DirectQuery dans Power BI
Dans Power BI Desktop ou le service Power BI, vous pouvez vous connecter à de nombreuses sources de données différentes de différentes manières. Vous pouvez importer des données dans Power BI, ce qui est la méthode la plus courante pour obtenir des données. Vous pouvez également vous connecter directement à certaines données dans leur référentiel source d’origine, appelé DirectQuery. Cet article traite principalement des fonctionnalités de DirectQuery.
Cet article aborde les points suivants :
- Différentes options de connectivité de données Power BI.
- Conseils sur le moment où utiliser DirectQuery plutôt que l’importation.
- Limitations et implications de l’utilisation de DirectQuery.
- Recommandations pour une utilisation réussie de DirectQuery.
- Comment diagnostiquer les problèmes de performances DirectQuery.
L’article se concentre sur le flux de travail DirectQuery lorsque vous créez un rapport dans Power BI Desktop, mais traite également de la connexion via DirectQuery dans le service Power BI.
Notes
DirectQuery est également une fonctionnalité de SQL Server Analysis Services. Cette fonctionnalité partage de nombreux points communs avec Direct Query dans Power BI, mais il existe également d’importantes différences. Cet article a principalement trait à DirectQuery avec Power BI, non à SQL Server Analysis Services.
Pour plus d’informations sur l’utilisation de DirectQuery avec SQL Server Analysis Services, consultez Utiliser DirectQuery pour les modèles sémantiques Power BI et Analysis Services (préversion). Vous pouvez également télécharger le PDF sur DirectQuery dans SQL Server 2016 Analysis Services.
Modes de connectivité de données Power BI
Power BI se connecte à un vaste éventail de sources de données, notamment :
- Services en ligne tels que Salesforce et Dynamics 365.
- Bases de données telles que SQL Server, Access et Amazon Redshift.
- Fichiers simples dans Excel, JSON et d’autres formats.
- Autres sources de données telles que Spark, sites web et Microsoft Exchange.
Vous pouvez importer des données à partir de ces sources dans Power BI. Pour certaines sources, vous pouvez également vous connecter à l’aide de DirectQuery. Pour obtenir un récapitulatif des sources compatibles avec DirectQuery, consultez Sources de données prises en charge par DirectQuery. Les sources compatibles avec DirectQuery sont principalement des sources qui peuvent fournir de bonnes performances de requêtes interactives.
Nous vous recommandons d’importer des données dans Power BI chaque fois que c’est possible. L’importation tire parti du moteur de requête hautes performances de Power BI et vous offre une expérience très interactive et complète.
Si vous ne parvenez pas à atteindre vos objectifs en important des données, par exemple si les données changent fréquemment et que les rapports doivent refléter les données les plus récentes, envisagez d’utiliser DirectQuery. L’utilisation de DirectQuery n’est possible que si la source de données sous-jacente peut fournir des résultats de requêtes interactifs en moins de 5 secondes pour une requête d’agrégation type et qu’elle peut gérer la charge de requête générée. Examinez attentivement les limitations et les implications de l’utilisation de DirectQuery.
Les fonctionnalités d’importation Power BI et DirectQuery évoluent au fil du temps. Les modifications qui offrent plus de flexibilité lors de l’utilisation de données importées vous permettent d’importer plus souvent et d’éliminer certains des inconvénients de l’utilisation de DirectQuery. Quelles que soient les améliorations, en cas d’utilisation de DirectQuery, les performances de la source de données sous-jacente sont une considération majeure. Si une source de données sous-jacente est lente, l’utilisation de DirectQuery pour cette source demeure impossible.
Les sections suivantes couvrent les trois options de connexion aux données : importation, DirectQuery et connexion active. Le reste de l’article se concentre sur DirectQuery.
Connexions d’importation
Lorsque vous vous connectez à une source de données comme SQL Server et importez des données dans Power BI Desktop, les résultats suivants se produisent :
Lorsque vous obtenez initialement des données, chaque jeu de tables que vous sélectionnez définit une requête qui retourne un ensemble de données. Vous pouvez modifier ces requêtes avant le chargement des données, par exemple pour appliquer des filtres, agréger les données ou joindre des tables différentes.
Lors du chargement, toutes les données définies par ces requêtes sont importées dans le cache Power BI.
La création d’un visuel dans Power BI Desktop interroge les données mises en cache. Le magasin Power BI garantit que la requête est rapide et toutes les modifications apportées au visuel sont immédiatement reflétées.
Les visuels ne reflètent pas les modifications apportées aux données sous-jacentes dans le magasin de données. Vous devez réimporter pour actualiser les données.
La publication du rapport dans le service Power BI en tant que fichier .pbix crée et charge un modèle sémantique qui inclut les données importées. Vous pouvez ensuite programmer l’actualisation des données, par exemple réimporter les données tous les jours. Selon l’emplacement de la source de données d’origine, il peut être nécessaire de configurer une passerelle de données locale pour l’actualisation.
Lors de l’ouverture d’un rapport existant ou de la création d’un rapport dans le service Power BI , les données importées sont de nouveau interrogées, ce qui garantit l’interactivité.
Vous pouvez épingler des visuels ou des pages de rapport entières sous forme de vignettes de tableau de bord dans le service Power BI. Les vignettes s’actualisent automatiquement chaque fois que le modèle sémantique sous-jacent est actualisé.
Connexions DirectQuery
Lorsque vous utilisez DirectQuery pour vous connecter à une source de données dans Power BI Desktop, les résultats suivants se produisent :
Vous utilisez Obtenir des données pour sélectionner la source. Pour les sources relationnelles, vous pouvez toujours sélectionner un ensemble de tables qui définissent une requête renvoyant logiquement un ensemble de données. Pour les sources multidimensionnelles telles que SAP Business Warehouse (SAP BW), vous sélectionnez uniquement la source.
Au chargement, aucune donnée n’est importée dans le magasin Power BI. Au lieu de cela, lorsque vous créez un visuel, Power BI Desktop envoie des requêtes à la source de données sous-jacente pour récupérer les données nécessaires. Le temps nécessaire à l’actualisation du visuel dépend des performances de la source de données sous-jacente.
Les modifications apportées aux données sous-jacentes ne sont pas immédiatement répercutées dans les visuels existants. Il est toujours nécessaire de procéder à une actualisation. Power BI Desktop renvoie à nouveau les requêtes nécessaires pour chaque visuel et met à jour le visuel si nécessaire.
La publication du rapport sur le service Power BI crée et charge un modèle sémantique, identique à l’importation. Toutefois, ce modèle sémantique n’inclut aucune donnée.
Lors de l’ouverture ou de la création d’un rapport dans le service Power BI, la source de données sous-jacente est interrogée pour extraire les données nécessaires. Selon l’emplacement de la source de données d’origine, il peut être nécessaire de configurer une passerelle de données locale pour obtenir les données.
Vous pouvez épingler des visuels ou des pages de rapport entières sous forme de vignettes de tableau de bord. Pour garantir la rapidité de l’ouverture d’un tableau de bord, les vignettes sont actualisées automatiquement à intervalles réguliers, par exemple toutes les heures. Vous pouvez contrôler la fréquence d’actualisation en fonction de la fréquence à laquelle les données changent et de l’importance de voir les dernières données.
À l’ouverture d’un tableau de bord, les vignettes reflètent les données correspondant à l’heure de la dernière actualisation et pas nécessairement les dernières modifications apportées à la source de données sous-jacente. Vous pouvez actualiser un tableau de bord ouvert pour vérifier qu’il est à jour.
Connexions actives
Lors de la connexion à SQL Server Analysis Services, vous pouvez choisir d’importer les données ou d’utiliser une connexion active pour le modèle de données sélectionné. L’utilisation d’une connexion active est similaire à l’utilisation de DirectQuery. Aucune donnée n’est importée, et la source de données sous-jacente est interrogée pour actualiser les visuels.
Par exemple, lorsque vous utilisez l’importation pour vous connecter à SQL Server Analysis Services, vous définissez une requête sur la source SQL Server Analysis Services externe et importez les données. Si vous vous connectez en direct, vous ne définissez pas de requête et le modèle externe entier s’affiche dans la liste des champs.
Cette situation s’applique également lorsque vous vous connectez aux sources suivantes, sauf qu’il n’existe aucune option permettant d’importer les données :
Modèles sémantiques Power BI, par exemple la connexion à un modèle sémantique Power BI déjà publié sur le service, pour créer un nouveau rapport sur celui-ci.
Microsoft Dataverse.
Lorsque vous publiez des rapports SQL Server Analysis Services qui utilisent des connexions actives, le comportement dans le service Power BI est similaire aux rapports DirectQuery des manières suivantes :
Lors de l’ouverture ou de la création d’un rapport dans le service Power BI, la source SQL Server Analysis Services sous-jacente est interrogée, ce qui nécessite éventuellement une passerelle de données locale.
Les vignettes de tableau de bord sont actualisées automatiquement à intervalles réguliers, par exemple toutes les heures.
Une connexion active diffère également de DirectQuery de plusieurs façons. Par exemple, les connexions actives transmettent toujours l’identité de l’utilisateur qui ouvre le rapport à la source SQL Server Analysis Services sous-jacente.
Cas d’usage DirectQuery
La connexion à DirectQuery peut être utile dans les scénarios suivants. Dans plusieurs de ces cas, il est nécessaire ou bénéfique de laisser les données à leur emplacement source d’origine.
DirectQuery dans Power BI offre les plus grands avantages dans les scénarios suivants :
- Les données changent fréquemment et vous avez besoin de rapports en quasi temps réel.
- Vous devez gérer des données volumineuses sans avoir à pré-agréger.
- La source sous-jacente définit et applique des règles de sécurité.
- Des restrictions de souveraineté des données s’appliquent.
- La source est multidimensionnelle et contient des mesures (par exemple, SAP BW).
Les données changent fréquemment et vous avez besoin de rapports quasiment en temps réel
Vous pouvez actualiser les modèles avec des données importées au maximum une fois par heure (plus fréquemment avec des abonnements Power BI Pro ou Power BI Premium). Si les données évoluent en permanence et qu’il est nécessaire que les rapports présentent les données les plus récentes, l’utilisation de l’importation avec une actualisation planifiée peut ne pas répondre à vos besoins. Vous pouvez envoyer les données en streaming directement à Power BI, même s’il existe des limites aux volumes de données pris en charge en pareil cas.
L’utilisation de DirectQuery signifie que l’ouverture ou l’actualisation d’un rapport ou d’un tableau de bord affiche toujours les données les plus récentes dans la source. Les vignettes de tableau de bord peuvent également être mises à jour plus fréquemment (jusqu’à toutes les 15 minutes).
Les données sont très volumineuses
Si les données sont très volumineuses, il n’est pas possible de les importer toutes. DirectQuery ne nécessite aucun transfert important de données, car celles-ci sont interrogées sur place. Cependant, des données volumineuses peuvent également ralentir trop les performances des requêtes sur cette source sous-jacente.
Il n’est pas toujours nécessaire d’importer l’absolue totalité des données. L’Éditeur Power Query facilite la pré-agrégation des données lors de l’importation. Techniquement, il est possible d’importer exactement les données agrégées dont vous avez besoin pour chaque visuel. Si DirectQuery constitue l’approche la plus simple pour des données volumineuses, l’importation de données agrégées peut offrir une solution si la source de données sous-jacente est trop lente pour DirectQuery.
Ces détails concernent l’utilisation de Power BI seul. Pour plus d’informations sur l’utilisation de modèles volumineux dans Power BI, consultez modèles sémantiques volumineux dans Power BI Premium. Par ailleurs, elle n’impose aucune restriction quant à la fréquence d’actualisation des données.
La source sous-jacente définit des règles de sécurité
Lorsque vous importez des données, Power BI se connecte à la source de données à l’aide des informations d’identification Power BI Desktop de l’utilisateur actuel ou des informations d’identification configurées pour l’actualisation planifiée à partir du service Power BI. Dans la publication et le partage de rapports qui ont importé des données, vous devez être prudent de partager uniquement avec les utilisateurs autorisés à voir les données, ou vous devez définir la sécurité au niveau des lignes dans le cadre du modèle sémantique.
DirectQuery permet de transmettre les informations d’identification d’un lecteur de rapports à la source sous-jacente, qui applique des règles de sécurité. DirectQuery prend en charge l’authentification unique (SSO) pour les sources de données Azure SQL et via une passerelle de données vers des serveurs SQL locaux. Pour plus d’informations, consultez Vue d’ensemble de l’authentification unique (SSO) pour les passerelles dans Power BI.
Des restrictions de souveraineté des données s’appliquent
Certaines organisations adoptent des stratégies relatives à la souveraineté des données, en vertu desquelles les données ne peuvent pas quitter le site de l’organisation. Ces données présentent des problèmes pour les solutions basées sur l’importation de données. Avec DirectQuery, les données restent à l’emplacement source sous-jacent. Toutefois, même avec DirectQuery, le service Power BI conserve des caches de données au niveau du visuel en raison de l’actualisation planifiée des vignettes.
La source de données sous-jacente utilise des mesures
Une source de données sous-jacente telle que SAP HANA ou SAP BW contient des mesures. Les mesures signifient que les données importées sont déjà à un certain niveau d’agrégation, tel que défini par la requête. Un visuel qui demande des données à un agrégat de niveau supérieur, tel que Total des ventes par année, agrège davantage la valeur d’agrégation. Cette agrégation convient pour des mesures additives (par exemple, Somme et Min), mais constitue un problème pour des mesures non additives (par exemple, Moyenne et DistinctCount).
L’obtention facile des données d’agrégation correctes nécessaires pour un visuel directement à partir de la source nécessite l’envoi de requêtes par visuel, comme dans DirectQuery. Lorsque vous vous connectez à SAP BW, le choix de DirectQuery permet ce traitement des mesures. Pour plus d’informations, consultez DirectQuery et SAP BW.
Actuellement, DirectQuery sur SAP HANA traite les données de la même manière qu’une source relationnelle et produit un comportement similaire à l’importation. Pour plus d’informations, consultez DirectQuery et SAP HANA.
Limitations de DirectQuery
L’utilisation de DirectQuery a des implications potentiellement négatives. Certaines de ces limitations diffèrent légèrement selon la source exacte que vous utilisez. Les sections suivantes répertorient les implications générales de l’utilisation de DirectQuery, ainsi que les limitations liées aux performances, à la sécurité, aux transformations, à la modélisation et à la création de rapports.
Implications générales
Voici quelques limitations et implications générales de l’utilisation de DirectQuery :
Si les données changent, vous devez les actualiser pour afficher les données les plus récentes. Compte tenu de l’utilisation de caches, il n’est pas garanti que le visuel affiche toujours les données les plus récentes. Par exemple, un visuel peut afficher les transactions de la veille. Une modification de segment peut actualiser le visuel pour qu’il affiche les transactions des deux derniers jours, y compris les transactions récentes et nouvellement arrivées. Toutefois, le rétablissement du segment à sa valeur d’origine peut entraîner l’affichage à nouveau de la valeur précédente mise en cache. La sélection de l’option Actualiser a pour effet d’effacer tous les caches et d’actualiser tous les visuels sur la page afin d’afficher les données les plus récentes.
Si les données changent, il n’existe aucune garantie de cohérence entre les visuels. des visuels différents, qu’ils figurent sur une même page ou sur des pages différentes, peuvent être actualisés à des moments différents. Si les données de la source sous-jacente changent, il n’existe aucune garantie que chaque visuel affiche des données correspondant au même point dans le temps.
Étant donné que plusieurs requêtes peuvent être nécessaires pour un seul visuel (par exemple, pour obtenir les détails et les totaux), la cohérence au sein d’un même visuel n’est pas garantie. Garantir cette cohérence nécessiterait l’actualisation de tous les visuels chaque fois qu’un visuel est actualisé et l’utilisation de fonctionnalités coûteuses telles que l’isolement de capture instantanée dans la source de données sous-jacente.
Vous pouvez atténuer ce problème dans une large mesure en sélectionnant la commande Actualiser, qui a pour effet de mettre à jour tous les visuels de la page. Même en utilisant le mode Importation, il existe un problème similaire de garantie de la cohérence en cas d’importation de données à partir de plusieurs tables.
Vous devez actualiser dans Power BI Desktop pour refléter les modifications de schéma. Une fois qu’un rapport est publié, l’option Actualiser dans le service Power BI actualise les visuels du rapport. Toutefois, si le schéma source sous-jacent change, le service Power BI ne met pas automatiquement à jour la liste des champs disponibles. Si des tables ou des colonnes sont supprimées de la source sous-jacente, cela peut entraîner un échec de requête lors de l’actualisation. Pour mettre à jour les champs du modèle afin de refléter les modifications, vous devez ouvrir le rapport dans Power BI Desktop et choisir Actualiser.
Une limite de 1 million de lignes peut être retournée sur n’importe quelle requête. Il existe une limite fixe de 1 million de lignes pouvant être retournées dans une seule requête à la source sous-jacente. Cette limite n’a généralement pas de conséquences pratiques et les visuels n’afficheront pas autant de points. Toutefois, la limite peut être atteinte dans les cas où Power BI n’optimise pas entièrement les requêtes envoyées et demande des résultats intermédiaires qui dépassent la limite.
La limite peut également être atteinte lors de la création d’un visuel, en cherchant à obtenir un état final plus raisonnable. Par exemple, à défaut d’application d’un filtre, l’inclusion de Customer et de TotalSalesQuantity entraîne le dépassement de cette limite s’il y a plus de 1 million de clients. L’erreur retournée est : Le jeu de résultats d’une requête sur une source de données externe a dépassé la taille maximale autorisée de « 1000000 » lignes.
Notes
Les capacités Premium vous permettent de dépasser la limite de 1 million de lignes. Pour plus d’informations, consultez Nombre maximal d’ensembles de lignes intermédiaires.
Vous ne pouvez pas changer un modèle à partir de l’importation en mode DirectQuery. Vous pouvez passer d’un modèle du mode DirectQuery au mode Importation si vous importez toutes les données nécessaires. Il n’est pas possible de revenir en mode DirectQuery, principalement en raison de l’ensemble de fonctionnalités que le mode DirectQuery ne prend pas en charge. Pour les sources multidimensionnelles telles que SAP BW, vous ne pouvez pas basculer du mode DirectQuery vers le mode Importation, en raison du traitement différent des mesures externes.
Implications en matière de performances et de charge
Lorsque vous utilisez DirectQuery, l’expérience globale dépend des performances de la source de données sous-jacente. Si l’actualisation de chaque visuel, par exemple après la modification d’une valeur de segment, prend moins de cinq secondes, l’expérience est raisonnable, mais peut sembler lente par rapport à la réponse immédiate avec les données importées. Si la lenteur de la source fait que l’actualisation d’un visuel prend plus que quelques dizaines de secondes, l’expérience devient très médiocre. Les délais de requête peuvent même expirer.
En plus des performances de la source sous-jacente, la charge placée sur la source a également un impact sur les performances. Chaque ouverture de rapport partagé par un utilisateur et chaque actualisation de vignette de tableau de bord ont pour effet d’envoyer au moins une requête par visuel à la source sous-jacente. La source doit être capable de gérer une telle charge de requête tout en maintenant des performances raisonnables.
Implications en matière de sécurité
À moins que la source de données sous-jacente utilise l’authentification unique, un rapport DirectQuery utilise toujours les mêmes informations d’identification fixes pour se connecter à la source une fois qu’elle est publiée sur le service Power BI. Immédiatement après la publication d’un rapport DirectQuery, vous devez configurer les informations d’identification de l’utilisateur à utiliser. Tant que cela n’est pas fait, l’ouverture du rapport dans le service Power BI entraîne une erreur.
Une fois que vous avez fourni les informations d’identification de l’utilisateur, Power BI utilise ces informations d’identification pour quiconque ouvre le rapport, comme pour les données importées. Chaque utilisateur voit les mêmes données sauf si une sécurité au niveau des lignes est définie dans le cadre du rapport. Vous devez porter la même attention au partage du rapport que pour les données importées, même s’il existe des règles de sécurité définies dans la source sous-jacente.
La connexion à des modèles sémantiques Power BI et Analysis Services en mode DirectQuery utilise toujours l’authentification unique. Par conséquent, la sécurité est similaire aux connexions actives à Analysis Services.
Les « informations d’identification alternatives » ne sont pas prises en charge lors de l’établissement de connexions DirectQuery à SQL Server depuis Power BI Desktop. Vous pouvez utiliser vos informations d’identification Windows actuelles ou vos informations d’identification de base de données.
Vous pouvez utiliser plusieurs sources de données dans un modèle DirectQuery à l’aide de modèles composites. Si vous utilisez plusieurs sources de données, vous devez comprendre les implications relatives à la sécurité et comment les données sont déplacées entre les sources de données sous-jacentes.
Limitations de la transformation des données
DirectQuery limite les transformations de données que vous pouvez appliquer dans l’Éditeur Power Query. Avec les données importées, vous pouvez facilement appliquer un ensemble sophistiqué de transformations pour nettoyer et remodeler les données avant de les utiliser pour créer des visuels. Par exemple, vous pouvez analyser des documents JSON ou des données de tableau croisé dynamique d’une colonne vers un formulaire de ligne. Ces transformations sont plus limitées dans DirectQuery.
Lorsque vous vous connectez à une source OLAP (Online Analytical Processing) telle que SAP BW, vous ne pouvez définir aucune transformation, et l’intégralité du modèle externe est extraite de la source. Pour des sources relationnelles comme SQL Server, vous pouvez toujours définir une série de transformations par requête, mais celles-ci sont limitées pour des raisons de performances.
Toutes les transformations doivent être appliquées à chaque requête à la source sous-jacente, plutôt qu’une fois lors de l’actualisation des données. Les transformations doivent être en mesure de se traduire raisonnablement en une seule requête native. Si vous utilisez une transformation trop complexe, vous recevez un message d’erreur indiquant que vous devez la supprimer ou que le modèle de connexion a basculé vers le mode Importation.
En outre, la boîte de dialogue Obtenir des données ou l’Éditeur Power Query utilisent des sous-sélections dans les requêtes qu’ils génèrent et envoient pour récupérer des données pour un visuel. Les requêtes définies dans l’Éditeur Power Query doivent être valides dans ce contexte. En particulier, il n’est pas possible d’utiliser une requête avec des expressions de table courantes, ni une requête qui appelle des procédures stockées.
Limitations de la modélisation
Le terme modélisation dans ce contexte signifie affiner et enrichir les données brutes dans le cadre de la création d’un rapport qui utilise les données. Voici quelques exemples de modélisation :
- définition de relations entre des tables ;
- ajout de nouveaux calculs, comme les colonnes calculées et les mesures ;
- changement de nom et masquage de colonnes et de mesures ;
- définition de hiérarchies ;
- définition de la mise en forme des colonnes, du résumé par défaut et de l’ordre de tri ;
- regroupement ou clustering de valeurs.
Vous pouvez toujours effectuer un grand nombre de ces enrichissements de modèles lorsque vous utilisez DirectQuery et utiliser le principe d’enrichissement des données brutes pour améliorer l’utilisation ultérieure. Toutefois, lors de l’utilisation de DirectQuery, certaines fonctionnalités de modélisation ne sont pas disponibles ou sont limitées. Les limitations sont appliquées pour éviter des problèmes de performances.
Les limitations suivantes sont communes à toutes les sources DirectQuery. D’autres limitations peuvent s’appliquer à des sources individuelles.
Aucune hiérarchie de dates intégrée : quand vous importez des données, une hiérarchie de dates intégrée est disponible pour chaque colonne de date/heure présente. Par exemple, si vous importez une table de commandes client qui inclut une colonne OrderDate et que vous utilisez OrderDate dans un visuel, vous pouvez choisir le niveau de date approprié à utiliser, tel que l’année, le mois ou le jour. Cette hiérarchie de dates intégrée n’est pas disponible avec DirectQuery. Si une table de dates est disponible dans la source sous-jacente, comme c’est souvent le cas dans de nombreux entrepôts de données, vous pouvez utiliser les fonctions d’intelligence temporelle DAX (Data Analysis Expressions) comme d’habitude.
Prise en charge de date/heure uniquement au niveau des secondes : Pour les modèles sémantiques qui utilisent des colonnes d’heure, Power BI émet des requêtes vers la source DirectQuery sous-jacente uniquement jusqu’au niveau des détails des secondes, et non en millisecondes. Supprimez les données en millisecondes de vos colonnes sources.
Limitations dans les colonnes calculées : les colonnes calculées doivent figurer à l’intérieur d’une ligne, car elles peuvent uniquement faire référence à des valeurs d’autres colonnes de la même table, sans possibilité d’utiliser des fonctions d’agrégation. De plus, les fonctions scalaires DAX autorisées telles que
LEFT()se limitent à celles qui peuvent simplement être envoyées (via push) à la source sous-jacente. Les fonctions varient selon les capacités exactes de la source. Les fonctions non prises en charge ne sont pas proposées dans l’autocomplétion lors de la création de la requête DAX pour une colonne calculée et leur utilisation entraîne une erreur.Aucune prise en charge des fonctions DAX parent-enfant : le mode DirectQuery ne permet pas d’utiliser la famille de fonctions
DAX PATH(), qui servent généralement à gérer des structures parent-enfant (par exemple un graphe de comptes ou des hiérarchies d’employés).Aucun clustering : lorsque vous utilisez DirectQuery, vous ne pouvez pas utiliser la fonctionnalité de clustering pour rechercher automatiquement des groupes.
Limitations des rapports
Presque toutes les fonctionnalités de rapports sont prises en charge pour les modèles DirectQuery. Tant que la source sous-jacente offre un niveau de performances approprié, vous pouvez utiliser le même ensemble de visualisations que pour les données importées.
Une limitation générale est que la longueur maximale des données d’une colonne de texte pour les modèles sémantiques DirectQuery est de 32 764 caractères. Des rapports avec des textes plus longs entraînent une erreur.
Les fonctionnalités de création de rapports Power BI suivantes peuvent entraîner des problèmes de performances dans les rapports basés sur DirectQuery :
Filtres de mesures : les visuels utilisant des mesures ou des agrégats de colonnes peuvent également contenir des filtres dans ces mesures. Par exemple, le graphique ci-dessous présente la valeur SalesAmount par catégorie, mais inclut uniquement les catégories avec plus de 20 millions de ventes (20M).

Cette approche entraîne l’envoi de deux requêtes à la source sous-jacente :
- La première requête récupère les catégories correspondant à la condition (valeurs SalesAmount supérieures à 20 millions).
- La deuxième requête récupère ensuite les données nécessaires au visuel, notamment les catégories qui respectent la condition
WHERE.
Cette approche est généralement efficace s’il existe des centaines, voire des milliers de catégories comme dans cet exemple. Les performances peuvent se dégrader si le nombre de catégories est beaucoup plus élevé. La requête échoue s’il existe plus d’un million de catégories.
Filtres TopN : vous pouvez définir des filtres avancés pour filtrer uniquement les valeurs
Nsupérieures ou inférieures classées par une certaine mesure. Par exemple, vous pouvez définir des filtres incluant les 10 premières catégories. Cette approche entraîne l’envoi de deux requêtes à la source sous-jacente : Toutefois, la première requête retourne toutes les catégories de la source sous-jacente, puis les catégoriesTopNsont déterminées sur la base des résultats retournés. Selon la cardinalité de la colonne impliquée, cette approche peut entraîner des problèmes de performances ou des échecs de requête en raison de la limite de 1 million de lignes dans les résultats de la requête.Médiane : toute agrégation (comme
SumouCount Distinct) est envoyée (via push) à la source sous-jacente. Toutefois, l’agrégatmediann’est généralement pas pris en charge par la source sous-jacente. Pourmedian, les données détaillées sont extraites de la source sous-jacente, et la valeur médiane calculée à partir des résultats retournés. Cette approche est raisonnable quand la valeur médiane doit être calculée sur un nombre relativement restreint de résultats.Des problèmes de performances ou des échecs de requête peuvent survenir si la cardinalité est élevée en raison de la limite de 1 million de lignes. Par exemple, interroger la population médiane du pays/région peut être raisonnable, mais interroger le prix de vente médian peut ne pas l’être.
Filtres de texte avancés comme « contains » : le filtrage avancé sur une colonne de texte autorise des filtres comme
containsetbegins with. Ces filtres peuvent entraîner une dégradation des performances pour certaines sources de données. En particulier, n’utilisez pas le filtre par défautcontainssi vous avez besoin d’une correspondance exacte. Si les résultats peuvent être identiques, en fonction des données réelles, les performances peuvent être considérablement différentes en raison de l’utilisation d’index.Multisélection de segments : par défaut, les segments n’autorisent qu’une seule sélection. L’autorisation de plusieurs sélections dans les filtres peut entraîner des problèmes de performances. Par exemple, si l’utilisateur sélectionne les 10 produits qui l’intéressent, chaque nouvelle sélection entraîne l’envoi de requêtes à la source. Même si l’utilisateur peut sélectionner l’élément suivant avant la fin de requête, cette approche entraîne une charge supplémentaire sur la source sous-jacente.
Totaux sur les visuels de table : par défaut, les tables et les matrices affichent les totaux et les sous-totaux. Dans de nombreux cas, l’obtention des valeurs de ces totaux nécessite l’envoi de requêtes distinctes à la source sous-jacente. Cette exigence s’applique chaque fois que vous utilisez l’agrégation
DistinctCount, ou dans tous les cas qui utilisent DirectQuery sur SAP BW ou SAP HANA. Vous pouvez désactiver ces totaux à l’aide du volet Format.
Recommandations de DirectQuery
Cette section fournit des conseils généraux sur la façon d’utiliser DirectQuery avec succès, compte tenu de ses implications.
Performances de la source de données sous-jacente
Vérifiez que les visuels simples s’actualisent en cinq secondes pour offrir une expérience interactive raisonnable. Si l’actualisation des visuels prend plus de 30 secondes, il est probable que d’autres problèmes après la publication du rapport rendent la solution inutilisable.
Si les requêtes sont lentes, examinez celles envoyées à la source sous-jacente et la cause des problèmes de faibles performances. Pour plus d’informations, consultez Diagnostics de performances.
Cet article ne couvre pas toutes les recommandations d’optimisation de base de données sur l’ensemble des sources sous-jacentes potentielles. Les pratiques de base de données standard ci-dessous s’appliquent à la plupart des situations :
Pour de meilleures performances, basez les relations sur des colonnes entières au lieu de joindre des colonnes d’autres types de données.
Créez les index appropriés. La création d’index implique généralement d’utiliser des index de stockage en colonne dans les sources qui les prennent en charge, par exemple SQL Server.
Mettez à jour toutes les statistiques nécessaires dans la source.
Conception de modèle
Lorsque vous définissez le modèle, suivez ces instructions :
Évitez les requêtes complexes dans l’Éditeur Power Query. L’Éditeur Power Query convertit une requête complexe en une requête SQL unique. Celle-ci apparaît dans la sous-sélection de chaque requête envoyée à cette table. Si cette requête est complexe, elle peut entraîner des problèmes de performances à chaque requête envoyée. Vous pouvez obtenir la requête SQL réelle pour un ensemble d’étapes en cliquant avec le bouton droit sur la dernière étape sous Étapes appliquées dans l’Éditeur Power Query et en choisissant Afficher la requête native.
Veillez à utiliser des mesures simples. Au départ, limitez les mesures à des agrégats simples. Si les mesures fonctionnent de manière satisfaisante, vous pouvez définir des mesures plus complexes, mais faites alors attention aux performances.
Évitez les relations sur des colonnes calculées. Dans les bases de données où vous devez effectuer des jointures à plusieurs colonnes, Power BI n’autorise pas le fait de baser des relations sur plusieurs colonnes en tant que clé primaire ou clé étrangère. La solution de contournement courante consiste à concaténer les colonnes à l’aide d’une colonne calculée et à baser la jointure sur cette colonne.
Si cette solution de contournement est raisonnable pour des données importées, en cas d’utilisation de DirectQuery, elle aboutit à une jointure sur une expression. Ce résultat empêche généralement l’utilisation d’index et entraîne une dégradation des performances. La seule solution de contournement consiste à matérialiser réellement les colonnes multiples dans une colonne unique de la source de données sous-jacente.
Évitez les relations sur des colonnes uniqueidentifier. Power BI ne prend pas en charge un type de données
uniqueidentifieren mode natif. La définition d’une relation entre des colonnesuniqueidentifierentraîne une requête avec une jointure impliquant un cast. Là encore, cette approche aboutit généralement à une dégradation des performances. La seule solution de contournement consiste à matérialiser des colonnes d’un autre type de données dans la source de données sous-jacente.Masquez la colonne sur des relations. La colonne
tosur les relations est généralement la clé primaire sur la tableto. Cette colonne doit être masquée, mais si elle est masquée, elle n’apparaît pas dans la liste des champs et ne peut pas être utilisée dans les visuels. Souvent, les colonnes sur lesquelles reposent des relations sont en fait des colonnes système, par exemple, des clés de substitution dans un entrepôt de données. Il est toujours préférable de masquer ces colonnes.Si la colonne a du sens, introduisez une colonne calculée visible, comportant une expression simple d’égalité avec la clé primaire, par exemple :
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...Examinez l’ensemble des colonnes calculées et modifications de type de données. Vous pouvez utiliser des tables calculées lorsque vous utilisez DirectQuery avec des modèles composites. Ces fonctionnalités ne sont pas nécessairement dangereuses, mais elles entraînent des requêtes qui contiennent des expressions plutôt que de simples références à des colonnes. Ces requêtes peuvent également empêcher l’utilisation d’index.
Évitez le filtrage croisé bidirectionnel sur les relations. L’utilisation du filtrage croisé bidirectionnel peut aboutir à des instructions de requête qui ne fonctionnent pas correctement. Pour plus d’informations sur le filtrage croisé bidirectionnel, consultez Activer le filtrage croisé bidirectionnel pour DirectQuery dans Power BI Desktop ou téléchargez le livre blanc sur le filtrage croisé bidirectionnel. Les exemples du document sont destinés à SQL Server Analysis Services, mais les points fondamentaux s’appliquent également à Power BI.
Expérimentez le paramètre d’Intégrité référentielle supposée. Le paramètre Intégrité référentielle supposée appliqué à des relations permet aux requêtes d’utiliser
INNER JOINau lieu d’instructionsOUTER JOIN. Cette recommandation permet généralement d’améliorer les performances des requêtes, même si celles-ci dépendent des spécificités de la source de données.N’utilisez pas de filtrage de date relative dans l’Éditeur Power Query. L’Éditeur Power Query permet de définir un filtrage de date relative. Par exemple, vous pouvez filtrer les lignes où la date se situe dans les 14 derniers jours.
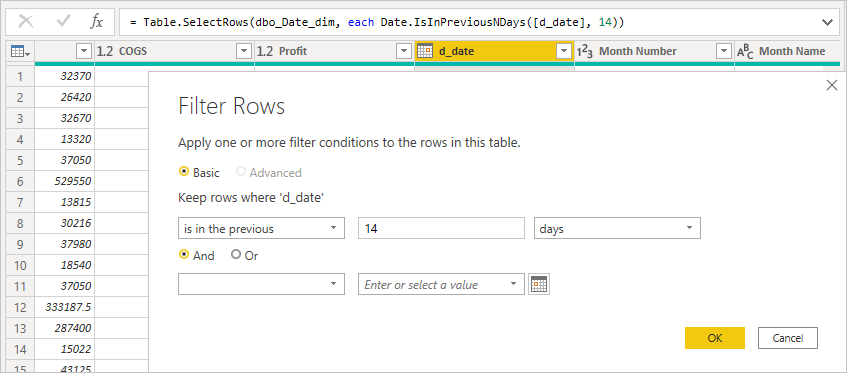
Toutefois, ce filtre se traduit par un filtre basé sur une date fixe, telle que l’heure à laquelle la requête a été créée, comme vous pouvez le voir dans la requête native.

Ces données ne sont probablement pas celles que vous souhaitiez. Pour vous assurer que le filtre est appliqué en fonction de la date d’exécution du rapport, appliquez le filtre de date dans le rapport. Vous pouvez créer une colonne calculée qui calcule le nombre de jours auparavant à l’aide de la fonction
DAX DATE()et utiliser cette colonne calculée dans le filtre.
Conception de rapports
Lorsque vous créez un rapport qui utilise une connexion DirectQuery, suivez ces instructions :
Envisagez d’utiliser les options de réduction de la requête : Power BI propose des options de rapport permettant d’envoyer moins de requêtes et de désactiver certaines interactions qui aboutiraient à une mauvaise expérience dans le cas où les requêtes résultantes mettent longtemps à s’exécuter. Ces options s’appliquent lorsque vous interagissez avec votre rapport dans Power BI Desktop, et s’appliquent également lorsque les utilisateurs consomment le rapport dans le service Power BI.
Pour accéder à ces options dans Power BI Desktop, cliquez sur Fichier>Options et paramètres>Options et sélectionnez Réduction des requêtes.
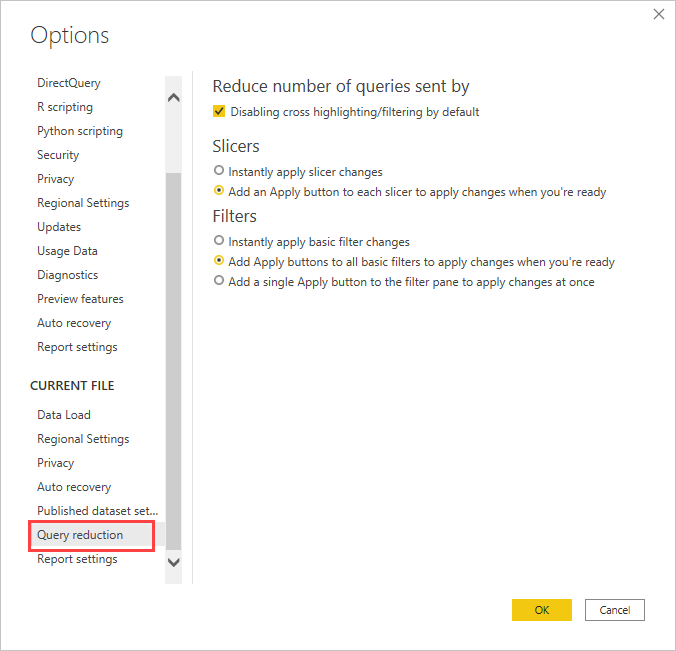
Les sélections de l’écran Réduction des requêtes vous permettent d’afficher un bouton Appliquer pour les sélections de segments ou de filtres. Aucune requête n’est envoyée tant que vous n’avez pas sélectionné le bouton Appliquer sur le segment ou le filtre. Les requêtes utilisent ensuite vos sélections pour filtrer les données. Ce bouton vous permet d’effectuer plusieurs sélections de segments et de filtres avant de les appliquer.
Appliquer d’abord des filtres : appliquez toujours les filtres applicables au début de la création d’un visuel. Par exemple, au lieu de faire glisser vers TotalSalesAmount et ProductName, puis de filtrer sur une année en particulier, appliquez le filtre à Année dès le début.
Chaque étape de création d’un visuel entraîne l’envoi d’une requête. Même s’il est possible d’apporter une autre modification avant l’accomplissement de la première requête, cette approche laisse toujours peser une charge inutile sur la source sous-jacente. L’application précoce de filtres rend généralement ces requêtes intermédiaires moins coûteuses. La non-application précoce de filtres peut amener à atteindre la limite de 1 million de lignes.
Limitez le nombre de visuels sur une page : quand vous ouvrez une page ou modifiez un filtre ou un segment au niveau page, tous les visuels sur la page sont actualisés. Le nombre de requêtes parallèles est limité. À mesure que le nombre de visuels augmente, certains visuels s’actualisent en série, ce qui augmente le temps nécessaire à l’actualisation de la page. C’est pourquoi il est recommandé de limiter le nombre de visuels sur une même page, et d’avoir plutôt un nombre plus important de pages plus simples.
Envisagez de désactiver l’interaction entre les visuels : Par défaut, vous pouvez utiliser les visualisations d’une page de rapport pour filtrer et mettre en évidence les autres visualisations de la page. On parle alors de « filtrage croisé » et de « mise en évidence croisée ». Par exemple, quand vous sélectionnez 1999 sur le graphique en secteurs, l’histogramme est sélectionné de façon croisée pour afficher les ventes par catégorie pour l’année 1999.

Le filtrage croisé et la sélection croisée dans DirectQuery nécessitent l’envoi des requêtes à la source sous-jacente. Vous devez désactiver cette interaction si le temps nécessaire pour répondre aux sélections des utilisateurs est déraisonnablement long.
Vous pouvez utiliser les paramètres de réduction des requêtes pour désactiver la sélection croisée dans votre rapport ou au cas par cas. Pour plus d’informations, consultez Comment les visuels s’entrefiltrent dans un rapport Power BI.
Nombre maximal de connexions
Vous pouvez définir le nombre maximal de connexions que DirectQuery ouvre pour chaque source de données sous-jacente et ainsi contrôler le nombre de requêtes envoyées simultanément à chaque source de données.
Par défaut, DirectQuery ouvre au maximum 10 connexions simultanées. Pour modifier le nombre maximal du fichier actuel dans Power BI Desktop, accédez à Fichier>Options et paramètres>Options, puis sélectionnez DirectQuery dans la section Fichier actuel du volet gauche.
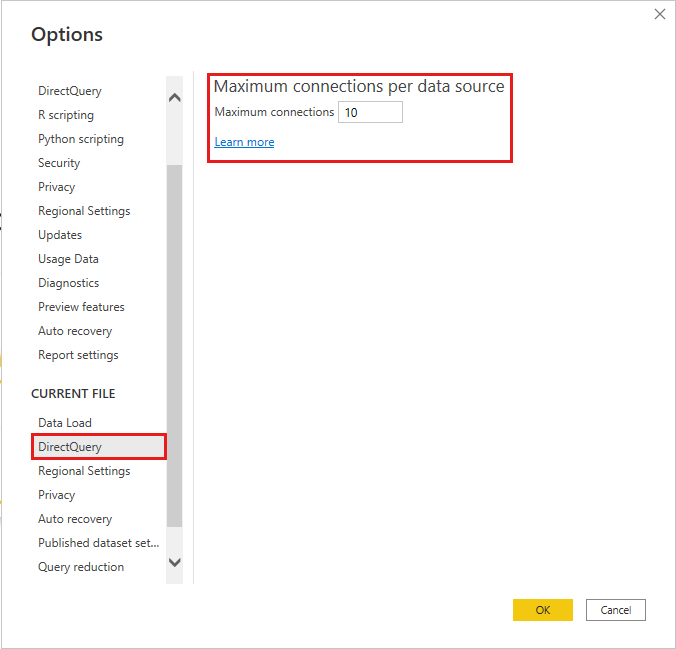
Le paramètre est uniquement activé quand il existe au moins une source DirectQuery dans le rapport actuel. La valeur s’applique à toutes les sources DirectQuery et à toutes les nouvelles sources DirectQuery ajoutées au rapport.
L’augmentation de la valeur Nombre maximal de connexions par source de données permet l’envoi d’un nombre plus élevé de requêtes (jusqu’au nombre maximal spécifié) à la source de données sous-jacente. Cette approche s’avère utile quand de nombreux visuels figurent sur une seule page ou quand de nombreux utilisateurs accèdent à un rapport en même temps. Une fois le nombre maximal de connexions atteint, les requêtes sont mises en file d’attente jusqu’à ce qu’une connexion soit disponible. L’augmentation de cette limite entraîne celle de la charge sur la source sous-jacente, si bien que le paramètre ne garantit pas une amélioration des performances globales.
Une fois que vous avez publié un rapport sur le service Power BI, le nombre maximal de requêtes simultanées dépend également de limites fixes définies sur l’environnement cible dans lequel le rapport est publié. Power BI, Power BI Premium et Power BI Report Server imposent des limites différentes. Dans le tableau suivant figurent les limites supérieures des connexions actives par source de données pour chaque environnement Power BI. Ces limites s’appliquent aux sources de données cloud et aux sources de données locales, par exemple SQL Server, Oracle et Teradata.
| Environnement | Limite supérieure par source de données |
|---|---|
| Power BI Pro | 10 connexions actives |
| Power BI Premium | Dépend de la limitation de la référence SKU du modèle sémantique |
| Power BI Report Server | 10 connexions actives |
Notes
Le paramètre du nombre maximal de connexions DirectQuery s’applique à toutes les sources DirectQuery quand vous activez les métadonnées améliorées, ce qui correspond au paramétrage par défaut pour tous les modèles créés dans Power BI Desktop.
DirectQuery dans le service Power BI
Toutes les sources de données DirectQuery sont prises en charge à partir de Power BI Desktop, et certaines sources sont également disponibles directement à partir du service Power BI. Un utilisateur professionnel peut utiliser Power BI pour se connecter à ses données dans Salesforce et obtenir immédiatement un tableau de bord, sans utiliser Power BI Desktop.
Seules les deux sources suivantes compatibles avec DirectQuery sont disponibles directement dans le service Power BI :
- Spark
- Azure Synapse Analytics (anciennement SQL Data Warehouse)
Même pour ces deux sources, il est toujours préférable de commencer à utiliser DirectQuery dans Power BI Desktop. Bien qu’il soit facile d’établir initialement la connexion dans le service Power BI, il existe des limitations à l’amélioration du rapport généré. Par exemple, dans le service, il n’est pas possible de créer des calculs, d’utiliser de nombreuses fonctionnalités analytiques, voire d’actualiser les métadonnées pour refléter des modifications apportées au schéma sous-jacent.
Les performances d’un rapport DirectQuery dans le service Power BI dépendent du degré de charge placé sur la source de données sous-jacente. La charge dépend des éléments suivants :
- Nombre d’utilisateurs qui partagent le rapport et le tableau de bord.
- Complexité du rapport.
- Si le rapport définit la sécurité au niveau des lignes.
Comportement des rapports dans le service Power BI
Lorsque vous ouvrez un rapport dans le service Power BI, tous les visuels de la page actuellement visible s’actualisent. Chaque visuel nécessite au moins une requête à la source de données sous-jacente. Certains visuels peuvent nécessiter plusieurs requêtes. Par exemple, un visuel peut présenter des valeurs agrégées de deux tables de faits différentes ou contenir une mesure plus complexe ou des totaux d’une mesure non additive telle que Count Distinct. Le déplacement vers une nouvelle page entraîne l’actualisation de ces visuels. L’actualisation envoie un nouvel ensemble de requêtes à la source sous-jacente.
Chaque interaction utilisateur sur le rapport peut entraîner une actualisation des visuels. Par exemple, la sélection d’une valeur différente sur un segment nécessite l’envoi d’un nouvel ensemble de requêtes pour actualiser tous les visuels concernés. C’est également vrai en cas de clic sur un visuel pour opérer une sélection croisée d’autres visuels, ou de modification d’un filtre. De même, la création ou la modification d’un nouveau rapport exige l’envoi de requêtes à chaque étape de la production du visuel final.
Des résultats sont mis en cache. L’actualisation d’un visuel est instantanée si des résultats rigoureusement identiques ont été récemment obtenus. Si la sécurité au niveau des lignes est définie, ces caches ne sont pas partagés entre les utilisateurs.
L’utilisation de DirectQuery impose des limitations importantes dans certaines des fonctionnalités offertes par le service Power BI pour les rapports publiés :
Fonctionnalité Informations rapides non prise en charge : cette fonction de Power BI effectue des recherches rapides dans différents sous-ensembles de votre modèle sémantique tout en appliquant un jeu d’algorithmes sophistiqués pour détecter les informations potentiellement intéressantes. Étant donné que les aperçus rapides nécessitent des requêtes hautes performances, cette fonctionnalité n’est pas disponible sur les modèles sémantiques qui utilisent DirectQuery.
L’utilisation de l’option Explorer dans Excel entraîne des performances médiocres : vous pouvez explorer un modèle sémantique à l’aide de la fonctionnalité Explorer dans Excel, qui vous permet de créer des tableaux croisés dynamiques et des graphiques croisés dynamiques dans Excel. Cette fonctionnalité est prise en charge pour les modèles sémantiques qui utilisent DirectQuery, mais les performances sont plus lentes que la création de visuels dans Power BI. Si l’utilisation d’Excel est importante pour vos scénarios, tenez compte de ce problème lorsque vous décidez d’utiliser DirectQuery.
Excel n’affiche pas de hiérarchies : Par exemple, lorsque vous utilisez Analyser dans Excel, Excel n’affiche pas de hiérarchies définies dans des modèles Azure Analysis Services ou des modèles sémantiques Power BI qui utilisent DirectQuery.
Actualisation du tableau de bord
Dans le service Power BI, vous pouvez épingler des visuels individuels ou des pages entières à des tableaux de bord sous forme de vignettes. Les vignettes basées sur des modèles sémantiques DirectQuery s’actualisent automatiquement en envoyant des requêtes aux sources de données sous-jacentes selon une planification. Par défaut, les modèles sémantiques s’actualisent toutes les heures, mais vous pouvez configurer l’actualisation entre chaque semaine et toutes les 15 minutes dans le cadre des paramètres de modèle sémantique.
Si aucune sécurité au niveau des lignes n’est définie dans le modèle, chaque vignette est actualisée une seule fois et les résultats sont partagés entre tous les utilisateurs. Si vous utilisez la sécurité au niveau des lignes, chaque vignette nécessite l’envoi de requêtes distinctes par utilisateur à la source sous-jacente.
Cela peut avoir un effet multiplicateur important. Un tableau de bord avec 10 vignettes, partagés avec 100 utilisateurs, créés sur un modèle sémantique à l’aide de DirectQuery avec une sécurité au niveau des lignes, entraîne l’envoi d’au moins 1 000 requêtes à la source de données sous-jacente pour chaque actualisation. Soyez particulièrement attentif à l’utilisation de la sécurité au niveau des lignes et à la configuration de la planification de l’actualisation.
Délais d’expiration des requêtes
Un délai d’expiration de quatre minutes est appliqué aux requêtes individuelles dans le service Power BI. Les requêtes qui prennent plus de quatre minutes échouent. Cette limite vise à éviter les problèmes résultant de temps d’exécution trop longs. Vous devez utiliser DirectQuery uniquement pour les sources qui peuvent fournir des performances de requêtes interactives.
Diagnostics des performances
Cette section décrit comment diagnostiquer des problèmes de performances ou obtenir des informations plus détaillées pour optimiser vos rapports.
Débutez un diagnostic de problèmes de performances dans Power BI Desktop plutôt que dans le service Power BI. Les problèmes de performances sont souvent liés aux performances de la source sous-jacente. Vous pouvez identifier et diagnostiquer les problèmes plus facilement dans l’environnement plus isolé de Power BI Desktop.
Cette approche élimine d’emblée certains composants tels que la passerelle Power BI. Si Power BI Desktop ne permet pas d’identifier les problèmes de performances, examinez les spécificités du rapport dans le service Power BI.
L’analyseur de performances Power BI Desktop est un outil utile pour identifier les problèmes. Essayez d’isoler tous les problèmes sur un seul visuel, plutôt que sur plusieurs visuels sur une page. Si un seul visuel d’une page Power BI Desktop est lent, utilisez l’analyseur de performances pour analyser les requêtes que Power BI Desktop envoie à la source sous-jacente.
Vous pouvez également afficher les traces et les informations de diagnostic émises par certaines sources de données sous-jacentes. Même s’il n’y a pas de traces provenant de la source, le fichier de trace peut contenir des détails utiles sur la façon dont une requête s’exécute et comment vous pouvez l’améliorer. Vous pouvez utiliser le processus suivant pour afficher les requêtes envoyées par Power BI et leurs heures d’exécution.
Utiliser SQL Server Profiler pour afficher les requêtes
Par défaut, Power BI Desktop journalise les événements survenant au cours d’une session donnée dans un fichier de trace nommé FlightRecorderCurrent.trc. Le fichier de trace se trouve dans le dossier Power BI Desktop de l’utilisateur actuel, dans un dossier appelé AnalysisServicesWorkspaces.
Pour certaines sources DirectQuery, ce fichier de trace inclut toutes les requêtes envoyées à la source de données sous-jacente. Les sources de données suivantes envoient des requêtes au journal :
- SQL Server
- Azure SQL Database
- Azure Synapse Analytics (anciennement SQL Data Warehouse)
- Oracle
- Teradata
- SAP HANA
Vous pouvez lire les fichiers de trace à l’aide de SQL Server Profiler, qui fait partie de SQL Server Management Studio, disponible en téléchargement gratuit.
Pour ouvrir le fichier de trace de la session active :
Pendant une session Power BI Desktop, sélectionnez Fichier>Options et paramètres>Options, puis Diagnostics.
Sous Collecte des vidages sur incident, sélectionnez Ouvrir le dossier des traces/vidages sur incident.
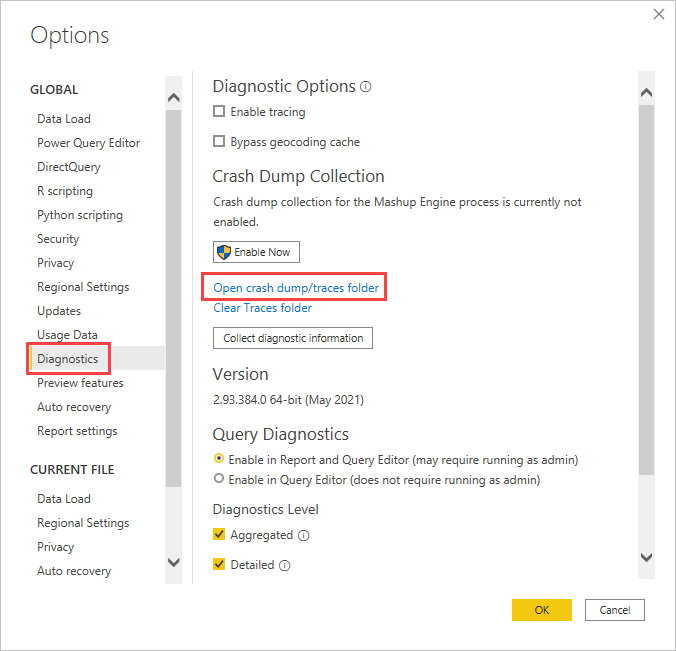
Le dossier Power BI Desktop\Traces s’ouvre.
Accédez au dossier parent, puis au dossier AnalysisServicesWorkspaces, qui contient un dossier d’espace de travail pour chaque instance ouverte de Power BI Desktop. Les noms de ces dossiers ont un nombre entier en suffixe, par exemple AnalysisServicesWorkspace2058279583. Le dossier d’espace de travail est supprimé à l’issue de la session Power BI Desktop associée.
Dans le dossier de l’espace de travail de la session Power BI active, le dossier \Data contient le fichier de trace FlightRecorderCurrent.trc. Prenez note de l’emplacement.
Dans SQL Server Profiler, sélectionnez Fichier>Ouvrir>Fichier de trace.
Accédez à ou entrez le chemin d’accès au fichier de trace pour la session Power BI active, puis ouvrez FlightRecorderCurrent.trc.
SQL Server Profiler affiche tous les événements de la session active. La capture d’écran suivante met en évidence un groupe d’événements pour une requête. Chaque groupe de requête inclut les événements suivants :
Événements
Query BeginetQuery End, qui représentent le début et la fin d’une requête DAX générée en modifiant un visuel ou un filtre dans l’interface utilisateur Power BI, ou en filtrant ou transformant des données dans le Éditeur Power Query.Une ou plusieurs paires d’événements
DirectQuery BeginetDirectQuery End, qui représentent une requête envoyée à la source de données sous-jacente dans le cadre de l’évaluation de la requête DAX.

Dans la mesure où plusieurs requêtes DAX peuvent être exécutées en parallèle, les événements de différents groupes peuvent être entrelacés. Vous pouvez utiliser la valeur ActivityID pour déterminer quels événements appartiennent au même groupe.
Les colonnes suivantes sont également intéressantes :
- TextData : détail textuel de l’événement. Pour les événements
Query BeginetQuery End, il s’agit de la requête DAX. Pour les événementsDirectQuery BeginetDirectQuery End, il s’agit de la requête SQL envoyée à la source sous-jacente. Le TextData de l’événement actuellement sélectionné apparaît également dans le volet en bas de l’écran. - EndTime : heure de fin de l’événement.
- Durée : durée d’exécution de la requête DAX ou SQL, exprimée en millisecondes.
- Erreur : indique si une erreur s’est produite, auquel cas l’événement s’affiche également en rouge.
Pour capturer une trace afin de faciliter le diagnostic d’un problème potentiel de performances :
Ouvrez une session Power BI Desktop pour éviter les confusions possibles entre plusieurs dossiers de l’espace de travail.
Effectuez l’ensemble des actions qui vous intéressent dans Power BI Desktop. Incluez quelques actions supplémentaires pour vous assurer que les événements intéressants sont vidés dans le fichier de trace.
Ouvrez SQL Server Profiler, puis examinez la trace. N’oubliez pas que le fichier de trace est supprimé à la fermeture de Power BI Desktop. Par ailleurs, les actions supplémentaires effectuées dans Power BI Desktop n’apparaissent pas immédiatement. Vous devez fermer et rouvrir le fichier de trace pour voir les nouveaux événements.
Conservez des sessions individuelles relativement petites (10 secondes d’actions éventuellement, mais pas des centaines). Cette approche simplifie l’interprétation du fichier de trace. Par ailleurs, la taille du fichier de trace est limitée. Pour les sessions longues il se peut que des événements du début soient supprimés.
Comprendre le format des requêtes
Le format général des requêtes Power BI Desktop utilise des sous-sélections pour chaque table qu’elles référencent. La requête de l’Éditeur Power Query définit les requêtes de sous-sélection. Par exemple, imaginez les tables TPC-DS suivantes dans SQL Server :
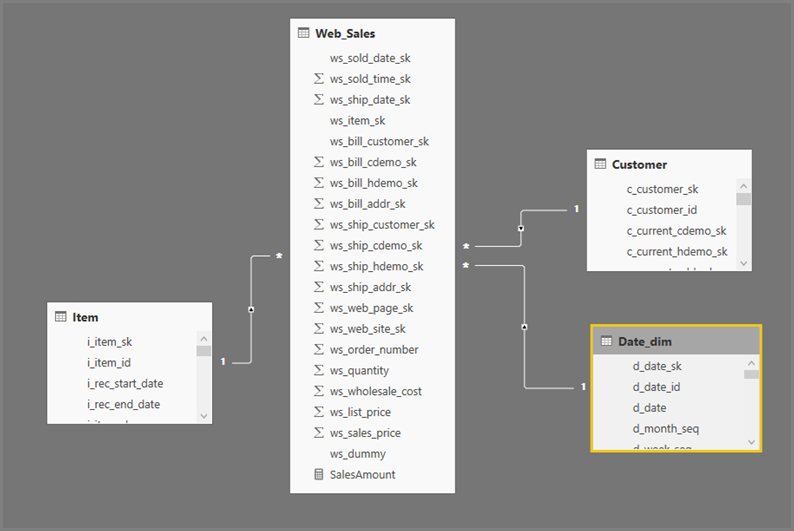
Exécution de la requête suivante :
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Génère le visuel suivant dans Power BI :

L’actualisation de ce visuel produit la requête SQL dans l’image suivante. Il existe trois requêtes de sous-sélection pour Web_Sales, Item et Date_dim, qui retournent chacune toutes les colonnes de la table respective, même si le visuel ne fait référence qu’à quatre colonnes.
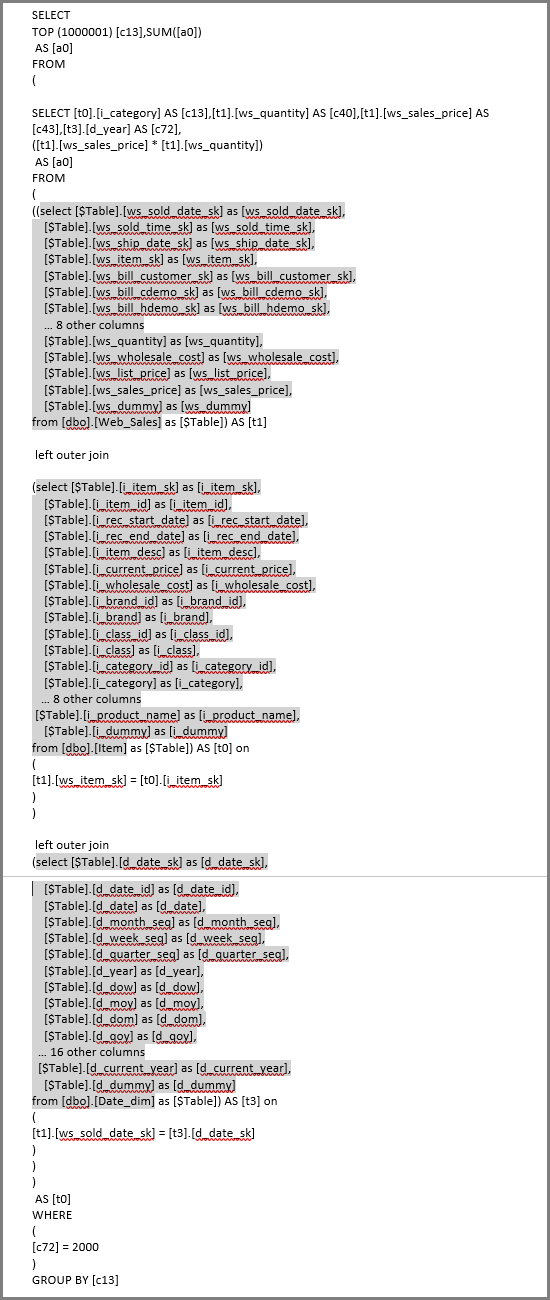
L’Éditeur Power Query définit les requêtes de sous-sélection exactes. Cette utilisation de requêtes de sous-sélection ne semble pas affecter les performances des sources de données prises en charge par DirectQuery. Des sources de données telles que SQL Server optimisent les références aux autres colonnes.
Power BI utilise ce modèle, car l’analyste fournit directement la requête SQL. Power BI utilise la requête telle qu’elle est fournie, sans aucune tentative de réécriture.
Contenu connexe
Pour plus d’informations sur DirectQuery dans Power BI, consultez :
Cet article a présenté les aspects de DirectQuery communs à toutes les sources de données. Pour plus d’informations sur des sources spécifiques, consultez les articles suivants :