Oktatóanyag: Az Apache Spark strukturált stream használata az Apache Kafkával a HDInsighton
Ez az oktatóanyag bemutatja, hogyan használható az Apache Spark strukturált streamelése adatok olvasására és írására az Apache Kafkával az Azure HDInsighton.
A Spark Strukturált streamelés egy Spark SQL-n alapuló streamfeldolgozó motor. Lehetővé teszi, hogy ugyanúgy fejezze ki a streamszámításokat, mint a kötegelt számításokat a statikus adatok esetében.
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Fürtök létrehozása Azure Resource Manager-sablonnal
- Spark strukturált streamelés használata a Kafkával
Ha végzett a dokumentum lépéseivel, ne felejtse el törölni a fürtöket a többletköltségek elkerülése érdekében.
Előfeltételek
jq, egy parancssori JSON-processzor. Lásd: https://stedolan.github.io/jq/.
A Jupyter Notebooks és a Spark on HDInsight használatának ismerete. További információ: Adatok betöltése és lekérdezések futtatása az Apache Spark on HDInsight-dokumentummal .
A Scala programozási nyelv ismerete. Az oktatóanyagban használt kód Scala nyelven van megírva.
A Kafka-témakörök létrehozásának ismerete. További információ: Apache Kafka on HDInsight – rövid útmutató .
Fontos
A dokumentum lépéseihez egy olyan Azure-erőforráscsoport szükséges, amely Spark on HDInsight- és Kafka on HDInsight-fürtöt is tartalmaz. Mindkét fürt Azure virtuális hálózatban található, így a Spark-fürt közvetlenül kommunikálhat a Kafka-fürttel.
A kényelmes használat érdekében ez a dokumentum tartalmaz egy hivatkozást egy olyan sablonra, amellyel az összes szükséges Azure-erőforrás létrehozható.
A HDInsight virtuális hálózatban való használatáról további információt a HDInsight virtuális hálózatának megtervezése című dokumentumban talál.
Strukturált streamelés az Apache Kafkával
A Spark strukturált stream egy, a Spark SQL-motorra épülő streamfeldolgozó rendszer. Strukturált streamelés használatakor ugyanúgy írhat streamlekérdezéseket, mint a kötegelt lekérdezéseket.
Az alábbi kódrészletek az adatok Kafkából való beolvasását és fájlban való tárolását mutatják be. Az első egy köteg-, míg a második egy streamelési művelet:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
Mindkét kódrészlet a Kafkából olvassa be az adatokat, majd fájlba írja azokat. A két példa közötti különbségek:
| Batch | Streamelés |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
A streamelési művelet is használ awaitTermination(30000), amely 30 000 ms után leállítja a streamet.
A strukturált streamelés a Kafkával való használatához a projektnek függőségi viszonyban kell lennie az org.apache.spark : spark-sql-kafka-0-10_2.11 csomaggal. A csomag verziójának egyeznie kell a Spark on HDInsight verziójával. A Spark 2.4 esetében (amely a HDInsight 4.0-s verziójában érhető el) a különböző projekttípusok függőségi információi a következő helyen https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjartalálhatók: .
Az oktatóanyagban használt Jupyter Notebook esetében a következő cella tölti be ezt a csomagfüggőséget:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
A fürtök létrehozása
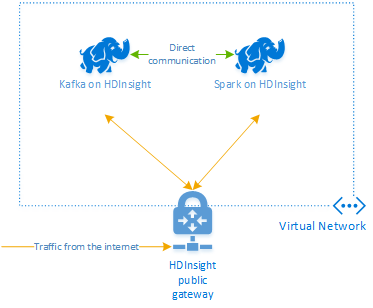
A HDInsighton futó Apache Kafka nem biztosít hozzáférést a Kafka-közvetítőkhöz a nyilvános interneten keresztül. A Kafkát használó minden eszköznek ugyanabban az Azure virtuális hálózatban kell lennie. Ebben az oktatóanyagban a Kafka- és a Spark-fürtök is ugyanabban az Azure virtuális hálózatban szerepelnek.
Az alábbi ábra a Spark és a Kafka közötti kommunikáció áramlását mutatja be.
Feljegyzés
A Kafka szolgáltatás a virtuális hálózaton belüli kommunikációra van korlátozva. A fürtön lévő többi szolgáltatás, például az SSH és az Ambari az interneten keresztül is elérhető. További információ a HDInsighttal elérhető nyilvános portokról: A HDInsight által használt portok és URI-k.
Azure-beli virtuális hálózat, majd az abban lévő Kafka- és Spark-fürtök létrehozásához hajtsa végre a következő lépéseket:
Az alábbi gombbal jelentkezzen be az Azure szolgáltatásba, és nyissa meg a sablont az Azure Portalon.

Az Azure Resource Manager-sablon a következő helyen található: https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Ez a sablon a következő erőforrásokat hozza létre:
Kafka a HDInsight 4.0-s vagy 5.0-s fürtjén.
Spark 2.4 vagy 3.1 HDInsight 4.0-s vagy 5.0-s fürtön.
Egy Azure virtuális hálózat, amely tartalmazza a HDInsight-fürtöket.
Fontos
Az oktatóanyagban használt strukturált streamelési jegyzetfüzethez a HDInsight 4.0-s vagy 5.0-s verzióján futó Spark 2.4 vagy 3.1 szükséges. Ha a Spark on HDInsight korábbi verzióját használja, hibák lépnek fel a notebook használatakor.
A következő információkkal töltheti ki a Testreszabott sablon szakaszban lévő bejegyzéseket:
Beállítás Érték Előfizetés Az Azure-előfizetése Erőforráscsoport Az erőforrásokat tartalmazó erőforráscsoport. Hely Az az Azure-régió, amelyben az erőforrások létrejönnek. Spark-fürt neve A Spark-fürt neve. Az első hat karakternek a Kafka-fürt nevétől eltérőnek kell lennie. Kafka-fürt neve A Kafka-fürt neve. Az első hat karakternek a Spark-fürt nevétől eltérőnek kell lennie. Fürt bejelentkezési felhasználóneve A fürtök rendszergazdai felhasználóneve. Fürt bejelentkezési jelszava A fürtök rendszergazdai felhasználójának jelszava. SSH-felhasználónév A fürtökhöz létrehozandó SSH-felhasználó. SSH-jelszó Az SSH-felhasználó jelszava. 
Olvassa el a Használati feltételeket, majd válassza ki , hogy elfogadom-e a fenti feltételeket.
Válassza a Vásárlás lehetőséget.
Feljegyzés
A fürtök létrehozása 20 percig is eltarthat.
Spark strukturált streamelés használata
Ez a példa bemutatja, hogyan használható a Spark strukturált streamelés a Kafkával a HDInsighton. A New York City által biztosított taxiutak adatait használja fel. A jegyzetfüzet által használt adatkészlet a 2016-os Green Taxi Trip-adatokból származik.
Gazdagépadatok gyűjtése. Az alábbi curl- és jq-parancsokkal szerezheti be a Kafka ZooKeeper és a közvetítő gazdagépeinek adatait. A parancsok windowsos parancssorhoz vannak tervezve, más környezetekhez kisebb változatokra lesz szükség. Cserélje le
KafkaClustera Kafka-fürt nevére ésKafkaPassworda fürt bejelentkezési jelszavára. Cserélje leC:\HDI\jq-win64.exea jq-telepítés tényleges elérési útját is. Írja be a parancsokat egy Windows parancssorba, és mentse a kimenetet a későbbi lépésekben való használatra.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Egy webböngészőben keresse meg
https://CLUSTERNAME.azurehdinsight.net/jupyterCLUSTERNAMEa fürt nevét. Amikor a rendszer kéri, írja be a fürt létrehozásakor használt bejelentkezési (rendszergazdai) nevet és jelszót.Jegyzetfüzet létrehozásához válassza az Új > Spark lehetőséget.
A Spark-stream mikrobatchinget tartalmaz, ami azt jelenti, hogy a kötegek és a végrehajtók az adatkötegeken futnak. Ha a végrehajtó üresjárati időtúllépése kevesebb, mint a köteg feldolgozásához szükséges idő, akkor a rendszer folyamatosan hozzáadja és eltávolítja a végrehajtókat. Ha a végrehajtók tétlen időtúllépése nagyobb, mint a köteg időtartama, a végrehajtó soha nem lesz eltávolítva. Ezért javasoljuk, hogy tiltsa le a dinamikus lefoglalást a spark.dynamicAllocation.enabled érték hamis értékre állításával streamelési alkalmazások futtatásakor.
Töltse be a jegyzetfüzet által használt csomagokat úgy, hogy beírja a következő adatokat egy Jegyzetfüzet cellába. Futtassa a parancsot a CTRL + ENTER billentyűkombinációval.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Hozza létre a Kafka-témakört. Szerkessze az alábbi parancsot az első lépésben kinyert Zookeeper-gazdagépadatokra cserélve
YOUR_ZOOKEEPER_HOSTS. A témakör létrehozásához írja be a szerkesztett parancsot atripdataJupyter-jegyzetfüzetbe.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersTaxiutak adatainak lekérése. Írja be a parancsot a következő cellába, hogy adatokat tölthessen be a New York-i taxiutakon. Az adatok betöltődnek egy adatkeretbe, majd az adatkeret cellakimenetként jelenik meg.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Adja meg a Kafka-közvetítő állomásadatait. Cserélje le
YOUR_KAFKA_BROKER_HOSTSaz 1. lépésben kinyert közvetítői adatokat. Írja be a szerkesztett parancsot a következő Jupyter Notebook cellába.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Küldje el az adatokat a Kafkának. Az alábbi parancsban a
vendoridmező lesz a Kafka-üzenet kulcsértéke. A kulcsot a Kafka használja az adatok particionálásakor. Az összes mező JSON-sztringértékként van tárolva a Kafka-üzenetben. Adja meg a következő parancsot a Jupyterben az adatok Kafkába való mentéséhez kötegelt lekérdezés használatával.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Séma deklarálása. Az alábbi parancs bemutatja, hogyan használhat sémát JSON-adatok kafkából való olvasásakor. Írja be a parancsot a következő Jupyter-cellába.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Válassza ki az adatokat, és indítsa el a streamet. Az alábbi parancs bemutatja, hogyan lehet adatokat lekérni a Kafkából kötegelt lekérdezéssel. Ezután írja ki az eredményeket a HDFS-be a Spark-fürtön. Ebben a példában a
selectrendszer lekéri az üzenetet (értékmezőt) a Kafkából, és alkalmazza rá a sémát. Az adatok ezután a HDFS-be (WASB vagy ADL) parquet formátumban lesznek megírva. Írja be a parancsot a következő Jupyter-cellába.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")A fájlok létrehozásának ellenőrzéséhez írja be a parancsot a következő Jupyter-cellába. Felsorolja a könyvtárban lévő
/example/batchtripdatafájlokat.%%bash hdfs dfs -ls /example/batchtripdataMíg az előző példa kötegelt lekérdezést használt, az alábbi parancs bemutatja, hogyan végezheti el ugyanezt streamlekérdezés használatával. Írja be a parancsot a következő Jupyter-cellába.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Futtassa a következő cellát annak ellenőrzéséhez, hogy a fájlokat a streamelési lekérdezés írta-e.
%%bash hdfs dfs -ls /example/streamingtripdata
Az erőforrások eltávolítása
Ha törölni szeretné a jelen oktatóanyag által létrehozott erőforrásokat, akkor törölje az erőforráscsoportot. Az erőforráscsoport törlése a társított HDInsight-fürtöt is törli. És az erőforráscsoporthoz társított egyéb erőforrásokat is.
Az erőforráscsoport eltávolítása az Azure Portallal:
- Az Azure Portalon bontsa ki a bal oldali menüt a szolgáltatások menüjének megnyitásához, majd válassza az Erőforráscsoportok lehetőséget az erőforráscsoportok listájának megjelenítéséhez.
- Keresse meg a törölni kívánt erőforráscsoportot, és kattintson a jobb gombbal a lista jobb oldalán lévő Továbbiak gombra (...).
- Válassza az Erőforráscsoport törlése elemet, és erősítse meg a választását.
Figyelmeztetés
A HDInsight-fürt számlázása a fürt létrehozásakor kezdődik és a fürt törlésekor fejeződik be. A számlázás percalapú, ezért mindig érdemes törölni a fürtöt, ha az már nincs használatban.
A Kafka on HDInsight-fürt törlése a Kafkában tárolt összes adatot is törli.