Monolitikus adatmegőrzési kizárási minta
Egy alkalmazás összes adatának egyetlen adattárolóba való helyezése hátrányosan befolyásolhatja a teljesítményt, mert erőforrás-versengéshez vezet, vagy mert az adattároló nem alkalmas az adatok egy részének tárolására.
A probléma leírása
Az alkalmazások korábban egyetlen adattárolót használtak, függetlenül attól, hogy az alkalmazásnak adott esetben különböző adattípusokat kellett tárolnia. Ezzel általában az alkalmazás tervezését kívánták leegyszerűsíteni, vagy pedig ez a megoldás felelt meg a fejlesztői csapat ismereteinek.
A modern felhőalapú rendszerek további funkcionális és nem funkcionális követelményekkel rendelkeznek, és sok különféle adattípust kell tárolniuk, például dokumentumokat, képeket, gyorsítótárazott adatokat, üzenetsorokat, alkalmazásnaplókat és telemetriai adatokat. A hagyományos megoldás követése, vagyis az összes fenti információ egyetlen adattárolóba való helyezése negatívan befolyásolja a teljesítményt. Ennek két fő oka van:
- A nagy mennyiségű, egymáshoz nem kapcsolódó adatok egyetlen adattárolóban történő tárolása és lekérése versengést idéz elő, amely lassú válaszidőkhöz és csatlakozási hibákhoz vezet.
- Egy adattároló sem biztosan megfelelő egy adott adattípus tárolásához, illetve előfordulhat, hogy nem az alkalmazás által végzett műveletekhez optimalizálták.
A következő példában egy ASP.NET webes API-vezérlő látható, amely új rekordot ad hozzá egy adatbázishoz, az eredményt pedig feljegyzi egy naplóban. A rendszer ugyanabban az adatbázisban tárolja a naplót, mint az üzleti adatokat. A teljes kódmintát itt találja.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
A naplórekordok létrehozásának sebessége valószínűleg kihat az üzleti műveletek teljesítményére. Ha egy másik összetevő, például egy alkalmazásfolyamat-figyelő rendszeresen olvassa és feldolgozza a naplóadatokat, az szintén kihathat az üzleti tevékenységekre.
A probléma megoldása
Válassza szét az adatokat a felhasználásuk módja szerint. Minden egyes adatkészlethez külön adattárolót válasszon ki, amely a legalkalmasabb az adott adat felhasználási módjához. Az előző példában az alkalmazás naplóját el kell különíteni az üzleti adatokat tartalmazó adatbázistól:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Considerations
Válassza szét az adatokat a felhasználási és hozzáférési módjuk szerint. Ne tároljon például naplózási információkat és üzleti adatokat ugyanabban az adattárban. Ezekre az adatokra ugyanis különböző követelmények vonatkoznak, és a hozzáférési mintáik is eltérnek. A naplórekordok természetüknél fogva szekvenciálisak, míg az üzleti adatok esetében valószínűleg többször van szükség véletlen sorrendű hozzáférésre, és gyakran relációsak.
Tartsa szem előtt az egyes adattípusok adathozzáférési mintáit. A formázott jelentéseket és dokumentumokat például egy dokumentumadatbázisban, például az Azure Cosmos DB-ben tárolhatja, de az Ideiglenes adatok gyorsítótárazásához használja az Azure Cache for Redist .
Ha ezt az útmutatót követve is eléri az adatbázis korlátait, valószínűleg vertikálisan fel kell skáláznia az adatbázist. Érdemes megfontolnia a horizontális skálázást és a terhelés több adatbázis-kiszolgálón történő particionálását is. A particionálás azonban szükségessé teheti az alkalmazás újratervezését. További információért tekintse meg az adatparticionálást ismertető részt.
A probléma észlelése
A rendszer valószínűleg nagymértékben lelassul, végül hibával leáll, mert elfogynak az erőforrások, például az adatbázis-kapcsolatok.
A következő lépéseket végezheti el a hiba okának meghatározásához.
- Alakítsa ki úgy a rendszert, hogy feljegyezze a fő teljesítménystatisztikákat. Rögzítse az egyes műveletek időzítési információit, valamint azokat a pontokat, ahol az alkalmazás adatokat olvas be ír.
- Ha lehetséges, monitorozza a rendszer futását néhány napig éles környezetben, így valós információkat szerezhet a rendszer használatának módjáról. Ha ez nem lehetséges, futtasson szkriptelt terhelési teszteket, amelyek a valóságnak megfelelő számú felhasználó által végzett jellemző művelettípusokat tartalmazzák.
- Használja a telemetriaadatokat a gyenge teljesítmény időszakainak meghatározásához.
- Állapítsa meg, melyik adattárolók voltak használatban az érintett időszakokban.
- Azonosítsa az adattároló-erőforrásokat, amelyek esetleg versengésre kényszerülnek.
Diagnosztikai példa
Az alábbi szakaszokban ezeket a lépéseket hajtjuk végre a fentebb leírt mintaalkalmazáson.
A rendszer kialakítása és monitorozása
A következő diagram a korábban ismertetett mintaalkalmazás terhelési tesztjének eredményeit mutatja be. Ez a teszt lépéses terhelést használt legfeljebb 1000 egyidejű felhasználóval.
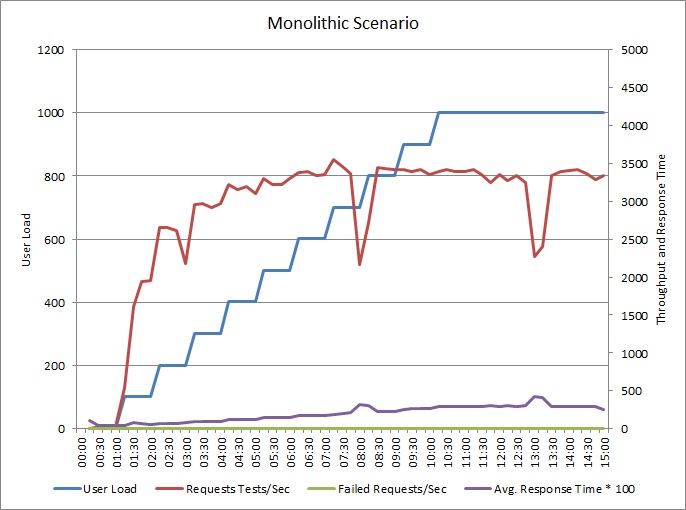
Ahogy a terhelés 700 felhasználóra emelkedik, úgy nő az átviteli teljesítmény is. Az átviteli teljesítmény növekedése itt megáll, a rendszer pedig a jelek szerint maximális kapacitással működik. Az átlagos válaszidő fokozatosan nő a felhasználói terheléssel együtt, ami jelzi, hogy a rendszer nem tud lépést tartani az igényekkel.
A gyenge teljesítmény időszakainak meghatározása
Ha az üzemi környezetet monitorozza, felfigyelhet bizonyos mintákra. Előfordulhat például, hogy a válaszidők jelentősen nőnek minden nap ugyanabban az időben. Ezt okozhatja rendszeres számítási feladat vagy ütemezett kötegelt folyamat, vagy hogy bizonyos időszakokban egyszerűen több felhasználó csatlakozik a rendszerhez. Ilyen esetben tekintse át a telemetriai adatokat.
Keressen összefüggéseket a nagyobb válaszidők, illetve a nagyobb mértékű adatbázis-tevékenység vagy a közös erőforrásokra irányuló I/O között. Ha talál összefüggéseket, lehetséges, hogy az adatbázis a szűk keresztmetszet.
Az érintett időszakokban elért adattárak azonosítása
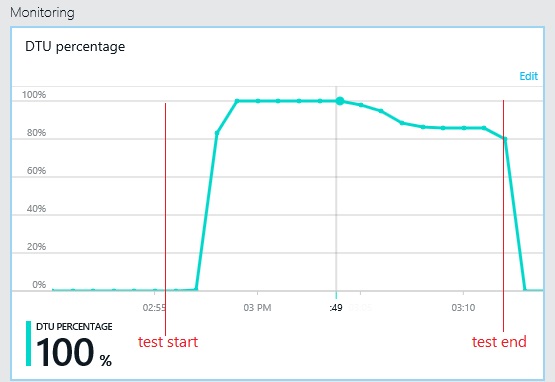
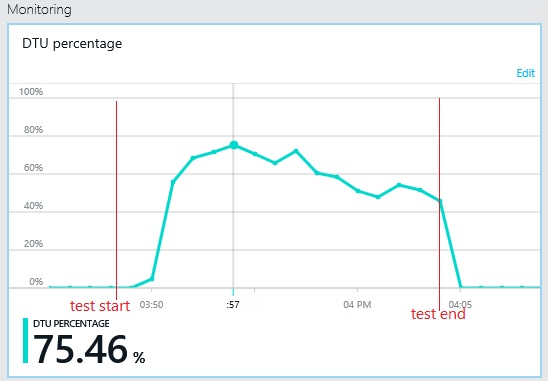
A következő diagramon az adatbázis átviteli egységeinek (DTU) terhelési teszt közbeni felhasználása látható. (A DTU a rendelkezésre álló kapacitás mértéke, és a processzorkihasználtság, a memóriafoglalás és az I/O-sebesség kombinációja.) A DTU-k kihasználtsága gyorsan elérte a 100%-ot. Ez nagyjából az a pont, ahol az átviteli teljesítmény az előző diagramon elérte a maximumot. Az adatbázis kihasználtsága a teszt befejezéséig nagyon magas maradt. A vége felé enyhe csökkenés látható, amelyet a szabályozás, az adatbázis-kapcsolatokért folytatott versengés vagy egyéb tényezők okozhattak.
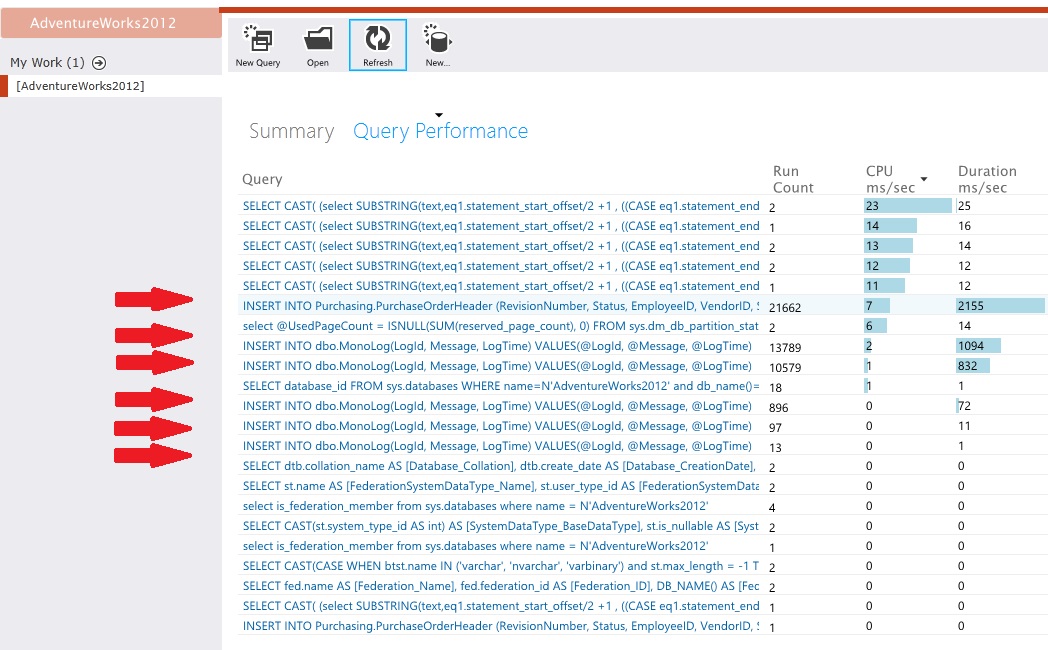
Az adattárolók telemetriai vizsgálata
Alakítsa ki az adattárolókat úgy, hogy részletesen rögzítsék a tevékenységeket. A mintaalkalmazásban az adathozzáférési statisztikák nagy számú beszúrási műveleteket mutattak a PurchaseOrderHeader és a MonoLog táblában is.
Az erőforrás-versengés azonosítása
Megkeresheti a forráskódban azokat a pontokat, ahol az alkalmazás olyan erőforrásokhoz fér hozzá, amelyekért versengés folyik. Keressen a következőkhöz hasonló helyzeteket:
- Logikailag különálló adat, amelyet a rendszer ugyanazon tárolóba ír. A naplók, jelentések, üzenetsorok és egyéb hasonló adatokat nem ajánlott ugyanabban az adatbázisban tartani, mint az üzleti információkat.
- Eltérés az adattároló típusa és az adat típusa között, például ha nagyméretű blobok vagy XML-dokumentumok találhatók egy relációs adatbázisban.
- Lényegesen eltérő felhasználási mintájú adatok vannak egyazon tárolóban, például magas írású/alacsony olvasású és alacsony írású/magas olvasású adatok.
A megoldás megvalósítása és az eredmény ellenőrzése
Az alkalmazás módosítva lett, hogy külön adattárolóba írja a naplókat. Itt láthatók a terhelési teszt eredményei:
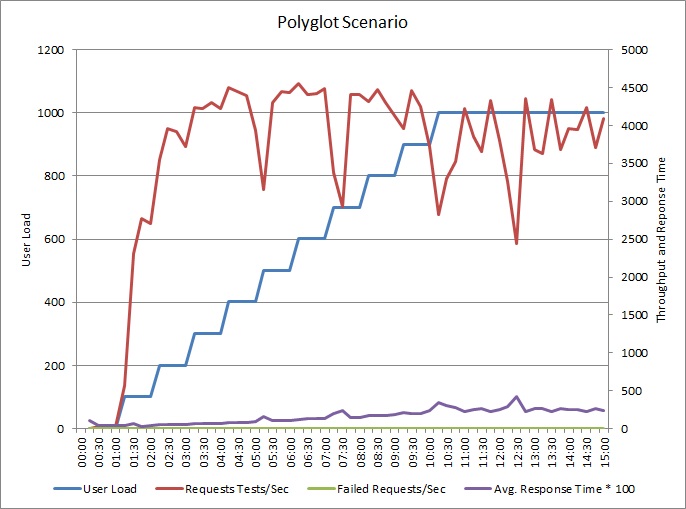
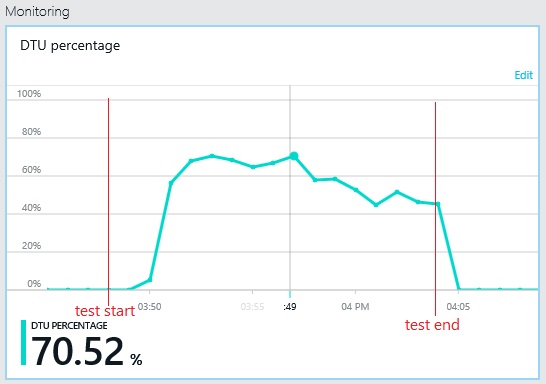
Az átviteli teljesítmény mintája hasonló az előző diagramon látotthoz, de a maximális teljesítmény körülbelül 500 kérés/másodperccel magasabb terhelésnél következik be. Az átlagos válaszidő valamivel alacsonyabb. Azonban ezekből a statisztikákból nem derül ki minden. Az üzleti adatbázis telemetriája azt mutatja, hogy a DTU-felhasználás nem 100, hanem 75%-nál éri el a maximumot.
Hasonló módon a naplóadatbázis maximális DTU-kihasználtsága csak 70% körüli értéket ér el. Az adatbázisok már nem korlátozzák a rendszer teljesítményét.
Kapcsolódó erőforrások
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: