Az Azure Databricks használata felhőalapú elemzéseken belül az Azure-ban
Az Azure Databricks a Microsoft Azure Cloud Services platformra optimalizált adatelemzési platform. Az Azure Databricks két környezetet kínál az adatintenzív alkalmazások fejlesztéséhez:
Az Azure Databricks SQL lehetővé teszi gyors alkalmi SQL-lekérdezések futtatását a data lake-en.
Az Azure Databricks Adattudomány & mérnöki (más néven egyszerűen "Workspace") egy Apache Sparkon alapuló elemzési platform. Az Azure-ral integrálva egykattintásos beállítási, egyszerűsített munkafolyamatokat és egy interaktív munkaterületet biztosít, amely lehetővé teszi az adatmérnökök, adattudósok és gépi tanulási mérnökök közötti együttműködést.
A felhőalapú elemzések esetében az Azure Databricks Adattudomány > Mérnöki szolgáltatásra összpontosítunk.
Áttekintés
Minden üzembe helyezett adat-kezdőzóna esetében lehetősége van két megosztott munkaterület üzembe helyezésére. Az egyik az adatelemzéshez, a másik az elemzéshez.
- A betöltéshez és feldolgozáshoz használt Azure Databricks mérnöki munkaterület Azure-szolgáltatásneveken keresztül csatlakozik az Azure Data Lake-hez. Ezt az adatelemzés hívja meg.
- Az Azure Databricks-elemzési munkaterület minden adatelemző és adatműveleti csapat számára kiépíthető. Ez a munkaterület a Microsoft Entra átmenő hitelesítésével csatlakozna az Azure Data Lake-hez. Az Azure Databricks-elemzési és adatelemzési munkaterületet az adat-kezdőzónában oszthatja meg az összes olyan felhasználóval, aki hozzáfér a munkaterülethez.
Ha automatizált adatbetöltési motorral rendelkezik, az Azure Databricks mérnöki munkaterülete az Azure metaadat-szolgáltatás erőforráscsoportjában létrehozott Azure Key Vault-példányt használja az adatbetöltési folyamatok nyersről gazdagítottra való futtatásához.
Az Azure Databricks-elemzési munkaterületnek olyan fürtszabályzatokkal kell rendelkeznie, amelyek megkövetelik, hogy magas egyidejűségi fürtöket hozzon létre. Ez a fürttípus lehetővé teszi a Data Lake megismerését a Microsoft Entra hitelesítő adatok átadásának használatával. További információ: Hozzáférés-vezérlés és data lake-konfigurációk az Azure Data Lake Storage-ban.
Az Azure Databricks konfigurálása
Az Azure Databricks üzembe helyezése részben paraméteralapú egy Azure Resource Manager-sablonnal és YAML-szkriptekkel, de az összes munkaterület konfigurálásához manuális beavatkozásra is szükség van.
Minden Azure Databricks-munkaterületnek a prémium csomagot kell használnia, amely a következő szükséges funkciókat biztosítja:
- Számítások optimalizált automatikus méretezése
- Microsoft Entra hitelesítő adatok átmenő hitelesítése
- Feltételes hitelesítés
- Szerepköralapú hozzáférés-vezérlés jegyzetfüzetekhez, fürtökhöz, feladatokhoz és táblákhoz
- Audit logs
A felhőalapú elemzésekhez való igazodás érdekében javasoljuk, hogy minden munkaterületen az alábbi alapértelmezett üzembehelyezési beállítások legyenek konfigurálva:
- Az Azure Databricks-munkaterületek egy külső Apache Hive metaadattár-példányhoz csatlakoznak az adat-kezdőzónában.
- Az egyes munkaterületek konfigurálása a Databricks diagnosztikai naplózásának az Azure Log Analyticsbe való küldéséhez a databricks-monitoring-rg fájlban
- Fürtszabályzatok implementálása a fürtök szabályokon alapuló létrehozásának korlátozására. További információ: Fürtszabályzatok kezelése.
- Több fürtszabályzat definiálása. Az előkészítési folyamat részeként rendeljen hozzá minden célcsoport-engedélyt az adat-kezdőzóna-üzemeltetési csapat általi használatra. Alapértelmezés szerint a fürtlétrehozási engedélyt csak az operatív csapat kapja meg. Különböző csapatok vagy csoportok kapnak engedélyt a fürtszabályzatok használatára.
- A fürtszabályzatok és az Azure Databricks-készletek együttes használatával csökkentheti a fürtindítási és automatikus skálázási időket a kihasználatlan, használatra kész példányok fenntartásával. További információ: Készletek.
- Egy Azure Key Vault-példányból lekérheti az Összes Azure Databricks-üzemeltetési titkos kulcsot, például az SPN-hitelesítő adatokat és a kapcsolati sztring.
- Munkaterületenként konfiguráljon külön vállalati alkalmazást az SCIM-hez (tartományközi identitáskezeléshez). Az Azure Databricks-munkaterületre mutató hivatkozás az egyes munkaterületek hozzáférésének és engedélyeinek szabályozásához. További információ: Felhasználók és csoportok kiépítése SCIM használatával és SCIM-kiépítés konfigurálása a Microsoft Entra-azonosítóhoz.
Figyelmeztetés
Ha nem konfigurálja az Azure Databricks-munkaterületet az Azure Databricks SCIM-felület használatára, az hatással van a biztonsági vezérlők biztosítására. Automatizált folyamatról manuális folyamatra változik, és megszakítja az összes üzembe helyezési CI-/CD-folyamatot.
Az összes Databricks-munkaterülethez a következő hozzáférés-vezérlési beállítások vannak beállítva:
- Munkaterület láthatósági vezérlője: engedélyezve (alapértelmezett: letiltva)
- Fürt láthatóságának vezérlése: engedélyezve (alapértelmezett: letiltva)
- Feladat láthatóságának vezérlése: engedélyezve (alapértelmezett: letiltva)
Az Azure Databricks Analytics-munkaterületen a következő beállításokat érdemes engedélyezni:
- Jegyzetfüzet exportálása: letiltva (alapértelmezett: engedélyezve)
- Jegyzetfüzettábla vágólap funkciói: letiltva (alapértelmezett: engedélyezve)
- Táblahozzáférés-vezérlés: engedélyezve (alapértelmezett: letiltva)
- Microsoft Entra feltételes hozzáférés
Az Azure Databricks üzembe helyezése
Ha az Azure Databricks-munkaterületeket egy új adat-kezdőzóna üzembe helyezése részeként helyezi üzembe. Az alábbi képen egy Azure Databricks-környezet felhőalapú elemzésben való üzembe helyezésének minta-munkafolyamata látható.
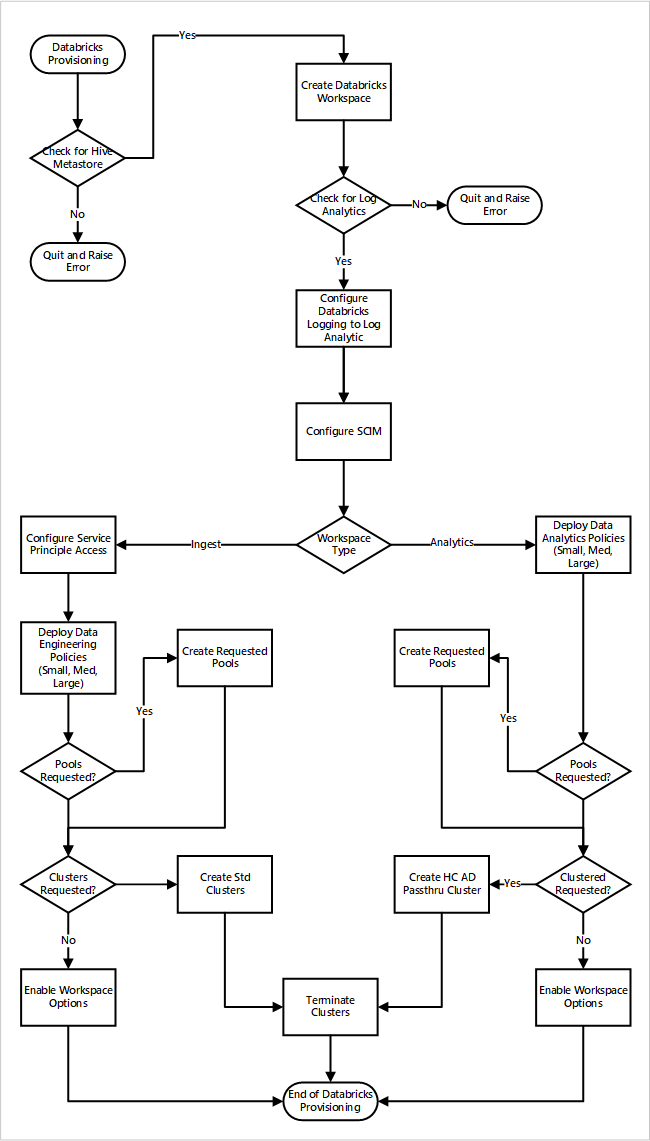
- A kiépítési folyamat először ellenőrzi, hogy létezik-e Apache Hive metaadattár-példány az adat-kezdőzónában. Ha nem találja az Apache Hive metaadattárat, kilép, és hibát jelez.
- Az Apache Hive metaadattár sikeres megkeresése után létrejön egy munkaterület.
- A folyamat egy Log Analytics-munkaterületet keres az adat-kezdőzónában. Ha nem találja a Log Analytics-munkaterületet, kilép, és hibát jelez.
- Minden munkaterülethez létrehoz egy Microsoft Entra-alkalmazást, és konfigurálja az SCIM-et.
Az Azure Databricks betöltési munkaterülete esetén:
- A folyamat konfigurálja a munkaterületet a szolgáltatásnév-hozzáféréssel.
- Az adatplatform-üzemeltetési csapat által definiált adatmérnöki szabályzatok üzembe vannak helyezve.
- Ha az adat-kezdőzóna műveleti csapata Databricks-készleteket vagy -fürtöket kért, azokat integrálhatja az üzembe helyezési folyamatba.
- Lehetővé teszi az Azure Databricks mérnöki munkaterületre vonatkozó munkaterületi beállításokat.
Az Azure Databricks-elemzési munkaterület esetében:
- A folyamat olyan adatelemzési szabályzatokat helyez üzembe, amelyeket az adatplatform-üzemeltetési csapat definiált.
- Ha az adat-kezdőzóna műveleti csapata Databricks-készleteket vagy -fürtöket kért, azokat integrálhatja az üzembe helyezési folyamatba.
- Lehetővé teszi az Azure Databricks mérnöki munkaterületre vonatkozó munkaterületi beállításokat.
Külső Hive-metaadattár
Azure Databricks-munkaterület üzembe helyezésében:
- Egy új globális init-szkript konfigurálja az Apache Hive metaadattár-beállításait az összes fürthöz. Ezt a szkriptet az új globális init szkriptek API kezeli.
Az új globális init scripts API nyilvános előzetes verzióban érhető el. Az Azure Databricks nyilvános előzetes funkciói készen állnak az éles környezetekre, és a támogatási csapat támogatja. További információkért tekintse meg az Azure Databricks előzetes kiadásait.
- Ez a megoldás az Azure Database for MySQL használatával tárolja az Apache Hive metaadattár-példányt. Ezt az adatbázist a költséghatékonyság és az Apache Hive-lel való magas kompatibilitás érdekében választották ki.
További lépések
A felhőalapú elemzés az alábbi irányelveket veszi figyelembe az Azure Databricks integrálásához: