Jointures (SQL Server)
S’applique à :![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
SQL Server effectue des opérations de tri, d’intersection, d’union et de différence à l’aide du tri en mémoire et de la technologie de jointure de hachage. À l’aide de ce type de plan de requête, SQL Server prend en charge le partitionnement vertical de tables.
SQL Server implémente des opérations de jointure logique, comme déterminé par la syntaxe Transact-SQL :
- Jointure interne
- Jointure externe gauche
- Jointure externe droite
- Jointure externe entière
- Jointure croisée
Remarque
Pour plus d’informations sur la syntaxe de jointure, consultez Clause FROM plus JOIN, APPLY, PIVOT (Transact-SQL).
SQL Server utilise quatre types d’opérations de jointure physique pour effectuer les opérations de jointure logique :
- Jointures de boucles imbriquées
- Jointures de fusion
- Jointures de hachage
- Jointures adaptatives (à partir de SQL Server 2017 (14.x))
Principes de base des jointures
Les jointures permettent d'extraire des données de deux ou de plusieurs tables en fonction des relations logiques existant entre ces tables. Les jointures indiquent comment SQL Server doit utiliser les données d’une table pour sélectionner les lignes d’une autre table.
Une condition de jointure définit la manière dont deux tables sont liées dans une requête :
- en spécifiant la colonne de chaque table à utiliser pour la jointure. Une condition de jointure standard spécifie une clé étrangère d'une table et la clé qui lui est associée dans l'autre table ;
- En spécifiant l’opérateur logique (par exemple = ou <>) à utiliser pour comparer les valeurs des colonnes.
Les jointures sont exprimées logiquement à l’aide de la syntaxe Transact-SQL suivante :
- INNER JOIN
- LEFT [ OUTER ] JOIN
- RIGHT [ OUTER ] JOIN
- FULL [ OUTER ] JOIN
- CROSS JOIN
Vous pouvez spécifier des jointures internes dans les clauses FROM ou WHERE. Vous pouvez spécifier des jointures externes et des jointures croisée uniquement dans la clause FROM. Les conditions de jointure peuvent être combinées aux conditions de recherche WHERE et HAVING afin de contrôler les lignes qui sont sélectionnées parmi les tables de base référencées dans la clause FROM.
Nous vous recommandons de spécifier les conditions de jointure dans la clause FROM, car cela vous permet de les séparer des autres conditions de recherche susceptibles d’être spécifiées dans une clause WHERE. Voici une syntaxe de jointure simplifiée d’une clause FROM ISO :
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
Le join_type spécifie le type de jointure effectué : jointure interne, externe ou croisée. join_condition définit le prédicat à évaluer pour chaque paire de lignes jointes. L’exemple suivant spécifie une jointure dans une clause FROM :
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
L’instruction SELECT suivante utilise cette jointure :
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
L’instruction SELECT retourne les informations relatives au produit et au fournisseur pour toutes les combinaisons de pièces fournies par une société dont le nom commence par F et dont le prix du produit est supérieur à 10 dollars US.
Lorsque plusieurs tables sont référencées dans une seule requête, aucune référence de colonne ne doit être ambiguë. Dans l’exemple précédent, les tables ProductVendor et Vendor contiennent toutes deux une colonne nommée BusinessEntityID. Tout nom de colonne dupliqué dans deux ou plusieurs tables référencées dans la requête doit être qualifié par le nom de la table. Toutes les références aux colonnes Vendor de l’exemple sont qualifiées.
Lorsqu'un nom de colonne n'est pas dupliqué dans d'autres tables utilisées dans la requête, les références à ce nom ne doivent pas être qualifiées par le nom de la table. Cette caractéristique apparaît dans l'exemple précédent. Une telle clause SELECT est parfois difficile à comprendre car rien n’indique de quelle table provient chaque colonne. Vous pouvez donc améliorer la lisibilité de la requête si vous qualifiez toutes les colonnes par leur nom de table. La lisibilité est encore améliorée si vous utilisez des alias de table, surtout lorsque les noms de table eux-mêmes doivent être qualifiés par les noms de base de données et de propriétaire. Il s'agit du même exemple, à ceci près que des alias de table ont été affectés et que les colonnes ont été qualifiées par les alias de table afin d'améliorer la lisibilité :
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Dans les exemples précédents, les conditions de jointure sont spécifiées dans la clause FROM, ce qui correspond à la méthode recommandée. La requête suivante contient la même condition de jointure spécifiée dans la clause WHERE :
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
La liste SELECT d’une jointure peut faire référence à toutes les colonnes des tables jointes ou à un sous-ensemble de colonnes. Il n’est pas nécessaire que la liste SELECTcontienne des colonnes de toutes les tables de la jointure. Dans une jointure sur trois tables, par exemple, vous pouvez n'utiliser qu'une seule table pour rapprocher l'une des autres tables de la troisième, sans qu'il soit nécessaire de référencer dans la liste de sélection une des colonnes de la table du milieu. Ceci est également appelé antisemi-jointure.
Bien que les conditions de jointure disposent généralement d'opérateurs de comparaison d'égalité (=), vous pouvez spécifier d'autres opérateurs de comparaison ou relationnels ainsi que d'autres prédicats. Pour plus d’informations, consultez Opérateurs de comparaison (Transact-SQL) et WHERE (Transact-SQL).
Lorsque SQL Server traite les jointures, l’optimiseur de requête choisit la méthode la plus efficace (hors de plusieurs possibilités) de traitement de la jointure. Cela inclut le choix du type de jointure physique le plus efficace, de l’ordre dans lequel les tables seront jointes, et même en utilisant des types d’opérations de jointure logique qui ne peuvent pas être directement exprimées avec la syntaxe Transact-SQL, comme les jointures semi-jointes et les jointures anti-semi-jointures. L'exécution physique de différentes jointures peut utiliser de nombreuses optimisations différentes et ne peut par conséquent pas être prédite de manière fiable. Pour plus d’informations sur les semi-jointures et les antisemi-jointures, consultez Informations de référence des opérateurs logiques et physiques du plan d’exécution de requêtes.
Les colonnes utilisées dans une condition de jointure ne doivent pas forcément porter le même nom ou être du même type de données. Si les types de données ne sont pas identiques, ils doivent cependant être compatibles ou pouvoir être convertis de manière implicite par SQL Server. Si les types de données ne peuvent pas être convertis implicitement, la condition de jointure doit le faire explicitement à l’aide de la fonction CAST. Pour plus d’informations sur les conversions implicites et explicites, consultez Conversion de type de données (Moteur de base de données).
La plupart des requêtes utilisant une jointure peuvent être réécrites à l'aide d'une sous-requête (une requête imbriquée dans une autre), et la plupart des sous-requêtes peuvent être réécrites sous forme de jointures. Pour plus d’informations sur les sous-requêtes, consultez Sous-requêtes.
Remarque
Les tables ne peuvent pas être jointes directement sur des colonnes ntext, text ou image. Elles peuvent cependant l’être indirectement sur des colonnes ntext, text ou image à l’aide de SUBSTRING.
Par exemple, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) effectue une jointure interne à deux tables sur les 20 premiers caractères de chaque colonne de texte dans les tableaux t1 et t2.
En outre, il existe une autre possibilité de comparaison des colonnes ntext ou text de deux tables ; elle consiste à comparer les longueurs des colonnes à l’aide d’une clause WHERE, par exemple WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Comprendre les jointures de boucles imbriquées
Si une entrée de jointure est petite (moins de 10 lignes) et que l'autre entrée de jointure est assez importante et indexée sur ses colonnes de jointure, une jointure de type boucles imbriquées d'index représente l'opération de jointure la plus rapide, car elle nécessite le moins d'E/S et de comparaisons.
La jointure de boucles imbriquées, également nommée itération imbriquée, utilise une entrée de jointure comme table d’entrée externe (représentée comme entrée la plus haute dans le plan d’exécution graphique) et une autre comme table d’entrée interne (la plus basse). La boucle externe mobilise la table d'entrée externe ligne par ligne. La boucle interne, exécutée pour chaque ligne externe, recherche les lignes en correspondance dans la table d'entrée interne.
Dans le cas le plus simple, la recherche analyse intégralement une table ou un index, opération désignée tout simplement sous le nom de jointure de boucles imbriquées. Si la recherche exploite un index, il s’agit d’une jointure de boucles imbriquées d’index. Si l’index est généré dans le cadre du plan de requête (et détruit à l’achèvement de la requête), il s’agit d’une jointure de boucles imbriquées d’index temporaire. Toutes ces variantes sont prises en compte par l’optimiseur de requête.
Une jointure de boucles imbriquées est particulièrement efficace si l'entrée externe est petite alors que l'entrée interne préindexée est volumineuse. Dans bon nombre de transactions réduites, comme celles concernant un petit nombre de lignes seulement, les jointures de boucles imbriquées d'index sont supérieures aux jointures de fusion et de hachage. À l'inverse, pour les requêtes de grande ampleur, les jointures de boucles imbriquées ne constituent pas le meilleur choix.
Lorsque l’attribut OPTIMIZED d’un opérateur de jointure de boucles imbriquées est défini sur True, une boucle imbriquée optimisée (ou tri par lot) est utilisée pour réduire les E/S lorsque la table interne est volumineuse, indépendamment de sa parallélisation. La présence de cette optimisation peut ne pas être très évidente lorsque vous analysez un plan d’exécution, étant donné que le tri est une opération cachée. Toutefois, en recherchant l’attribut OPTIMIZED dans le plan XML, vous pouvez voir que la jointure de boucles imbriquées tente de réorganiser les lignes d’entrée pour améliorer les performances d’E/S.
Jointures de fusion
Si les deux entrées de jointure ne sont pas réduites, mais triées sur leur colonne de jointure (si elles ont été obtenues par analyse des index triés, par exemple), une jointure de fusion constitue l'opération de jointure la plus rapide. Si les deux entrées de jointure sont étendues et de taille similaire, une jointure de fusion avec tri préalable et une jointure de hachage offrent des performances équivalentes. Cependant, les opérations de jointure de hachage sont souvent beaucoup plus rapides si la taille des deux entrées diffère de façon significative.
La jointure de fusion impose le tri des deux entrées sur les colonnes de fusion, qui sont définies par les clauses d'égalité (ON) du prédicat de jointure. L'optimiseur de requête analyse généralement un index, s'il en existe un sur l'ensemble approprié de colonnes, ou place un opérateur de tri sous la jointure de fusion. Dans de rares cas, il peut y avoir plusieurs clauses d'égalité, mais les colonnes de fusion ne sont prises en compte que par certaines des clauses d'égalité disponibles.
Étant donné que chaque entrée est triée, l’opérateur Merge Join reçoit une ligne de chaque entrée et les compare. Par exemple, pour les opérations de jointure interne, les lignes sont retournées si elles sont égales. Si elles ne le sont pas, la ligne ayant la valeur la plus faible est ignorée et une autre ligne est prélevée dans cette entrée. Ce processus se répète jusqu'au traitement intégral de toutes les lignes.
L'opération de jointure de fusion peut être de type régulier ou de type plusieurs-à-plusieurs. Une jointure de fusion de type plusieurs-à-plusieurs utilise une table temporaire pour stocker des lignes. S’il existe des valeurs en double de chaque entrée, l’une des entrées doit rembobiner au début des doublons, car chaque doublon de l’autre entrée est traité.
Si un prédicat résiduel existe, toutes les lignes répondant au prédicat de fusion évaluent le prédicat résiduel, et seules celles y répondant sont retournées.
La jointure de fusion est très rapide en elle-même mais elle peut constituer un choix onéreux si des opérations de tri sont nécessaires. Toutefois, si le volume de données est important et si les données souhaitées peuvent être obtenues prétriées à partir d'index d'arbre B (B-tree) existants, la jointure de fusion constitue souvent l'algorithme de jointure le plus rapide.
Jointures de hachage
Les jointures de hachage peuvent traiter efficacement des entrées importantes, non indexées et non triées. Elles sont utiles pour obtenir des résultats intermédiaires dans des requêtes complexes, car :
- Les résultats intermédiaires ne sont pas indexés (sauf s'ils sont volontairement enregistrés sur disque puis indexés) et souvent ne sont pas triés de façon adéquate pour l'opération suivante du plan de requête.
- Les optimiseurs de requêtes n'évaluent que les tailles de résultats intermédiaires. Comme ces estimations risquent d'être imprécises pour les requêtes complexes, les algorithmes qui traitent les résultats intermédiaires doivent bien évidemment être efficaces, mais ils doivent également offrir un traitement réduit si un résultat intermédiaire s'avère bien plus volumineux que prévu.
La jointure de hachage permet le déroulement de réductions dans le cadre de la dénormalisation. Cette dernière est généralement utilisée pour obtenir de meilleures performances par la réduction des opérations de jointure, malgré les risques de redondance, tels que les mises à jour incohérentes. Les jointures de hachage réduisent le besoin de dénormalisation. Elles autorisent le partitionnement vertical (en représentant des groupes de colonnes d'une table unique dans des index ou des fichiers séparés) comme option valable pour la structure des bases de données physiques.
La jointure de hachage dispose de deux entrées : l’entrée de construction (build) et l’entrée d’exploration (probe). L'optimiseur de requête attribue ces rôles de sorte que la plus petite des deux entrées soit l'entrée de construction.
Les jointures de hachage sont utilisées pour de nombreux types d'opérations de correspondance d'ensembles : jointure interne ; jointure externe gauche, droite et complète ; semi-jointure gauche et droite ; intersection ; union ; différentiation. En outre, le regroupement et la suppression des doublons, tels que SUM(salary) GROUP BY department, peuvent être effectués par une variante de la jointure de hachage. Ces modifications n'utilisent qu'une seule entrée pour les rôles de construction et d'exploration.
Les sections suivantes décrivent différents types de jointures de hachage : jointure de hachage en mémoire, jointure de hachage progressive et jointure de hachage récursive.
Jointure de hachage en mémoire
La jointure de hachage analyse ou calcule l'intégralité de l'entrée de construction puis génère une table de hachage en mémoire. Chaque ligne est insérée dans un compartiment de hachage en fonction de la valeur de hachage calculée pour la clé de hachage. Si la totalité de l'entrée de construction est inférieure à la mémoire disponible, toutes les lignes peuvent être insérées dans la table de hachage. La phase de construction est suivie de la phase d'exploration. La totalité de l'entrée d'exploration est analysée ou calculée ligne par ligne puis, pour chaque ligne d'exploration, la valeur de clé de hachage est calculée, le compartiment de hachage correspondant analysé et les correspondances établies.
Jointure de hachage Grace
Si l'entrée de construction ne tient pas en mémoire, une jointure de hachage intervient en plusieurs étapes. Cette opération est qualifiée de jointure de hachage progressive. Chaque étape comprend une phase de construction et une phase d'exploration. Initialement, l'intégralité des entrées de construction et d'exploration est mobilisée et partitionnée (à l'aide d'une fonction de hachage appliquée aux clés de hachage) en plusieurs fichiers. L'utilisation de la fonction de hachage sur les clés de hachage garantit la présence des deux enregistrements de jointure dans la même paire de fichiers. Ainsi, la tâche consistant à joindre deux entrées volumineuses a été réduite à plusieurs instances moins importantes des mêmes tâches. La jointure de hachage est ensuite appliquée à chaque paire de fichiers partitionnés.
Jointure de hachage récursive
Si l'entrée de construction est volumineuse au point que les entrées pour une fusion externe standard nécessitent plusieurs niveaux de fusion, plusieurs étapes et plusieurs niveaux de partitionnement sont nécessaires. Si seules certaines partitions sont volumineuses, des étapes de partitionnement supplémentaires ne sont utilisées que pour celles-ci. Des opérations d'E/S asynchrones sont utilisées de sorte qu'un thread unique puisse occuper plusieurs unités de disque, dans le but d'accélérer au maximum les étapes du partitionnement.
Remarque
Si l'entrée de construction est à peine plus volumineuse que la mémoire disponible, des éléments de jointure de hachage en mémoire et de jointure de hachage progressive sont associés en une étape unique, créant ainsi une jointure de hachage hybride.
Il n'est pas toujours possible, lors de l'optimisation, de déterminer quelle jointure de hachage doit être utilisée. C’est pourquoi SQL Server commence par utiliser une jointure de hachage en mémoire, puis transite graduellement vers la jointure de hachage progressive et la jointure de hachage récursive en fonction de la taille de l’entrée de construction.
Si l’optimiseur de requête anticipe mal laquelle des deux entrées est moins volumineuse et devrait donc être l’entrée de construction, les rôles de construction et d’exploration sont inversés de façon dynamique. La jointure de hachage garantit que l'optimiseur utilise bien le fichier de débordement le moins volumineux comme entrée de construction. Cette technique s’appelle l’inversion des rôles. L'inversion des rôles intervient à l'intérieur de la jointure de hachage après au moins un débordement sur le disque.
Remarque
L'inversion des rôles se produit indépendamment de tous les indicateurs ou de toute structure de requête. L'inversion des rôles ne s'affiche pas dans votre plan de requête ; quand elle se produit, elle est transparente pour l'utilisateur.
Hachage de sauvetage
Le terme interruption de hachage est parfois utilisé pour décrire des jointures de hachage progressives ou des jointures de hachage récursives.
Remarque
Les jointures de hachage récursives ou les interruptions de hachage entraînent une diminution des performances de votre serveur. Si vous voyez de nombreux événements d’avertissements de hachage dans une trace, mettez à jour les statistiques sur les colonnes qui sont jointes.
Pour plus d’informations sur l’interruption de hachage, consultez Hash Warning (classe d’événements).
Jointures adaptatives
En mode batch, les jointures adaptatives permettent de choisir entre la méthode de jointure Jointure hachée et la méthode Boucles imbriquées. En outre, vous pouvez attendre que la première entrée ait été analysée avant de procéder à la jointure. L’opérateur de jointure adaptative définit un seuil qui sert à déterminer le moment où il faut basculer vers un plan de boucles imbriquées. Un plan de requête peut donc passer dynamiquement à une meilleure stratégie de jointure pendant l’exécution, sans que cela nécessite une recompilation.
Conseil
Ce sont les charges de travail avec des variations fréquentes entre les grandes et les petites analyses d’entrée de jointure qui bénéficient le plus de cette fonctionnalité.
La décision d’exécution est basée sur les étapes suivantes :
- Si le nombre de lignes de l’entrée de jointure de génération est suffisamment petit pour qu’une jointure de boucles imbriquées soit plus optimale qu’une jointure hachée, le plan bascule vers un algorithme de boucles imbriquées.
- Si l’entrée de jointure de génération dépasse un seuil spécifique de nombre de lignes, aucun basculement ne se produit et votre plan se poursuit avec une jointure hachée.
La requête suivante est utilisée pour illustrer un exemple de jointure adaptative :
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
Cette requête retourne 336 lignes. L’activation de l’option Statistiques des requêtes actives affiche le plan suivant :
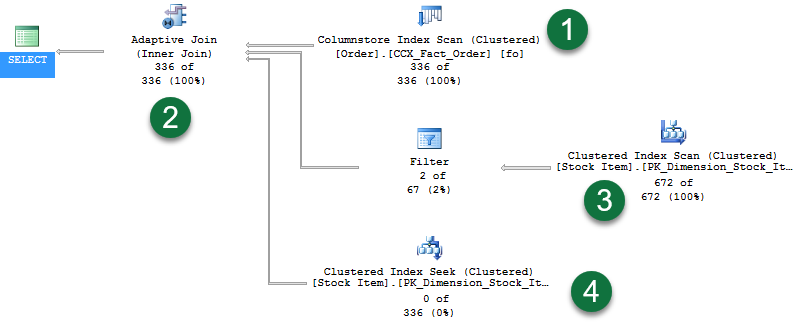
Dans le plan, remarquez les éléments suivants :
- Une analyse d’index columnstore utilisée pour fournir des lignes pendant la phase de génération de la jointure hachée.
- Le nouvel opérateur de jointure adaptative. Cet opérateur définit un seuil qui sert à déterminer le moment où il faut basculer vers un plan de boucles imbriquées. Dans cet exemple, le seuil est fixé à 78 lignes. Dès que le nombre de lignes est >= à 78 lignes, une jointure hachée est utilisée. Si le nombre de lignes est inférieur au seuil, une jointure de boucles imbriquées est utilisée.
- Étant donné que la requête retourne 336 lignes, cela a dépassé le seuil, et donc la deuxième branche représente la phase de sonde d’une opération de jointure de hachage standard. Notez que les statistiques des requêtes actives affichent les lignes qui sont traitées par les opérateurs (dans notre exemple, « 672 sur 672 »).
- La dernière branche est la recherche d’index cluster qui aurait dû être utilisée par la jointure de boucles imbriquées si le seuil n’avait pas été dépassé. Notez que nous voyons « 0 sur 336 » lignes affichées (la branche n’est pas utilisée).
À présent, contrastez le plan avec la même requête, mais lorsque la Quantity valeur n’a qu’une seule ligne dans la table :
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
La requête retourne une ligne. L’activation de l’option Statistiques des requêtes actives affiche le plan suivant :
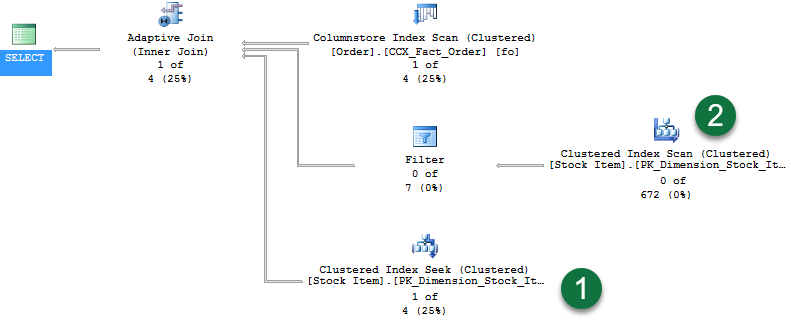
Dans le plan, remarquez les éléments suivants :
- Avec une ligne retournée, le flux des lignes est maintenant inclus dans la recherche d’index cluster.
- De plus, comme la phase de génération de jointure hachée n’a pas continué, aucun flux de lignes n’est inclus dans la deuxième branche.
Remarques concernant les jointures adaptatives
Les jointures adaptatives nécessitent davantage de mémoire que les jointures de boucles imbriquées d’index en cas de plan équivalent. De la mémoire supplémentaire est demandée comme si les boucles imbriquées étaient une jointure hachée. Une opération discontinue engendre également une surcharge pendant la phase de génération contrairement à la diffusion d’une boucle imbriquée, en cas de jointure équivalente. Ce coût supplémentaire apporte une certaine flexibilité dans les scénarios où le nombre de lignes peut fluctuer dans l’entrée de génération.
En mode batch, les jointures adaptatives sont utilisées pour l’exécution initiale d’une instruction. Une fois compilées, les exécutions consécutives restent adaptatives en fonction du seuil des jointures adaptatives compilées et du flux des lignes de runtime dans la phase de génération de l’entrée externe.
Si une jointure adaptative bascule sur une opération de boucles imbriquées, elle utilise les lignes déjà lues dans la génération de jointure hachée. L’opérateur ne relit pas les lignes de référence externe.
Suivre l’activité de jointure adaptative
L’opérateur de jointure adaptative a les attributs d’opérateur de plan suivants :
| Attribut de plan | Description |
|---|---|
| AdaptiveThresholdRows | Montre l’utilisation du seuil pour passer d’une jointure hachée à une jointure de boucles imbriquées. |
| EstimatedJoinType | Type de jointure probable. |
| ActualJoinType | Dans un plan réel, indique l’algorithme de jointure qui a finalement été choisi en fonction du seuil. |
Le plan estimé montre la forme du plan de jointure adaptative, ainsi que le seuil de jointure adaptative défini et un type de jointure estimé.
Conseil
Le Magasin des requêtes capture un plan de jointure adaptative en mode batch et est capable de forcer son application.
Instructions éligibles pour la jointure adaptative
Une jointure logique doit respecter certaines conditions pour être assimilée à une jointure adaptative en mode batch :
- Le niveau de compatibilité de la base de données est de 140 ou supérieur.
- La requête est une instruction
SELECT(les instructions de modification des données ne sont pas éligibles). - La jointure est éligible pour être exécutée par une jointure de boucles imbriquées indexées ou par un algorithme physique de jointure hachée.
- La jointure de hachage utilise le mode Batch, activé par le biais de la présence d’un index columnstore dans l’ensemble de la requête, d’une table indexée columnstore référencée directement par la jointure ou via l’utilisation du mode Batch sur rowstore.
- Les solutions alternatives générées de la jointure de boucles imbriquées et de la jointure hachée doivent avoir le même premier enfant (référence externe).
Lignes du seuil adaptatif
Le graphique suivant montre un exemple d’intersection entre le coût d’une jointure hachée et le coût d’une jointure de boucles imbriquées alternative. À ce point d’intersection, le seuil est déterminé, qui détermine à son tour l’algorithme réel utilisé pour l’opération de jointure.

Désactiver les jointures adaptatives sans modifier le niveau de compatibilité
Les jointures adaptatives peuvent être désactivées au niveau de la base de données ou de l’instruction tout en conservant le niveau de compatibilité de la base de données 140 et les niveaux supérieurs.
Si vous souhaitez désactiver les jointures adaptatives pour toutes les exécutions de requête en provenance de la base de données, exécutez le code suivant dans le contexte de la base de données applicable :
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Lorsqu’il est activé, ce paramètre apparaît comme activé dans sys.database_scoped_configurations.
Pour réactiver les jointures adaptatives pour toutes les exécutions de requête en provenance de la base de données, exécutez ce qui suit dans le contexte de la base de données applicable :
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Vous pouvez également désactiver les jointures adaptatives pour une requête spécifique en désignant DISABLE_BATCH_MODE_ADAPTIVE_JOINS en tant qu’indicateur de requête USE HINT. Par exemple :
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Remarque
Un indicateur de requête USE HINT est prioritaire par rapport à une configuration incluse dans l’étendue d’une base de données ou à un paramètre d’indicateur de trace.
Valeurs et jointures Null
Si certaines colonnes de tables jointes contiennent des valeurs NULL, ces valeurs NULL ne correspondent pas les unes aux autres. La présence de valeurs Null dans une colonne d’une des tables jointes ne peut être retournée que si vous utilisez une jointure externe (sauf si la clause WHERE exclut les valeurs Null).
Voici deux tables qui ont NULL chacune dans la colonne qui participeront à la jointure :
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Une jointure qui compare les valeurs de la colonne par rapport à la colonne ac n’obtient pas de correspondance sur les colonnes dont les valeurs NULLsont :
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Une seule ligne avec la valeur dans 4 les colonnes a et c est retournée :
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Les valeurs NULL retournées d'une table de base sont également difficiles à distinguer des valeurs NULL retournées d'une jointure externe. Par exemple, l'instruction SELECT suivante effectue une jointure externe gauche sur ces deux tables :
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Voici le jeu de résultats obtenu.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Les résultats ne facilitent pas la distinction entre les NULL données et les données qui NULL représentent un échec de jointure. Lorsque des valeurs NULL sont présentes dans les données jointes, il est généralement préférable de les omettre des résultats à l’aide d’une jointure régulière.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour