OutOfMemoryError kivételek az Apache Sparkhoz az Azure HDInsightban
Ez a cikk az Apache Spark-összetevők Azure HDInsight-fürtökben való használatakor felmerülő problémák hibaelhárítási lépéseit és lehetséges megoldásait ismerteti.
Forgatókönyv: OutOfMemoryError kivétel az Apache Sparkhoz
Probléma
Az Apache Spark-alkalmazás nem kezelt OutOfMemoryError kivétellel meghiúsult. A következőhöz hasonló hibaüzenet jelenhet meg:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Ok
A kivétel legvalószínűbb oka az, hogy nincs elegendő halommemória a Java virtuális gépekhez (JVM-ekhez). Ezek a JVM-k végrehajtóként vagy illesztőprogramként indulnak el az Apache Spark-alkalmazás részeként.
Resolution (Osztás)
Határozza meg a Spark-alkalmazás által kezelt adatok maximális méretét. Ezt a bemeneti adatok, a bemeneti adatok átalakításával keletkező köztes adatok és a köztes adatok további átalakításával keletkező kimeneti adatok maximális mérete alapján lehet megbecsülni. Ha a kezdeti becslés nem elegendő, növelje kissé a méretet, és ismételje, amíg a memóriahibák el nem múlnak.
Győződjön meg arról, hogy a használni kívánt HDInsight-fürtnek elegendő memória-erőforrás áll a rendelkezésére, és elegendő maggal rendelkezik a Spark-alkalmazás elhelyezéséhez. Ez a fürt YARN felhasználói felületének Fürtmetrikák szakaszának megtekintésével határozható meg a felhasznált memória és a felhasznált virtuális magok és a virtuális magok összesített értékeihez.

Állítsa be a következő Spark-konfigurációkat a megfelelő értékekre. Egyensúlyozza az alkalmazáskövetelményeket a fürtben elérhető erőforrásokkal. Ezek az értékek nem haladhatják meg a YARN által megtekintett memória és magok 90%-át, és meg kell felelniük a Spark-alkalmazás minimális memóriaigényének is:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Az összes végrehajtó által használt teljes memória =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Az illesztő által használt teljes memória =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Forgatókönyv: Java-halomtérhiba az Apache Spark előzménykiszolgáló megnyitásakor
Probléma
A Spark-előzmények kiszolgáló eseményeinek megnyitásakor a következő hibaüzenet jelenik meg:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Ok
Ezt a problémát gyakran az okozza, hogy nagy spark-event fájlok megnyitásakor nem áll rendelkezésre erőforrás. A Spark-halomméret alapértelmezés szerint 1 GB, de a nagy Spark-eseményfájlok ennél többet igényelhetnek.
Ha ellenőrizni szeretné a betölteni kívánt fájlok méretét, a következő parancsokat hajthatja végre:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Resolution (Osztás)
A Spark-előzménykiszolgáló memóriájának növeléséhez szerkessze a SPARK_DAEMON_MEMORY tulajdonságot a Spark-konfigurációban, és indítsa újra az összes szolgáltatást.
Ezt az Ambari böngésző felhasználói felületén teheti meg a Spark2/Config/Advanced spark2-env szakasz kiválasztásával.
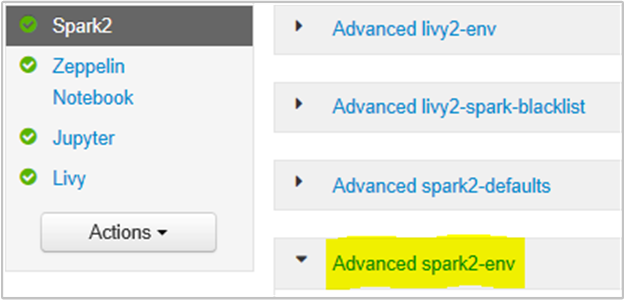
Adja hozzá a következő tulajdonságot a Spark History Server memóriájának 1g-ról 4g-ra való módosításához: SPARK_DAEMON_MEMORY=4g.
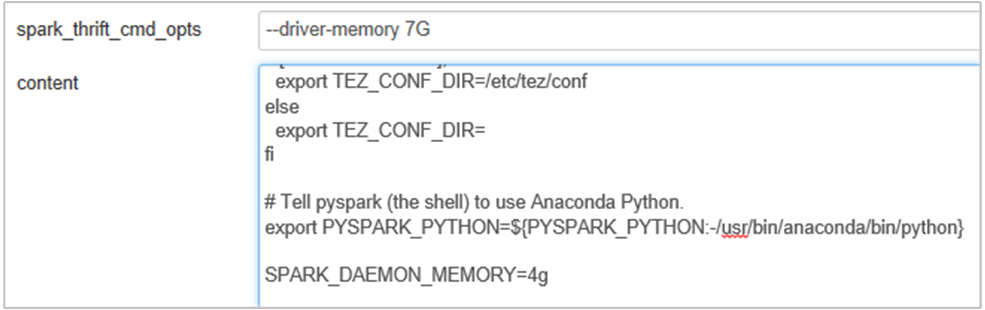
Mindenképpen indítsa újra az összes érintett szolgáltatást az Ambariból.
Forgatókönyv: A Livy-kiszolgáló nem indul el az Apache Spark-fürtön
Probléma
A Livy-kiszolgáló nem indítható el Apache Sparkon [(Spark 2.1 Linuxon (HDI 3.6)]. Az újraindítás megkísérlése a következő hiba vermet eredményezi a Livy-naplókból:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Ok
java.lang.OutOfMemoryError: unable to create new native thread kiemeli, hogy az operációs rendszer nem tud több natív szálat hozzárendelni a JVM-ekhez. Megerősítette, hogy ezt a kivételt a folyamatonkénti szálszám korlátjának megsértése okozza.
Amikor a Livy-kiszolgáló váratlanul leáll, a Spark-fürtökkel létesített összes kapcsolat is megszakad, ami azt jelenti, hogy az összes feladat és a kapcsolódó adatok elvesznek. A HDP 2.6-os munkamenet-helyreállítási mechanizmus bevezetésekor Livy a Zookeeperben tárolja a munkamenet részleteit, amelyeket a Livy-kiszolgáló visszatérése után kell helyreállítani.
Ha a Livyen keresztül ennyi feladat küldésére kerül sor, a Livy Server magas rendelkezésre állásának részeként ezeket a munkamenet-állapotokat ZK-ban (HDInsight-fürtökön) tárolja, és visszaállítja ezeket a munkameneteket a Livy szolgáltatás újraindításakor. A váratlan leállítás utáni újraindításkor Livy munkamenetenként egy szálat hoz létre, és ez összegyűjt néhány helyreállítandó munkamenetet, ami túl sok szál létrehozását okozza.
Resolution (Osztás)
Törölje az összes bejegyzést az alábbi lépésekkel.
A zookeeper-csomópontok IP-címének lekérése a következő használatával:
grep -R zk /etc/hadoop/confA fenti parancs egy fürt összes zookeeperét listázta
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>A zookeeper-csomópontok IP-címének lekérése pingelve Vagy a zookeeperhez is csatlakozhat a zookeeper-hez a zookeeper nevével
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Miután csatlakozott a zookeeperhez, hajtsa végre a következő parancsot az újraindításra kísérelt munkamenetek listázásához.
A legtöbb esetben ez több mint 8000 munkamenetet tartalmazó lista lehet ####
ls /livy/v1/batchA következő parancs az összes helyreállítandó munkamenet eltávolítása. #####
rmr /livy/v1/batch
Várja meg, amíg a fenti parancs befejeződik, és a kurzor visszaadja a parancssort, majd indítsa újra a Livy szolgáltatást az Ambariból, aminek sikeresnek kell lennie.
Feljegyzés
DELETE a livy munkamenet végrehajtása után. A Livy-köteg-munkamenetek nem törlődnek automatikusan, amint a Spark-alkalmazás befejeződik, ami terv szerint történik. A Livy-munkamenetek olyan entitások, amelyeket POST-kérés hozott létre a Livy REST-kiszolgálóval szemben. Az DELETE entitás törléséhez hívásra van szükség. Vagy várnunk kell, amíg a GC beindul.
Következő lépések
Ha nem látja a problémát, vagy nem tudja megoldani a problémát, további támogatásért látogasson el az alábbi csatornák egyikére:
Azure-szakértőktől kaphat választ az Azure közösségi támogatásán keresztül.
Csatlakozás @AzureSupport – a hivatalos Microsoft Azure-fiók az ügyfélélmény javításához. Csatlakozás az Azure-közösséget a megfelelő erőforrásokhoz: válaszokhoz, támogatáshoz és szakértőkhöz.
Ha további segítségre van szüksége, támogatási kérelmet küldhet az Azure Portalról. Válassza a Támogatás lehetőséget a menüsávon, vagy nyissa meg a Súgó + támogatási központot. Részletesebb információkért tekintse át a Azure-támogatás kérések létrehozását ismertető cikket. Az előfizetés-kezeléssel és számlázással kapcsolatos támogatás a Microsoft Azure-előfizetés részét képezi, míg a technikai támogatást Azure-támogatási csomagjainkkal biztosítjuk.