Concepts de récupération d’urgence d’Azure Virtual Desktop
Azure Virtual Desktop a considérablement évolué en tant que solution de travail distante et hybride ces dernières années. Étant donné qu’un très grand nombre d’utilisateurs travaillent à distance, les organisations ont besoin de solutions offrant une vitesse de déploiement élevée et des coûts réduits. Les utilisateurs doivent également disposer d’un environnement de travail distant garantissant la disponibilité et la résilience qui leur permettent d’accéder à leurs machines virtuelles même en cas de sinistre. Ce document décrit les plans de récupération d’urgence que nous vous recommandons pour que votre organisation reste opérationnelle.
Pour éviter les pannes ou les temps d’arrêt du système, chaque système et composant de votre déploiement Azure Virtual Desktop doit être tolérant aux pannes. La tolérance aux pannes s’applique lorsque vous disposez d’une configuration ou d’un système en double dans une autre région Azure qui prend le relais de la configuration principale en cas de panne. Cette configuration ou ce système secondaire réduit l’impact d’une panne localisée. Diverses manières de configurer la tolérance aux pannes sont possibles, mais cet article se concentre sur les méthodes actuellement disponibles dans Azure.
Infrastructure d’Azure Virtual Desktop
Pour déterminer les domaines qui doivent être tolérants aux pannes, nous devons tout d’abord savoir qui est responsable de la maintenance de chaque domaine. Vous pouvez répartir la responsabilité dans le service Azure Virtual Desktop entre deux domaines : celui managé par Microsoft et celui managé par le client. Les métadonnées comme les pools d’hôtes, les groupes d’applications et les espaces de travail sont contrôlées par Microsoft. Les métadonnées sont toujours disponibles et ne nécessitent pas de configuration supplémentaire par le client pour répliquer les données ou les configurations du pool d’hôtes. Nous avons conçu l’infrastructure de passerelle qui relie les personnes à leurs hôtes de session pour obtenir un service global et hautement résilient managé par Microsoft. Dans le même temps, les domaines managés par le client impliquent les machines virtuelles utilisées dans Azure Virtual Desktop et les paramètres et configurations uniques au déploiement du client. Le tableau suivant présente plus clairement les domaines managés par chaque partie.
| Gestion par Microsoft | Managé par le client |
|---|---|
| Équilibrage de charge | Réseau |
| Répartiteur de session | Hôtes de session |
| Passerelle | Stockage |
| Diagnostics | Données de profil utilisateur |
| Plateforme d’identité cloud | Identité |
Dans cet article, nous allons nous concentrer sur les composants managés par le client, car ce sont des paramètres que vous pouvez configurer vous-même.
Principes de base de la récupération d’urgence
Dans cette section, nous aborderons les actions et principes de conception qui peuvent protéger vos données et éviter d’énormes efforts de récupération de données après de petites pannes ou des sinistres complets. Pour les pannes plus petites, suivre des étapes plus petites peut permettre d’éviter qu’elles ne deviennent des sinistres plus importants. Abordons certains termes de base qui vous seront utiles lorsque vous commencerez à configurer votre plan de récupération d’urgence.
Lorsque vous concevez un plan de récupération d’urgence, vous devez garder à l’esprit les trois informations suivantes :
- Haute disponibilité : distribution de l’infrastructure de sorte que les pannes plus petites et localisées n’interrompent pas l’ensemble de votre déploiement. Une conception avec la haute disponibilité peut réduire l’impact d’une panne et éviter la nécessité d’une récupération d’urgence complète.
- Continuité de l’activité : comment une organisation peut continuer à fonctionner pendant les pannes de quelque envergure que ce soit.
- Récupération d’urgence : processus de retour au fonctionnement après une panne complète.
Azure dispose de nombreuses fonctionnalités intégrées et gratuites qui peuvent offrir une haute disponibilité à de nombreux niveaux. La première fonctionnalité correspond aux groupes à haute disponibilité, qui distribuent des machines virtuelles entre différents domaines d’erreur et de mise à jour dans Azure. Ensuite, les zones de disponibilité sont des groupes physiquement isolés et géographiquement distribués de centres de données qui peuvent réduire l’impact d’une panne. Enfin, la distribution des hôtes de session sur plusieurs régions Azure offre une distribution encore plus géographique, ce qui réduit davantage l’impact d’une panne. Ces trois fonctionnalités fournissent un certain niveau de protection dans Azure Virtual Desktop, et vous devez les prendre rigoureusement en compte, ainsi que toutes les implications sur les coûts.
En fait, la stratégie de récupération d’urgence que nous recommandons pour Azure Virtual Desktop consiste à déployer des ressources sur plusieurs zones de disponibilité au sein d’une région. Si vous avez besoin de plus de protection encore, vous pouvez également déployer des ressources dans plusieurs régions Azure jumelées.
Déploiements actif/passif et actif/actif
Une autre information que vous devez garder à l’esprit est la différence entre les plans actif/passif et actif/actif. Les plans de type actif/passif conviennent lorsque vous disposez d’une région comprenant un ensemble de ressources actives et d’une autre qui est désactivée jusqu’à ce que vous en ayez besoin (passive). Si la région active est mise hors connexion en cas d’urgence, l’organisation peut basculer vers la région passive en l’activant et en déplaçant tous ses utilisateurs.
Une autre option est le déploiement de type actif/actif, où vous utilisez les deux ensembles d’infrastructure en même temps. Même si certains utilisateurs peuvent être affectés par les pannes, l’impact sera limité aux utilisateurs de la région qui connaît la panne. Les utilisateurs de l’autre région qui sont toujours en ligne ne seront pas affectés, et la reprise d’activité sera limitée aux utilisateurs de la région affectée qui se reconnectent à la région active qui est fonctionnelle. Les déploiements de type actif-actif peuvent prendre de nombreuses formes, notamment :
- Surprovisionner l’infrastructure dans chaque région pour prendre en charge les utilisateurs affectés en cas de panne de l’une des régions. Un inconvénient potentiel de cette méthode est que la gestion des ressources supplémentaires coûte plus cher.
- Avoir des hôtes de session supplémentaires dans les deux régions actives, mais les libérer quand ils ne sont pas nécessaires, ce qui réduit les coûts.
- Provisionner uniquement une nouvelle infrastructure pendant la reprise d’activité et autoriser les utilisateurs affectés à se connecter aux hôtes de session nouvellement provisionnés. Cette méthode nécessite des tests réguliers avec des outils IaC afin de pouvoir déployer la nouvelle infrastructure aussi rapidement que possible lors d’un sinistre.
Méthodes de reprise d’activité après sinistre recommandées
Les méthodes de récupération d’urgence que nous vous recommandons sont les suivantes :
Configurez et déployez des ressources Azure sur plusieurs zones de disponibilité.
Configurez et déployez des ressources Azure dans plusieurs régions dans des configurations de type actif/actif ou actif/passif. Ces configurations se trouvent généralement dans des pools d’hôtes partagés.
Pour les pools d’hôtes personnels avec des machines virtuelles dédiées, répliquez des machines virtuelles à l’aide d’Azure Site Recovery sur une autre région.
Configurez un pool d'hôtes de « reprise après sinistre » distinct dans la région secondaire. Lors d’un sinistre, vous pouvez basculer les utilisateurs vers la région secondaire.
Dans les sections suivantes, nous allons aborder plus en détail les deux méthodes principales que vous pouvez appliquer aux pools d’hôtes partagés et personnels.
Récupération d’urgence pour les pools d’hôtes partagés
Dans cette section, nous allons aborder les pools d’hôtes partagés (ou « mis en pool ») à l’aide d’une approche de type actif/passif. L’approche actif/passif consiste à diviser les ressources existantes en une région primaire et secondaire. En temps normal, votre organisation effectuerait tout son travail dans la région primaire (ou « active »). Toutefois, lors d’un sinistre, pour basculer vers la région secondaire (ou « passive »), il suffit de désactiver les ressources de la région primaire (si vous pouvez le faire, en fonction de l’étendue de la panne) et d’activer celles de la région secondaire.
Le diagramme suivant montre un exemple de déploiement avec une infrastructure redondante dans une région secondaire. « Redondant » signifie qu’une copie de l’infrastructure d’origine existe dans cette autre région et qu’elle est standard dans les déploiements pour fournir une résilience pour tous les composants. Un même Microsoft Entra ID comporte deux régions : USA Ouest et USA Est. Chaque région comprend deux hôtes de la session exécutant un système d’exploitation multisession, un serveur exécutant Microsoft Entra Connect, un contrôleur de domaine Active Directory, un partage de fichiers Azure Files Premium pour les profils FSLogix, un compte de stockage et un réseau virtuel (VNET). Dans la région primaire, USA Ouest, toutes les ressources sont activées. Dans la région secondaire, USA Est, les hôtes de la session du pool d’hôtes sont désactivés ou en mode maintenance, et le serveur Microsoft Entra Connect est en mode intermédiaire. Les deux réseaux virtuels des deux régions sont connectés par peering.
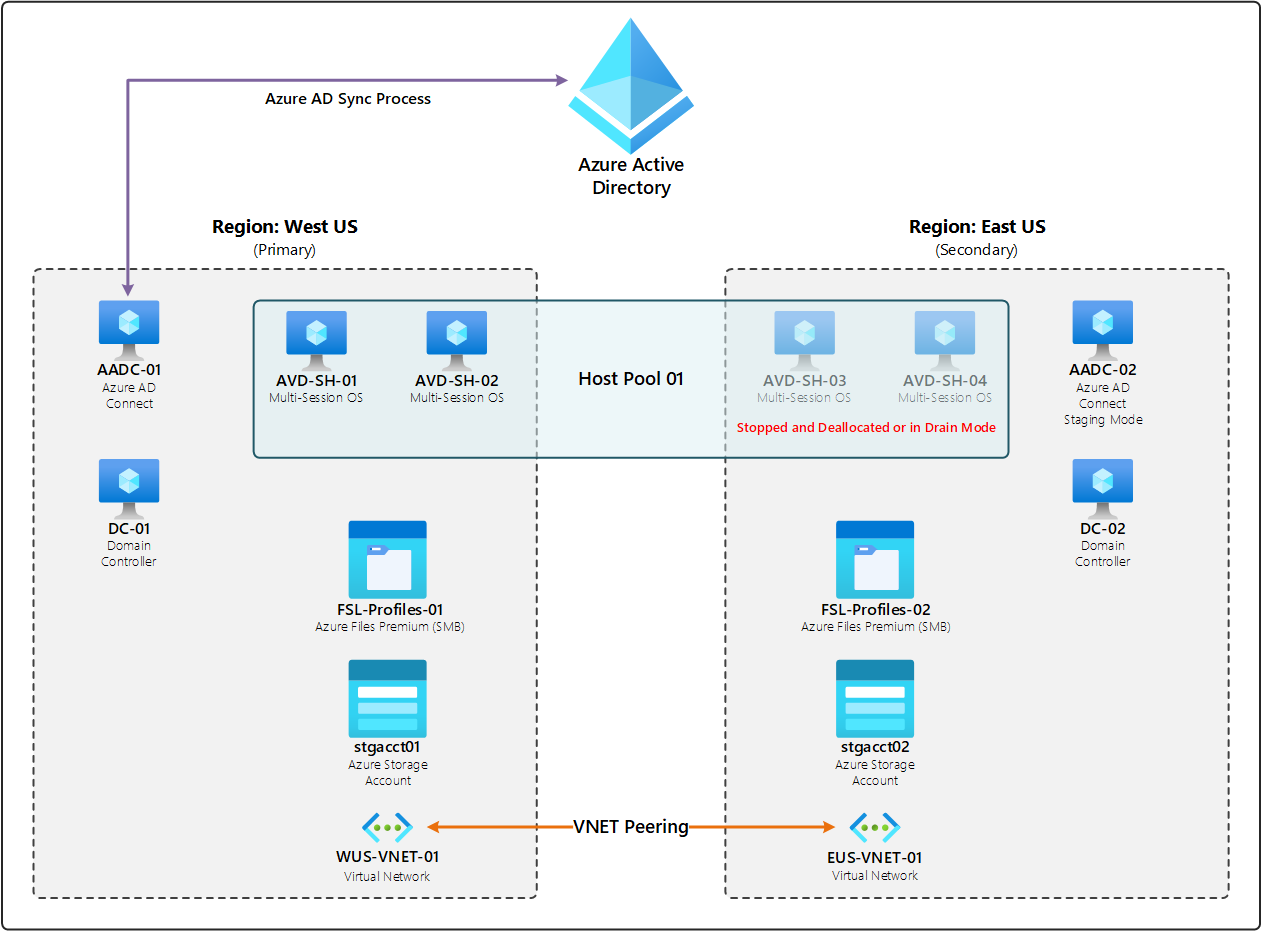
Dans la plupart des cas, si un composant échoue ou si la région primaire n’est pas disponible, la seule action que le client doit effectuer consiste à activer les hôtes ou à supprimer le mode maintenance dans la région secondaire pour activer les connexions d’utilisateur final. Ce scénario vise à réduire les temps d’arrêt. Toutefois, un plan de récupération d’urgence basé sur la redondance peut coûter plus du fait de la nécessité de maintenir ces composants supplémentaires dans la région secondaire.
Les avantages potentiels de ce plan sont les suivants :
- Moins de temps passé à récupérer des sinistres. Par exemple, vous passerez moins de temps sur l’approvisionnement, la configuration, l’intégration et la validation des ressources nouvellement déployées.
- Il n’est pas nécessaire d’utiliser des procédures complexes.
- Il est facile de tester le basculement en dehors de sinistres.
Les inconvénients potentiels sont les suivants :
- Peut coûter plus cher du fait d’une infrastructure à gérer plus conséquente, comme les comptes de stockage, les hôtes, etc.
- Vous devez passer plus de temps à configurer votre déploiement pour prendre en charge ce plan.
- Vous devez maintenir l’infrastructure supplémentaire que vous avez configurée même lorsque vous n’en avez pas besoin.
Informations importantes pour la récupération du pool d’hôtes partagé
Lorsque vous utilisez cette stratégie de récupération d’urgence, il est important de garder à l’esprit les informations suivantes :
La présence de plusieurs hôtes de session en ligne dans de nombreuses régions peut avoir un impact sur l’expérience utilisateur. L’équilibreur de charge réseau managé ne tient pas compte de la proximité géographique, au lieu de traiter tous les hôtes dans un pool d’hôtes de manière égale.
En cas de sinistre, les utilisateurs créent de nouveaux profils dans la région secondaire. Vous devez stocker toutes les données stratégiques ou professionnelles dans OneDrive (à l’aide de la redirection de dossiers connus) ou Dans Sharepoint. Le stockage de données ici permet aux utilisateurs d’accéder rapidement à leurs applications avec une interruption mineure de l’expérience utilisateur.
Assurez-vous de configurer vos machines virtuelles exactement comme dans votre pool d’hôtes. Assurez-vous également que toutes les machines virtuelles au sein de votre pool d’hôtes sont identiques. Si vos machines virtuelles ne sont pas identiques, l’équilibreur de charge réseau managé distribue uniformément les connexions utilisateur entre toutes les machines virtuelles disponibles. Les machines virtuelles plus petites peuvent être contraintes de ressources plus rapidement que prévu par rapport aux machines virtuelles plus volumineuses, ce qui entraîne une expérience utilisateur négative.
La disponibilité de la région affecte la surveillance des données ou de l’espace de travail. Si une région n’est pas disponible, le service peut perdre toutes les données de surveillance historiques en cas de sinistre. Nous vous recommandons d’utiliser une exportation ou un vidage personnalisé des données de surveillance historiques.
Nous vous recommandons de mettre à jour vos hôtes de session au moins une fois par mois. Cette recommandation s’applique aux hôtes de session que vous maintenez désactivés pendant de longues périodes.
Testez votre déploiement en exécutant un basculement contrôlé au moins une fois tous les six mois. Une partie du basculement contrôlé peut signifier que votre emplacement secondaire devient principal jusqu’au basculement contrôlé suivant. La modification de votre emplacement secondaire en emplacement principal permet aux utilisateurs d’avoir des profils presque identiques lors d’un sinistre réel.
Le tableau suivant répertorie les recommandations de déploiement pour les stratégies de récupération d’urgence du pool d’hôtes :
| Technologie | Recommandations |
|---|---|
| Réseau | Créez et déployez un réseau virtuel secondaire dans une autre région et configurez Azure Peering avec votre réseau virtuel principal. |
| Hôtes de session | Créez et déployez un pool d’hôtes partagé Azure Virtual Desktop avec une référence SKU de système d’exploitation multisession et incluez des machines virtuelles à partir d’autres zones de disponibilité et d’une autre région. |
| Stockage | Créez des comptes de stockage dans plusieurs régions à l’aide de comptes de niveau Premium. |
| Données de profil utilisateur | Créez des emplacements de stockage SMB dans plusieurs régions. |
| Identité | Contrôleurs de domaine Active Directory du même répertoire. |
Récupération d’urgence pour les pools d’hôtes personnels
Pour les pools d’hôtes personnels, votre stratégie de récupération d’urgence doit impliquer la réplication de vos ressources vers une région secondaire à l’aide d’Azure Site Recovery Services Vault. Si votre région primaire tombe en panne lors d’un sinistre, Azure Site Recovery peut basculer et activer les ressources dans votre région secondaire.
Par exemple, supposons que nous avons un déploiement avec une région primaire, USA Ouest, et une région secondaire, USA Est. La région primaire comprend un pool d’hôtes personnel avec deux hôtes de session. Chaque hôte de session dispose d’un disque local contenant les données de profil utilisateur et son propre réseau virtuel qui n’est jumelé à rien. En cas de sinistre, vous pouvez utiliser Azure Site Recovery pour basculer vers la région secondaire USA Est (ou vers une autre zone de disponibilité dans la même région). Contrairement à la région primaire, la région secondaire ne comprend pas de machines ou de disques locaux. Pendant le basculement, Azure Site Recovery prend les données répliquées à partir d’Azure Site Recovery Vault et les utilise pour créer deux nouvelles machines virtuelles qui sont des copies des hôtes de session d’origine, y compris les données de disque local et de profil utilisateur. La région secondaire dispose d’un réseau virtuel indépendant, de sorte que le réseau virtuel en ligne dans la région primaire n’affecte pas les fonctionnalités.
Le diagramme suivant montre l’exemple de déploiement que nous venons de décrire.
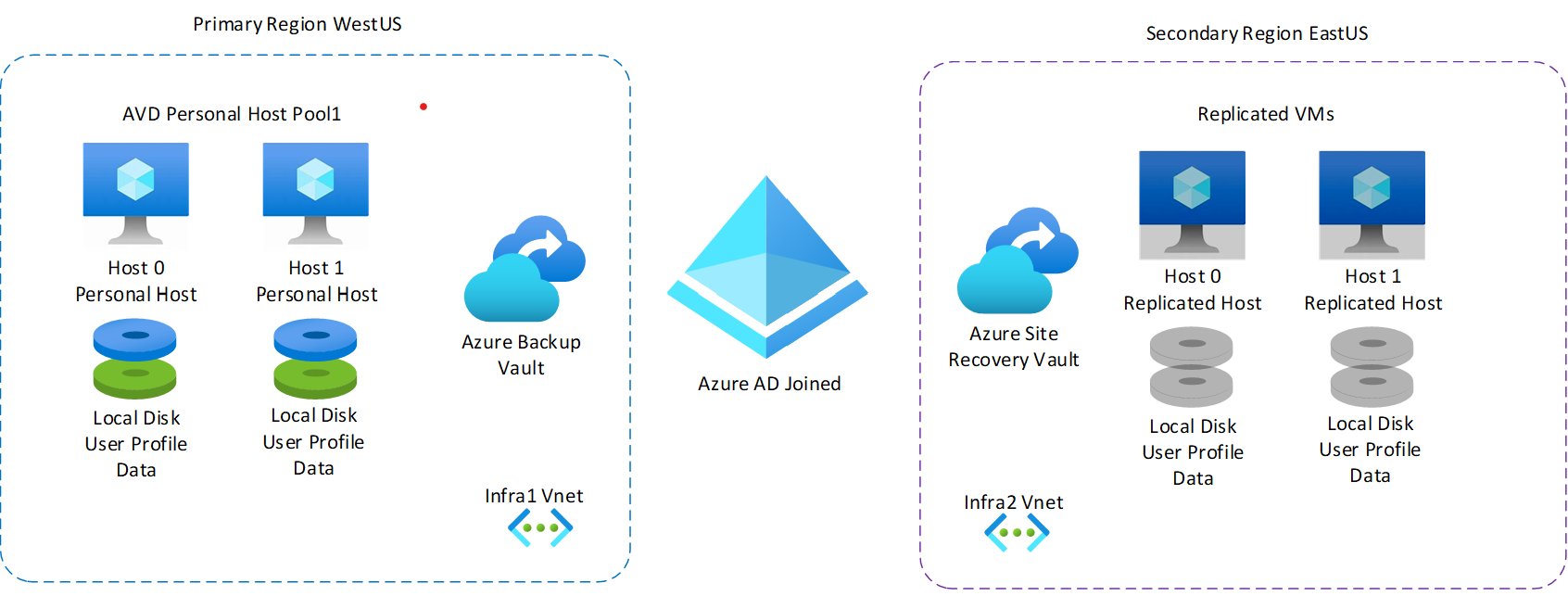
Les avantages de ce plan incluent un coût global inférieur et il ne requiert aucune maintenance de correction ou de mise à jour car les ressources ne sont approvisionnées que lorsque vous en avez besoin. Toutefois, un inconvénient potentiel est que vous passerez plus de temps à approvisionner, intégrer et valider l’infrastructure de basculement qu’avec une configuration de récupération d’urgence de pool d’hôtes partagé.
Informations importantes sur la récupération de pool d’hôtes personnel
Lorsque vous utilisez cette stratégie de récupération d’urgence, il est important de garder à l’esprit les informations suivantes :
Les machines virtuelles du pool d’hôtes devront peut-être s’exécuter dans le site secondaire, comme des réseaux virtuels, des sous-réseaux, la sécurité réseau ou des VPN pour accéder à un annuaire comme un Active Directory local.
Remarque
L’utilisation d’une machine virtuelle jointe à Microsoft Entra répond automatiquement à certaines de ces exigences.
Vous pouvez rencontrer des problèmes d’intégration, de performances ou de contention pour les ressources si un sinistre à grande échelle affecte plusieurs clients ou locataires.
Les pools d’hôtes personnels utilisent des machines virtuelles dédiées à un utilisateur, ce qui signifie que les règles d’équilibrage de charge d’affinité dirigent toutes les sessions utilisateur vers une machine virtuelle spécifique. Ce mappage un-à-un entre l’utilisateur et la machine virtuelle signifie que si une machine virtuelle tombe en panne, l’utilisateur ne pourra pas se connecter tant que la machine virtuelle ne sera pas de nouveau en ligne ou que la machine virtuelle n’aura pas repris après la récupération d’urgence.
Les machines virtuelles dans un pool d’hôtes personnel stockent le profil utilisateur sur le lecteur C, ce qui signifie que FSLogix n’est pas obligatoire.
La disponibilité de la région affecte la surveillance des données ou de l’espace de travail. Si une région n’est pas disponible, le service peut perdre toutes les données de surveillance historiques en cas de sinistre. Nous vous recommandons d’utiliser une exportation ou un vidage personnalisé des données de surveillance historiques.
Nous vous recommandons d’éviter d’utiliser FSLogix avec une configuration de pool d’hôtes personnel.
L’approvisionnement de machines virtuelles n’est pas garanti dans la région de basculement.
Exécutez les tests de basculement contrôlé et de restauration automatique au moins une fois tous les six mois.
Le tableau suivant répertorie les recommandations de déploiement pour les stratégies de récupération d’urgence du pool d’hôtes :
| Technologie | Recommandations |
|---|---|
| Réseau | Créez et déployez un réseau virtuel secondaire dans une autre région pour suivre des conventions d’affectation de noms personnalisées ou des exigences de sécurité en dehors du schéma d’affectation de noms par défaut d’Azure Site Recovery. |
| Hôtes de session | Activez et configurez Azure Site Recovery pour les machines virtuelles. Si vous le souhaitez, vous pouvez préparer une image manuellement ou utiliser le service Azure Image Builder pour l’approvisionnement en cours. |
| Stockage | La création d’un compte stockage Azure pour stocker des profils est facultative. |
| Données de profil utilisateur | Les données de profil utilisateur sont stockées localement sur le lecteur C. |
| Identité | Contrôleurs de domaine Active Directory du même annuaire dans plusieurs régions. |
Étapes suivantes
Pour plus d’informations détaillées sur la récupération d’urgence dans Azure, consultez les articles suivants :