Az AutoML beállítása a számítógépes látásmodellek betanítása érdekében
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Ebből a cikkből megtudhatja, hogyan taníthat be számítógépes látásmodelleket képadatokon automatizált gépi tanulással. Modelleket az Azure Machine Tanulás CLI 2-s bővítményével vagy az Azure Machine Tanulás Python SDK 2-vel taníthat be.
Az automatizált gépi tanulás támogatja a modellbetanítást olyan számítógépes látástechnológiás feladatok esetében, mint a képbesorolás, objektumészlelés és a példányszegmentálás. Az AutoML-modellek számítógépes látástechnológiás feladatokhoz való létrehozása jelenleg az Azure Machine Learning Python SDK-n keresztül támogatott. Az eredményként kapott kísérletezési kísérletek, modellek és kimenetek az Azure Machine Tanulás studio felhasználói felületén érhetők el. További információ az automatikus ml-ről a képadatok számítógépes látási feladataihoz.
Előfeltételek
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
- Egy Azure Machine Learning-munkaterület. A munkaterület létrehozásához lásd : Munkaterület-erőforrások létrehozása.
- Telepítse és állítsa be a parancssori felületet (v2), és győződjön meg arról, hogy telepíti a bővítményt
ml.
Válassza ki a feladattípust
A rendszerképekhez készült automatizált gépi tanulás a következő feladattípusokat támogatja:
| Tevékenység típusa | AutoML-feladat szintaxisa |
|---|---|
| képbesorolás | CLI v2: image_classification SDK v2: image_classification() |
| képbesorolás többcímke | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| képobjektum-észlelés | CLI v2: image_object_detection SDK v2: image_object_detection() |
| képpéldány szegmentálása | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
Ez a feladattípus kötelező paraméter, és a task kulccsal állítható be.
Például:
task: image_object_detection
Betanítási és érvényesítési adatok
A számítógépes látásmodellek létrehozásához címkézett képadatokat kell bevinnie a modellbetanítás bemeneteként egy MLTable. JSONL formátumban hozhat létre betanítási MLTable adatokat.
Ha a betanítási adatok más formátumban vannak (például pascal VOC vagy COCO), a mintajegyzetfüzetekben található segédszkriptekkel JSONL-vé alakíthatja az adatokat. További információ az adatok számítógépes látási feladatokhoz való előkészítéséről az automatizált gépi tanulással.
Megjegyzés:
A betanítási adatoknak legalább 10 képből kell lenniük ahhoz, hogy autoML-feladatokat lehessen küldeni.
Figyelmeztetés
Az adatok JSONL formátumban való MLTable létrehozását csak az SDK és a CLI támogatja, ehhez a funkcióhoz. A MLTable felhasználói felület létrehozása jelenleg nem támogatott.
JSONL-sémaminták
A TabularDataset felépítése az adott feladattól függ. A computer vision tevékenységtípusok esetében a következő mezőkből áll:
| Mező | Description |
|---|---|
image_url |
A FilePath-t StreamInfo-objektumként tartalmazza |
image_details |
A kép metaadatai a magasságból, a szélességből és a formátumból állnak. Ez a mező nem kötelező, ezért előfordulhat, hogy nem létezik. |
label |
A képcímke json-ábrázolása a feladat típusa alapján. |
Az alábbi kód egy minta JSONL-fájl képbesoroláshoz:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Az alábbi kód egy objektumészlelési JSONL-mintafájl:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Adatok felhasználása
Miután az adatok JSONL formátumban vannak, létrehozhatja a betanítást és az ellenőrzést MLTable az alább látható módon.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Az automatizált gépi tanulás nem kényszeríti a betanítási vagy érvényesítési adatméretet a számítógépes látási feladatok esetében. Az adathalmaz maximális méretét csak az adathalmaz mögötti tárolási réteg korlátozza (például: blobtároló). Nincs minimális számú kép vagy címke. Javasoljuk azonban, hogy címkénként legalább 10–15 mintát kezdjen, hogy a kimeneti modell megfelelően be legyen tanítva. Minél nagyobb a címkék/osztályok teljes száma, annál több mintára van szükség címkénként.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
A betanítási adatok egy kötelező paraméter, és a kulcs használatával kerülnek átadásra training_data . Opcionálisan megadhat egy másik MLtable-t érvényesítési adatként a validation_data kulccsal. Ha nincs megadva érvényesítési adat, a betanítási adatok 20%-át használja alapértelmezés szerint az ellenőrzéshez, hacsak nem ad át validation_data_size egy másik értékkel rendelkező argumentumot.
A céloszlop neve kötelező paraméter, és a felügyelt ml-feladat céljaként használatos. A kulcs használatával target_column_name van átadva. Példa:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Számítás a kísérlet futtatásához
Adjon meg egy számítási célt az automatizált gépi tanuláshoz a modell betanításának elvégzéséhez. A számítógépes látási feladatok automatizált ml-modelljei gpu-termékváltozatokat igényelnek, és támogatják az NC- és ND-családokat. A gyorsabb betanításhoz az NCsv3 sorozatot (v100 GPU-kkal) javasoljuk. A több GPU-s virtuálisgép-termékváltozattal rendelkező számítási cél több GPU-val is felgyorsítja a betanítást. Emellett ha több csomóponttal állít be számítási célt, akkor a modell hiperparamétereinek finomhangolása során a párhuzamosságon keresztül gyorsabban végezheti el a modell betanítását.
Megjegyzés:
Ha számítási példányt használ számítási célként, győződjön meg arról, hogy több AutoML-feladat nem fut egyszerre. Emellett győződjön meg arról, hogy a max_concurrent_trials feladatkorlátok 1 értékre vannak állítva.
A számítási cél a paraméterrel compute lesz átadva. Például:
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
compute: azureml:gpu-cluster
Kísérletek konfigurálása
A számítógépes látási feladatokhoz egyéni próbaidőszakokat, manuális vagy automatikus nyereményjátékokat is indíthat. Javasoljuk, hogy az első alapmodell beszerzéséhez kezdjen automatikus takarítással. Ezután kipróbálhatja az egyes próbaidőszakokat bizonyos modellekkel és hiperparaméter-konfigurációkkal. Végül a manuális takarítással több hiperparaméter-értéket is felfedezhet az ígéretesebb modellek és hiperparaméter-konfigurációk közelében. Ez a háromlépéses munkafolyamat (automatikus takarítás, egyéni próbaverziók, manuális takarítások) elkerüli a hiperparaméter teljes területének keresését, ami exponenciálisan növekszik a hiperparaméterek számában.
Az automatikus nyereményjátékok számos adathalmaz esetében versenyképes eredményeket hozhatnak. Emellett nem igényelnek fejlett modellarchitektúra-ismereteket, figyelembe veszik a hiperparaméter-korrelációkat, és zökkenőmentesen működnek a különböző hardverbeállítások között. Mindezek az okok miatt a kísérletezés korai szakaszában erős választássá teszik őket.
Elsődleges metrika
Az AutoML-betanítási feladatok elsődleges metrikát használnak a modelloptimalizáláshoz és a hiperparaméter finomhangolásához. Az elsődleges metrika az alább látható tevékenységtípustól függ; az egyéb elsődleges metrikaértékek jelenleg nem támogatottak.
- Képbesorolás pontossága
- Metszet a többcímkés képosztályozás egyesítésénél
- Átlagos pontosság a képobjektumok észleléséhez
- Átlagos pontosság a képpéldány szegmentálásához
A feladat korlátja
Az AutoML-rendszerkép betanítási feladatára fordított erőforrásokat úgy szabályozhatja, max_trials hogy megadja az timeout_minutesmax_concurrent_trials alábbi példában leírt korlátbeállításokat a feladathoz és a feladathoz.
| Paraméter | Részlet |
|---|---|
max_trials |
A takarításhoz szükséges kísérletek maximális számának paramétere. 1 és 1000 közötti egész számnak kell lennie. Ha csak az adott modellarchitektúra alapértelmezett hiperparamétereit vizsgálja meg, állítsa ezt a paramétert 1 értékre. Az alapértelmezett érték 1. |
max_concurrent_trials |
Az egyidejűleg futtatható kísérletek maximális száma. Ha meg van adva, 1 és 100 közötti egész számnak kell lennie. Az alapértelmezett érték 1. MEGJEGYZÉS: max_concurrent_trials belsőleg van leképezve max_trials . Ha például a felhasználó beállítja max_concurrent_trials=4, max_trials=2az értékek belsőleg frissülnek a következőként max_concurrent_trials=2: , max_trials=2. |
timeout_minutes |
A kísérlet befejeződése előtt percek alatt eltelt idő. Ha nincs megadva, az alapértelmezett kísérlet timeout_minutes hét nap (legfeljebb 60 nap) |
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Modell hiperparamétereinek automatikus takarítása (AutoMode)
Fontos
Ez a funkció jelenleg nyilvános előzetes verzióban érhető el. Ez az előzetes verzió szolgáltatásszintű szerződés nélkül érhető el. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Nehéz előrejelezni az adatkészletek legjobb modellarchitektúráját és hiperparamétereit. Bizonyos esetekben a hiperparaméterek finomhangolásához lefoglalt emberi idő is korlátozott lehet. A számítógépes látási feladatokhoz tetszőleges számú próbaverziót megadhatja, és a rendszer automatikusan meghatározza a hiperparaméter területének a takarításhoz szükséges régióját. Nem kell hiperparaméteres keresési területet, mintavételezési módszert vagy korai megszüntetési szabályzatot definiálnia.
AutoMode aktiválása
Az automatikus takarítást úgy futtathatja, hogy 1-nél limits nagyobb értéket ad max_trials meg, és nem adja meg a keresési területet, a mintavételezési módszert és a megszüntetési szabályzatot. Ezt a funkciót AutoMode-nak hívjuk; lásd a következő példát.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
limits:
max_trials: 10
max_concurrent_trials: 2
A 10 és 20 közötti kísérletek száma valószínűleg sok adathalmazon jól működik. Az AutoML-feladat időkerete továbbra is beállítható, de ezt csak akkor javasoljuk, ha az egyes próbaverziók hosszú ideig tarthatnak.
Figyelmeztetés
Az automatikus nyereményjátékok felhasználói felületen való elindítása jelenleg nem támogatott.
Egyéni próbaverziók
Az egyes próbaidőszakokban közvetlenül szabályozhatja a modellarchitektúrát és a hiperparamétereket. A modellarchitektúra a model_name paraméteren keresztül lesz átadva.
Támogatott modellarchitektúrák
Az alábbi táblázat az egyes számítógépes látási feladatok támogatott örökölt modelljeit foglalja össze. Ha csak ezeket az örökölt modelleket használja, az örökölt futtatókörnyezet használatával aktiválja a futtatásokat (ahol az egyes futtatások vagy próbaverziók parancsfeladatként lesznek elküldve). A HuggingFace és az MMDetection támogatásáról alább olvashat.
| Task | modellarchitektúrák | Sztringkonstans szintaxisadefault_model* *-nal jelölve |
|---|---|---|
| Képbesorolás (többosztályos és többcímkés) |
MobileNet: Egyszerűsített modellek mobilalkalmazásokhoz ResNet: Reziduális hálózatok ResNeSt: Figyelési hálózatok felosztása Standard kiadás-ResNeXt50: Kiszorítási és gerjesztési hálózatok ViT: Vision transzformátor hálózatok |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (kicsi) vitb16r224* (alap) vitl16r224 (nagy) |
| Objektumészlelés | YOLOv5: Egyfázisú objektumészlelési modell Gyorsabb RCNN ResNet FPN: Kétfázisú objektumészlelési modellek RetinaNet ResNet FPN: az osztály kiegyensúlyozatlanságának kezelése a fókuszveszteséggel Megjegyzés: A YOLOv5-modellméretekhez tekintse meg model_size a hiperparamétert . |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Példányszegmentálás | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Támogatott modellarchitektúrák – HuggingFace és MMDetection (előzetes verzió)
Az Azure Machine-Tanulás-folyamatokon futó új háttérrendszerrel emellett bármilyen képosztályozási modellt használhat a HuggingFace Hubról, amely a transzformátorok kódtárának része (például microsoft/beit-base-patch16-224), valamint az MMDetection 3.1.0 Model Zoo -ból származó objektumészlelési vagy példányszegmentálási modellt (például atss_r50_fpn_1x_coco).
A HuggingFace Transfomers és az MMDetection 3.1.0 bármely modelljének támogatása mellett az azureml-beállításjegyzékben ezen kódtárakból származó válogatott modellek listáját is kínáljuk. Ezeket a válogatott modelleket alaposan teszteltük, és a hatékony betanítás érdekében a széles körű teljesítménymérésből kiválasztott alapértelmezett hiperparamétereket használjuk. Az alábbi táblázat összefoglalja ezeket a válogatott modelleket.
| Task | modellarchitektúrák | Sztringkonstans szintaxisa |
|---|---|---|
| Képbesorolás (többosztályos és többcímkés) |
Beit Vit DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Objektumészlelés | Ritka R-CNN Deformálható DETR VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Példány szegmentálása | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Folyamatosan frissítjük a válogatott modellek listáját. A Python SDK használatával lekérheti az adott feladathoz tartozó válogatott modellek legfrissebb listáját:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Output:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Bármely HuggingFace- vagy MMDetection-modell használata folyamatösszetevők használatával indítja el a futtatásokat. Ha örökölt és HuggingFace/MMdetection modelleket is használ, az összes futtatás/próba összetevővel aktiválódik.
A modellarchitektúra szabályozása mellett a modell betanításához használt hiperparamétereket is hangolhatja. Bár a közzétett hiperparaméterek többsége modellfüggő, vannak olyan példányok, ahol a hiperparaméterek feladatspecifikusak vagy modellspecifikusak. További információ az ilyen példányokhoz elérhető hiperparaméterekről.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
Ha egy adott architektúra (például yolov5) alapértelmezett hiperparaméter-értékeit szeretné használni, a training_parameters szakaszban található model_name kulccsal adhatja meg. Példa:
training_parameters:
model_name: yolov5
Modell hiperparamétereinek manuális takarítása
A számítógépes látásmodellek betanításakor a modell teljesítménye nagymértékben függ a kiválasztott hiperparaméter-értékektől. Gyakran érdemes lehet a hiperparamétereket finomhangolni az optimális teljesítmény érdekében. A számítógépes látási feladatokhoz a hiperparamétereket átsöprve megtalálhatja a modell optimális beállításait. Ez a funkció az Azure Machine Tanulás hiperparaméter-finomhangolási képességeit alkalmazza. Megtudhatja, hogyan hangolhatja a hiperparamétereket.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
A paraméter keresési helyének meghatározása
Meghatározhatja a modellarchitektúrákat és a hiperparamétereket, hogy a paramétertérben söpörjenek. Megadhat egy vagy több modellarchitektúrát.
- Az egyes tevékenységtípusok támogatott modellarchitektúráinak listáját az egyéni próbaverziókban találja.
- Lásd : Hyperparameters for computer vision tasks hyperparameters for each computer vision task type.
- A különálló és folyamatos hiperparaméterek támogatott eloszlásainak részletei.
Mintavételi módszerek a takarításhoz
Hiperparaméterek seprésekor meg kell adnia a mintavételezési módszert, amelyet a megadott paraméterterületen való átsöpréshez használ. Jelenleg a következő mintavételezési módszerek támogatottak a sampling_algorithm paraméterrel:
| Mintavételezési típus | AutoML-feladat szintaxisa |
|---|---|
| Véletlenszerű mintavételezés | random |
| Rácsos mintavételezés | grid |
| Bayesian mintavételezés | bayesian |
Megjegyzés:
Jelenleg csak a véletlenszerű és a rácsos mintavételezés támogatja a feltételes hiperparaméter-szóközöket.
Korai megszüntetési szabályzatok
A rosszul teljesítő próbaidőszakokat automatikusan megszüntetheti egy korai felmondási szabályzattal. A korai megszüntetés javítja a számítási hatékonyságot, így olyan számítási erőforrásokat takarít meg, amelyeket egyébként kevésbé ígéretes kísérletekre fordítottak volna. A rendszerképekhez készült automatizált gépi tanulás a következő korai megszüntetési szabályzatokat támogatja a early_termination paraméter használatával. Ha nincs megadva leállítási szabályzat, az összes próba végrehajtása befejeződik.
| Korai felmondási szabályzat | AutoML-feladat szintaxisa |
|---|---|
| Bandit szabályzat | CLI v2: bandit SDK v2: BanditPolicy() |
| Medián-leállítási szabályzat | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Csonkítás kiválasztási szabályzata | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
További információ a hiperparaméter-takarítás korai megszakítási szabályzatának konfigurálásáról.
Megjegyzés:
A teljes takarítási konfigurációs mintaért tekintse meg ezt az oktatóanyagot.
Az alábbi példában látható módon konfigurálhatja az összes takarítással kapcsolatos paramétert.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Rögzített beállítások
Az alábbi példában látható módon olyan rögzített beállításokat vagy paramétereket adhat át, amelyek nem változnak a paraméterterület-takarítás során.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Adatnagyobbítás
A mélytanulási modell teljesítménye általában több adattal javítható. Az adatnagyobbítás gyakorlati módszer az adathalmazok adatméretének és variabilitásának felerősítésére, amely segít megelőzni a modell túlillesztési és általánosítási képességét a nem látott adatokon. Az automatizált gépi tanulás különböző adatnagyobbítási technikákat alkalmaz a számítógépes látási feladat alapján, mielőtt bemeneti képeket ad a modellhez. Jelenleg nincs közzétéve hiperparaméter az adatnagyobbítás szabályozásához.
| Task | Érintett adathalmaz | Alkalmazott adatnagyobbítási technika(ok) |
|---|---|---|
| Képbesorolás (többosztályos és többcímke) | Képzés Ellenőrzés > teszt |
Véletlenszerű átméretezés és körülvágás, vízszintes tükrözés, szín jitter (fényerő, kontraszt, telítettség és árnyalat), normalizálás csatorna-bölcs ImageNet középérték és szórás használatával Átméretezés, körülvágás középre igazítása, normalizálás |
| Objektumészlelés, példányszegmentálás | Képzés Ellenőrzés > teszt |
Véletlenszerű körülvágás a határolókeretek körül, kibontás, vízszintes tükrözés, normalizálás, átméretezés Normalizálás, átméretezés |
| Objektumészlelés a yolov5 használatával | Képzés Ellenőrzés > teszt |
Mozaik, véletlenszerű affine (forgatás, fordítás, skálázás, nyírás), vízszintes tükrözés Postaláda átméretezése |
Jelenleg a rendszer alapértelmezés szerint alkalmazza a fent definiált kiegészítéseket egy automatikus gépi tanulási feladathoz a rendszerkép-feladatokhoz. A kiegészítések vezérlésének biztosítása érdekében a képekhez készült automatizált gépi tanulás két jelző alatt teszi elérhetővé bizonyos bővítmények kikapcsolását. Ezek a jelzők jelenleg csak az objektumészlelési és példányszegmentálási feladatok esetében támogatottak.
- apply_mosaic_for_yolo: Ez a jelző csak a Yolo-modellre vonatkozik. Ha False értékre állítja, kikapcsolja a betanításkor alkalmazott mozaikadat-bővítést.
- apply_automl_train_augmentations: Ha ezt a jelzőt hamis értékre állítja, kikapcsolja az objektumészlelési és példányszegmentálási modellek betanítási ideje alatt alkalmazott kiegészítést. A kiegészítéseket a fenti táblázatban találja.
- A nem yolo objektumészlelési modell és a példányszegmentálási modellek esetében ez a jelző csak az első három bővítést kapcsolja ki. Például: Véletlenszerű körülvágás a határolókeretek körül, kibontás, vízszintes tükrözés. A normalizálási és átméretezési bővítéseket a rendszer ettől a jelzőtől függetlenül továbbra is alkalmazza.
- A Yolo-modell esetében ez a jelző kikapcsolja a véletlenszerű affine-t és a vízszintes tükrözési kiegészítéseket.
Ez a két jelző advanced_settings training_parameters alatt támogatott, és az alábbi módon vezérelhető.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Vegye figyelembe, hogy ez a két jelző független egymástól, és az alábbi beállításokkal kombinálva is használható.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Kísérleteink során megállapítottuk, hogy ezek a kiegészítések segítenek a modell általánosításában. Ezért ha ezek a kiegészítések ki vannak kapcsolva, azt javasoljuk a felhasználóknak, hogy kombinálják őket más offline kiegészítésekkel a jobb eredmények érdekében.
Növekményes betanítás (nem kötelező)
A betanítási feladat befejezése után a betanított modell ellenőrzőpontjának betöltésével tovább taníthatja a modellt. Használhatja ugyanazt az adatkészletet vagy egy másikat a növekményes betanításhoz. Ha elégedett a modellel, leállíthatja a betanítást, és használhatja az aktuális modellt.
Az ellenőrzőpont átadása feladatazonosítón keresztül
Megadhatja azt a feladatazonosítót, amelyből be szeretné tölteni az ellenőrzőpontot.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Az AutoML-feladat elküldése
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
Az AutoML-feladat elküldéséhez futtassa a következő CLI v2 parancsot az .yml fájl elérési útjával, a munkaterület nevével, az erőforráscsoporttal és az előfizetés azonosítójával.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Kimenetek és kiértékelési metrikák
Az automatizált gépi tanulási feladatok kimeneti modellfájlokat, kiértékelési metrikákat, naplókat és üzembehelyezési összetevőket hoznak létre, például a pontozófájlt és a környezeti fájlt. Ezek a fájlok és metrikák a gyermekfeladatok kimenetei, naplói és metrikái lapjáról tekinthetők meg.
Tipp.
Ellenőrizze, hogyan navigálhat a feladateredmények között a Feladateredmények megtekintése szakaszban.
Az egyes feladatokhoz megadott teljesítménydiagramokra és metrikákra vonatkozó definíciókat és példákat az automatizált gépi tanulási kísérletek eredményeinek kiértékelése című témakörben talál.
Modell regisztrálása és üzembe helyezése
Miután a feladat befejeződött, regisztrálhatja a legjobb próbaverzióból létrehozott modellt (olyan konfigurációt, amely a legjobb elsődleges metrikát eredményezte). A modellt a letöltés után regisztrálhatja, vagy megadhatja az azureml elérési útját a megfelelő feladatazonosítóval. Megjegyzés: Ha módosítani szeretné az alább ismertetett következtetési beállításokat, le kell töltenie a modellt, és módosítania kell a settings.json fájlt, és regisztrálnia kell a frissített modellmappával.
A legjobb próbaverzió lekérése
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
CLI example not available, please use Python SDK.
a modell regisztrálása
Regisztrálja a modellt az azureml elérési út vagy a helyileg letöltött elérési út használatával.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
A használni kívánt modell regisztrálása után üzembe helyezheti azt a felügyelt online végponttal , a deploy-managed-online-endpoint használatával.
Online végpont konfigurálása
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
A végpont létrehozása
A MLClient korábban létrehozottak használatával létrehozzuk a végpontot a munkaterületen. Ez a parancs elindítja a végpont létrehozását, és egy megerősítést kérő választ ad vissza, amíg a végpont létrehozása folytatódik.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Online üzemelő példány konfigurálása
Az üzembe helyezés a tényleges következtetést okozó modell üzemeltetéséhez szükséges erőforrások készlete. Létrehozunk egy üzembe helyezést a végponthoz az ManagedOnlineDeployment osztály használatával. Az üzembehelyezési fürthöz GPU-t vagy CPU-beli virtuálisgép-termékváltozatokat is használhat.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Az üzembe helyezés létrehozása
MLClient A korábban létrehozottak használatával most létrehozzuk az üzembe helyezést a munkaterületen. Ez a parancs elindítja az üzembe helyezés létrehozását, és megerősítést kérő választ ad vissza, amíg a telepítés létrehozása folytatódik.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
forgalom frissítése:
Alapértelmezés szerint az aktuális üzemelő példány 0%-os forgalmat fogad. beállíthatja, hogy az aktuális üzemelő példány hány százalékos forgalommal rendelkezzen. Az egy végponttal rendelkező üzemelő példányok forgalmi százalékának összege nem haladhatja meg a 100%-ot.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Másik lehetőségként üzembe helyezheti a modellt az Azure Machine Tanulás studio felhasználói felületén. Lépjen az automatizált gépi tanulási feladat Modellek lapján üzembe helyezni kívánt modellre, és válassza az Üzembe helyezés lehetőséget, és válassza az Üzembe helyezés valós idejű végponton lehetőséget.
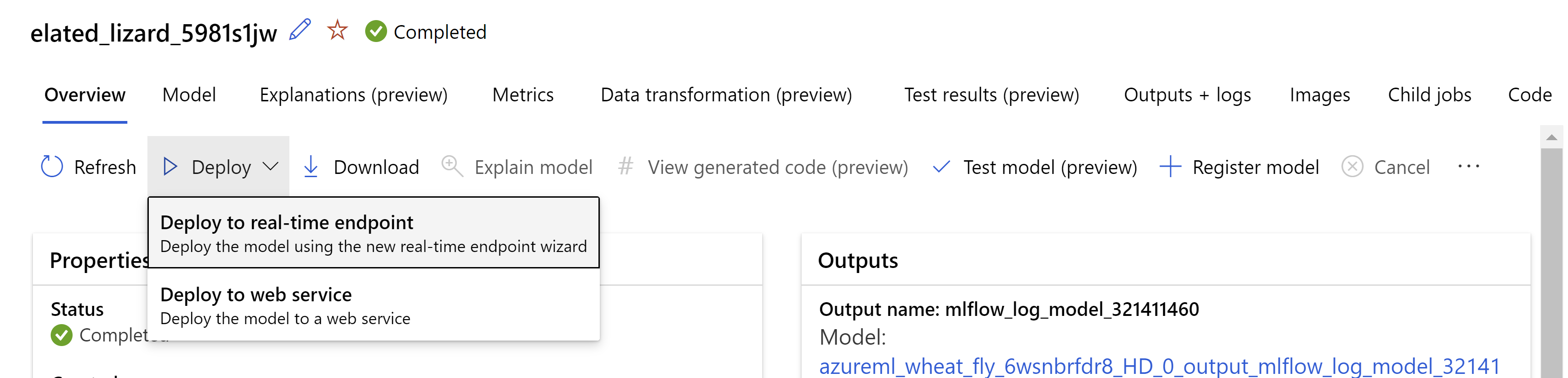 .
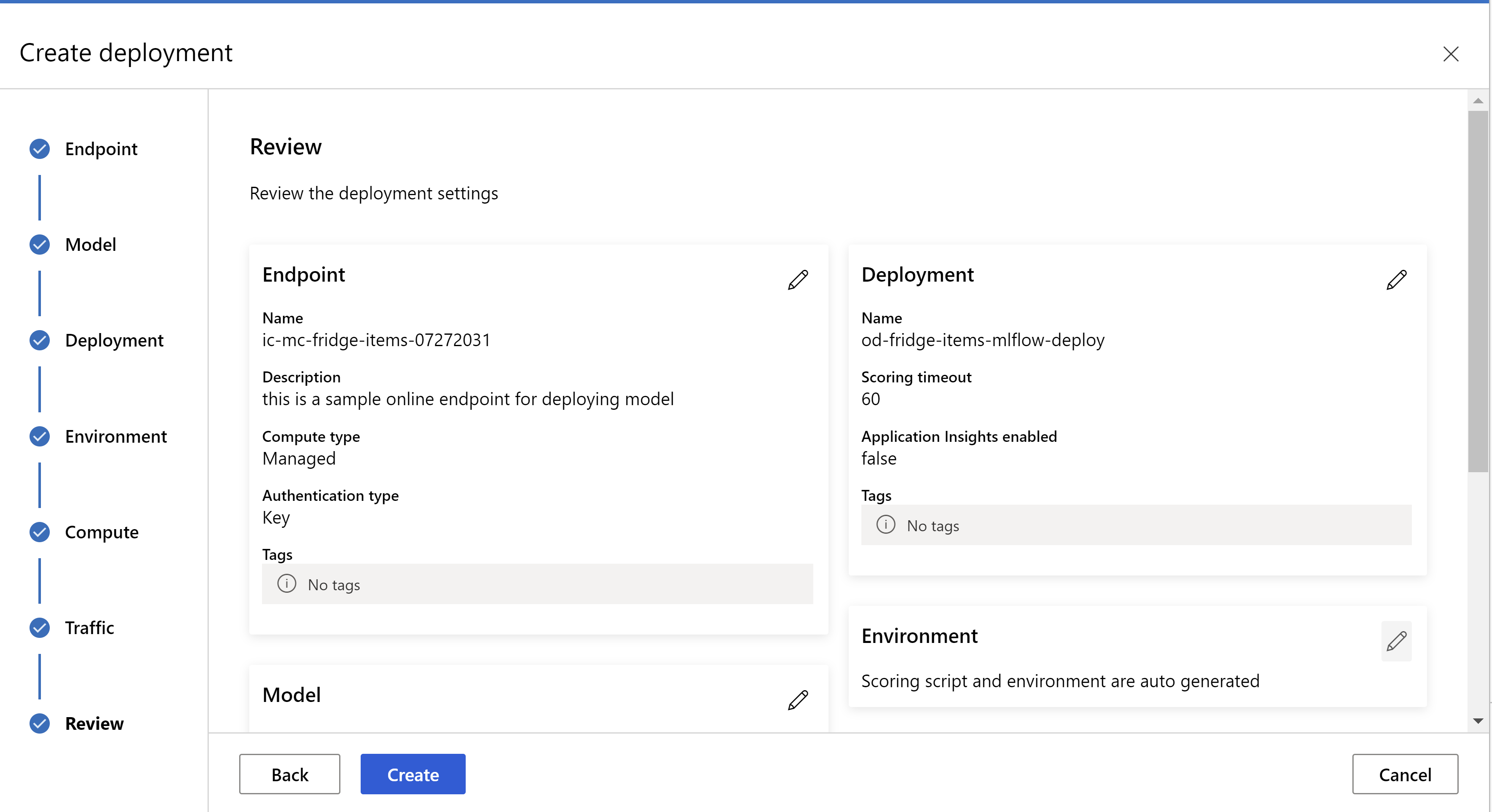
.
így néz ki a felülvizsgálati oldal. Kiválaszthatjuk a példány típusát, a példányok számát és a forgalom százalékos értékét az aktuális üzemelő példányhoz.
 .
.
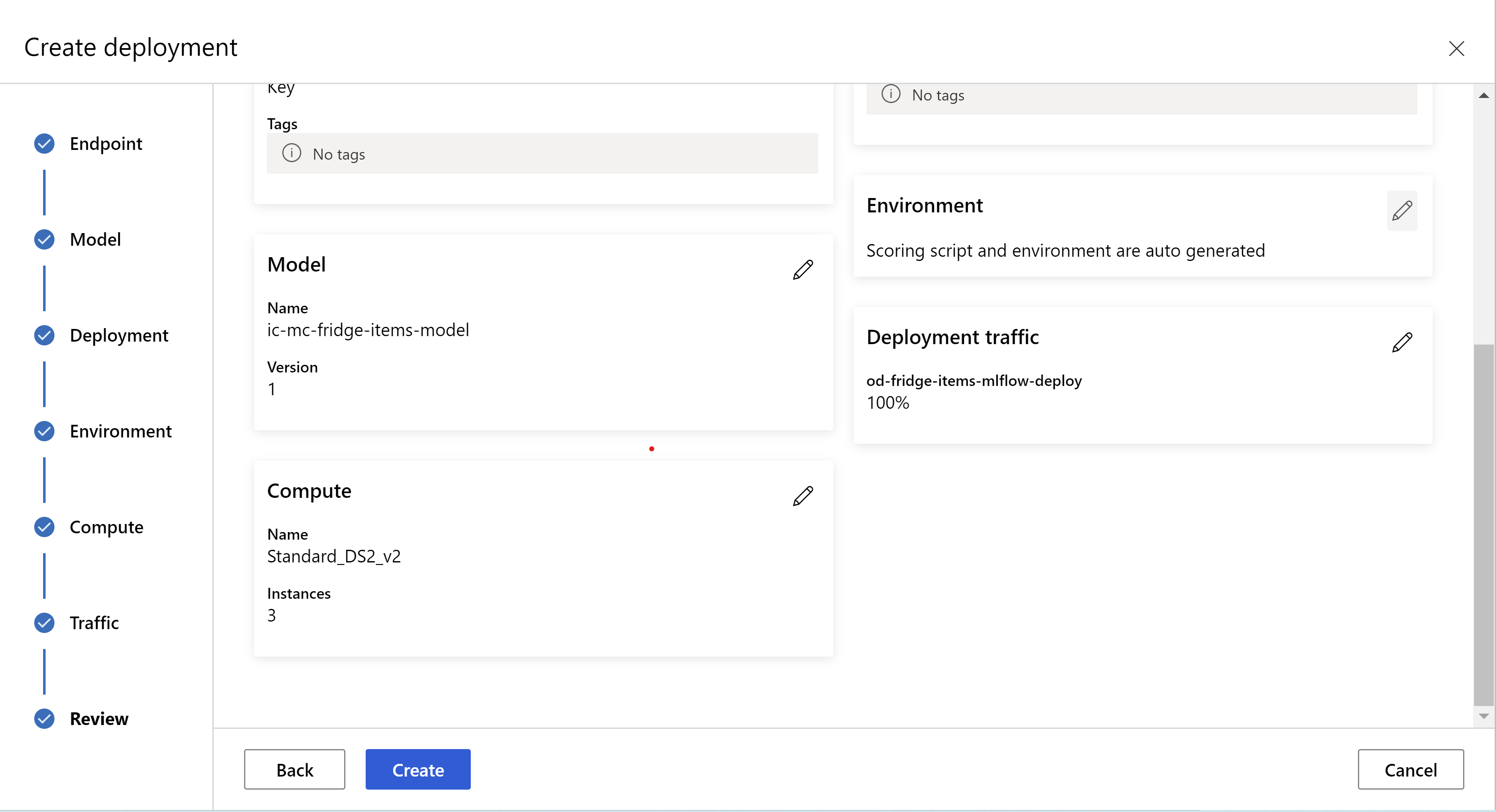 .
.
Következtetési beállítások frissítése
Az előző lépésben letöltöttünk egy fájlt mlflow-model/artifacts/settings.json a legjobb modellből. használatával frissítheti a következtetési beállításokat a modell regisztrálása előtt. Bár a legjobb teljesítmény érdekében ajánlott ugyanazokat a paramétereket használni, mint a betanítás.
Mindegyik tevékenység (és néhány modell) rendelkezik paraméterekkel. Alapértelmezés szerint ugyanazokat az értékeket használjuk a betanítás és ellenőrzés során használt paraméterekhez. Attól függően, hogy milyen viselkedésre van szükség a modell következtetéséhez, módosíthatjuk ezeket a paramétereket. Az alábbiakban megtalálja az egyes tevékenységtípusokhoz és modellekhez tartozó paraméterek listáját.
| Task | Paraméter neve | Alapértelmezett |
|---|---|---|
| Képbesorolás (többosztályos és többcímke) | valid_resize_sizevalid_crop_size |
256 224 |
| Objektumészlelés | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0,5 100 |
Objektumészlelés a következő használatával: yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 közepes 0,1 0,5 |
| Példányszegmentálás | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0,5 100 0,5 100 False JPG |
A feladatspecifikus hiperparaméterek részletes leírásáért tekintse meg az automatizált gépi tanulásban a számítógépes látási feladatok hyperparamétereit.
Ha burkolást szeretne használni, és szabályozni szeretné a burkolás viselkedését, a következő paraméterek érhetők el: tile_grid_sizeés tile_overlap_ratiotile_predictions_nms_thresh. Ezekről a paraméterekről további információt az AutoML használatával végzett kis objektumészlelési modell betanítása című témakörben talál.
Az üzemelő példány tesztelése
A telepítés teszteléséhez és a modellből származó észlelések vizualizációjának megtekintéséhez tekintse meg ezt a Tesztelés szakaszt.
Magyarázatok létrehozása az előrejelzésekhez
Fontos
Ezek a beállítások jelenleg nyilvános előzetes verzióban érhetők el. Ezek szolgáltatásszint-szerződés nélkül érhetők el. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Figyelmeztetés
A modell magyarázata csak többosztályos és többcímkés besorolás esetén támogatott.
A magyarázható AI (XAI) és az AutoML képekhez való használatának néhány előnye:
- Javítja az átláthatóságot az összetett látásmodell-előrejelzésekben
- Segít a felhasználóknak megérteni a bemeneti kép azon fontos funkcióit/képpontjait, amelyek hozzájárulnak a modell előrejelzéseihez
- Segítség a modellek hibaelhárításához
- Segít felderíteni az elfogultságokat
Magyarázatok
A magyarázatok a bemeneti kép egyes képpontjainak adott jellemzők vagy súlyok, a modell előrejelzéséhez való hozzájárulásuk alapján. Az egyes súlyok lehetnek negatívak (negatívan korrelálnak az előrejelzéssel) vagy pozitívak (pozitívan korrelálnak az előrejelzéssel). Ezek a hozzárendelések az előrejelzett osztály alapján lesznek kiszámítva. Többosztályos besorolás esetén a rendszer mintánként pontosan egy méretezési attribútummátrixot [3, valid_crop_size, valid_crop_size] hoz létre, míg a többcímkés besorolás esetén a rendszer minden egyes minta előrejelzett címkéje/osztálya esetében létrehozza a méretet [3, valid_crop_size, valid_crop_size] .
Ha az AutoML for Imagesben magyarázó AI-t használ az üzembe helyezett végponton, a felhasználók minden képhez megkaphatják a magyarázatok vizualizációit (a bemeneti lemezképen túlterjedő attribútumokat) és/vagy a hozzárendeléseket (többdimenziós mérettömb[3, valid_crop_size, valid_crop_size]). A vizualizációkon kívül a felhasználók hozzárendelési mátrixokat is kaphatnak, hogy jobban szabályozni tudják a magyarázatokat (például egyéni vizualizációkat hozhatnak létre hozzárendelések használatával vagy a hozzárendelések szegmenseinek vizsgálatával). Az összes magyarázó algoritmus körülvágott négyzet alakú képeket valid_crop_size használ a hozzárendelések létrehozásához.
Magyarázatok online végpontról vagy kötegvégpontról is létrehozhatók. Az üzembe helyezés befejezése után ez a végpont használható az előrejelzések magyarázatainak létrehozásához. Online üzemelő példányokban mindenképpen adja meg request_settings = OnlineRequestSettings(request_timeout_ms=90000) a paramétert ManagedOnlineDeployment , és állítsa a request_timeout_ms maximális értékére, hogy elkerülje az időtúllépési problémákat magyarázatok létrehozásakor (lásd a modell regisztrálását és üzembe helyezését ismertető szakaszt). Néhány magyarázó (XAI) módszer, például xrai több időt használ fel (különösen a többcímkés besoroláshoz, mivel minden előrejelzett címkéhez hozzárendeléseket és/vagy vizualizációkat kell létrehoznunk). Ezért a gyorsabb magyarázat érdekében minden GPU-példányt javasoljuk. A magyarázatok létrehozásához a bemeneti és kimeneti sémával kapcsolatos további információkért tekintse meg a séma dokumentációját.
A képekhez az AutoML-ben a következő korszerű magyarázó algoritmusokat támogatjuk:
- XRAI (xrai)
- Integrált színátmenetek (integrated_gradients)
- Irányított GradCAM (guided_gradcam)
- Irányított backpropagation (guided_backprop)
Az alábbi táblázat az XRAI és az integrált színátmenetek magyarázó algoritmusspecifikus hangolási paramétereit ismerteti. Az irányított backpropagation és az irányított gradcam nem igényel hangolási paramétereket.
| XAI-algoritmus | Algoritmusspecifikus paraméterek | Alapértelmezett értékek |
|---|---|---|
xrai |
1. n_steps: A közelítési módszer által használt lépések száma. A nagyobb számú lépés a leírások (magyarázatok) jobb közelítéséhez vezet. A n_steps tartománya [2, inf), de a hozzárendelések teljesítménye 50 lépés után elkezd konvergálni. Optional, Int 2. xrai_fast: Az XRAI gyorsabb verziójának használata. ha True, akkor a magyarázatok számítási ideje gyorsabb, de kevésbé pontos magyarázatokhoz (hozzárendelésekhez) vezet Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: A közelítési módszer által használt lépések száma. A nagyobb számú lépés jobb leírásokhoz (magyarázatokhoz) vezet. A n_steps tartománya [2, inf), de a hozzárendelések teljesítménye 50 lépés után elkezd konvergálni.Optional, Int 2. approximation_method: Az integrál közelítésének módszere. A rendelkezésre álló közelítési módszerek a következők: riemann_middle és gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Az XRAI-algoritmus belsőleg integrált színátmeneteket használ. n_steps A paramétert tehát az integrált színátmenetek és az XRAI-algoritmusok is megkövetelik. A nagyobb számú lépés több időt emészt fel a magyarázatok közelítéséhez, és időtúllépési problémákat okozhat az online végponton.
A jobb magyarázat érdekében javasoljuk az XRAI-alapú > irányított GradCAM > integrált színátmenetek > irányított BackPropagation algoritmusok használatát, míg az irányított BackPropagation > irányított GradCAM > integrált színátmenetek > XRAI használata javasolt a megadott sorrendben történő gyorsabb magyarázathoz.
Az online végpontra irányuló mintakérés az alábbihoz hasonlóan néz ki. Ez a kérés magyarázatokat hoz létre, ha model_explainability be van állítva True. A következő kérés 50 lépéssel generál vizualizációkat és hozzárendeléseket az XRAI-algoritmus gyorsabb verziójával.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
További információ a magyarázatok létrehozásával kapcsolatban: GitHub notebook-adattár automatizált gépi tanulási mintákhoz.
Vizualizációk értelmezése
Az üzembe helyezett végpont base64 kódolású képsztringet ad vissza, ha mindkettő model_explainabilityvisualizations be van állítva True. Dekódolja a base64 sztringet a jegyzetfüzetekben leírtak szerint, vagy használja az alábbi kódot a base64-es képsztringek dekódolásához és megjelenítéséhez az előrejelzésben.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Az alábbi kép egy minta bemeneti kép magyarázatainak vizualizációját ismerteti.

A dekódolt base64 ábra négy képszakaszt tartalmaz egy 2 x 2 rácson belül.
- A bal felső sarokban lévő kép (0, 0) a körülvágott bemeneti kép
- A jobb felső sarokban lévő kép (0, 1) a színskálán lévő bgyw (kék zöld sárga fehér) hozzárendelések hőtérképe, ahol az előrejelzett osztály fehér képpontjainak hozzájárulása a legmagasabb, a kék képpontok pedig a legalacsonyabbak.
- A bal alsó sarokban lévő kép (1, 0) a körülvágott bemeneti kép hozzárendeléseinek kevert hőtérképe
- A jobb alsó sarokban lévő kép (1, 1) a körülvágott bemeneti kép, amely a képpontok 30%-át adja meg a hozzárendelési pontszámok alapján.
Attribútumok értelmezése
Az üzembe helyezett végpont a hozzárendeléseket adja vissza, ha mindkettőre model_explainabilityattributions van állítva True. További részletekért tekintse meg a többosztályos besorolást és a többcímkés besorolási jegyzetfüzeteket.
Ezek a hozzárendelések nagyobb ellenőrzést biztosítanak a felhasználóknak az egyéni vizualizációk létrehozásához vagy a képpontszintű hozzárendelési pontszámok vizsgálatához. Az alábbi kódrészlet bemutatja, hogyan hozhat létre egyéni vizualizációkat a hozzárendelési mátrix használatával. A többosztályos és a többcímkés besorolás hozzárendelési sémájára vonatkozó további információkért tekintse meg a séma dokumentációját.
A magyarázatok létrehozásához használja a kiválasztott modell pontos valid_resize_size és valid_crop_size értékeit (az alapértelmezett értékek 256, illetve 224). A következő kód a Captum vizualizációs funkcióját használja egyéni vizualizációk létrehozásához. A felhasználók bármely más kódtárat használhatnak vizualizációk létrehozásához. További részletekért tekintse meg a captum vizualizációs segédprogramokat.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Nagyméretű adathalmazok
Ha autoML-t használ a nagy adathalmazok betanítása érdekében, néhány kísérleti beállítás hasznos lehet.
Fontos
Ezek a beállítások jelenleg nyilvános előzetes verzióban érhetők el. Ezek szolgáltatásszint-szerződés nélkül érhetők el. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Több GPU és többcsomópontos betanítás
Alapértelmezés szerint minden modell egyetlen virtuális gépen vonatoz. Ha egy modell betanítása túl sok időt vesz igénybe, több GPU-t tartalmazó virtuális gépek használata segíthet. A nagy adathalmazokra vonatkozó modellek betanítása nagyjából lineáris arányban kell, hogy történjen a használt GPU-k számával. (Például egy modellnek nagyjából kétszer olyan gyorsan kell betanulnia egy két GPU-val rendelkező virtuális gépen, mint egy GPU-val rendelkező virtuális gépen.) Ha a modellek betanítása még mindig magas egy több GPU-val rendelkező virtuális gépen, növelheti az egyes modellek betanítása során használt virtuális gépek számát. A több GPU-s betanításhoz hasonlóan a modell nagy adathalmazokon való betanításának ideje is nagyjából lineárisan csökken a használt virtuális gépek számával. Ha több virtuális gépen tanít be egy modellt, mindenképpen használjon olyan számítási termékváltozatot, amely támogatja az InfiniBandet a legjobb eredmények érdekében. Az AutoML-feladat tulajdonságának beállításával node_count_per_trial konfigurálhatja az egyetlen modell betanításához használt virtuális gépek számát.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
properties:
node_count_per_trial: "2"
Képfájlok streamelése a tárolóból
Alapértelmezés szerint a rendszer minden képfájlt letölt a lemezre a modell betanítása előtt. Ha a lemezképfájlok mérete nagyobb a rendelkezésre álló lemezterületnél, a feladat meghiúsul. Ahelyett, hogy az összes lemezképet letölti a lemezre, kiválaszthatja, hogy a betanítás során szükség szerint streamelje a képfájlokat az Azure Storage-ból. A rendszerképfájlokat a rendszer közvetlenül az Azure Storage-ból a rendszermemóriára streameli, megkerülve a lemezt. Ugyanakkor a tárolóból a lehető legtöbb fájl gyorsítótárazva lesz a lemezen, így minimalizálható a tárterületre irányuló kérések száma.
Megjegyzés:
Ha a streamelés engedélyezve van, győződjön meg arról, hogy az Azure Storage-fiók ugyanabban a régióban található, mint a számítás, a költségek és a késés minimalizálása érdekében.
ÉRVÉNYES:Azure CLI ml-bővítmény 2-es verzió (aktuális)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Példajegyzetfüzetek
Tekintse át a részletes kódmintákat és használati eseteket az automatizált gépi tanulási minták GitHub-jegyzetfüzettárában. Ellenőrizze a mappákban az "automl-image-" előtagot a számítógépes látásmodellek készítésére vonatkozó mintákhoz.
Kódpéldák
Tekintse át a részletes kódpéldákat és használati eseteket az azureml-examples adattárban automatizált gépi tanulási mintákhoz.