Apache Spark-alkalmazások létrehozása HDInsight-fürthöz az Azure Toolkit for IntelliJ használatával
Ez a cikk bemutatja, hogyan fejleszthet Apache Spark-alkalmazásokat az Azure HDInsighton az IntelliJ IDE Azure Toolkit beépülő moduljának használatával. Az Azure HDInsight egy felügyelt, nyílt forráskódú elemzési szolgáltatás a felhőben. A szolgáltatás lehetővé teszi olyan nyílt forráskódú keretrendszerek használatát, mint a Hadoop, az Apache Spark, az Apache Hive és az Apache Kafka.
Az Azure Toolkit beépülő modult többféleképpen is használhatja:
- Scala Spark-alkalmazás fejlesztése és elküldése EGY HDInsight Spark-fürtbe.
- Az Azure HDInsight Spark-fürt erőforrásainak elérése.
- Scala Spark-alkalmazás helyi fejlesztése és futtatása.
Ebben a cikkben az alábbiakkal ismerkedhet meg:
- Az Azure Toolkit for IntelliJ beépülő modul használata
- Apache Spark-alkalmazások fejlesztése
- Alkalmazás beküldése az Azure HDInsight-fürtbe
Előfeltételek
Apache Spark-fürt megléte a HDInsightban. További útmutatásért lásd: Apache Spark-fürt létrehozása az Azure HDInsightban. Csak a nyilvános felhőben lévő HDInsight-fürtök támogatottak, míg más biztonságos felhőtípusok (például kormányzati felhők) nem.
Oracle Java fejlesztői készlet. Ez a cikk a Java 8.0.202-es verzióját használja.
IntelliJ IDEA. Ez a cikk az IntelliJ IDEA Community 2018.3.4-et használja.
Azure Toolkit for IntelliJ. Lásd : Az Azure Toolkit for IntelliJ telepítése.
Scala beépülő modul az IntelliJ IDEA-hoz
A Scala beépülő modul telepítésének lépései:
Nyissa meg az IntelliJ IDEA-t.
Az üdvözlőképernyőn lépjen a Beépülő modulok konfigurálása>elemre a Beépülő modulok ablak megnyitásához.

Válassza a Telepítés lehetőséget az új ablakban megjelenő Scala beépülő modulhoz.
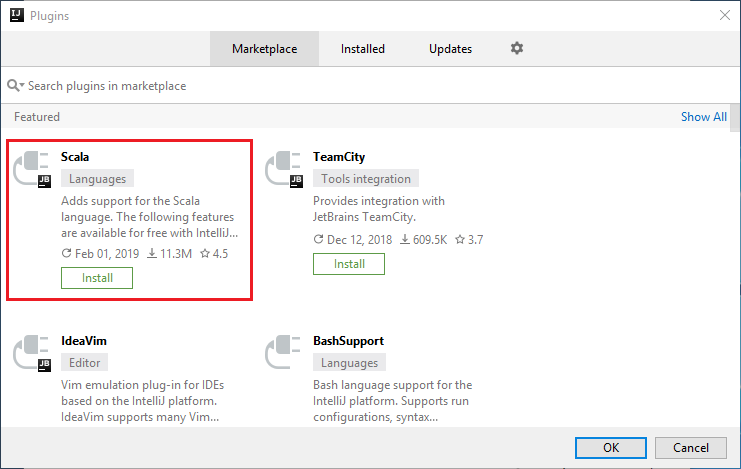
A beépülő modul sikeres telepítését követően újra kell indítania az IDE-t.
Spark Scala-alkalmazás létrehozása HDInsight Spark-fürthöz
Indítsa el az IntelliJ IDEA-t, és válassza az Új projekt létrehozása lehetőséget az Új projekt ablak megnyitásához.
Válassza az Azure Spark/HDInsight lehetőséget a bal oldali panelen.
Válassza a Spark Project (Scala) lehetőséget a főablakban.
A Build eszköz legördülő listájában válassza az alábbi lehetőségek egyikét:
A Maven a Scala projektlétrehozási varázslójának támogatása.
SBT a függőségek kezeléséhez és a Scala-projekt létrehozásához.
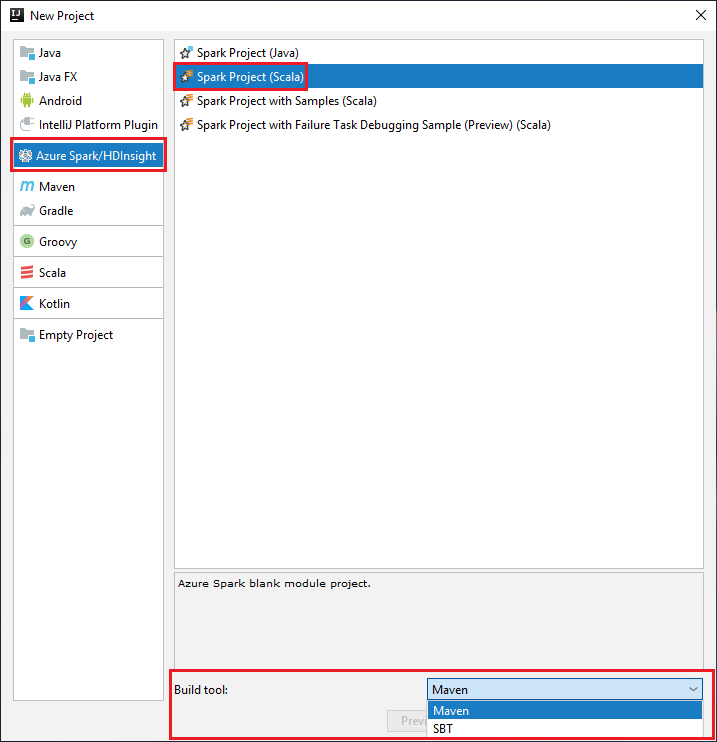
Válassza a Tovább lehetőséget.
Az Új projekt ablakban adja meg a következő információkat:
Tulajdonság Leírás Projekt neve Adjon meg egy nevet. Ez a cikk a . myAppProjekt helye Adja meg a projekt mentésének helyét. Project SDK Ez a mező üres lehet az IDEA első használatakor. Válassza az Új lehetőséget... és lépjen a JDK-ra. Spark-verzió A létrehozási varázsló integrálja a Spark SDK és a Scala SDK megfelelő verzióját. Ha a Spark-fürt verziója 2.0-nál korábbi, válassza a Spark 1.x lehetőséget. Máskülönben válassza a Spark2.x lehetőséget. Ez a példa a Spark 2.3.0 -t (Scala 2.11.8) használja. 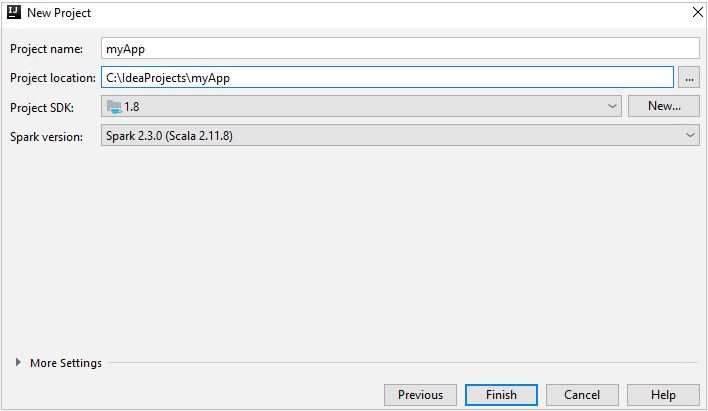
Válassza a Befejezés lehetőséget. A projekt elérhetővé válása eltarthat néhány percig.
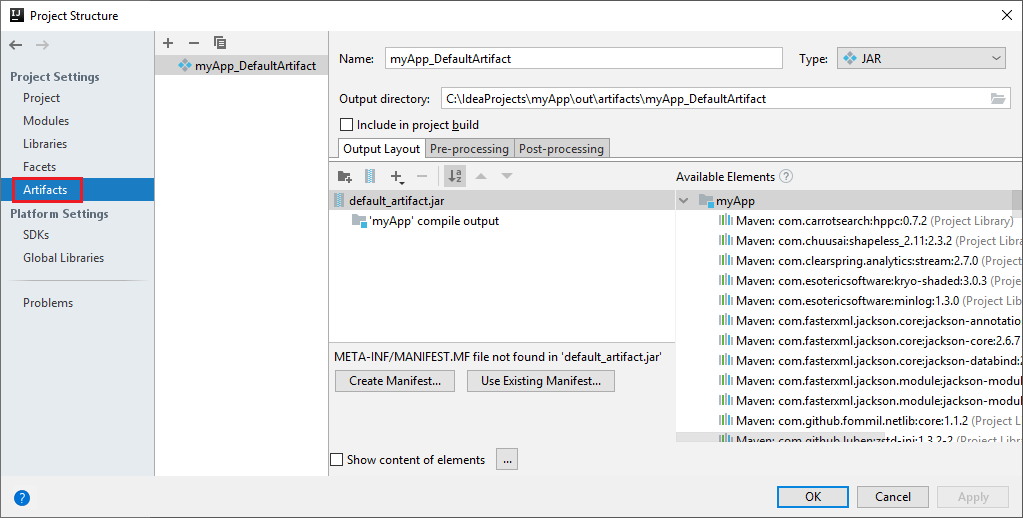
A Spark-projekt automatikusan létrehoz egy összetevőt. Az összetevő megtekintéséhez hajtsa végre a következő lépéseket:
a. A menüsávon navigáljon a Fájlprojekt>struktúrája... elemre.
b. A Projektstruktúra ablakban válassza az Összetevők lehetőséget.
c. Válassza a Mégse elemet az összetevő megtekintése után.
Adja hozzá az alkalmazás forráskódját az alábbi lépések végrehajtásával:
a. A Projectben keresse meg a myApp>src>fő>scalát.
b. Kattintson a jobb gombbal a Scala elemre, majd lépjen az Új>Scala osztályra.
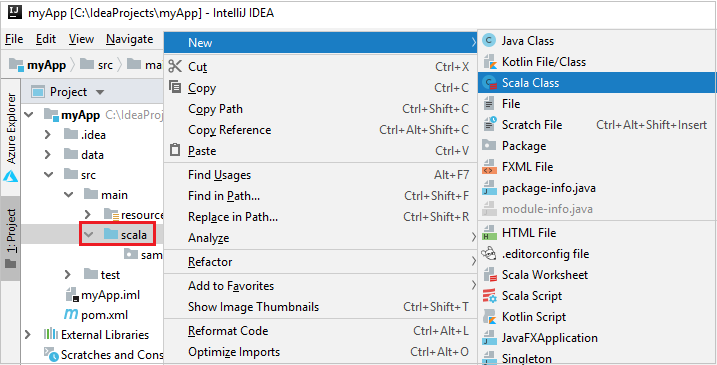
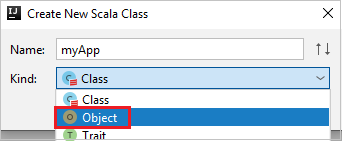
c. Az Új Scala-osztály létrehozása párbeszédpanelen adjon meg egy nevet, válassza az Objektum lehetőséget a Kind legördülő listában, majd kattintson az OK gombra.
d. Ekkor megnyílik a myApp.scala fájl a fő nézetben. Cserélje le az alapértelmezett kódot az alábbi kódra:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }A kód beolvassa az adatokat a HVAC.csv (minden HDInsight Spark-fürtön elérhető), lekéri azokat a sorokat, amelyek csak egy számjegyet tartalmaznak a CSV-fájl hetedik oszlopában, és a kimenetet
/HVACOuta fürt alapértelmezett tárolójába írja.
Csatlakozás a HDInsight-fürthöz
A felhasználó bejelentkezhet az Azure-előfizetésbe, vagy összekapcsolhat egy HDInsight-fürtöt. A HDInsight-fürthöz való csatlakozáshoz használja az Ambari felhasználónevet/jelszót vagy tartományhoz csatlakoztatott hitelesítő adatokat.
Jelentkezzen be az Azure-előfizetésébe
A menüsávon navigáljon a Windows>Azure Explorer Nézet>eszközre.
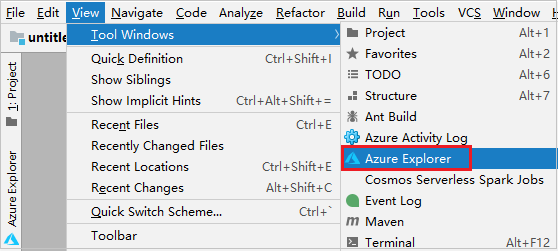
Az Azure Explorerben kattintson a jobb gombbal az Azure-csomópontra , majd válassza a Bejelentkezés lehetőséget.
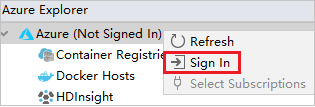
Az Azure Bejelentkezési párbeszédpanelen válassza az Eszközbejelentkeztetés, majd a Bejelentkezés lehetőséget.
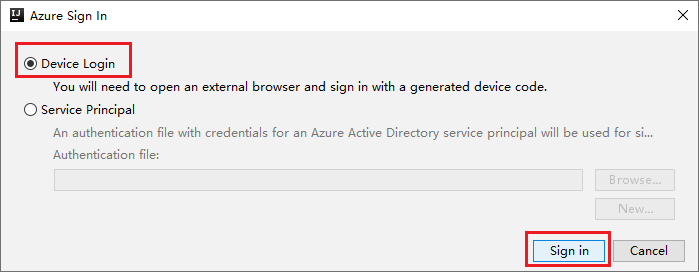
Az Azure Device Login párbeszédpanelen kattintson a Másolás> Megnyitás gombra.
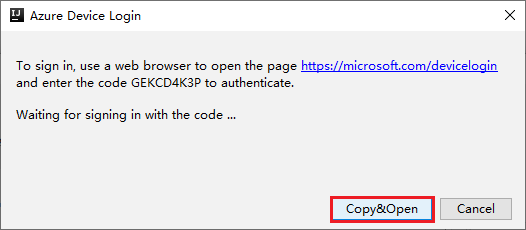
A böngészőfelületen illessze be a kódot, majd kattintson a Tovább gombra.
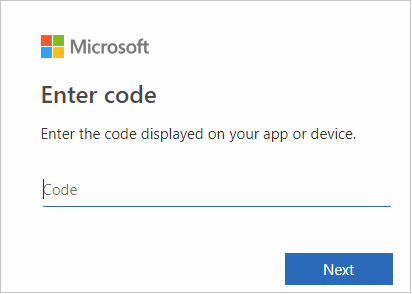
Adja meg azure-beli hitelesítő adatait, majd zárja be a böngészőt.
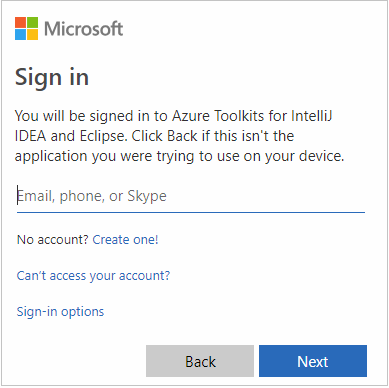
Miután bejelentkezett, az Előfizetések kiválasztása párbeszédpanel felsorolja a hitelesítő adatokhoz társított Összes Azure-előfizetést. Válassza ki az előfizetést, majd kattintson a Kiválasztás gombra.
Az Azure Explorerben bontsa ki a HDInsightot az előfizetésekben lévő HDInsight Spark-fürtök megtekintéséhez.
A fürthöz társított erőforrások (például tárfiókok) megtekintéséhez tovább bővítheti a fürtnévcsomópontot.
Fürt csatolása
A HDInsight-fürtöket az Apache Ambari által felügyelt felhasználónévvel kapcsolhatja össze. Hasonlóképpen, a tartományhoz csatlakoztatott HDInsight-fürtök esetében a tartomány és a felhasználónév használatával is összekapcsolható, például user1@contoso.com. Összekapcsolhatja a Livy Service-fürtöt is.
A menüsávon navigáljon a Windows>Azure Explorer Nézet>eszközre.
Az Azure Explorerben kattintson a jobb gombbal a HDInsight csomópontra, majd válassza a Fürt csatolása lehetőséget.
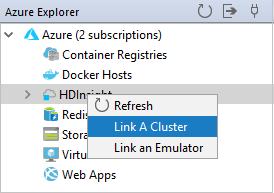
Az A fürt csatolása ablakban elérhető lehetőségek attól függően változnak, hogy melyik értéket választja ki a Csatolás erőforrástípus legördülő listából. Adja meg az értékeket, majd kattintson az OK gombra.
HDInsight-fürt
Tulajdonság Érték Erőforrástípus csatolása Válassza ki a HDInsight-fürtöt a legördülő listából. Fürt neve/URL-címe Adja meg a fürt nevét. Hitelesítés típusa Hagyja meg az alapszintű hitelesítést Felhasználónév Adja meg a fürt felhasználónevet, az alapértelmezett beállítás a rendszergazda. Jelszó Adja meg a felhasználónév jelszavát. 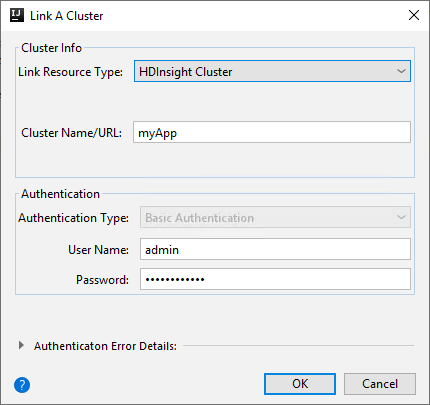
Livy szolgáltatás
Tulajdonság Érték Erőforrástípus csatolása Válassza ki a Livy szolgáltatást a legördülő listából. Livy-végpont Adja meg a Livy-végpontot Fürt neve Adja meg a fürt nevét. Yarn-végpont Opcionális. Hitelesítés típusa Hagyja meg az alapszintű hitelesítést Felhasználónév Adja meg a fürt felhasználónevet, az alapértelmezett beállítás a rendszergazda. Jelszó Adja meg a felhasználónév jelszavát. 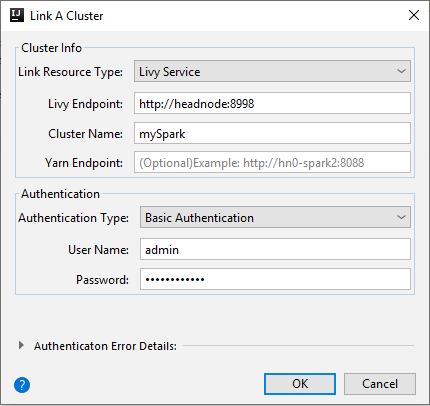
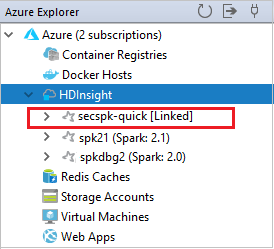
A csatolt fürt a HDInsight csomópontról látható.
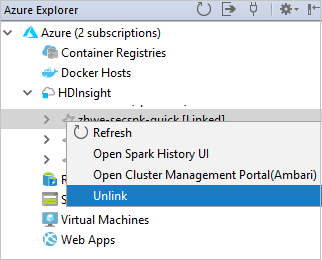
A fürtöt az Azure Explorerből is leválaszthatja.
Spark Scala-alkalmazás futtatása HDInsight Spark-fürtön
Scala-alkalmazás létrehozása után elküldheti azt a fürtnek.
A Projectben keresse meg a myApp>src>fő>scala>myAppját. Kattintson a jobb gombbal a myAppra, és válassza a Spark-alkalmazás elküldése lehetőséget (valószínűleg a lista alján található).

A Spark-alkalmazás elküldése párbeszédpanelen válassza az 1 lehetőséget. Spark on HDInsight.
A Konfiguráció szerkesztése ablakban adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Spark-fürtök (csak Linuxon) Válassza ki azt a HDInsight Spark-fürtöt, amelyen futtatni szeretné az alkalmazást. Elküldendő összetevő kiválasztása Hagyja meg az alapértelmezett beállítást. Főosztály neve Az alapértelmezett érték a kijelölt fájl főosztálya. Az osztályt a három pont (...) kiválasztásával és egy másik osztály kiválasztásával módosíthatja. Feladatkonfigurációk Módosíthatja az alapértelmezett kulcsokat és értékeket. További információ: Apache Livy REST API. Parancssori argumentumok Szükség esetén a főosztályhoz szóközzel elválasztott argumentumokat is megadhat. Hivatkozott jarok és hivatkozott fájlok Ha vannak ilyenek, megadhatja a hivatkozott Jars és fájlok elérési útját. Az Azure-beli virtuális fájlrendszerben is tallózhat a fájlok között, amely jelenleg csak az ADLS Gen 2 fürtöt támogatja. További információ: Apache Spark-konfiguráció. Lásd még: Erőforrások feltöltése fürtbe. Feladatfeltöltési tárterület Bontsa ki a további lehetőségek megjelenítéséhez. Tárhelytípusa Válassza az Azure Blob használata lehetőséget a legördülő listából való feltöltéshez . Tárfiók Adja meg a tárfiókot. Tárkulcs Adja meg a tárkulcsot. Tároló tárolója A tárfiók és a tárkulcs megadása után válassza ki a tárolót a legördülő listából. 
Válassza a SparkJobRun lehetőséget a projekt kijelölt fürtbe való elküldéséhez. A Fürt távoli Spark-feladata lap alján a feladat végrehajtásának előrehaladása látható. Az alkalmazást a piros gombra kattintva állíthatja le.
Apache Spark-alkalmazások hibakeresése helyileg vagy távolról EGY HDInsight-fürtön
Azt is javasoljuk, hogy küldje el a Spark-alkalmazást a fürtnek. Ezt úgy teheti meg, hogy beállítja a paramétereket a Run/Debug configurations IDE-ben. Tekintse meg az Apache Spark-alkalmazások helyi vagy távoli hibakeresését egy HDInsight-fürtön az Azure Toolkit for IntelliJ-vel SSH-n keresztül.
HDInsight Spark-fürtök elérése és kezelése az Azure Toolkit for IntelliJ használatával
Az IntelliJ-hez készült Azure Toolkit használatával különböző műveleteket végezhet. A legtöbb művelet az Azure Explorerből indul el. A menüsávon navigáljon a Windows>Azure Explorer Nézet>eszközre.
A feladatnézet elérése
Az Azure Explorerben keresse meg a HDInsight><a fürtfeladatokat.>>
A jobb oldali ablaktáblán a Spark-feladatnézet lap megjeleníti a fürtön futtatott összes alkalmazást. Válassza ki annak az alkalmazásnak a nevét, amelynek további részleteket szeretne látni.
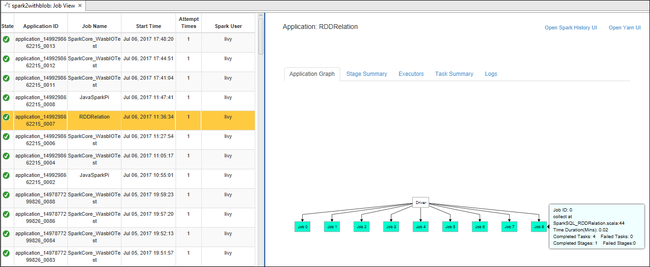
Az alapvető futó feladatok adatainak megjelenítéséhez vigye az egérmutatót a feladatdiagramra. Az egyes feladatok által generált szakaszok gráfjának és információinak megtekintéséhez jelöljön ki egy csomópontot a feladatgráfon.
A gyakran használt naplók, például a Driver Stderr, az Driver Stdout és a Címtáradatok megtekintéséhez válassza a Napló fület.
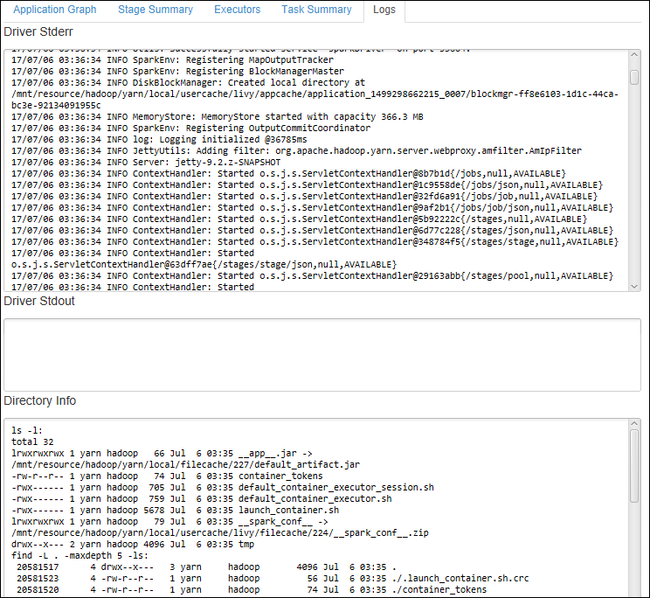
Megtekintheti a Spark-előzmények felhasználói felületét és a YARN felhasználói felületét (az alkalmazás szintjén). Jelöljön ki egy hivatkozást az ablak tetején.
A Spark előzménykiszolgálójának elérése
Az Azure Explorerben bontsa ki a HDInsightot, kattintson a jobb gombbal a Spark-fürt nevére, majd válassza a Spark-előzmények felhasználói felületének megnyitása lehetőséget.
Amikor a rendszer kéri, adja meg a fürt rendszergazdai hitelesítő adatait, amelyeket a fürt beállításakor adott meg.
A Spark előzménykiszolgáló irányítópultján az alkalmazás nevével megkeresheti az éppen futó alkalmazást. Az előző kódban az alkalmazás nevét a következővel
val conf = new SparkConf().setAppName("myApp")állíthatja be: . A Spark-alkalmazás neve myApp.
Az Ambari portál indítása
Az Azure Explorerben bontsa ki a HDInsightot, kattintson a jobb gombbal a Spark-fürt nevére, majd válassza a Fürtkezelési portál (Ambari) megnyitása lehetőséget.
Amikor a rendszer kéri, adja meg a fürt rendszergazdai hitelesítő adatait. Ezeket a hitelesítő adatokat a fürtbeállítási folyamat során adta meg.
Azure-előfizetések kezelése
Alapértelmezés szerint az Azure Toolkit for IntelliJ felsorolja az összes Azure-előfizetéséből származó Spark-fürtöket. Szükség esetén megadhatja a elérni kívánt előfizetéseket.
Az Azure Explorerben kattintson a jobb gombbal az Azure-gyökércsomópontra , majd válassza az Előfizetések kiválasztása lehetőséget.
Az Előfizetések kiválasztása ablakban törölje a jelet a nem elérni kívánt előfizetések melletti jelölőnégyzetekből, majd válassza a Bezárás lehetőséget.
Spark-konzol
Futtathatja a Spark helyi konzolját (Scala), vagy futtathatja a Spark Livy interaktív munkamenet-konzolt (Scala).
Spark helyi konzol (Scala)
Győződjön meg arról, hogy megfelelt a WINUTILS.EXE előfeltételeknek.
A menüsávon navigáljon a Konfigurációk szerkesztése parancsra...>
A Futtatási/hibakeresési konfigurációk ablak bal oldali ablaktábláján keresse meg az Apache Spark on HDInsight>[Spark on HDInsight] myApp webhelyet.
A főablakban válassza a
Locally Runlapot.Adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Feladat főosztálya Az alapértelmezett érték a kijelölt fájl főosztálya. Az osztályt a három pont (...) kiválasztásával és egy másik osztály kiválasztásával módosíthatja. Környezeti változók Győződjön meg arról, hogy a HADOOP_HOME értéke helyes. WINUTILS.exe helye Győződjön meg arról, hogy az elérési út helyes. 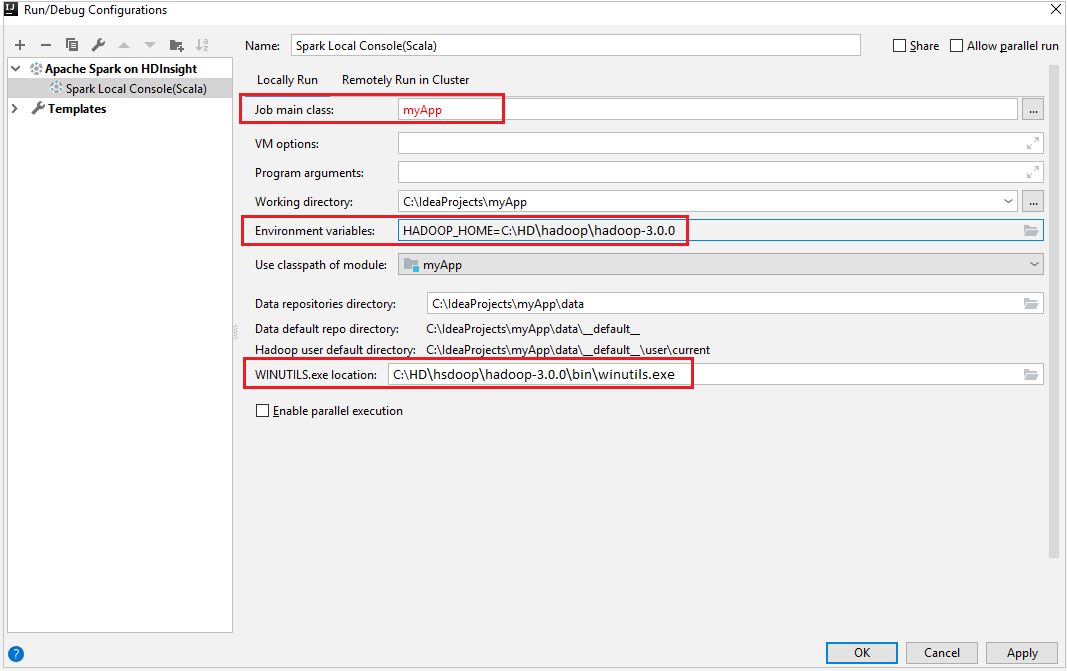
A Projectben keresse meg a myApp>src>fő>scala>myAppját.
A menüsávon keresse meg a Spark-konzolt futtató Spark-konzolt>>(Scala).
Ezután két párbeszédpanel jelenhet meg, hogy megkérdezze, szeretné-e automatikusan kijavítani a függőségeket. Ha igen, válassza az Automatikus javítás lehetőséget.
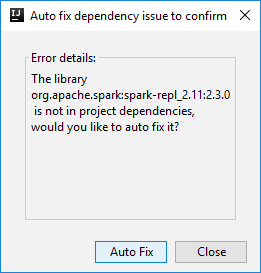
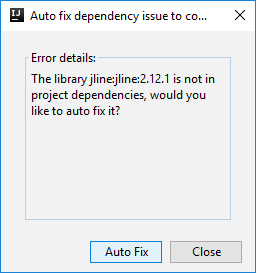
A konzolnak az alábbi képhez hasonlóan kell kinéznie. Írja be a konzolablak típusát
sc.appName, majd nyomja le a ctrl+Enter billentyűkombinációt. Az eredmény megjelenik. A helyi konzolt a piros gombra kattintva fejezheti be.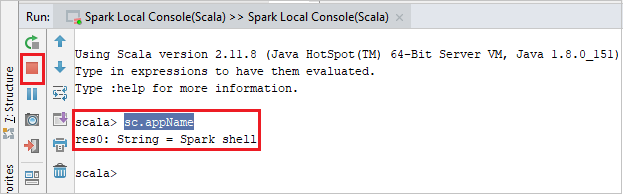
Spark Livy interaktív munkamenet-konzol (Scala)
A menüsávon navigáljon a Konfigurációk szerkesztése parancsra...>
A Futtatási/hibakeresési konfigurációk ablak bal oldali ablaktábláján keresse meg az Apache Spark on HDInsight>[Spark on HDInsight] myApp webhelyet.
A főablakban válassza a
Remotely Run in Clusterlapot.Adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Spark-fürtök (csak Linuxon) Válassza ki azt a HDInsight Spark-fürtöt, amelyen futtatni szeretné az alkalmazást. Főosztály neve Az alapértelmezett érték a kijelölt fájl főosztálya. Az osztályt a három pont (...) kiválasztásával és egy másik osztály kiválasztásával módosíthatja. 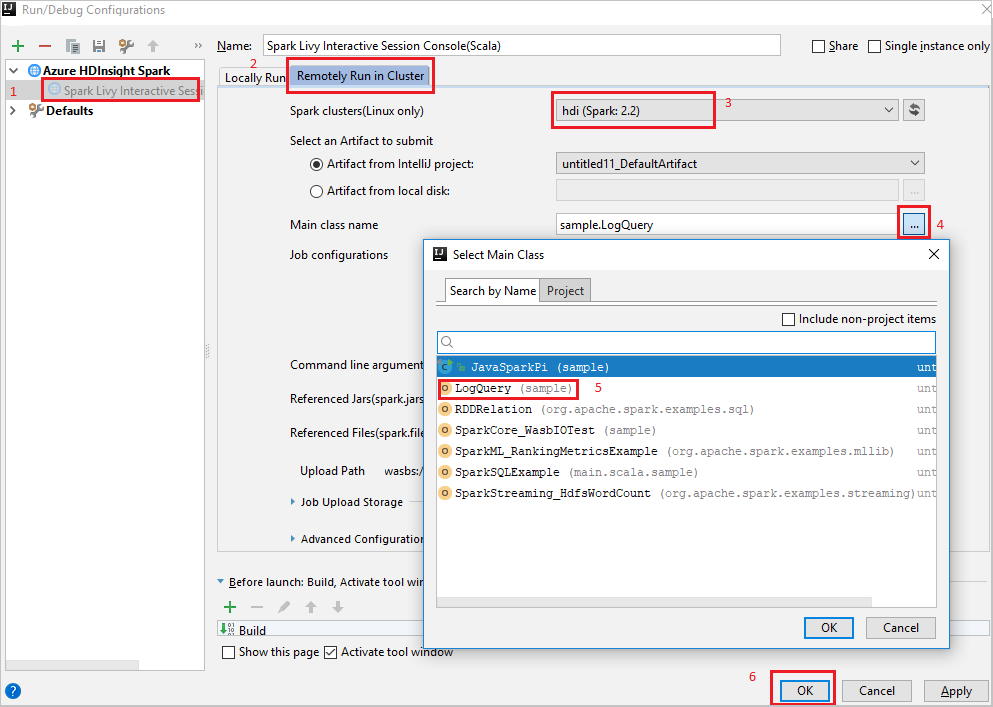
A Projectben keresse meg a myApp>src>fő>scala>myAppját.
A menüsávon navigáljon az Eszközök>Spark-konzolon>a Spark Livy interaktív munkamenet-konzol (Scala) futtatásához.
A konzolnak az alábbi képhez hasonlóan kell kinéznie. Írja be a konzolablak típusát
sc.appName, majd nyomja le a ctrl+Enter billentyűkombinációt. Az eredmény megjelenik. A helyi konzolt a piros gombra kattintva fejezheti be.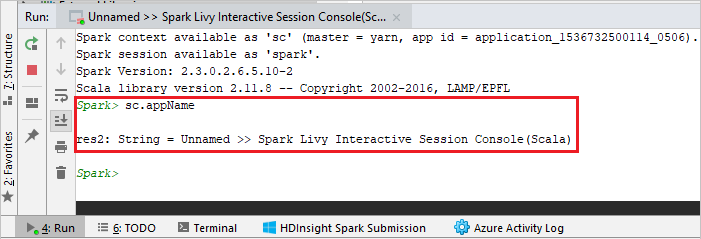
Kijelölés küldése a Spark-konzolra
Kényelmes, ha előrevetíti a szkript eredményét úgy, hogy elküld egy kódot a helyi konzolra vagy a Livy interaktív munkamenet-konzolra (Scala). Kiemelhet néhány kódot a Scala-fájlban, majd kattintson a jobb gombbal a Kijelölés küldése a Spark-konzolra. A rendszer elküldi a kijelölt kódot a konzolnak. Az eredmény a kód után jelenik meg a konzolon. A konzol ellenőrzi a hibákat, ha már létezik.

Integrálás a HDInsight Identity Brokerrel (HIB)
Csatlakozás a HDInsight ESP-fürthöz az ID Broker (HIB) használatával
A normál lépéseket követve bejelentkezhet az Azure-előfizetésbe a HDInsight ESP-fürthöz való csatlakozáshoz az ID Broker (HIB) használatával. A bejelentkezés után megjelenik a fürtlista az Azure Explorerben. További útmutatásért tekintse meg a HDInsight-fürtre vonatkozó Csatlakozás.
Spark Scala-alkalmazás futtatása HDInsight ESP-fürtön id Brokerrel (HIB)
A feladat HDInsight ESP-fürtbe való elküldéséhez kövesse a normál lépéseket az ID Broker (HIB) használatával. További útmutatásért tekintse meg a Spark Scala-alkalmazás HDInsight Spark-fürtön való futtatását.
Feltöltjük a szükséges fájlokat egy bejelentkezési fiókkal ellátott mappába, és a konfigurációs fájlban láthatja a feltöltési útvonalat.

Spark-konzol egy HDInsight ESP-fürtön az ID Broker (HIB) használatával
Futtathatja a Spark helyi konzolt (Scala), vagy futtathatja a Spark Livy interaktív munkamenet-konzolt (Scala) egy HDInsight ESP-fürtön az ID Broker (HIB) használatával. További útmutatásért tekintse meg a Spark Consolet .
Feljegyzés
Az Id Brokerrel (HIB) rendelkező HDInsight ESP-fürt esetében a fürt összekapcsolása és az Apache Spark-alkalmazások távoli hibakeresése jelenleg nem támogatott.
Csak olvasói szerepkör
Amikor a felhasználók csak olvasói szerepkörrel rendelkező fürtbe küldenek feladatot, az Ambari hitelesítő adataira van szükség.
Fürt csatolása a helyi menüből
Jelentkezzen be csak olvasói szerepkörrel.
Az Azure Explorerben bontsa ki a HDInsightot az előfizetésében lévő HDInsight-fürtök megtekintéséhez. A "Szerepkör:Olvasó" megjelölt fürtök csak olvasói szerepkör-engedéllyel rendelkeznek.
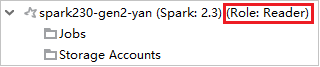
Kattintson a jobb gombbal a csak olvasói szerepkörrel rendelkező fürtre. A fürt csatolásához válassza a Fürt csatolása a helyi menüből lehetőséget. Adja meg az Ambari felhasználónevet és jelszót.
Ha a fürt csatolása sikeresen megtörtént, a HDInsight frissül. A fürt szakasza összekapcsolva lesz.
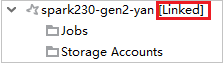
Fürt összekapcsolása a Feladatok csomópont kibontásával
Kattintson a Feladatok csomópontra, és megjelenik a Fürtfeladat-hozzáférés megtagadva ablak.
Kattintson a Fürt csatolása elemre a fürt csatolásához.

Fürt csatolása a Run/Debug Configurations ablakból
HDInsight-konfiguráció létrehozása. Ezután válassza a Távoli futtatás fürtben lehetőséget.
Válasszon ki egy fürtöt, amely csak olvasói szerepkörrel rendelkezik a Spark-fürtökhöz (csak Linux esetén). Figyelmeztető üzenet jelenik meg. A fürt csatolásához kattintson a Fürt csatolása elemre.
Tárfiókok megtekintése
Csak olvasói szerepkörrel rendelkező fürtök esetén kattintson a Tárfiókok csomópontra, és megjelenik a Storage Access Denied (Hozzáférés megtagadva ) ablak. A Storage Explorer megnyitásához kattintson az Azure Storage Explorer megnyitása gombra.
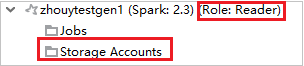

Csatolt fürtök esetén kattintson a Tárfiókok csomópontra, és megjelenik a Storage Access Denied (Hozzáférés megtagadva ) ablak. Az Azure Storage megnyitása gombra kattintva megnyithatja a Storage Explorert.

Meglévő IntelliJ IDEA-alkalmazások átalakítása az Azure Toolkit for IntelliJ használatára
Az IntelliJ IDEA-ban létrehozott meglévő Spark Scala-alkalmazásokat konvertálhatja úgy, hogy kompatibilisek legyenek az Azure Toolkit for IntelliJ-vel. Ezután a beépülő modullal elküldheti az alkalmazásokat egy HDInsight Spark-fürtnek.
Az IntelliJ IDEA-on keresztül létrehozott meglévő Spark Scala-alkalmazás esetén nyissa meg a társított
.imlfájlt.A gyökérszinten a következő szöveghez hasonló modulelem található:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Szerkessze a hozzáadni
UniqueKey="HDInsightTool"kívánt elemet úgy, hogy a modulelem a következő szöveghez hasonlóan nézzen ki:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Mentse el a módosításokat. Az alkalmazásnak kompatibilisnek kell lennie az IntelliJ-hez készült Azure Toolkittel. A teszteléshez kattintson a jobb gombbal a projekt nevére a Projectben. Az előugró menüben most már elérhető a Spark-alkalmazás elküldése a HDInsightba lehetőség.
Az erőforrások eltávolítása
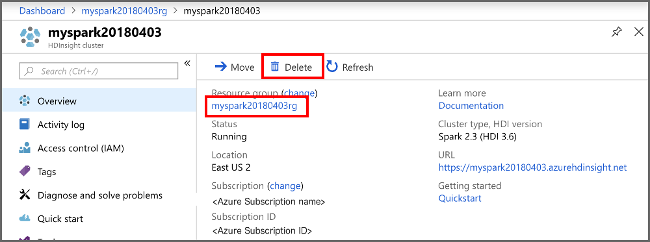
Ha nem folytatja az alkalmazás használatát, törölje a létrehozott fürtöt az alábbi lépésekkel:
Jelentkezzen be az Azure Portalra.
A felül található Keresőmezőbe írja be a HDInsight parancsot.
Válassza ki a HDInsight-fürtöket a Szolgáltatások területen.
A megjelenő HDInsight-fürtök listájában válassza ki a jelen cikkhez létrehozott fürt melletti ... elemet.
Válassza a Törlés lehetőséget. Válassza az Igen lehetőséget.
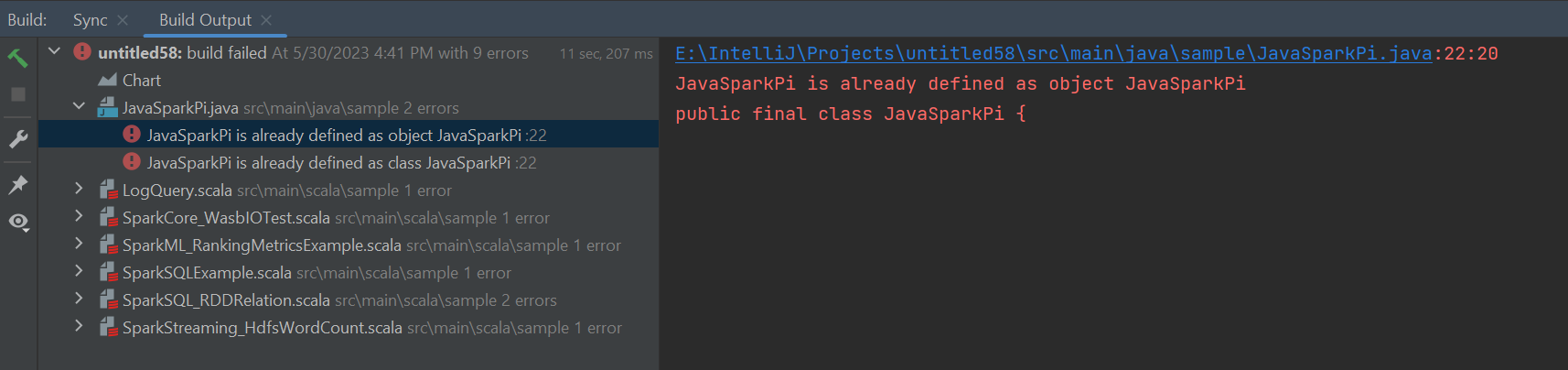
Hibák és megoldás
Ha a buildelési hibák az alábbi módon jelennek meg, törölje az src mappa forrásként való jelölését:
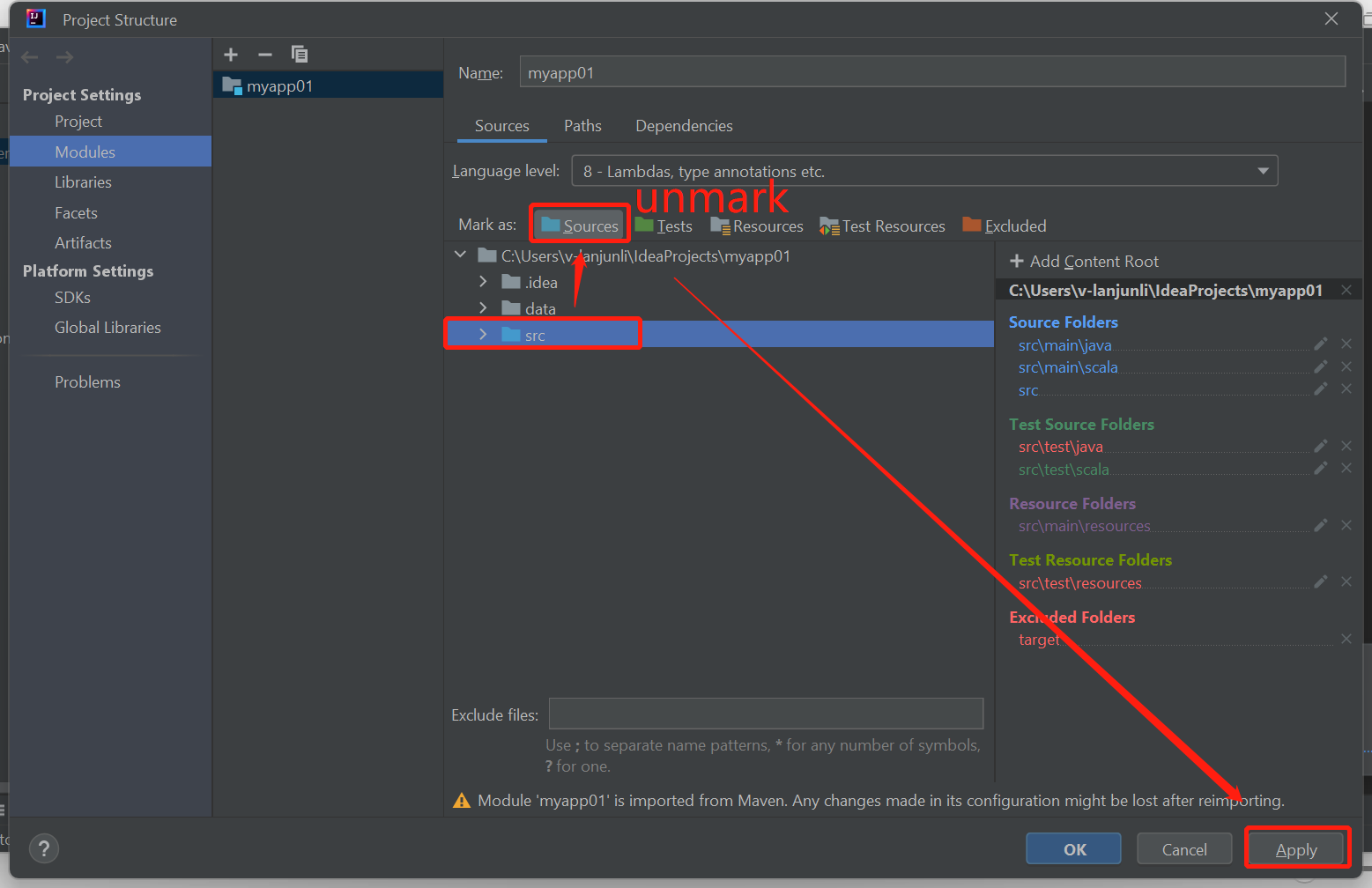
A probléma megoldásához törölje az src mappa megjelölését forrásként:
Lépjen a Fájl elemre, és válassza ki a projektstruktúrát.
Válassza ki a Modulokat a Project Gépház alatt.
Válassza ki az src fájlt, és törölje a jelölést forrásként.
Kattintson az Alkalmaz gombra, majd az OK gombra a párbeszédpanel bezárásához.
Következő lépések
Ebben a cikkben megtanulta, hogyan fejleszthet Scalában írt Apache Spark-alkalmazásokat az Azure Toolkit for IntelliJ beépülő modul használatával. Ezután közvetlenül az IntelliJ integrált fejlesztési környezetből (IDE) küldte el őket egy HDInsight Spark-fürtnek. A következő cikkből megtudhatja, hogy az Apache Sparkban regisztrált adatok hogyan állíthatók be egy OLYAN BI-elemző eszközbe, mint a Power BI.