Az Apache Spark Streaming áttekintése
Az Apache Spark Streaming adatfolyam-feldolgozást biztosít HDInsight Spark-fürtökön. Garantálva, hogy minden bemeneti esemény pontosan egyszer lesz feldolgozva, még akkor is, ha csomóponthiba történik. A Spark Stream egy hosszú ideig futó feladat, amely számos forrásból fogad bemeneti adatokat, beleértve az Azure Event Hubsot is. Továbbá: Azure IoT Hub, Apache Kafka, Apache Flume, Twitter, ZeroMQnyers TCP-szoftvercsatornák, vagy Apache Hadoop YARN fájlrendszerek monitorozásából. A kizárólag eseményvezérelt folyamatokkal ellentétben a Spark Stream időablakokba köti a bemeneti adatokat. Például egy 2 másodperces szeletet, majd térkép, csökkentés, illesztés és kinyerési műveletek használatával átalakítja az egyes adatkötegeket. A Spark Stream ezután kiírja az átalakított adatokat fájlrendszerekbe, adatbázisokba, irányítópultokra és a konzolra.
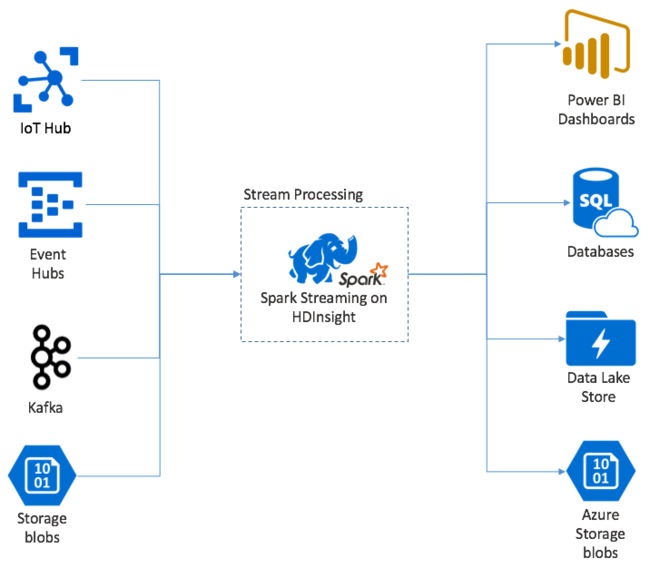
A Spark Streaming-alkalmazásoknak másodperc töredékét kell várniuk, hogy összegyűjtsék az egyes micro-batch eseményeket, mielőtt a köteget feldolgozásra küldenék. Ezzel szemben egy eseményvezérelt alkalmazás azonnal feldolgozza az egyes eseményeket. A Spark Streaming késése általában néhány másodperc alatt van. A mikroköteg-megközelítés előnyei a hatékonyabb adatfeldolgozás és az egyszerűbb aggregátumszámítások.
A DStream bemutatása
A Spark Streaming a bejövő adatok folyamatos adatfolyamát jelöli egy különálló, DStream nevű stream használatával. A DStream olyan bemeneti forrásokból hozható létre, mint az Event Hubs vagy a Kafka. Vagy átalakítások alkalmazásával egy másik DStreamen.
A DStream absztrakciós réteget biztosít a nyers eseményadatokon.
Kezdje egyetlen eseménysel, például egy csatlakoztatott termosztát hőmérséklet-leolvasásával. Amikor ez az esemény megérkezik a Spark Streaming-alkalmazáshoz, az esemény megbízható módon lesz tárolva, ahol több csomóponton replikálódik. Ez a hibatűrés biztosítja, hogy egyetlen csomópont meghibásodása ne okozza az esemény elvesztését. A Spark-mag egy olyan adatstruktúrát használ, amely a fürt több csomópontja között osztja el az adatokat. Ahol az egyes csomópontok általában a memóriában tartják a saját adataikat a legjobb teljesítmény érdekében. Ezt az adatstruktúrát rugalmas elosztott adatkészletnek (RDD) nevezzük.
Minden RDD egy felhasználó által meghatározott időkereten keresztül gyűjtött eseményeket jelöl, amelyeket kötegintervallumnak hívunk. Az egyes kötegintervallumok elteltével egy új RDD jön létre, amely az adott intervallum összes adatát tartalmazza. Az RDD-k folyamatos készletét a rendszer egy DStreambe gyűjti. Ha például a köteg időköze egy másodperc hosszú, a DStream másodpercenként bocsát ki egy köteget, amely egy RDD-t tartalmaz, amely tartalmazza az adott másodperc során betöltött összes adatot. A DStream feldolgozásakor a hőmérsékleti esemény ezen kötegek egyikében jelenik meg. A Spark Streaming-alkalmazás feldolgozza az eseményeket tartalmazó kötegeket, és végső soron az egyes RDD-kben tárolt adatokra hat.
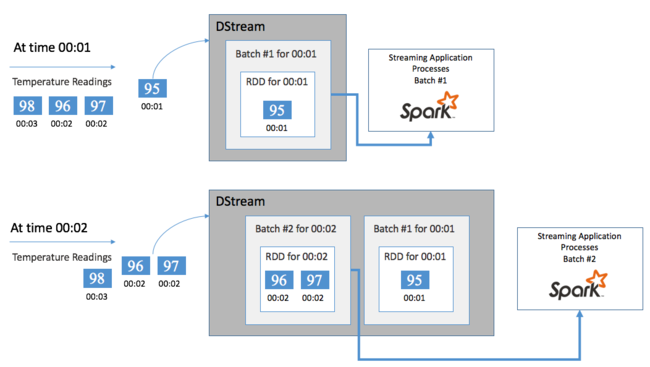
Spark Streaming-alkalmazás felépítése
A Spark Streaming-alkalmazások hosszú ideig futó alkalmazások, amelyek adatokat fogadnak a betöltési forrásokból. Átalakításokat alkalmaz az adatok feldolgozására, majd leküldi az adatokat egy vagy több célhelyre. A Spark Streaming-alkalmazások struktúrája statikus és dinamikus részből áll. A statikus rész határozza meg, hogy honnan származnak az adatok, milyen feldolgozást kell végezni az adatokon. És hová kell mennie az eredményeknek. A dinamikus rész határozatlan ideig futtatja az alkalmazást, és leállítási jelre vár.
Az alábbi egyszerű alkalmazás például egy TCP-szoftvercsatornán keresztül kap egy szövegsort, és megszámolja, hogy az egyes szavak hányszor jelennek meg.
Az alkalmazás definiálása
Az alkalmazáslogika definíciójának négy lépése van:
- Hozzon létre egy StreamingContextet.
- Hozzon létre egy DStreamet a StreamingContextből.
- Átalakítások alkalmazása a DStreamre.
- Adja ki az eredményeket.
Ez a definíció statikus, és az alkalmazás futtatásáig nem dolgoz fel adatokat.
StreamingContext létrehozása
Hozzon létre egy StreamingContextet a SparkContextből, amely a fürtre mutat. StreamContext létrehozásakor másodpercek alatt adja meg a köteg méretét, például:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
DStream létrehozása
A StreamingContext-példánnyal hozzon létre egy bemeneti DStreamet a bemeneti forráshoz. Ebben az esetben az alkalmazás figyeli az új fájlok megjelenését az alapértelmezett csatolt tárolóban.
val lines = ssc.textFileStream("/uploads/Test/")
Átalakítások alkalmazása
A feldolgozást átalakítások alkalmazásával valósíthatja meg a DStreamen. Ez az alkalmazás egyszerre egy sornyi szöveget kap a fájlból, és az egyes sorokat szavakra osztja. Ezután egy térkép-csökkentési mintát használva megszámolja az egyes szavak megjelenésének számát.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Kimeneti eredmények
Kimeneti műveletek alkalmazásával küldje el az átalakítás eredményeit a célrendszereknek. Ebben az esetben a számításon keresztüli futtatás eredményét a rendszer a konzol kimenetében nyomtatja ki.
wordCounts.print()
Az alkalmazás futtatása
Indítsa el a streamelési alkalmazást, és futtassa addig, amíg meg nem kapja a végpontjelet.
ssc.start()
ssc.awaitTermination()
A Spark Stream API-val kapcsolatos részletekért lásd az Apache Spark streamelési programozási útmutatóját.
Az alábbi mintaalkalmazás önálló, így egy Jupyter Notebookban futtathatja. Ez a példa létrehoz egy hamis adatforrást a DummySource osztályban, amely egy számláló értékét és az aktuális időt öt másodpercenként adja ki. Egy új StreamingContext objektum kötegintervalluma 30 másodperc. Minden egyes köteg létrehozásakor a streamelési alkalmazás megvizsgálja a létrehozott RDD-t. Ezután átalakítja az RDD-t Spark DataFrame-gé, és létrehoz egy ideiglenes táblát a DataFrame-en keresztül.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Várjon körülbelül 30 másodpercet a fenti alkalmazás elindítása után. Ezután rendszeres időközönként lekérdezheti a DataFrame-et a kötegben található értékek aktuális készletének megtekintéséhez, például ezzel az SQL-lekérdezéssel:
%%sql
SELECT * FROM demo_numbers
Az eredmény a következő kimenethez hasonlóan néz ki:
| Érték | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Hat érték van, mivel a DummySource 5 másodpercenként hoz létre egy értéket, az alkalmazás pedig 30 másodpercenként bocsát ki egy köteget.
Tolóablakok
Ha egy adott időszakban összesíteni szeretné a számításokat a DStreamen, például az utolsó két másodperc átlaghőmérsékletének lekéréséhez használja a sliding window Spark Streamingben szereplő műveleteket. A tolóablakok időtartama (az ablak hossza) és az ablak tartalmának kiértékelésének időköze (a dia időköze).
A tolóablakok átfedésben lehetnek, például megadhat egy két másodperc hosszúságú ablakot, amely másodpercenként csúszik. Ez a művelet azt jelenti, hogy minden alkalommal, amikor összesítési számítást végez, az ablak az előző ablak utolsó egy másodpercének adatait fogja tartalmazni. És minden új adat a következő egy másodpercben.
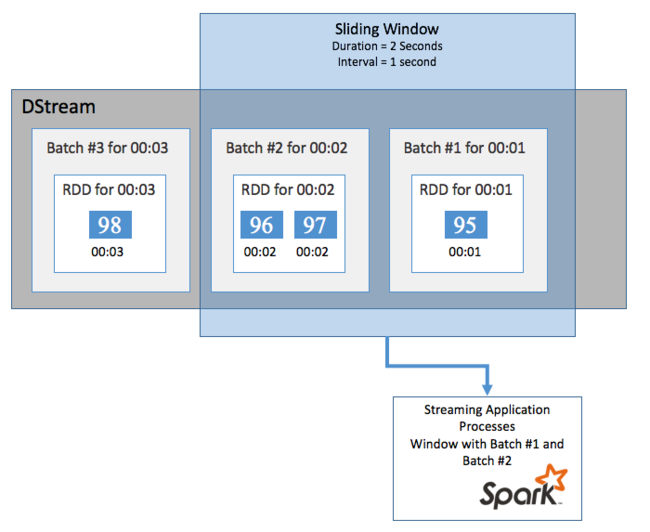
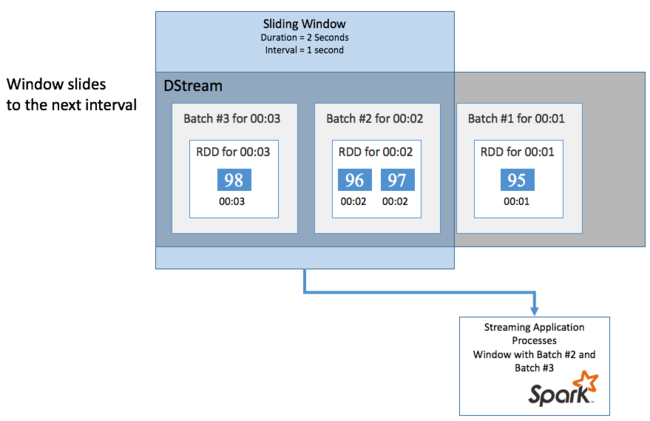
Az alábbi példa frissíti a DummySource-t használó kódot, hogy összegyűjtse a kötegeket egy egyperces időtartamú és egyperces diával rendelkező ablakban.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Az első perc után 12 bejegyzés található – az ablakban összegyűjtött két kötegből hat bejegyzés.
| Érték | time |
|---|---|
| 0 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
A Spark Streaming API-ban elérhető csúszóablak-függvények közé tartozik az ablak, a countByWindow, a reduceByWindow és a countByValueAndWindow. Ezekről a függvényekről további információt a D adatfolyamok transzformációi című témakörben talál.
Ellenőrző pontok használata
A rugalmasság és a hibatűrés biztosítása érdekében a Spark Streaming az ellenőrzőpontokra támaszkodik, hogy a streamfeldolgozás zavartalanul folytatódhasson, még a csomóponthibák esetén is. A Spark ellenőrzőpontokat hoz létre a tartós tároláshoz (Azure Storage vagy Data Lake Storage). Ezek az ellenőrzőpontok tárolják a streamelési alkalmazás metaadatait, például a konfigurációt és az alkalmazás által meghatározott műveleteket. Emellett minden olyan köteg, amely várólistára került, de még nem lett feldolgozva. Előfordulhat, hogy az ellenőrzőpontok közé tartozik az adatok rdD-kben való mentése is, hogy gyorsabban újraépíthesse az adatok állapotát a Spark által felügyelt RDD-kből.
Spark Streaming-alkalmazások üzembe helyezése
A Spark Streaming-alkalmazásokat általában helyileg hozhatja létre JAR-fájlba. Ezután helyezze üzembe a Spark on HDInsightban a JAR-fájl alapértelmezett csatolt tárolóba másolásával. Az alkalmazást post művelettel indíthatja el a fürtből elérhető LIVY REST API-kkal. A POST törzse tartalmaz egy JSON-dokumentumot, amely megadja a JAR elérési útját. És annak az osztálynak a neve, amelynek fő metódusa meghatározza és futtatja a streamelési alkalmazást, valamint opcionálisan a feladat erőforrás-követelményeit (például a végrehajtók számát, a memóriát és a magokat). Emellett az alkalmazáskód által igényelt konfigurációs beállításokat is.
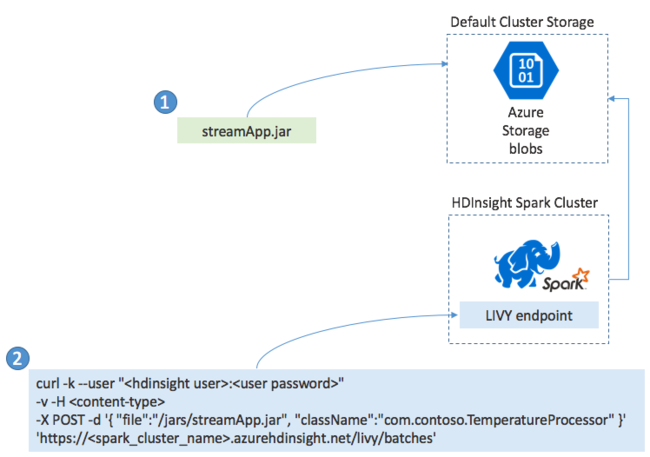
Az összes alkalmazás állapota egy GET kéréssel is ellenőrizhető egy LIVY-végponton. Végül befejezhet egy futó alkalmazást egy DELETE-kérés livy-végponton való kiadásával. A LIVY API részleteiért lásd : Távoli feladatok az Apache LIVY-vel