Ez a referenciaarchitektúra bemutatja, hogyan taníthat be javaslatmodelleket az Azure Databricks használatával, majd hogyan helyezheti üzembe a modellt API-ként az Azure Cosmos DB, az Azure Machine Tanulás és az Azure Kubernetes Service (AKS) használatával. Az architektúra referencia-implementációját a GitHubon valós idejű javaslati API létrehozása című témakörben talál.
Architektúra

Töltse le az architektúra Visio-fájlját.
Ez a referenciaarchitektúra egy valós idejű ajánló szolgáltatás API betanítására és üzembe helyezésére szolgál, amely a 10 legjobb filmjavaslatot nyújtja a felhasználó számára.
Adatfolyam
- Felhasználói viselkedés nyomon követése. Előfordulhat például, hogy egy háttérszolgáltatás naplózza, ha egy felhasználó egy filmet díjaz, vagy egy termékre vagy hírcikkre kattint.
- Töltse be az adatokat az Azure Databricksbe egy elérhető adatforrásból.
- Készítse elő az adatokat, és ossza fel őket betanítási és tesztelési csoportokra a modell betanításához. (Ez az útmutató az adatok felosztásának lehetőségeit ismerteti.)
- A Spark együttműködési szűrési modelljének igazítása az adatokhoz.
- Értékelje ki a modell minőségét minősítési és rangsorolási metrikák használatával. (Ez az útmutató részletesen ismerteti azokat a metrikákat, amelyekkel kiértékelheti az ajánlót.)
- A felhasználónkénti 10 javaslat előkomponálása és gyorsítótárként való tárolása az Azure Cosmos DB-ben.
- Api-szolgáltatás üzembe helyezése az AKS-ben a Machine Tanulás API-k használatával az API tárolóba helyezéséhez és üzembe helyezéséhez.
- Amikor a háttérszolgáltatás kérést kap egy felhasználótól, hívja meg az AKS-ben üzemeltetett recommendations API-t, hogy megkapja a 10 legjobb javaslatot, és megjelenítse őket a felhasználónak.
Összetevők
- Azure Databricks. A Databricks egy fejlesztési környezet, amellyel bemeneti adatokat készíthet elő, és betanítsa az ajánló modellt egy Spark-fürtön. Az Azure Databricks emellett interaktív munkaterületet is biztosít a jegyzetfüzetek futtatásához és együttműködéséhez bármilyen adatfeldolgozási vagy gépi tanulási feladathoz.
- Azure Kubernetes Service (AKS). Az AKS egy Gépi tanulási modell szolgáltatás API üzembe helyezésére és üzembe helyezésére szolgál egy Kubernetes-fürtön. Az AKS üzemelteti a tárolóalapú modellt, amely skálázhatóságot biztosít, amely megfelel az átviteli sebesség követelményeinek, az identitás- és hozzáférés-kezelésnek, valamint a naplózásnak és az állapotfigyelésnek.
- Azure Cosmos DB. Az Azure Cosmos DB egy globálisan elosztott adatbázis-szolgáltatás, amellyel minden felhasználó számára a 10 legjobban ajánlott film tárolható. Az Azure Cosmos DB kiválóan alkalmas erre a forgatókönyvre, mivel alacsony késést biztosít (10 ms a 99. percentilisnél), hogy elolvassa az adott felhasználó számára ajánlott legfontosabb elemeket.
- Gépi tanulás. Ez a szolgáltatás gépi tanulási modellek nyomon követésére és kezelésére, majd a modellek skálázható AKS-környezetbe való csomagolására és üzembe helyezésére szolgál.
- Microsoft-ajánlók. Ez a nyílt forráskódú adattár segédprogramkódot és mintákat tartalmaz, amelyek segítenek a felhasználóknak az ajánlórendszer kiépítésében, kiértékelésében és üzembe helyezésében.
Forgatókönyv részletei
Ez az architektúra általánosítható a legtöbb javaslatmotor-forgatókönyvhez, beleértve a termékekre, filmekre és hírekre vonatkozó javaslatokat.
Lehetséges használati esetek
Forgatókönyv: A médiaszervezet film- vagy videóajánlatokat szeretne nyújtani a felhasználóknak. A személyre szabott javaslatok révén a szervezet számos üzleti célnak tesz eleget, beleértve a megnövekedett átkattintási arányt, a webhelyen való nagyobb részvételt és a nagyobb felhasználói elégedettséget.
Ez a megoldás a kiskereskedelmi iparágra, valamint a média- és szórakoztatóiparra van optimalizálva.
Megfontolások
Ezek a szempontok implementálják az Azure Well-Architected Framework alappilléreit, amely a számítási feladatok minőségének javítására használható vezérelvek halmaza. További információ: Microsoft Azure Well-Architected Framework.
Az Azure Databricks Spark-modelljeinek kötegelt pontozása egy referenciaarchitektúrát ír le, amely a Spark és az Azure Databricks használatával végez ütemezett kötegelt pontozási folyamatokat. Ezt a megközelítést javasoljuk új javaslatok létrehozásához.
Teljesítmény hatékonysága
A teljesítménybeli hatékonyság lehetővé teszi, hogy a számítási feladatok hatékonyan méretezhetők legyenek a felhasználók igényei szerint. További információ: Teljesítményhatékonysági pillér áttekintése.
A valós idejű javaslatok elsődleges szempontja a teljesítmény, mivel a javaslatok általában a webhely felhasználói kéréseinek kritikus útjára esnek.
Az AKS és az Azure Cosmos DB kombinációja lehetővé teszi, hogy ez az architektúra jó kiindulópontot nyújtson egy közepes méretű számítási feladathoz, minimális többletterhelés mellett. Ez az architektúra egy 200 egyidejű felhasználóval végzett terheléses teszt során körülbelül 60 ms átlagos késéssel nyújt javaslatokat, és másodpercenként 180 kérést teljesít. A terhelési tesztet az alapértelmezett üzembehelyezési konfiguráción futtatták (egy 3x D3 v2 AKS-fürt 12 virtuális processzorral, 42 GB memóriával és 11 000 kérelemegységtel (RU- val) az Azure Cosmos DB-hez kiépített másodpercenként .
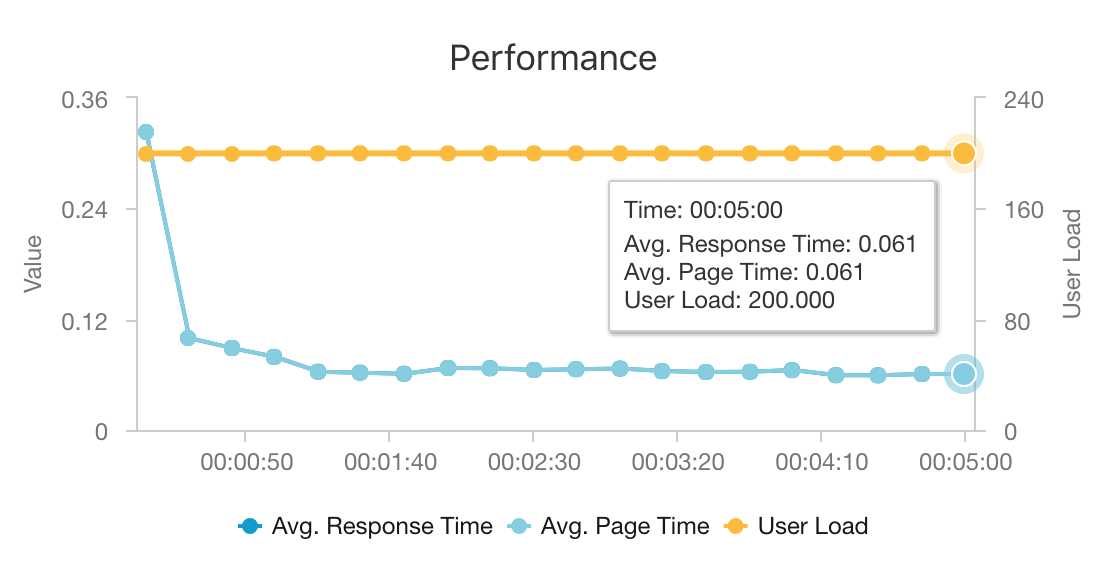
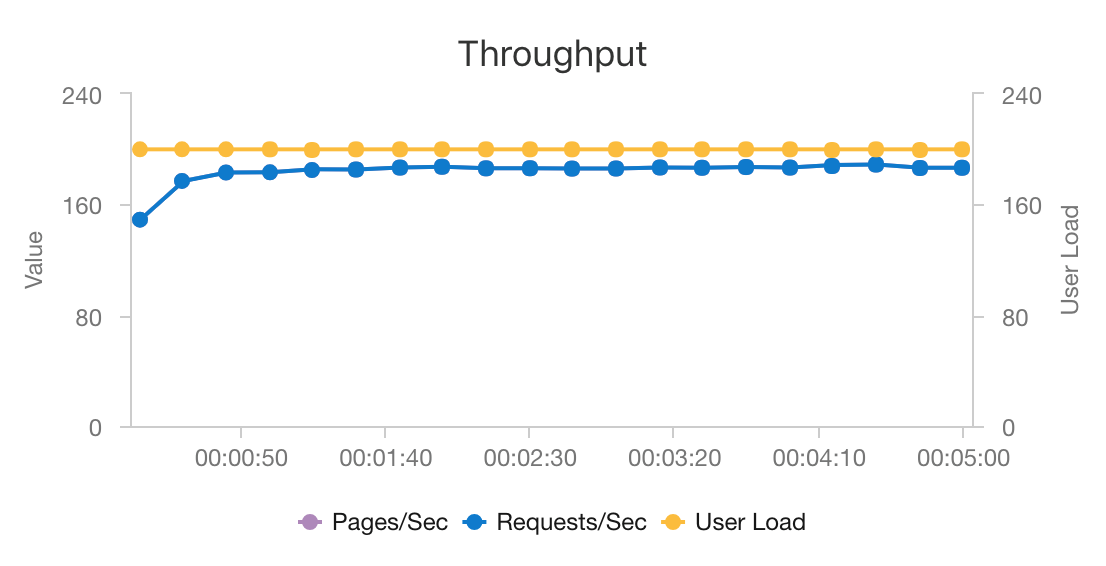
Az Azure Cosmos DB kulcsrakész globális terjesztéséhez és hasznosságához ajánlott az alkalmazás által támasztott adatbázis-követelmények teljesítése során. A késés kismértékben csökkentése érdekében fontolja meg az Azure Cache for Redis használatát az Azure Cosmos DB helyett a keresések kiszolgálásához. Az Azure Cache for Redis javíthatja azon rendszerek teljesítményét, amelyek nagymértékben támaszkodnak a háttértárak adataira.
Méretezhetőség
Ha nem tervezi a Spark használatát, vagy kisebb számítási feladattal rendelkezik, amely nem igényel elosztást, fontolja meg egy Adattudomány virtuális gép (DSVM) használatát az Azure Databricks helyett. A DSVM egy Azure-beli virtuális gép, amely mélytanulási keretrendszerekkel és eszközökkel rendelkezik a gépi tanuláshoz és az adatelemzéshez. Az Azure Databrickshez hasonlóan a DSVM-ben létrehozott modellek szolgáltatásként is üzembe telepíthetők az AKS-en a Machine Tanulás keresztül.
A betanítás során vagy hozzon létre egy nagyobb, rögzített méretű Spark-fürtöt az Azure Databricksben, vagy konfigurálja az automatikus skálázást. Ha az automatikus skálázás engedélyezve van, a Databricks figyeli a fürt terhelését, és igény szerint fel- és leskálázható. Nagyobb fürt kiépítése vagy vertikális felskálázása, ha nagy adatmérettel rendelkezik, és csökkenteni szeretné az adat-előkészítési vagy modellezési feladatokhoz szükséges időt.
Skálázza az AKS-fürtöt a teljesítményre és az átviteli sebességre vonatkozó követelményeknek megfelelően. Ügyeljen arra, hogy a fürt teljes kihasználtsága érdekében skálázza fel a podok számát, és skálázza a fürt csomópontjait a szolgáltatás igényeinek megfelelően. Az automatikus skálázásT AKS-fürtön is beállíthatja. További információ: Modell üzembe helyezése Azure Kubernetes Service-fürtön.
Az Azure Cosmos DB teljesítményének kezeléséhez becsülje meg a másodpercenként szükséges olvasások számát, és adja meg a másodpercenként szükséges kérelemegységek számát (átviteli sebesség). Ajánlott eljárások a particionáláshoz és a horizontális skálázáshoz.
Költségoptimalizálás
A költségoptimalizálás a szükségtelen kiadások csökkentésének és a működési hatékonyság javításának módjairól szól. További információ: A költségoptimalizálási pillér áttekintése.
Ebben a forgatókönyvben a költségek fő mozgatórugói a következők:
- A betanításhoz szükséges Azure Databricks-fürtméret.
- A teljesítménykövetelményeknek való megfeleléshez szükséges AKS-fürtméret.
- A teljesítménykövetelményeknek megfelelően kiépített Azure Cosmos DB RU-k.
Az Azure Databricks költségeinek kezelése a ritkábban végzett újratanítással és a Spark-fürt használaton kívüli kikapcsolásával. Az AKS és az Azure Cosmos DB költségei a webhely által igényelt átviteli sebességhez és teljesítményhez vannak kötve, és a webhely felé történő forgalom mennyiségétől függően fel- és leskálázhatók.
A forgatókönyv üzembe helyezése
Az architektúra üzembe helyezéséhez kövesse a beállítási dokumentumban található Azure Databricks-utasításokat. Röviden, az utasítások megkövetelik, hogy:
- Azure Databricks-munkaterület létrehozása.
- Hozzon létre egy új fürtöt az alábbi konfigurációval az Azure Databricksben:
- Fürt mód: Standard
- Databricks futtatókörnyezet verziója: 4.3 (tartalmazza az Apache Spark 2.3.1-et, a Scala 2.11-et)
- Python-verzió: 3
- Illesztőprogram típusa: Standard_DS3_v2
- Feldolgozó típusa: Standard_DS3_v2 (minimális és maximális igény szerint)
- Automatikus leállítás: (igény szerint)
- Spark-konfiguráció: (igény szerint)
- Környezeti változók: (igény szerint)
- Hozzon létre egy személyes hozzáférési jogkivonatot az Azure Databricks-munkaterületen. Részletekért tekintse meg az Azure Databricks hitelesítési dokumentációját .
- Klónozza a Microsoft Recommenders-adattárat egy olyan környezetbe, ahol szkripteket futtathat (például a helyi számítógépet).
- Kövesse a gyors telepítési telepítési utasításokat a megfelelő kódtárak Azure Databricksre való telepítéséhez.
- Az Azure Databricks üzembe helyezésének előkészítéséhez kövesse a gyors telepítés telepítési utasításait.
- Importálja az ALS Movie Operationalization jegyzetfüzetet a munkaterületre. Miután bejelentkezett az Azure Databricks-munkaterületre, tegye a következőket:
- Kattintson a munkaterület bal oldalán található Kezdőlap gombra.
- Kattintson a jobb gombbal a kezdőkönyvtárban lévő üres területre. Válassza az Importálás lehetőséget.
- Válassza ki az URL-címet, és illessze be a következőt a szövegmezőbe:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Kattintson az Importálás elemre.
- Nyissa meg a jegyzetfüzetet az Azure Databricksben, és csatolja a konfigurált fürtöt.
- Futtassa a jegyzetfüzetet a javaslati API létrehozásához szükséges Azure-erőforrások létrehozásához, amelyek az adott felhasználó számára a 10 legjobb filmjavaslatot biztosítják.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerzők:
- Miguel Fierro | Egyszerű adattudós-kezelő
- Nikhil Joglekar | Product Manager, Azure-algoritmusok és adatelemzés
A nem nyilvános LinkedIn-profilok megtekintéséhez jelentkezzen be a LinkedInbe.
Következő lépések
- Valós idejű javaslati API létrehozása
- Mi az az Azure Databricks?
- Azure Kubernetes Service
- Bevezetés az Azure Cosmos DB-e
- Mi az Azure Machine Learning?