Korištenje modela utemeljenih na Strojnom učenju Azure
Objedinjeni podaci u Dynamics 365 Customer Insights - Podaci izvor su za izgradnju Strojno učenje modela koji mogu generirati dodatne poslovne uvide. Customer Insights - Data integrira se sa servisom Azure Strojno učenje za korištenje vlastitih prilagođenih modela.
Preduvjeti
- Pristup Customer Insights - Data
- Aktivna pretplata za Azure Enterprise
- Objedinjeni profili kupaca
- Konfiguriran izvoz tablice u spremište bloba servisa Azure
Postavljanje radnog prostora Strojnog učenja Azure
Različite mogućnosti stvaranja radnog prostora potražite u članku Stvaranje radnog prostora servisa Azure Strojno učenje. Za najbolje performanse stvorite radni prostor u Azure regiji koja je geografski najbliža vašem okruženju Customer Insights.
Pristupite radnom prostoru putem servisa Azure Strojno učenje Studio. Postoji nekoliko načina interakcije s radnim prostorom.
Rad s dizajnerom za Strojno učenje Azure
Azure Strojno učenje designer nudi vizualno platno na kojem možete povlačiti i ispuštati skupove podataka i module. Skupni cjevovod stvoren od dizajnera može se integrirati u ako su konfigurirani u Customer Insights - Data skladu s tim.
Rad s SDK-om za Strojno učenje Azure
Podatkovni znanstvenici i razvojni inženjeri umjetne inteligencije koriste Azure Strojno učenje SDK za izradu Strojno učenje tijekova rada. Trenutno se modeli obučeni pomoću SDK-a ne mogu izravno integrirati. Za integraciju je potreban Customer Insights - Data skupni zaključivanje cjevovoda koji troši taj model.
Zahtjevi skupnog cjevovoda za integraciju Customer Insights - Data
Konfiguracija skupa podataka
Stvorite skupove podataka da biste koristili podatke tablice iz aplikacije Customer Insights za skupni zaključivački kanal. Registrirajte te skupove podataka u radnom prostoru. Trenutno podržavamo samo tablične skupove podataka u .csv formatu. Parametrizirajte skupove podataka koji odgovaraju podacima tablice kao parametru kanala.
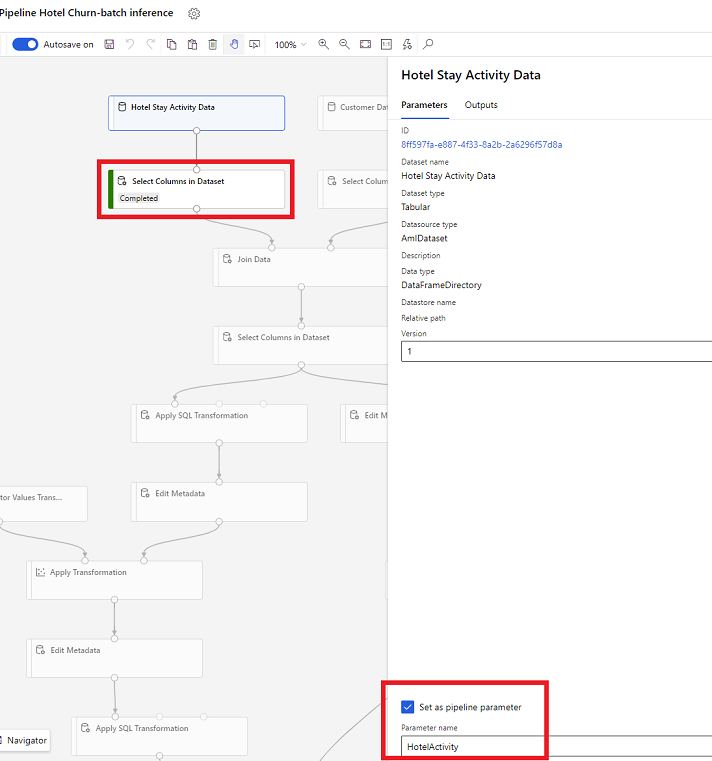
Parametri skupa podataka u Dizajneru
U dizajneru otvorite Odaberi stupce u skupu podataka i odaberite Postavi kao parametar kanala gdje dajete naziv parametra.
Parametar skupa podataka u SDK-u (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Skupni cjevovod za procjenjivanje
U dizajneru koristite kanal za obuku da biste stvorili ili ažurirali cjevovod za zaključivanje. Trenutačno su podržani samo skupni cjevovodi za procjenjivanje.
Pomoću SDK-a objavite kanal na krajnja točka. Trenutno se Customer Insights - Data integrira sa zadanim kanalom u skupnom kanalu krajnja točka u radnom prostoru Strojno učenje.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Uvoz podataka kanala
Dizajner nudi modul Izvoz podataka koji omogućuje izvoz izlaza kanala u spremište servisa Azure. Trenutno modul mora koristiti spremište podataka vrste Azure Blob Storage i parametrizirati spremište podataka i relativniput. Sustav nadjačava oba ova parametra tijekom izvođenja cjevovoda s spremištem podataka i putom koji je dostupan aplikaciji.
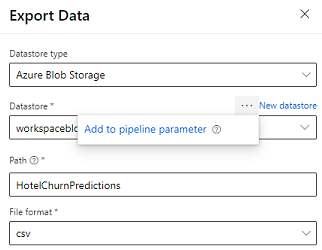
Prilikom pisanja izlaza zaključivanja pomoću koda, prenesite izlaz na put unutar registriranog spremišta podataka u radnom prostoru. Ako su put i spremište podataka parametrizirani u kanalu, Customer Insights može pročitati i uvesti izlaz zaključka. Trenutačno je podržana jedna tablična izlazna vrijednost u formatu csv. Putanja mora sadržavati direktorij i naziv datoteke.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name