisent les coûts.
En règle générale, les moteurs d’analyse tels que HDInsight ont une surcharge par fichier qui implique des tâches, telles que le listage, la vérification de l’accès et l’exécution de diverses opérations de métadonnées. Si vous stockez vos données sous forme de petits fichiers nombreux, cela peut nuire aux performances. En général, organisez vos données en fichiers de plus grande taille pour obtenir de meilleures performances (de 256 Mo à 100 Go). Certains moteurs et applications peuvent avoir des difficultés à traiter efficacement les fichiers supérieurs à 100 Go.
L’augmentation de la taille des fichiers peut également réduire les coûts des transactions. Les opérations de lecture et d’écriture sont facturées par incréments de 4 mégaoctets, de sorte que vous êtes facturé pour l’opération, que le fichier contienne ou non 4 mégaoctets ou seulement quelques kilo-octets. Pour obtenir des informations de tarification, consultez Tarification d’Azure Data Lake Storage.
Parfois, les pipelines de données ont un contrôle limité sur les données brutes qui contiennent un grand nombre de petits fichiers. En général, nous recommandons que votre système dispose d’une sorte de processus permettant d’agréger des fichiers de petite taille en fichiers plus volumineux pour les utiliser dans des applications en aval. Si vous traitez des données en temps réel, vous pouvez utiliser un moteur de diffusion en continu en temps réel (par exemple, Azure Stream Analytics ou Spark streaming) avec un répartiteur de messages (comme Event Hub ou Apache Kafka) pour stocker vos données en tant que fichiers plus volumineux. Au fur et à mesure que vous regroupez des fichiers de petite taille en fichiers plus volumineux, envisagez de les enregistrer dans un format optimisé en lecture comme Apache Parquet pour le traitement en aval.
Structure de répertoires
Chaque charge de travail a des prérequis différents concernant l’utilisation des données, mais vous trouverez ci-dessous des dispositions communes à prendre en compte lorsque vous utilisez des scénarios d’Internet des objets (IoT) ou de traitement, ou encore lors de l’optimisation pour des données de série chronologique.
Structure IoT
Dans des charges de travail IoT peuvent se trouver un grand nombre de données ingérées, couvrant de nombreux produits, appareils, organisations et clients. Il est important de planifier la disposition du répertoire pour des questions d’organisation, de sécurité et de traitement efficace des données pour les consommateurs en aval. Voici un modèle général de disposition à prendre en compte :
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Par exemple, la télémétrie d’arrivée d’un moteur d’avion dans le Royaume-Uni ressemble à la structure suivante :
- UK/Planes/BA1293/Engine1/2017/08/11/12/
Dans cet exemple, en plaçant la date à la fin de la structure de répertoire, vous pouvez utiliser des listes de contrôle d’accès pour sécuriser plus facilement les régions et les sujets à des utilisateurs et des groupes spécifiques. Si vous placez la structure de date au début, il sera bien plus difficile de sécuriser ces régions et sujets. Par exemple, si vous souhaitez fournir un accès uniquement aux données provenant du Royaume-Uni ou à certains plans, vous devez appliquer une autorisation distincte pour de nombreux répertoires sous chaque répertoire horaire. Cette structure augmenterait également de façon exponentielle le nombre de répertoires au fil du temps.
Structure de tâches de traitement par lots
Une approche couramment utilisée dans le traitement par lots consiste à placer les données dans un répertoire « in ». Ensuite, une fois les données traitées, les nouvelles données sont placées dans un répertoire « out » pour que les processus en aval puissent les consommer. Cette structure de répertoire est parfois utilisée pour des travaux qui nécessitent un traitement sur des fichiers individuels et qui ne nécessitent pas forcément de traitement parallèle massif sur des jeux de données volumineux. Tout comme la structure IoT recommandée plus haut, une bonne structure de répertoire dispose de répertoires de niveau parent pour des choses telles que la région et les sujets (par exemple l’organisation, le produit ou le producteur). Tenez compte de la date et de l’heure dans la structure pour permettre une meilleure organisation, des recherches filtrées, la sécurité et l’automatisation du traitement. Le niveau granularité de la structure de date est déterminé par l’intervalle de chargement ou de traitement des données, par exemple à l’heure, quotidien, ou mensuel.
Parfois le traitement de fichiers échoue en raison de corruption des données ou de formats inattendus. Dans ces cas, une structure de répertoire peut bénéficier d’un dossier /bad dans lequel les fichiers sont déplacés pour une inspection plus approfondie. La tâche de traitement par lots peut aussi gérer le rapport ou la notification de ces fichiers bad en vue d’une intervention manuelle. Considérez la structure de modèle suivante :
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Par exemple, une firme marketing qui reçoit quotidiennement des extraits de données de mises à jour client de la part de leurs clients en Amérique du Nord. Avant et après avoir été traité, il peut ressembler à l’extrait de code suivant :
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Dans le cas courant de traitement des données par lots directement dans des bases de données, telles que des bases de données Hive ou des bases de données SQL traditionnelles, il n’est pas nécessaire d’avoir un répertoire /in ou /out, car la sortie se trouve déjà dans un dossier différent pour la table Hive ou la base de données externe. Par exemple, les extraits quotidiens des clients se trouvent dans leurs répertoires respectifs. Ensuite, un service tel qu’Azure Data Factory, Apache Oozie ou Apache Airflow déclencherait un travail Hive ou Spark quotidien pour traiter et écrire les données dans une table Hive.
Structure de données de séries chronologiques
Pour les charges de travail Hive, le nettoyage de partition de données de série chronologique peut aider certaines requêtes à lire uniquement un sous-ensemble de données, ce qui améliore les performances.
Ces pipelines qui ingèrent des données de série chronologique organisent souvent leurs fichiers selon une dénomination structurée pour les fichiers et les dossiers. Découvrez ci-après un exemple courant de données structurées par date :
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Notez que les informations de date / heure s’affichent à la fois en tant que dossiers et dans le nom de fichier.
Pour la date et l’heure, le modèle suivant est récurrent.
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Là encore, le type d’organisation des dossiers et fichiers sélectionné doit optimiser les plus gros fichiers et un nombre raisonnable de fichiers par dossier.
Configurer la sécurité
Commencez par passer en revue les recommandations de l’article Recommandations de sécurité pour Stockage Blob. Vous allez trouver des recommandations sur la façon de protéger vos données contre la suppression accidentelle ou malveillante, la sécurisation des données derrière un pare-feu et l’utilisation de Microsoft Entra ID comme base de la gestion des identités.
Consultez ensuite l’article Modèle de contrôle d’accès dans Azure Data Lake Storage Gen2 pour obtenir une aide spécifique aux comptes compatibles avec Data Lake Storage Gen2. Cet article vous aide à comprendre comment utiliser des rôles Azure RBAC (contrôle d’accès en fonction du rôle) avec des listes de contrôle d’accès (ACL) pour appliquer des autorisations de sécurité aux répertoires et fichiers de votre système de fichiers hiérarchique.
Ingérer, traiter et analyser
Il existe de nombreuses sources de données et différentes manières d’ingérer ces données dans un compte Data Lake Storage Gen2.
Par exemple, vous pouvez ingérer de grands jeux de données à partir de clusters HDInsight et Hadoop, ou de plus petits jeux de données ad hoc pour le prototypage d’applications. Vous pouvez ingérer des données diffusées en continu qui sont générées par diverses sources, telles que des applications, des appareils et des capteurs. Pour ce type de données, vous pouvez utiliser des outils qui capturent et traitent généralement les données événement par événement en temps réel, puis écrivent les événements par lots dans votre compte. Vous pouvez également ingérer des journaux d’activité de serveur web qui contiennent des informations telles que l’historique des requêtes de pages. Pour les données de journal, envisagez d’écrire des scripts ou des applications personnalisés pour charger ces données. Vous aurez ainsi la possibilité d’inclure votre composant de chargement de données dans le cadre de votre application Big Data plus volumineuse.
Une fois les données disponibles dans votre compte, vous pouvez exécuter l’analyse sur ces données, créer des visualisations et même télécharger des données sur votre ordinateur local ou dans d’autres référentiels, tels qu’une base de données Azure SQL ou SQL Server instance.
Le tableau suivant recommande des outils que vous pouvez utiliser pour ingérer, analyser, visualiser et télécharger des données. Utilisez les liens de ce tableau pour obtenir des instructions sur la configuration et l’utilisation de chaque outil.
| Objectif | Outils et conseils |
|---|---|
| Ingérer des données ad hoc | Portail Azure, Azure PowerShell, Azure CLI, REST, Explorateur Stockage Azure, Apache DistCp, AzCopy |
| Ingérer des données relationnelles | Azure Data Factory. |
| Ingérer des journaux d’activité de serveur web | Azure PowerShell, Azure CLI, REST, kits de développement logiciel (SDK) Azure (.NET, Java, Pythonet Node.js), Azure Data Factory |
| Ingérer à partir des clusters HDInsight | Azure Data Factory, Apache DistCp, AzCopy |
| Ingérer à partir des clusters Hadoop | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator pour Azure, Azure Data Box |
| Ingérer des jeux de données volumineux (plusieurs téraoctets) | Azure ExpressRoute |
| Traiter et analyser les données | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Visualiser les données | Power BI, Accélération des requêtes Azure Data Lake Storage |
| Télécharger des données | Portail Azure, PowerShell, Azure CLI, REST, kits de développement logiciel (SDK) Azure (.NET, Java, Python et Node.js), Explorateur Stockage Azure, AzCopy, Azure Data Factory, Apache DistCp |
Notes
Ce tableau n’est pas une liste exhaustive des services Azure qui prennent en charge Data Lake Storage Gen2. Pour voir la liste des services Azure pris en charge, leur niveau de support, consultez Services Azure qui prennent en charge Azure Data Lake Storage Gen2.
Surveiller la télémétrie
La surveillance de l’utilisation et des performances est un élément important de l’opérationnalisation de votre service. Il peut s’agir d’opérations fréquentes, d’opérations avec une latence élevée ou d’opérations entraînant une limitation côté service.
Toutes les données de télémétrie de votre compte de stockage sont disponibles via les Journaux de Stockage Azure dans Azure Monitor. Cette fonctionnalité intègre votre compte de stockage avec Log Analytics et Event Hubs, tout en vous permettant d’archiver les journaux dans un autre compte de stockage. Pour consulter la liste complète des journaux de métriques et de ressources et le schéma associé, consultez Informations de référence sur les données de supervision du stockage Azure.
L’emplacement où vous choisissez de stocker vos journaux dépend de la façon dont vous envisagez d’y accéder. Par exemple, si vous souhaitez accéder à vos journaux en temps quasi-réel et être en mesure de mettre en corrélation les événements dans les journaux avec d’autres métriques à partir d’Azure Monitor, vous pouvez stocker vos journaux dans un espace de travail Log Analytics. Ensuite, interrogez vos journaux à l’aide de KQL et de créer des requêtes, qui énumèrent la table StorageBlobLogs dans votre espace de travail.
Si vous souhaitez stocker vos journaux pour une requête en temps quasi-réel et une rétention à long terme, vous pouvez configurer vos paramètres de diagnostic pour envoyer des journaux à un espace de travail Log Analytics et à un compte de stockage.
Si vous souhaitez accéder à vos journaux par le biais d’un autre moteur de requête, tel que Splunk, vous pouvez configurer vos paramètres de diagnostic de manière à envoyer des journaux à un Event Hub et ingérer les journaux de l’Event Hub vers la destination choisie.
Les journaux de Stockage Azure dans Azure Monitor peuvent être activés via le portail Azure, PowerShell, Azure CLI et les modèles Azure Resource Manager. Pour les déploiements à grande échelle, Azure Policy peut être utilisé avec prise en charge complète des tâches de correction. Pour plus d’informations, consultez ciphertxt/AzureStoragePolicy.