Támogatott fájlformátumok és tömörítési kodekek az Azure Data Factoryben és a Synapse Analyticsben (örökölt)
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk a következő összekötőkre vonatkozik: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, Fájlrendszer, FTP, Google Cloud Storage, HDFS, HTTP és SFTP.
Fontos
A szolgáltatás új formátumalapú adatkészletmodellt vezetett be. További részletekért tekintse meg a megfelelő formázási cikket:
- Avro formátum
- Bináris formátum
- Tagolt szövegformátum
- JSON formátum
- ORC formátum
- Parquet formátum
A cikkben említett többi konfiguráció továbbra is támogatott a visszamenőleges kompatibilitás szempontjából. Javasoljuk, hogy használja az új modellt.
Szövegformátum (örökölt)
Megjegyzés:
Ismerje meg az új modellt a tagolt szövegformátumú cikkből. A fájlalapú adattáradatkészlet alábbi konfigurációi továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy használja az új modellt.
Ha szövegfájlból szeretne olvasni, vagy szövegfájlba szeretne írni, állítsa az typeformat adathalmaz szakaszában lévő tulajdonságot TextFormat értékre. Emellett megadhatja a következő választható tulajdonságokat a format szakaszban. A konfigurálással kapcsolatban lásd A TextFormat használatát bemutató példa című szakaszt.
| Property | Leírás | Megengedett értékek | Szükséges |
|---|---|---|---|
| columnDelimiter | A fájlokban az oszlopok elválasztására használt karakter. Érdemes lehet olyan ritka nyomtathatatlan karaktert használni, amely nem feltétlenül létezik az adataiban. Adja meg például a "\u0001" értéket, amely a címsor kezdetét (SOH) jelöli. | Csak egy karakter használata engedélyezett. Az alapértelmezett érték a vessző (,). Unicode-karakterek használatához a Unicode-karakterekre hivatkozva szerezze be a megfelelő kódot. |
Nem |
| rowDelimiter | A fájlokban a sorok elválasztására használt karakter. | Csak egy karakter használata engedélyezett. Az alapértelmezett érték olvasáskor a következő értékek bármelyike: [„\r\n”, „\r”, „\n”], illetve „\r\n” írás esetén. | Nem |
| escapeChar | Az oszlophatároló feloldására szolgáló speciális karakter a bemeneti fájl tartalmában. Egy táblához nem határozható meg az escapeChar és a quoteChar is. |
Csak egy karakter használata engedélyezett. Nincs alapértelmezett érték. Például: ha vessző (',) van az oszlopelválasztóként, de a szövegben vessző karaktert szeretne használni (például: "Hello, world"), definiálhatja a "$" karaktert menekülési karakterként, és használhatja a "Hello$, world" sztringet a forrásban. |
Nem |
| quoteChar | Egy sztringérték idézéséhez használt karakter. Ekkor az idézőjel-karakterek közötti oszlop- és sorhatárolókat a rendszer a sztringérték részeként kezeli. Ez a tulajdonság a bemeneti és a kimeneti adatkészleteken is alkalmazható. Egy táblához nem határozható meg az escapeChar és a quoteChar is. |
Csak egy karakter használata engedélyezett. Nincs alapértelmezett érték. Ha például vesszőt ('') használ oszlopelválasztóként, de vessző karaktert szeretne használni a szövegben (például: <Hello, world>), akkor a " (kettős idézőjel) karaktert idézőjelként definiálhatja, és a forrásban a "Hello, world" sztringet használhatja. |
Nem |
| nullValue | A null értéket jelölő egy vagy több karakter. | Egy vagy több karakter. Az alapértelmezett értékek az „\N” és „NULL” olvasás, illetve „\N” írás esetén. | Nem |
| encodingName | A kódolási név megadására szolgál. | Egy érvényes kódolási név. Lásd az Encoding.EncodingName tulajdonságot. Például: windows-1250 vagy shift_jis. Az alapértelmezett érték az UTF-8. | Nem |
| firstRowAsHeader | Megadja, hogy az első sort fejlécnek kell-e tekinteni. Bemeneti adatkészlet esetén a szolgáltatás az első sort fejlécként olvassa be. Kimeneti adatkészlet esetén a szolgáltatás fejlécként írja az első sort. A firstRowAsHeader és a skipLineCount használatára vonatkozó forgatókönyvekben tekinthet meg minta-forgatókönyveket. |
Igaz False (alapértelmezett) |
Nem |
| skipLineCount | A bemeneti fájlokból származó adatok olvasásakor kihagyandó nem üres sorok számát jelzi. Ha a skipLineCount és a firstRowAsHeader tulajdonság is meg van adva, a rendszer először kihagyja a sorokat, majd beolvassa a fejléc-információkat a bemeneti fájlból. A firstRowAsHeader és a skipLineCount használatára vonatkozó forgatókönyvekben tekinthet meg minta-forgatókönyveket. |
Egész | Nem |
| treatEmptyAsNull | Meghatározza, hogy az adatok bemeneti fájlból történő olvasásakor a sztring null vagy üres értékeit null értékként kell-e kezelni. | True (alapértelmezett) Hamis |
Nem |
A TextFormat használatát bemutató példa
Az adathalmaz alábbi JSON-definíciójában a választható tulajdonságok némelyike meg van adva.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
quoteChar helyett quoteChar használatához cserélje le a sort escapeChar értékre a következő escapeChar kifejezéssel:
"escapeChar": "$",
A firstRowAsHeader és a skipLineCount használatára vonatkozó forgatókönyvek
- Egy nem fájlalapú forrásból másol egy szöveges fájlba, és szeretne hozzáadni egy fejlécsort, amely tartalmazza a séma (például SQL-séma) metaadatait. Ebben a forgatókönyvben adja meg a
firstRowAsHeaderértékét igazként a kimeneti adatkészletben. - Egy fejlécsort tartalmazó szöveges fájlból másol egy nem fájlalapú fogadóba, és el szeretné hagyni azt a sort. Adja meg a
firstRowAsHeaderértékét igazként a bemeneti adatkészletben. - Egy szöveges fájlból másol, és szeretne kihagyni néhány sort az elejéről, amelyek nem tartalmaznak adatokat vagy fejléc-információkat. Adja meg a
skipLineCountértékét a kihagyni kívánt sorok számának jelzéséhez. Ha a fájl hátralévő része fejlécsort tartalmaz, afirstRowAsHeaderis megadható. Ha askipLineCountés afirstRowAsHeaderis meg van adva, a rendszer először kihagyja a sorokat, majd beolvassa a fejléc-információkat a bemeneti fájlból
JSON formátum (örökölt)
Megjegyzés:
Ismerje meg az új modellt a JSON formátumú cikkből. A fájlalapú adattáradatkészlet alábbi konfigurációi továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy használja az új modellt.
JSON-fájlok importálása/exportálása az Azure Cosmos DB-be vagy onnan történő importálásához/exportálásához tekintse meg az Adatok áthelyezése az Azure Cosmos DB-be vagy onnan az Azure Cosmos DB-be című cikk JSON-dokumentumok importálása/exportálása című szakaszát.
Ha szeretné elemezni a JSON-fájlokat, vagy JSON formátumban szeretné írni az adatokat, állítsa a typeformat szakaszban lévő tulajdonságot JsonFormat értékre. Emellett megadhatja a következő választható tulajdonságokat a format szakaszban. A konfigurálással kapcsolatban lásd A JsonFormat használatát bemutató példa című szakaszt.
| Property | Leírás | Required |
|---|---|---|
| filePattern | Az egyes JSON-fájlokban tárolt adatok mintáját jelzi. Az engedélyezett értékek a következők: setOfObjects és arrayOfObjects. Az alapértelmezett érték a setOfObjects. A mintákkal kapcsolatban lásd a JSON-fájlminták című szakaszt. | Nem |
| jsonNodeReference | Ha egy azonos mintával rendelkező tömbmezőben található objektumokat szeretne iterálni, vagy azokból adatokat kinyerni, adja meg a tömb JSON-útvonalát. Ez a tulajdonság csak JSON-fájlokból történő adatmásoláskor támogatott. | Nem |
| jsonPathDefinition | Megadja az egyes oszlopmegfeleltetések JSON-útvonalának kifejezését testre szabott oszlopnevekkel (kezdje kisbetűvel). Ez a tulajdonság csak JSON-fájlokból másolt adatok esetén támogatott, és adatokat nyerhet ki objektumból vagy tömbből. A gyökérobjektum alatti mezők esetében kezdjen a gyökér $ értékkel. A jsonNodeReference tulajdonság által kiválasztott tömbben lévő mezők esetében kezdjen a tömbelemmel. A konfigurálással kapcsolatban lásd A JsonFormat használatát bemutató példa című szakaszt. |
Nem |
| encodingName | A kódolási név megadására szolgál. Az érvényes kódolási nevekkel kapcsolatban lásd az Encoding.EncodingName tulajdonságot. Például: windows-1250 vagy shift_jis. Az alapértelmezett érték az UTF-8. | Nem |
| nestingSeparator | A beágyazási szinteket elválasztó karakter. Az alapértelmezett érték a „.” (pont). | Nem |
Megjegyzés:
Ha a tömbben lévő adatokat több sorba helyezi át (1. eset –> 2. példa JsonFormat-példákban), akkor csak egy tömb kibontását választhatja a tulajdonság jsonNodeReferencehasználatával.
JSON-fájlminták
Copy tevékenység a következő JSON-fájlok mintáit elemezheti:
I. típus: setOfObjects
Minden fájl egyetlen objektumot, illetve több, sorokkal határolt/összefűzött objektumot tartalmaz. Ha ezt a lehetőséget választja egy kimeneti adatkészletben, a másolási tevékenység egyetlen JSON-fájlt állít elő, soronként egy objektummal (sorokkal határolt).
példa egy objektumot tartalmazó JSON-fájlra
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }példa sorokkal határolt JSON-fájlra
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}példa összefűzött JSON-fájlra
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
II. típus: arrayOfObjects
Minden fájl objektumok egy tömbjét tartalmazza.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
A JsonFormat használatát bemutató példa
1. eset: Adatok másolása JSON-fájlokból
1. példa: adatok kigyűjtése objektumból és tömbből
Ebben a példában egy JSON-gyökérobjektum képződik le egyetlen rekordba táblázatos nézetben. Ha a JSON-fájl a következőt tartalmazza:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
és az adatok objektumokból és tömbökből való kigyűjtésével szeretné átmásolni egy Azure SQL-táblába az alábbi formátumban:
| Azonosító | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
A JsonFormat típusú bemeneti adatkészlet a következőképpen van meghatározva (részleges meghatározás, csak a fontos részekkel). Pontosabban:
- A
structureszakasz határozza meg a testre szabott oszlopneveket és a megfelelő adattípusokat, miközben átalakítja őket táblázatos adatokká. Ez a szakasz nem kötelező, kivéve, ha oszlopleképezést kell végeznie. További információ: Forrásadatkészlet-oszlopok leképezése céladatkészletoszlopokra. - A
jsonPathDefinitionhatározza meg az egyes oszlopok JSON-útvonalát, amely jelzi, hogy honnan történjen az adatok kinyerése. Ha adatokat szeretne másolni a tömbből, az adott tulajdonság értékét kinyerhetiarray[x].propertyazxthobjektumból, vagy megkereshetiarray[*].propertyaz értéket az ilyen tulajdonságot tartalmazó bármely objektumból.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
2. példa: a tömbből származó ugyanazon minta keresztalkalmazása több objektumra
Ebben a példában egy JSON-gyökérobjektumot alakít át több rekorddá táblázatos nézetben. Ha a JSON-fájl a következőt tartalmazza:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
és szeretné átmásolni egy Azure SQL-táblába az alábbi formátumban, a tömbben lévő adatok egybesimításával, valamint keresztillesztést létrehozni a közös gyökérinformációval:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
A JsonFormat típusú bemeneti adatkészlet a következőképpen van meghatározva (részleges meghatározás, csak a fontos részekkel). Pontosabban:
- A
structureszakasz határozza meg a testre szabott oszlopneveket és a megfelelő adattípusokat, miközben átalakítja őket táblázatos adatokká. Ez a szakasz nem kötelező, kivéve, ha oszlopleképezést kell végeznie. További információ: Forrásadatkészlet-oszlopok leképezése céladatkészletoszlopokra. jsonNodeReferenceazt jelzi, hogy a tömborderlinesalatt azonos mintájú objektumokból iteráljon és nyerjen ki adatokat.- A
jsonPathDefinitionhatározza meg az egyes oszlopok JSON-útvonalát, amely jelzi, hogy honnan történjen az adatok kinyerése. Ebben a példábanordernumberorderdatecitya JSON-elérési úttal kezdődőorder_price$.order_pd, a tömbelemből$.származó elérési úttal definiált és a nélküle lévő JSON-elérési úttal rendelkező gyökérobjektum alatt van.
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Vegye figyelembe a következő szempontokat:
- Ha a
structuremásolási tevékenység észleli az első objektum sémáját, ésjsonPathDefinitionnincs definiálva az adathalmazban, akkor a másolási tevékenység észleli az első objektum sémáját, és elsimíthatja az egész objektumot. - Ha a JSON-bemenet egy tömböt tartalmaz, a másolási tevékenység alapértelmezés szerint a tömb teljes értékét egy sztringgé alakítja át. Választhatja, hogy a
jsonNodeReferenceés/vagy ajsonPathDefinitionhasználatával kívánja kinyerni belőle az adatokat, vagy ki is hagyhatja ezt a műveletet, ha nem adja meg ajsonPathDefinitionértékét. - Ha ismétlődő nevek szerepelnek ugyanazon a szinten, a másolási tevékenység az utolsót választja ki.
- A tulajdonságnevek megkülönböztetik a kis- és nagybetűket. A rendszer két azonos nevű, de eltérő kis- és nagybetűket tartalmazó tulajdonságot két különálló tulajdonságként kezel.
2. eset: Adatok írása JSON-fájlba
Ha az SQL Database-ben a következő táblázat található:
| Azonosító | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000. | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
és minden rekord esetében a következő formátumban kell írnia egy JSON-objektumba:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
A JsonFormat típusú kimeneti adatkészlet a következőképpen van meghatározva (részleges meghatározás, csak a fontos részekkel). Pontosabban a structure szakasz a célfájlban definiálja a testreszabott tulajdonságneveket, nestingSeparator (az alapértelmezett érték a ".") a névből származó beágyazott réteg azonosítására szolgál. Ez a szakasz nem kötelező, kivéve, ha módosítani szeretné a tulajdonság nevét a forrásoszlop nevéhez képest, vagy egyes tulajdonságokat egymásba szeretne ágyazni.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet formátum (örökölt)
Megjegyzés:
Ismerje meg az új modellt a Parquet formátumcikkből. A fájlalapú adattáradatkészlet alábbi konfigurációi továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy használja az új modellt.
Ha elemezni szeretné a Parquet-fájlokat, vagy Parquet formátumban szeretne adatokat írni, állítsa a formattype tulajdonságot ParquetFormat értékre. Nem kell meghatároznia semmilyen tulajdonságot a Format szakaszban a typeProperties szakaszon belül. Példa:
"format":
{
"type": "ParquetFormat"
}
Vegye figyelembe a következő szempontokat:
- Az összetett adattípusok nem támogatottak (MAP, LIST).
- Az oszlopnévben lévő üres terület nem támogatott.
- A Parquet-fájlok a következő tömörítéshez kapcsolódó beállításokat használják: NONE, SNAPPY, GZIP és LZO. A szolgáltatás támogatja a Parquet-fájlból származó adatok olvasását ezen tömörített formátumok bármelyikében, kivéve az LZO-t – a metaadatokban lévő tömörítési kodek használatával olvassa be az adatokat. Parquet-fájlba való íráskor azonban a szolgáltatás a SNAPPY-t választja, amely a Parquet formátum alapértelmezett formátuma. Jelenleg nincs lehetőség ennek a viselkedésnek a felülírására.
Fontos
A saját üzemeltetésű integrációs futtatókörnyezet (például a helyszíni és a felhőbeli adattárak közötti) másoláshoz, ha nem parquet-fájlokat másol, telepítenie kell a 64 bites JRE 8-at (Java Runtime Environment) vagy az OpenJDK-t az integrációs modul gépére. További részletekért lásd a következő bekezdést.
A Parquet-fájlszerializálással/deszerializálással futtatott saját üzemeltetésű integrációs modulon futó példányok esetében a szolgáltatás megkeresi a Java-futtatókörnyezetet, először ellenőrizze a JRE beállításjegyzékét (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) , ha nem található, másodszor pedig ellenőrizze az OpenJDK rendszerváltozóit JAVA_HOME .
- A JRE használatához: A 64 bites integrációs modulhoz 64 bites JRE szükséges. Innen megtalálhatja.
- Az OpenJDK használata: az INTEGRÁCIÓ 3.13-as verziója óta támogatott. Csomagolja be a jvm.dll fájlt az OpenJDK minden más szükséges szerelvényével egy saját üzemeltetésű integrációs modulba, és ennek megfelelően állítsa be a rendszerkörnyezet változóját JAVA_HOME.
Tipp.
Ha saját üzemeltetésű integrációs modullal másol adatokat a Parquet formátumba vagy onnan, és "Hiba történt a java meghívásakor, üzenet: java.lang.OutOfMemoryError:Java halomterület" hibaüzenet jelenik meg, hozzáadhat egy környezeti változót _JAVA_OPTIONS a saját üzemeltetésű integrációs modult futtató géphez, hogy módosítsa a JVM minimális/maximális halomméretét a másolás engedélyezése érdekében, majd futtassa újra a folyamatot.
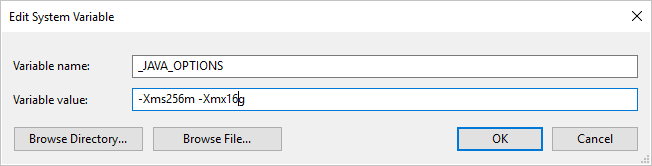
Példa: állítsa be a változót _JAVA_OPTIONS értékként -Xms256m -Xmx16g. A jelölő Xms a Java virtuális gép (JVM) kezdeti memóriafoglalási készletét adja meg, míg Xmx a maximális memóriafoglalási készletet határozza meg. Ez azt jelenti, hogy a JVM a memória mennyiségével Xms lesz elindítva, és maximális Xmx mennyiségű memóriát fog tudni használni. Alapértelmezés szerint a szolgáltatás min. 64 MB-ot és legfeljebb 1G-t használ.
Adattípus-leképezés Parquet-fájlokhoz
| Köztes szolgáltatás adattípusa | Parquet Primitív típus | Parquet Original Type (Deserialize) | Parquet Original Type (Szerializálás) |
|---|---|---|---|
| Logikai | Logikai | N.A. | N.A. |
| SByte | Int32 | Int8 | Int8 |
| Bájt | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/Binary | UInt64 | Decimális |
| Egyszeres | Lebegőpontos értékek | N.A. | N.A. |
| Dupla | Dupla | N.A. | N.A. |
| Decimális | Bináris | Decimális | Decimális |
| Sztring | Bináris | Utf8 | Utf8 |
| DateTime | Int96 | N.A. | N.A. |
| időtartam | Int96 | N.A. | N.A. |
| DateTimeOffset | Int96 | N.A. | N.A. |
| ByteArray | Bináris | N.A. | N.A. |
| GUID | Bináris | Utf8 | Utf8 |
| Char | Bináris | Utf8 | Utf8 |
| CharArray | Nem támogatott | N.A. | N.A. |
ORC formátum (örökölt)
Megjegyzés:
Ismerje meg az új modellt az ORC formátumcikkből. A fájlalapú adattáradatkészlet alábbi konfigurációi továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy használja az új modellt.
Ha elemezni szeretné a ORC-fájlokat, vagy ORC formátumban szeretne adatokat írni, állítsa a formattype tulajdonságot OrcFormat értékre. Nem kell meghatároznia semmilyen tulajdonságot a Format szakaszban a typeProperties szakaszon belül. Példa:
"format":
{
"type": "OrcFormat"
}
Vegye figyelembe a következő szempontokat:
- Az összetett adattípusok nem támogatottak (STRUCT, MAP, LIST, UNION).
- Az oszlopnévben lévő üres terület nem támogatott.
- Az ORC-fájlok három, tömörítéshez kapcsolódó beállítással rendelkeznek: NONE, ZLIB, SNAPPY. A szolgáltatás támogatja az ORC-fájlból származó adatok olvasását ezen tömörített formátumok bármelyikében. Az adatok olvasásához a metaadatokban szereplő tömörítési kodeket használja. ORC-fájlba való íráskor azonban a szolgáltatás a ZLIB-t választja, amely az ORC alapértelmezett értéke. Jelenleg nincs lehetőség ennek a viselkedésnek a felülírására.
Fontos
A saját üzemeltetésű integrációs futtatókörnyezet (például a helyszíni és a felhőbeli adattárak közötti) másoláshoz, ha nem az ORC-fájlokat másolja, telepítenie kell a 64 bites JRE 8-at (Java Futtatókörnyezet) vagy az OpenJDK-t az integrációs modul gépére. További részletekért lásd a következő bekezdést.
A saját üzemeltetésű integrációs modulon orc fájlszerializálással/deszerializálással futtatott példány esetében a szolgáltatás megkeresi a Java-futtatókörnyezetet, először ellenőrizze a JRE beállításjegyzékét (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) , ha nem található, másodszor pedig ellenőrizze az OpenJDK rendszerváltozóit JAVA_HOME .
- A JRE használatához: A 64 bites integrációs modulhoz 64 bites JRE szükséges. Innen megtalálhatja.
- Az OpenJDK használata: az INTEGRÁCIÓ 3.13-as verziója óta támogatott. Csomagolja be a jvm.dll fájlt az OpenJDK minden más szükséges szerelvényével egy saját üzemeltetésű integrációs modulba, és ennek megfelelően állítsa be a rendszerkörnyezet változóját JAVA_HOME.
ORC-fájlok adattípus-leképezése
| Köztes szolgáltatás adattípusa | ORC-típusok |
|---|---|
| Logikai | Logikai |
| SByte | Bájt |
| Bájt | Rövid |
| Int16 | Rövid |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | Sztring |
| Egyszeres | Lebegőpontos értékek |
| Dupla | Dupla |
| Decimális | Decimális |
| Sztring | Sztring |
| DateTime | Timestamp |
| DateTimeOffset | Timestamp |
| időtartam | Timestamp |
| ByteArray | Bináris |
| GUID | Sztring |
| Char | Char(1) |
AVRO formátum (örökölt)
Megjegyzés:
Ismerje meg az új modellt az Avro formátumcikkből. A fájlalapú adattáradatkészlet alábbi konfigurációi továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy használja az új modellt.
Ha elemezni szeretné a Avro-fájlokat, vagy Avro formátumban szeretne adatokat írni, állítsa a formattype tulajdonságot AvroFormat értékre. Nem kell meghatároznia semmilyen tulajdonságot a Format szakaszban a typeProperties szakaszon belül. Példa:
"format":
{
"type": "AvroFormat",
}
Ha Avro-formátumot szeretne használni Egy Hive-táblában, tekintse meg az Apache Hive oktatóanyagát.
Vegye figyelembe a következő szempontokat:
- Az összetett adattípusok (rekordok, enumerálások, tömbök, térképek, egyesítők és rögzítettek) nem támogatottak.
Tömörítés támogatása (örökölt)
A szolgáltatás támogatja az adatok tömörítését/felbontását a másolás során. Amikor tulajdonságot ad meg compression egy bemeneti adatkészletben, a másolási tevékenység beolvassa a tömörített adatokat a forrásból, és kibontja azokat, és amikor megadja a tulajdonságot egy kimeneti adatkészletben, a másolási tevékenység tömöríti, majd adatokat ír a fogadóba. Íme néhány példaforgatókönyv:
- GZIP-tömörített adatok olvasása egy Azure-blobból, kibontása és eredményadatok írása az Azure SQL Database-be. A bemeneti Azure Blob-adatkészletet GZIP-ként definiálja a
compressiontypetulajdonsággal. - Egyszerű szöveges fájlból származó adatok beolvasása a helyszíni fájlrendszerből, GZip-formátummal való tömörítés, és a tömörített adatok azure-blobba írása. A kimeneti Azure Blob-adatkészletet GZip-ként definiálja a
compressiontypetulajdonsággal. - Olvassa el a .zip fájlt az FTP-kiszolgálóról, bontsa ki, hogy beolvassa a fájlokat, és helyezze el őket az Azure Data Lake Store-ban. A bemeneti FTP-adatkészletet ZipDeflate néven definiálja a
compressiontypetulajdonsággal. - GZIP-tömörített adatok beolvasása egy Azure-blobból, kibontása, tömörítése a BZIP2 használatával, és eredményadatok írása egy Azure-blobba. A bemeneti Azure Blob-adatkészletet GZIP értékre
compressiontype, a kimeneti adatkészletet pedig BZIP2 értékrecompressiontypeállítja.
Az adathalmaz tömörítésének megadásához használja a JSON adathalmaz tömörítési tulajdonságát az alábbi példához hasonlóan:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
A tömörítési szakasz két tulajdonsággal rendelkezik:
Típus: a tömörítési kodek, amely lehet GZIP, Deflate, BZIP2 vagy ZipDeflate. Vegye figyelembe, hogy a ZipDeflate fájl(ok) tömörítéséhez és fájlalapú fogadóadattárba való íráshoz másolási tevékenység esetén a fájlok a következő mappába lesznek kinyerve:
<path specified in dataset>/<folder named as source zip file>/.Szint: a tömörítési arány, amely lehet optimális vagy leggyorsabb.
Leggyorsabb: A tömörítési műveletnek a lehető leggyorsabban végre kell hajtania, még akkor is, ha az eredményül kapott fájl nincs optimálisan tömörítve.
Optimális: A tömörítési műveletet optimálisan kell tömöríteni, még akkor is, ha a művelet végrehajtása hosszabb időt vesz igénybe.
További információ: Tömörítési szint témakör.
Megjegyzés:
Az AvroFormat, az OrcFormat vagy a ParquetFormat adatai nem támogatják a tömörítési beállításokat. Ha ilyen formátumban olvas fájlokat, a szolgáltatás észleli és használja a metaadatok tömörítési kodekét. Amikor ilyen formátumú fájlokba ír, a szolgáltatás kiválasztja a formátum alapértelmezett tömörítési kodekét. Például: ZLIB for OrcFormat és SNAPPY for ParquetFormat.
Nem támogatott fájltípusok és tömörítési formátumok
A bővíthetőségi funkciókkal átalakíthatja a nem támogatott fájlokat. Két lehetőség közül választhat az Azure Functions és az Egyéni feladatok az Azure Batch használatával.
Látható egy minta, amely egy Azure-függvényt használ egy tar-fájl tartalmának kinyeréséhez. További információ: Azure Functions-tevékenység.
Ezt a funkciót egyéni dotnet-tevékenységekkel is létrehozhatja. További információ itt érhető el
Kapcsolódó tartalom
Ismerje meg a támogatott fájlformátumok és tömörítések legújabb támogatott fájlformátumait és tömörítéseit.