Azure Databricks-fürtök regionális vészhelyreállítása
Ez a cikk az Azure Databricks-fürtök számára hasznos vészhelyreállítási architektúrát és a tervezés lépéseit ismerteti.
Az Azure Databricks architektúrája
Amikor Azure Databricks-munkaterületet hoz létre az Azure Portalról, a felügyelt alkalmazás Azure-erőforrásként lesz üzembe helyezve az előfizetésében, a kiválasztott Azure-régióban (például az USA nyugati régiójában). Ez a berendezés egy Azure-beli virtuális hálózaton van üzembe helyezve egy hálózati biztonsági csoporttal és egy Azure Storage-fiókkal, amely elérhető az előfizetésében. A virtuális hálózat szegélyszintű biztonságot biztosít a Databricks-munkaterület számára, és hálózati biztonsági csoporton keresztül védi. A munkaterületen databricks-fürtöket hozhat létre a feldolgozó és illesztőprogram virtuálisgép-típusának és a Databricks futtatókörnyezet verziójának megadásával. A tárolt adatok a tárfiókban érhetők el. A fürt létrehozása után a feladatokat jegyzetfüzeteken, REST API-kon vagy ODBC/JDBC-végpontokon keresztül futtathatja úgy, hogy egy adott fürthöz csatolja őket.
A Databricks vezérlősík kezeli és figyeli a Databricks-munkaterület környezetét. Minden felügyeleti művelet( például fürt létrehozása) a vezérlősíkról indul el. Az összes metaadat, például az ütemezett feladatok egy Azure Database-ben vannak tárolva, és az adatbázis biztonsági másolatai automatikusan georeplikálva lesznek a párosított régiókba , ahol implementálva van.
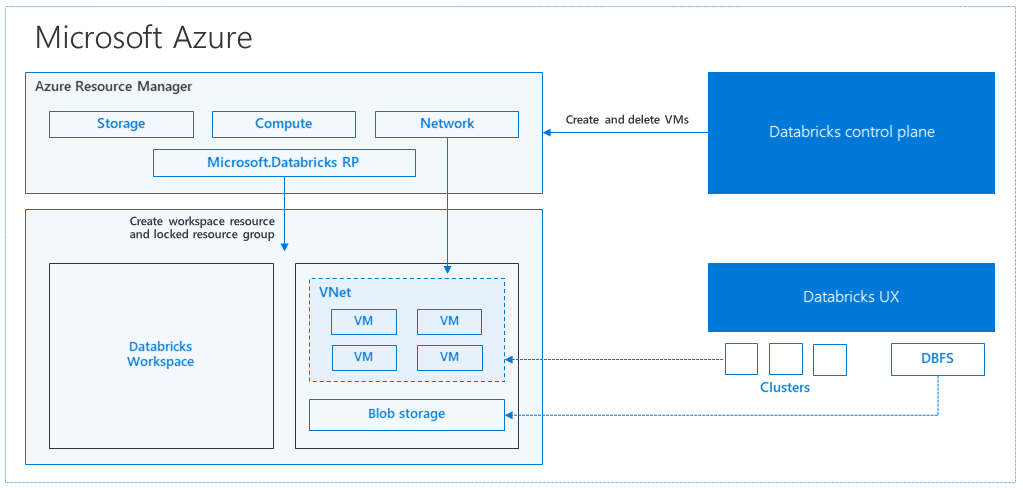
Az architektúra egyik előnye, hogy a felhasználók az Azure Databrickset a fiókjukban lévő bármely tárolási erőforráshoz csatlakoztathatják. A legfontosabb előnye, hogy a számítás (Azure Databricks) és a tárolás egymástól függetlenül skálázható.
Regionális vészhelyreállítási topológia létrehozása
Az előző architektúra leírásában számos összetevőt használunk egy Big Data-folyamathoz az Azure Databricks használatával: Azure Storage, Azure Database és más adatforrások. Az Azure Databricks a Big Data-folyamat számítása . Ez rövides természetű, ami azt jelenti, hogy amíg az adatok továbbra is elérhetők az Azure Storage-ban, a számítás (Azure Databricks-fürt) leállhat, hogy ne kelljen fizetnie a számításért, ha nincs rá szüksége. A számítási (Azure Databricks) és a tárolási forrásoknak ugyanabban a régióban kell lenniük, hogy a feladatok ne tapasztalják a nagy késést.
Saját regionális vészhelyreállítási topológia létrehozásához kövesse az alábbi követelményeket:
Több Azure Databricks-munkaterület kiépítése külön Azure-régiókban. Például hozza létre az elsődleges Azure Databricks-munkaterületet az USA keleti régiójában. Hozza létre a másodlagos vészhelyreállítási Azure Databricks-munkaterületet egy külön régióban, például az USA nyugati régiójában. A párosított Azure-régiók listájáért tekintse meg a régiók közötti replikációt. Az Azure Databricks-régiókkal kapcsolatos részletekért lásd a támogatott régiókat.
Georedundáns tárolás használata. Alapértelmezés szerint az Azure Databrickshez társított adatok az Azure Storage-ban vannak tárolva, a Databricks-feladatok eredményei pedig az Azure Blob Storage-ban vannak tárolva, így a feldolgozott adatok tartósak, és a fürt leállítása után is magas rendelkezésre állásúak maradnak. A fürttároló és a feladattároló ugyanabban a rendelkezésre állási zónában található. A regionális elérhetetlenség elleni védelem érdekében az Azure Databricks-munkaterületek alapértelmezés szerint georedundáns tárolást használnak. Georedundáns tárolás esetén az adatok replikálódnak egy Azure-párosított régióba. A Databricks azt javasolja, hogy tartsa meg a georedundáns tárolás alapértelmezett értékét, de ha ehelyett helyileg redundáns tárolást kell használnia, beállíthatja
storageAccountSkuNameStandard_LRSa munkaterület ARM-sablonjában .A másodlagos régió létrehozása után át kell telepítenie a felhasználókat, a felhasználói mappákat, a jegyzetfüzeteket, a fürtkonfigurációt, a feladatok konfigurációját, a tárakat, a tárakat, az inicializálási szkripteket és a hozzáférés-vezérlés újrakonfigurálását. A további részleteket a következő szakaszban ismertetjük.
Regionális katasztrófa
A regionális katasztrófákra való felkészüléshez explicit módon fenn kell tartania egy másik Azure Databricks-munkaterületet egy másodlagos régióban. Lásd: Vészhelyreállítás.
A vészhelyreállításhoz ajánlott eszközök elsősorban a Terraform (az infrareplikációhoz) és a Delta Deep Clone (adatreplikációhoz).
Részletes migrálási lépések
A Databricks parancssori felületének beállítása a számítógépen
Ez a cikk számos olyan kódpéldát mutat be, amelyek a parancssori felületet használják az automatizált lépések többségéhez, mivel ez egy könnyen kezelhető burkoló az Azure Databricks REST API-val.
A migrálási lépések végrehajtása előtt telepítse a databricks-cli-t az asztali számítógépre vagy egy olyan virtuális gépre, ahol el szeretné végezni a munkát. További információ: A Databricks parancssori felület telepítése
pip install databricks-cliFeljegyzés
A cikkben szereplő python-szkriptek várhatóan a Python 2.7+ < 3.x-et is használhatják.
Konfiguráljon két profilt.
Konfiguráljon egyet az elsődleges munkaterülethez, egy másikat a másodlagos munkaterülethez:
databricks configure --profile primary --token databricks configure --profile secondary --tokenA cikkben szereplő kódblokkok a megfelelő munkaterületi paranccsal váltanak a profilok között minden további lépésben. Győződjön meg arról, hogy a létrehozott profilok nevei minden kódblokkra fel lesznek cserélve.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"Szükség esetén manuálisan is válthat a parancssorban:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMicrosoft Entra-azonosító (korábbi nevén Azure Active Directory) felhasználóinak migrálása
Adja hozzá manuálisan ugyanazokat a Microsoft Entra-azonosítót (korábbi nevén Azure Active Directory-felhasználókat) az elsődleges munkaterületen található másodlagos munkaterülethez.
A felhasználói mappák és jegyzetfüzetek migrálása
A következő Python-kóddal migrálhatja a tesztkörnyezeteket, amelyek tartalmazzák a beágyazott mappastruktúrát és a felhasználónkénti jegyzetfüzeteket.
Feljegyzés
Ebben a lépésben a kódtárak nem lesznek átmásolva, mivel a mögöttes API nem támogatja ezeket.
Másolja és mentse a következő Python-szkriptet egy fájlba, majd futtassa a Databricks parancssorában. Például:
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")A fürtkonfigurációk migrálása
A jegyzetfüzetek migrálása után igény szerint áttelepítheti a fürtkonfigurációkat az új munkaterületre. Ez szinte teljesen automatizált lépés a databricks-cli használatával, hacsak nem szeretne szelektív fürtkonfigurációs migrálást végezni, nem pedig mindenki számára.
Feljegyzés
Sajnos nincs fürtkonfigurációs végpont, és ez a szkript azonnal megpróbálja létrehozni az egyes fürtöket. Ha nem áll rendelkezésre elegendő mag az előfizetésben, a fürt létrehozása meghiúsulhat. A hiba figyelmen kívül hagyható, amíg a konfiguráció sikeresen át lesz helyezve.
A következő szkript a régi és az új fürtazonosítók közötti leképezést nyomtatja ki, amelyek később a feladatmigráláshoz használhatók (meglévő fürtök használatára konfigurált feladatok esetén).
Másolja és mentse a következő Python-szkriptet egy fájlba, majd futtassa a Databricks parancssorában. Például:
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")A feladatok konfigurációjának migrálása
Ha az előző lépésben migrálta a fürtkonfigurációkat, a feladatkonfigurációkat áttelepítheti az új munkaterületre. Ez egy teljesen automatizált lépés a databricks-cli használatával, hacsak nem szeretne szelektív feladatkonfigurációs migrálást végezni ahelyett, hogy minden feladathoz elvégezné.
Feljegyzés
Az ütemezett feladatok konfigurációja tartalmazza az "ütemezési" információkat is, így alapértelmezés szerint a migrálás után a konfigurált időzítésnek megfelelően fog működni. Ezért a következő kódblokk eltávolít minden ütemezési információt az áttelepítés során (a régi és az új munkaterületek ismétlődő futtatásainak elkerülése érdekében). Ha készen áll az átállásra, konfigurálja az ilyen feladatok ütemezését.
A feladatkonfigurációhoz új vagy meglévő fürt beállításaira van szükség. Meglévő fürt használata esetén az alábbi szkript /kód megpróbálja lecserélni a régi fürtazonosítót új fürtazonosítóra.
Másolja és mentse a következő Python-szkriptet egy fájlba. Cserélje le az és
new_cluster_id, értéketold_cluster_idaz előző lépésben elvégzett fürtmigrálás kimenetére. Futtassa például a databricks-cli parancssorbanpython scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Kódtárak migrálása
Jelenleg nem lehet egyszerűen áttelepíteni a kódtárakat egyik munkaterületről a másikra. Ehelyett telepítse újra ezeket a kódtárakat manuálisan az új munkaterületre. A DBFS CLI kombinációjával automatizálható az egyéni kódtárak feltöltése a munkaterületre és a Kódtárak parancssori felületére.
Azure Blob Storage- és Azure Data Lake Storage-csatlakoztatások migrálása
Az Azure Blob Storage és az Azure Data Lake Storage (Gen 2) csatlakoztatási pontjainak manuális csatlakoztatása jegyzetfüzetalapú megoldással. A tárolóerőforrások az elsődleges munkaterületen lettek volna csatlakoztatva, és ezt meg kell ismételni a másodlagos munkaterületen. A csatlakoztatásokhoz nincs külső API.
Fürt init szkriptjeinek migrálása
A fürt inicializálási szkriptjei a DBFS parancssori felületével migrálhatók a régiről az új munkaterületre. Először másolja a szükséges szkripteket
dbfs:/dat abricks/init/..a helyi asztalra vagy virtuális gépre. Ezután másolja ezeket a szkripteket az új munkaterületre ugyanazon az útvonalon.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryManuálisan konfigurálja újra és alkalmazza újra a hozzáférés-vezérlést.
Ha a meglévő elsődleges munkaterület a Prémium vagy a Nagyvállalati szint (SKU) használatára van konfigurálva, akkor valószínűleg a Hozzáférés-vezérlés funkciót is használja.
Ha a Hozzáférés-vezérlés funkciót használja, manuálisan alkalmazza újra a hozzáférés-vezérlést az erőforrásokhoz (jegyzetfüzetek, fürtök, feladatok, táblák).
Azure-ökoszisztéma vészhelyreállítása
Ha más Azure-szolgáltatásokat használ, mindenképpen implementáljon vészhelyreállítási ajánlott eljárásokat ezekhez a szolgáltatásokhoz is. Ha például külső Hive-metaadattár-példányt használ, érdemes megfontolnia az Azure SQL Database, az Azure HDInsight és/vagy az Azure Database for MySQL vészhelyreállítását. A vészhelyreállítással kapcsolatos általános információkért tekintse meg az Azure-alkalmazások vészhelyreállítását ismertető témakört.
Következő lépések
További információkért tekintse meg az Azure Databricks dokumentációját.