Exécuter un exemple de notebook avec Spark
S’applique à :![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Ce tutoriel montre comment charger et exécuter un notebook dans Azure Data Studio sur un cluster Big Data SQL Server 2019. Cela permet aux scientifiques des données et aux ingénieurs de données d’exécuter du code Python, R ou Scala sur le cluster.
Conseil
Si vous préférez, vous pouvez télécharger et exécuter un script pour les commandes de ce tutoriel. Pour obtenir des instructions, consultez les exemples Spark sur GitHub.
Prérequis
- Outils Big Data
- kubectl
- Azure Data Studio
- Extension SQL Server 2019
- Charger des exemples de données dans votre cluster Big Data
Télécharger l’exemple de fichier de notebook
Utilisez les instructions suivantes pour charger l’exemple de fichier de notebook spark-sql.ipynb dans Azure Data Studio.
Ouvrez une invite de commandes bash (Linux) ou Windows PowerShell.
Accédez au répertoire dans lequel vous souhaitez télécharger l’exemple de fichier de notebook.
Exécutez la commande curl suivante pour télécharger le fichier de notebook à partir de GitHub :
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Ouvrir le notebook
Les étapes suivantes montrent comment ouvrir le fichier de notebook dans Azure Data Studio :
Dans Azure Data Studio, connectez-vous à l’instance maître de votre cluster Big Data. Pour plus d’informations, consultez Se connecter à un cluster Big Data.
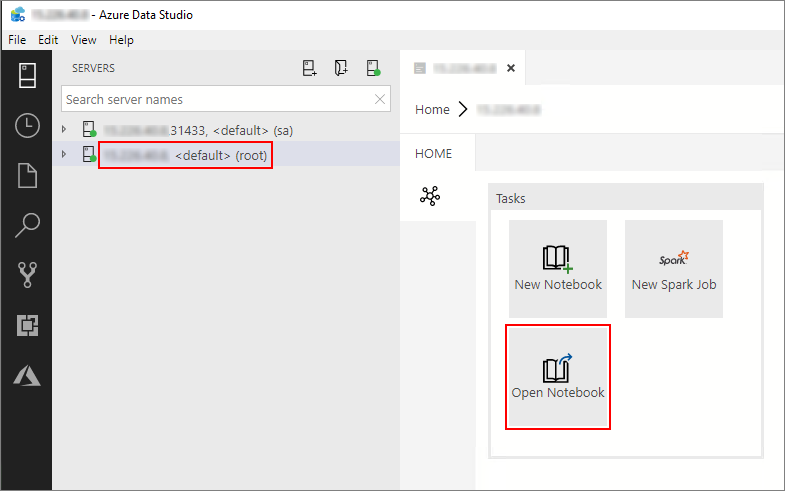
Double-cliquez sur la connexion de passerelle HDFS/Spark dans la fenêtre Serveurs. Sélectionnez ensuite Open Notebook (Ouvrir un notebook).
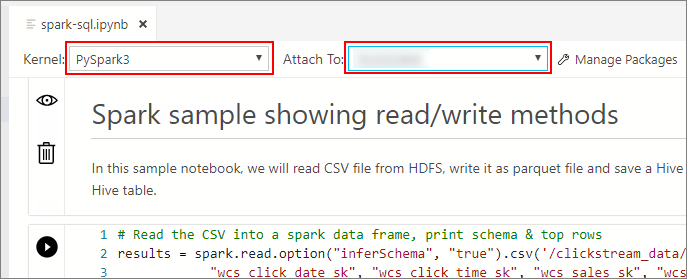
Attendez que Noyau et le contexte cible (Attacher à) soient remplis. Affectez à Noyau la valeur PySpark3 et à Attacher à l’adresse IP de votre point de terminaison de cluster Big Data.
Important
Dans Azure Data Studio, tous les types de notebook Spark (Scala Spark, PySpark et SparkR) définissent par convention certaines variables importantes liées à la session Spark lors de la première exécution de la cellule. Ces variables sont les suivantes: spark, sc et sqlContext. Lors de la copie d’une logique à partir de notebooks pour l’envoi par lots (dans un fichier Python à exécuter avec azdata bdc spark batch create, par exemple), veillez à définir les variables en conséquence.
Exécuter les cellules de notebook
Vous pouvez exécuter chaque cellule de notebook en appuyant sur le bouton de lecture situé à gauche de la cellule. Les résultats sont affichés dans le notebook après la fin de l’exécution de la cellule.

Exécutez chaque cellule de l’exemple de notebook l’une après l’autre. Pour plus d’informations sur l’utilisation des notebooks avec Clusters Big Data SQL Server, consultez les ressources suivantes :
Étapes suivantes
Découvrez-en plus sur les notebooks :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour