Soumettre des travaux Spark sur Clusters Big Data SQL Server dans IntelliJ
S’applique à :![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Un des principaux scénarios pour Clusters Big Data SQL Server est la possibilité de soumettre des travaux Spark. La fonctionnalité de soumission de travaux Spark vous permet d’envoyer un fichier Jar ou Py local avec des références à Clusters Big Data SQL Server. Elle vous permet également d’exécuter des fichiers jar ou py, qui se trouvent déjà sur le système de fichiers HDFS.
Prérequis
- Un cluster Big Data SQL Server
- Kit de développement Java.
- IntelliJ IDEA. Vous pouvez l’installer à partir du site web JetBrains.
- L’extension Azure Toolkit for IntelliJ. Pour obtenir des instructions d’installation, consultez Installer Azure Toolkit for IntelliJ.
Lier un cluster Big Data SQL Server
Ouvrez l’outil IntelliJ IDEA.
Si vous utilisez un certificat autosigné, vous devez désactiver la validation des certificats TLS/SSL. Pour cela, accédez au menu Tools, sélectionnez Azure, Validate Spark Cluster SSL Certificate (Valider les certificats SSL des clusters Spark), puis Disable.
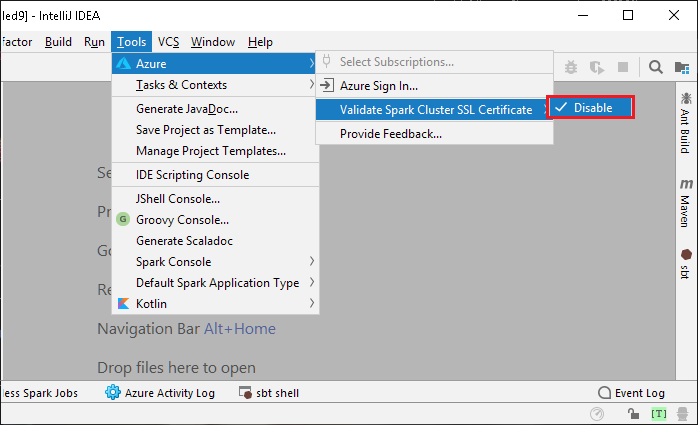
Pour ouvrir l’explorateur Azure, dans le menu View, sélectionnez Tool Windows, puis Azure Explorer.
Cliquez avec le bouton droit sur Cluster Big Data SQL Server et sélectionnez Lier un cluster Big Data SQL Server. Dans les champs Server, User Name et Password, entrez respectivement un nom de serveur, un nom d’utilisateur et un mot de passe, puis cliquez sur OK.
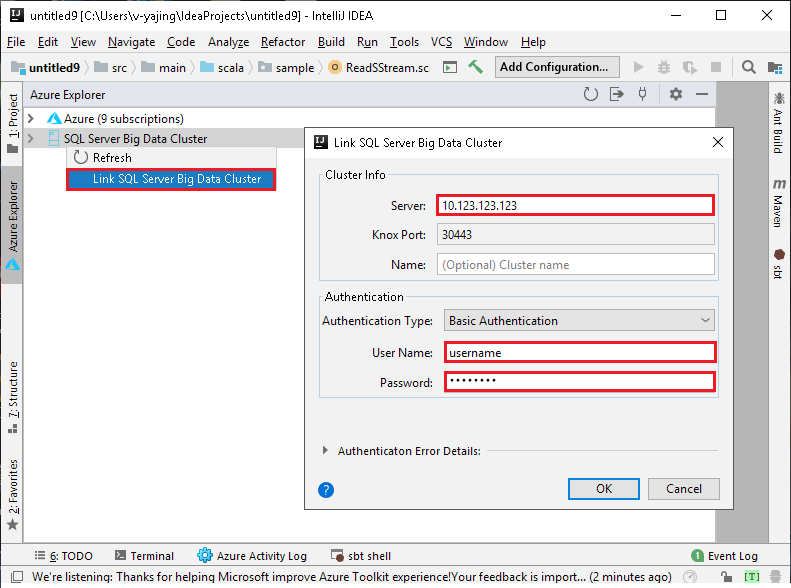
Lorsque la boîte de dialogue du certificat du serveur non approuvé s’affiche, cliquez sur Accept. Vous pourrez gérer le certificat ultérieurement (voir Certificats de serveur).
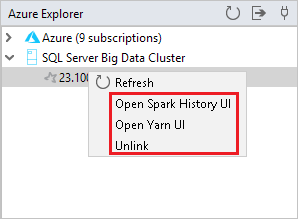
Le cluster lié s’affiche sous SQL Server big data cluster. Vous pouvez superviser un travail Spark à partir de l’historique Spark ou de l’interface utilisateur Yarn. Vous pouvez également supprimer la liaison en cliquant avec le bouton droit sur le cluster.
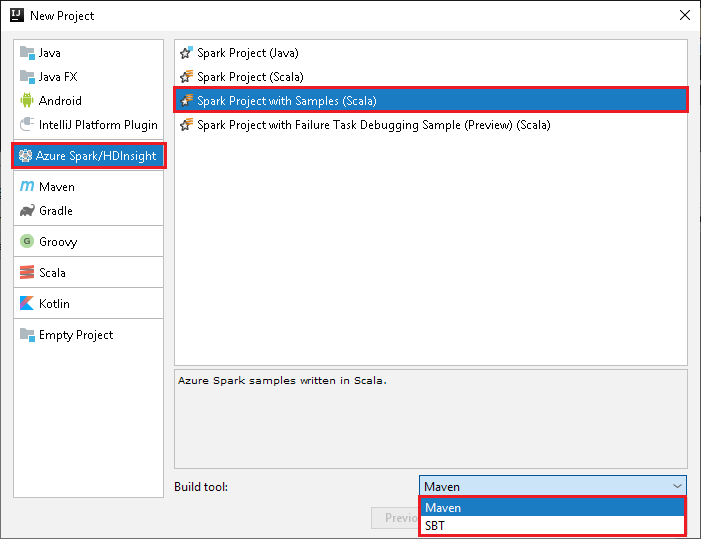
Créer une application Spark Scala à partir d’un modèle Spark
Démarrez IntelliJ IDEA, puis créez un projet. Dans la boîte de dialogue New Project, effectuez les étapes suivantes :
a. Sélectionnez Azure Spark/HDInsight>Spark Project with Samples (Scala) .
b. Dans la liste Build tool (Outil de build), sélectionnez l’une des options ci-dessous, en fonction de vos besoins :
- Maven, pour la prise en charge de l’Assistant Création de projet Scala
- SBT, pour la gestion des dépendances et la création du projet Scala
Sélectionnez Suivant.
L’Assistant Création de projet Scala détecte automatiquement si vous avez installé le plug-in Scala. Sélectionnez Installer.
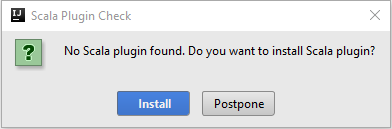
Pour télécharger le plug-in Scala, sélectionnez OK. Suivez les instructions pour redémarrer IntelliJ.
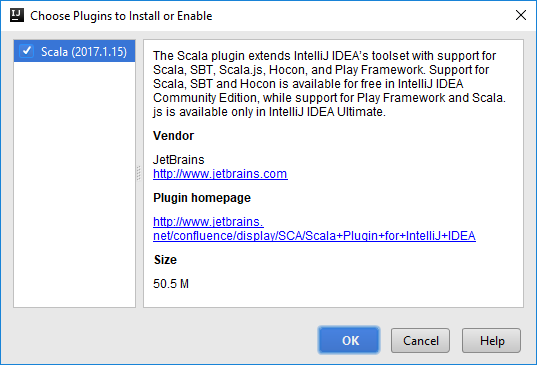
Dans la boîte de dialogue New Project (Nouveau projet), effectuez les étapes suivantes :
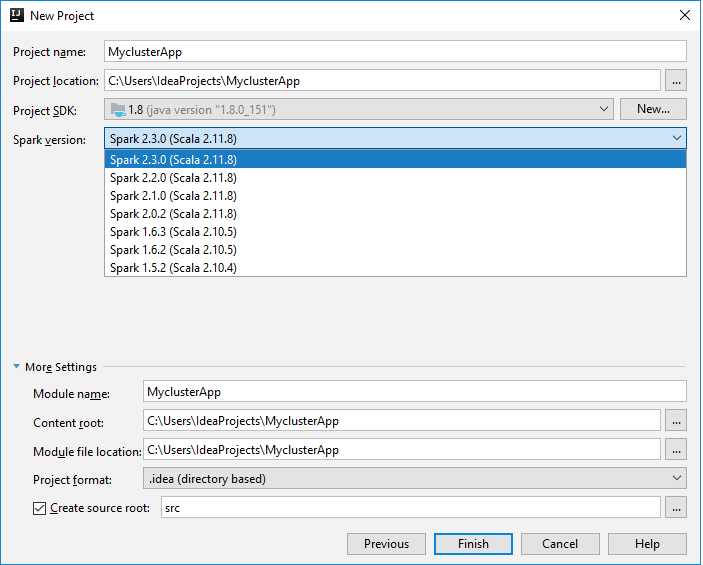
a. Entrez un nom et un emplacement pour le projet.
b. Dans la liste déroulante Project SDK (SDK du projet), sélectionnez Java 1.8 pour le cluster Spark 2.x, ou sélectionnez Java 1.7 pour le cluster Spark 1.x.
c. Dans la liste déroulante Spark version (Version Spark), l’Assistant Création de projets Scala affiche la version du SDK Spark et la version du SDK Scala correspondantes. Si la version du cluster Spark est antérieure à la version 2.0, sélectionnez Spark 1.x. Sinon, sélectionnez Spark 2.x. Cet exemple utilise Spark 2.0.2 (Scala 2.11.8) .
Sélectionnez Terminer.
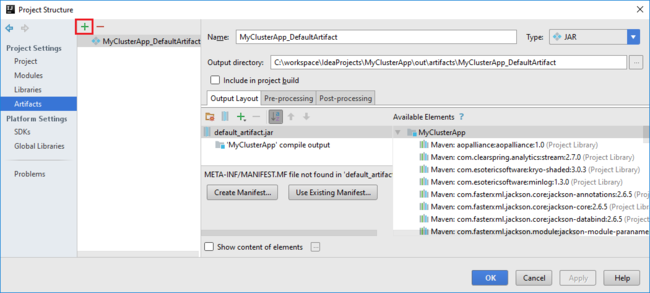
Le projet Spark crée automatiquement un artefact. Pour afficher l’artefact, effectuez les étapes suivantes :
a. Dans le menu File (Fichier), sélectionnez Project Structure (Structure du projet).
b. Dans la boîte de dialogue Project Structure, sélectionnez Artifacts pour voir l’artefact par défaut qui a été créé. Vous pouvez également créer votre propre artefact en sélectionnant le signe plus ( + ).
Envoyer l’application vers un cluster Big Data SQL Server
Après avoir lié un cluster Big Data SQL Server, vous pouvez envoyer une application vers celui-ci.
Dans la fenêtre Run/Debug Configurations (Exécuter/Déboguer les configurations),procédez à la configuration, cliquez sur +->Apache Spark on SQL Server, sélectionnez l’onglet Remotely Run in Cluster (Exécuter à distance dans le cluster), configurez les paramètres comme ci-dessous, puis cliquez sur OK.

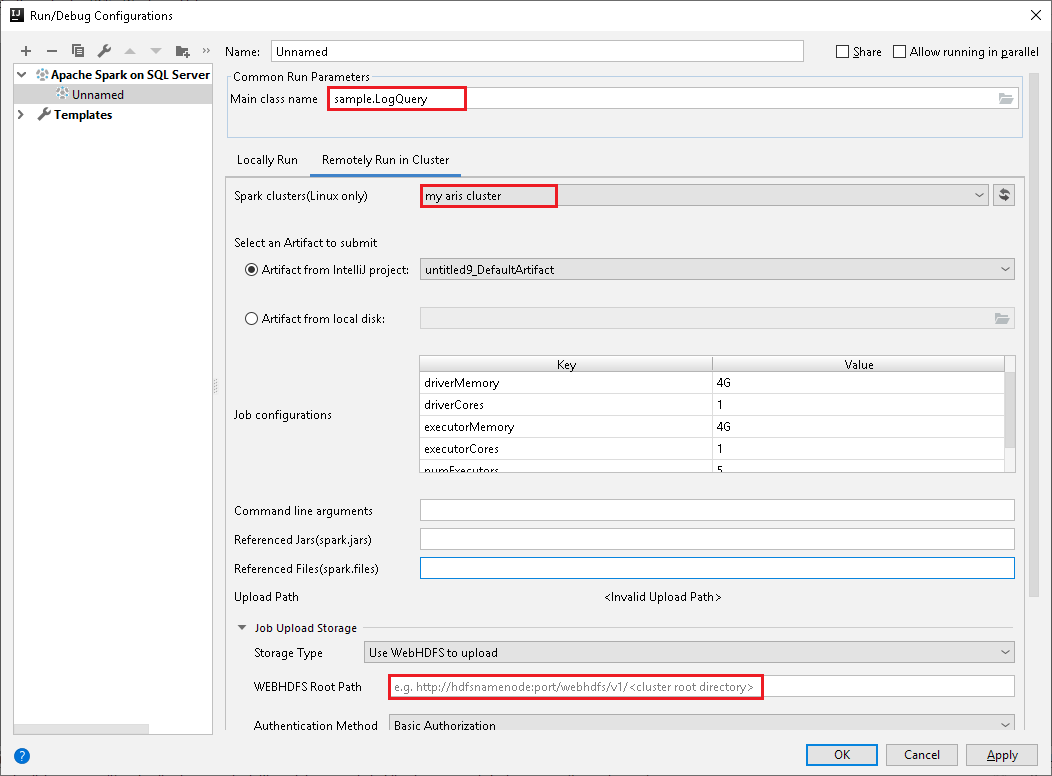
Dans Spark clusters (Linux only) (Clusters Spark (Linux uniquement)), sélectionnez le cluster sur lequel vous souhaitez exécuter votre application.
Sélectionnez un artefact dans le projet IntelliJ ou sélectionnez-en un à partir du disque dur.
Champ Main class name (Nom de la classe principale) : La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe.
Champ Job Configurations (Configurations de tâche) : les valeurs par défaut sont définies comme dans l’image ci-dessus. Vous pouvez changer la valeur ou ajouter une nouvelle clé/valeur pour l’envoi de votre travail. Pour plus d'informations : API REST Apache Livy

Champ Command line arguments : Pour la classe principale, vous pouvez entrer les valeurs des arguments en les séparant par un espace, si nécessaire.
Champs Referenced Jars et Referenced Files : vous pouvez entrer les chemins des fichiers jar et des fichiers référencés, si vous en avez. Pour plus d'informations : Configuration Apache Spark

Notes
Pour charger vos fichiers jar et vos fichiers référencés, consultez : Comment charger des ressources dans un cluster
Champ Upload Path : vous pouvez indiquer l’emplacement de stockage pour l’envoi du fichier jar ou des ressources du projet Scala. Plusieurs types de stockage sont pris en charge : Use Spark interactive session to upload (Utiliser une session interactive Spark pour le chargement) et Use WebHDFS to upload (Utiliser WebHDFS pour le chargement)
Cliquez sur SparkJobRun pour envoyer votre projet vers le cluster sélectionné. L’onglet Remote Spark Job in Cluster (Travail Spark distant dans le cluster) affiche la progression de l’exécution du travail au bas de la page. Vous pouvez arrêter l’application en cliquant sur le bouton rouge.
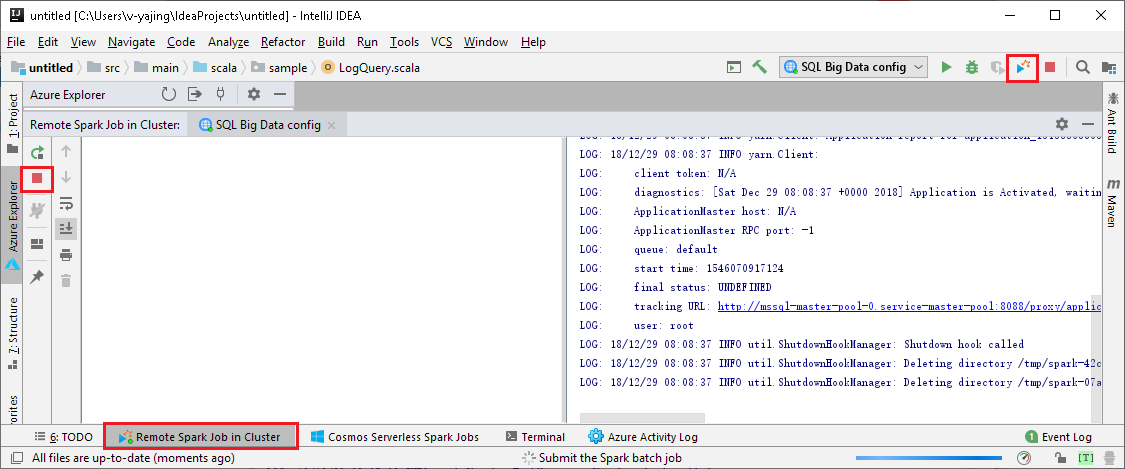
Console Spark
Vous pouvez exécuter la console locale Spark (Scala) ou exécuter la console de sessions interactives Spark Livy (Scala).
Console locale Spark (Scala)
Veillez à respecter les prérequis WINUTILS.EXE.
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations, dans le volet de gauche, accédez à Apache Spark on SQL Server big data cluster>[Spark on SQL] myApp.
Dans la fenêtre principale, sélectionnez l’onglet Locally Run.
Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Job main class (Classe principale du travail) La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. Variables d'environnement Vérifiez que la valeur de HADOOP_HOME est correcte. WINUTILS.exe location Vérifiez que le chemin est correct. 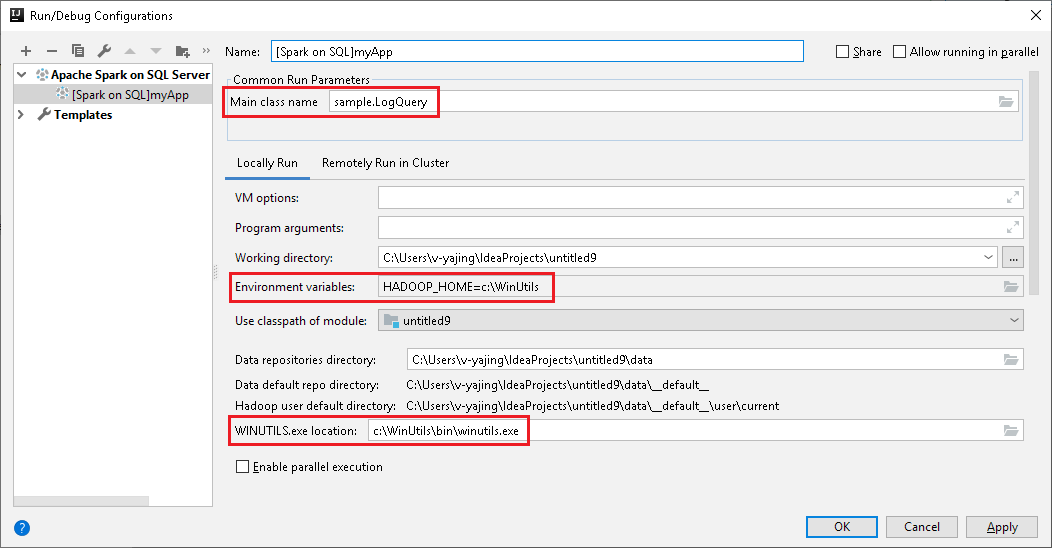
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark Console>Run Spark Local Console(Scala) .
Deux boîtes de dialogue peuvent s’afficher pour vous demander si vous souhaitez corriger automatiquement les dépendances. Si c’est le cas, sélectionnez Correction automatique.
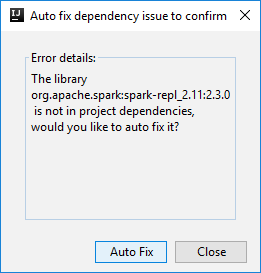
La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter l’exécution de la console locale en cliquant sur le bouton rouge.
Console de sessions interactives Spark Livy (Scala)
La console de sessions interactives Spark Livy (Scala) est uniquement prise en charge sur IntelliJ 2018.2 et 2018.3.
Dans la barre de menus, accédez à Run>Edit Configurations... .
Dans la fenêtre Run/Debug Configurations, dans le volet de gauche, accédez à Apache Spark on SQL Server big data cluster>[Spark on SQL] myApp.
Dans la fenêtre principale, sélectionnez l’onglet Remotely Run in Cluster.
Entrez les valeurs suivantes, puis sélectionnez OK :
Propriété Valeur Spark clusters (Linux only) Sélectionnez le cluster Big Data SQL Server sur lequel vous souhaitez exécuter votre application. Main class name La valeur par défaut est la classe principale du fichier sélectionné. Vous pouvez changer la classe en sélectionnant les points de suspension ( ... ), puis en choisissant une autre classe. 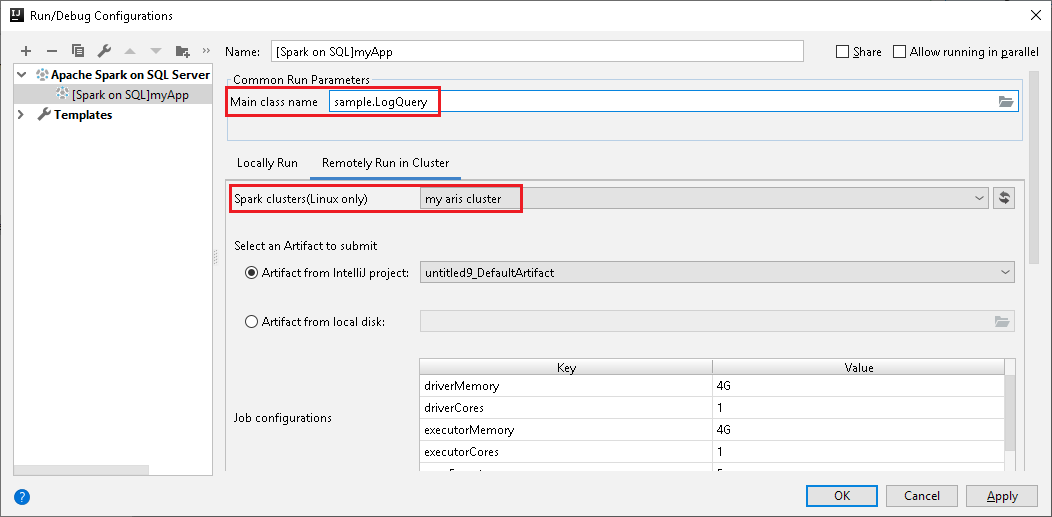
Dans le projet, accédez à myApp>src>main>scala>myApp.
Dans la barre de menus, accédez à Tools>Spark Console>Run Spark Livy Interactive Session Console(Scala) .
La console doit ressembler à l’image ci-dessous. Dans la fenêtre de la console, tapez
sc.appName, puis appuyez sur Ctrl + Entrée. Le résultat s’affiche. Vous pouvez arrêter l’exécution de la console locale en cliquant sur le bouton rouge.
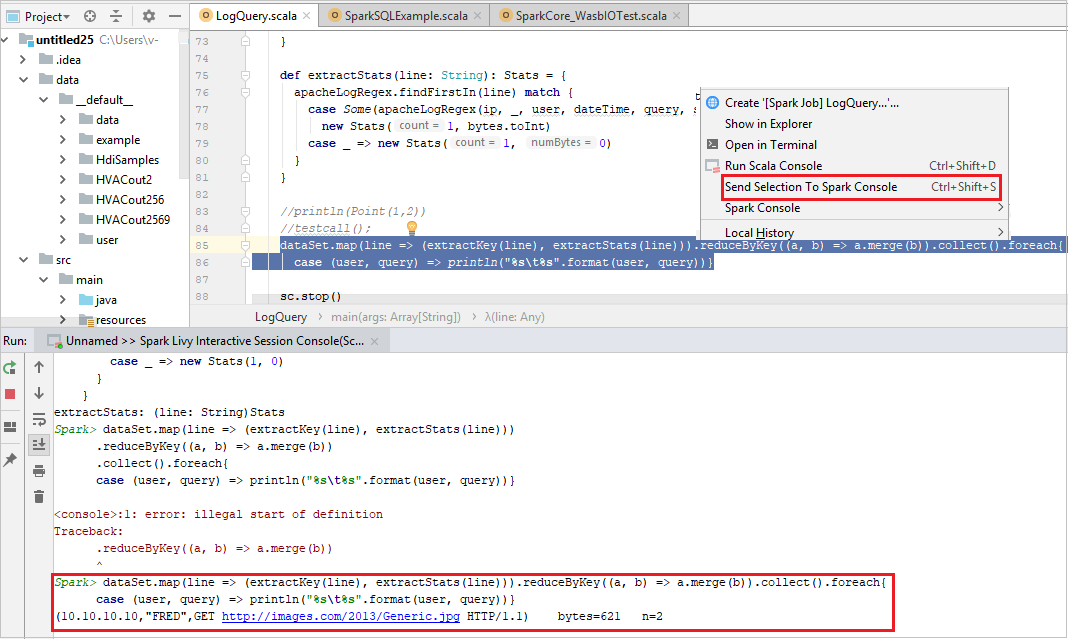
Envoyer la sélection vers la console Spark
Pour des raisons pratiques, vous pouvez voir le résultat du script en envoyant du code vers la console locale ou la console de sessions interactives Livy (Scala). Vous pouvez mettre en surbrillance du code dans le fichier Scala, puis cliquer avec le bouton droit sur Send Selection To Spark Console (Envoyer la sélection vers la console Spark). Le code sélectionné est envoyé vers la console pour être exécuté. Le résultat s’affiche après le code dans la console. La console vérifie les erreurs, le cas échant.
Étapes suivantes
Pour plus d’informations sur le cluster Big Data SQL Server et les scénarios associés, consultez Présentation des Clusters de Big Data SQL Server 2019.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour