Automatizált gépi tanulási kísérlet eredményeinek kiértékelése
Ebből a cikkből megtudhatja, hogyan értékelheti ki és hasonlíthatja össze az automatizált gépi tanulási (automatizált gépi tanulási) kísérlet által betanított modelleket. Egy automatizált gépi tanulási kísérlet során számos feladat jön létre, és mindegyik feladat létrehoz egy modellt. Az automatizált gépi tanulás mindegyik modellhez olyan értékelési metrikákat és diagramokat hoz létre, amelyek segítenek a modell teljesítményének mérésében. Emellett létrehozhat egy felelős AI-irányítópultot, amely alapértelmezés szerint holisztikus értékelést és hibakeresést végez az ajánlott legjobb modellről. Ilyenek például a modellmagyarázatok, a méltányosság és a teljesítménykezelő, az adatkezelő, a modellhibák elemzése. További információ arról, hogyan hozhat létre felelős AI-irányítópultot.
Az automatizált gépi tanulás például a következő diagramokat hozza létre a kísérlet típusa alapján.
Fontos
A cikkben megjelölt (előzetes verziójú) elemek jelenleg nyilvános előzetes verzióban érhetők el. Az előzetes verzió szolgáltatásszint-szerződés nélkül érhető el, és éles számítási feladatokhoz nem ajánlott. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Előfeltételek
- Azure-előfizetés. (Ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt hozzon létre egy ingyenes fiókot )
- Egy Azure Machine-Tanulás kísérlet a következőkkel:
- Az Azure Machine Tanulás studio (nincs szükség kódra)
- Az Azure Machine Tanulás Python SDK
Feladat eredményeinek megtekintése
Az automatizált gépi tanulási kísérlet befejezése után a feladatok előzményei a következő címen találhatók:
- Böngésző az Azure Machine Tanulás Studióval
- Jupyter-jegyzetfüzet a JobDetails Jupyter widget használatával
Az alábbi lépések és videó bemutatja, hogyan tekintheti meg a futtatási előzményeket és a modell kiértékelési metrikáit és diagramjait a stúdióban:
- Jelentkezzen be a stúdióba , és lépjen a munkaterületre.
- A bal oldali menüben válassza a Feladatok lehetőséget.
- Válassza ki a kísérletet a kísérletek listájából.
- A lap alján található táblázatban válasszon ki egy automatizált gépi tanulási feladatot.
- A Modellek lapon válassza ki a kiértékelni kívánt modell algoritmusnevét.
- A Metrikák lapon a bal oldali jelölőnégyzetekkel tekintheti meg a metrikákat és diagramokat.
Besorolási metrikák
Az automatizált gépi tanulás kiszámítja a kísérlethez létrehozott egyes besorolási modellek teljesítménymetrikáit. Ezek a metrikák a scikit learn implementációján alapulnak.
Számos besorolási metrika definiálva van két osztály bináris besorolásához, és az osztályok átlagolását követeli meg, hogy egy pontszámot állítsunk elő a többosztályos besoroláshoz. A Scikit-learn számos átlagolási módszert kínál, amelyek közül három automatizált gépi tanulást tesz elérhetővé: makrót, mikrot és súlyozottat.
- Makró – Az egyes osztályok metrikáinak kiszámítása és a nem súlyozott átlag figyelembevétele
- Mikro – A metrikát globálisan számítja ki az összes valódi pozitív, hamis negatív és hamis pozitív érték számlálásával (osztályoktól függetlenül).
- Súlyozott – Számítsa ki az egyes osztályok metrikáit, és vegye figyelembe a súlyozott átlagot az osztályonkénti minták száma alapján.
Bár minden átlagolási módszernek megvannak az előnyei, a megfelelő módszer kiválasztásakor gyakori szempont az osztályegyensúlytalanság. Ha az osztályok különböző számú mintával rendelkeznek, akkor hasznosabb lehet egy olyan makróátlag használata, amelyben a kisebbségi osztályok egyenlő súlyozást kapnak a többségi osztályokhoz. További információ a bináris és a többosztályos metrikákról az automatizált gépi tanulásban.
Az alábbi táblázat összefoglalja azokat a modellteljesítmény-metrikákat, amelyeket az automatizált gépi tanulás kiszámít a kísérlethez létrehozott egyes besorolási modellekhez. További részletekért tekintse meg az egyes metrikák Számítás mezőjében hivatkozott scikit-learn dokumentációt.
Megjegyzés:
A képbesorolási modellek metrikáival kapcsolatos további részletekért tekintse meg a képmetrikák szakaszt.
| Metrika | Leírás | Számítás |
|---|---|---|
| AUC | Az AUC a vevő működési jellemző görbéje alatti terület. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] A támogatott metrikák nevei a következők: AUC_macroosztályonként az AUC számtani középértéke.AUC_micro, kiszámítja a valódi pozitívok, a hamis negatívok és a hamis pozitívok számlálásával. AUC_weightedaz egyes osztályok pontszámának számtani középértéke, az egyes osztályok valódi példányainak számával súlyozott átlaga. AUC_binaryaz AUC értéke egy adott osztály osztályként true való kezelésével és az összes többi osztály osztályként való false kombinálásával. |
Számítás |
| accuracy | A pontosság az előrejelzések aránya, amely pontosan megfelel a valódi osztálycímkéknek. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] |
Számítás |
| average_precision | Az átlagos pontosság az egyes küszöbértékeken elért pontosságok súlyozott középértékeként összegzi a pontosságvisszahívási görbét, és a visszahívás az előző küszöbértékből való visszahívást használja súlyként. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] A támogatott metrikák nevei a következők: average_precision_score_macroaz egyes osztályok átlagos pontossági pontszámának számtani középértéke.average_precision_score_micro, kiszámítja a valódi pozitívok, a hamis negatívok és a hamis pozitívok számlálásával.average_precision_score_weightedaz egyes osztályok átlagos pontossági pontszámának számtani középértéke, az egyes osztályok valódi példányainak számával súlyozott átlaga. average_precision_score_binary, az átlagos pontosság értéke egy adott osztály osztályként true való kezelésével és az összes többi osztály osztályként való false kombinálásával. |
Számítás |
| balanced_accuracy | A kiegyensúlyozott pontosság az egyes osztályok visszahívásának számtani középértéke. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] |
Számítás |
| f1_score | Az F1 pontszám a pontosság és a visszahívás harmonikus középértékét jelenti. Ez a hamis pozitív és a hamis negatív értékek jó kiegyensúlyozott mértéke. Azonban nem veszi figyelembe a valódi negatív értékeket. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] A támogatott metrikák nevei a következők: f1_score_macro: az egyes osztályok F1 pontszámának számtani középértéke. f1_score_micro: a valódi pozitívok, a hamis negatívok és a hamis pozitívok számlálásával számítható ki. f1_score_weighted: az egyes osztályok F1 pontszámának osztályonkénti gyakorisága szerint súlyozott. f1_score_binary, az f1 értéke egy adott osztály osztályként true való kezelésével és az összes többi osztály osztályként való false kombinálásával. |
Számítás |
| log_loss | Ez a (többnomiális) logisztikai regresszióban és annak kiterjesztéseiban, például neurális hálózatokban használt veszteségfüggvény, amely a valódi címkék negatív napló-valószínűségét határozza meg, figyelembe véve a valószínűségi osztályozó előrejelzéseit. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) |
Számítás |
| norm_macro_recall | A normalizált makróvisszahívás a makró átlagolt és normalizált visszahívása, így a véletlenszerű teljesítmény értéke 0, a tökéletes teljesítmény pedig 1-es pontszámmal rendelkezik. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] |
(recall_score_macro - R) / (1 - R) R ahol a véletlenszerű előrejelzések várható értékerecall_score_macro.R = 0.5 bináris besoroláshoz. R = (1 / C) C-osztály besorolási problémái esetén. |
| matthews_correlation | A Matthews korrelációs együttható a pontosság kiegyensúlyozott mértéke, amely akkor is használható, ha az egyik osztály több mintával rendelkezik, mint egy másik. Az 1-ből álló együttható tökéletes előrejelzést, 0 véletlenszerű előrejelzést és -1 inverz előrejelzést jelez. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [-1, 1] |
Számítás |
| pontosság | A pontosság a modell azon képessége, hogy elkerülje a negatív minták pozitívként való címkézését. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] A támogatott metrikák nevei a következők: precision_score_macroosztályonként a pontosság számtani középértéke. precision_score_micro, globálisan kiszámítva a teljes valódi pozitív és hamis pozitív érték megszámlálásával. precision_score_weighted, az egyes osztályok pontosságának számtani középértéke, az egyes osztályok valódi példányainak számával súlyozottan. precision_score_binary, a pontosság értéke egy adott osztály osztályként true való kezelésével és az összes többi osztály osztályként való false kombinálásával. |
Számítás |
| felidézés | A visszahívás a modell azon képessége, hogy az összes pozitív mintát észlelje. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] A támogatott metrikák nevei a következők: recall_score_macro: az egyes osztályok visszahívásának aritmetikai középértéke. recall_score_micro: globálisan kiszámítva a teljes valódi pozitív, hamis negatív és hamis pozitív értékek megszámlálásával.recall_score_weighted: az egyes osztályok visszahívásának aritmetikai középértéke, az egyes osztályok valódi példányainak számával súlyozottan. recall_score_binary, a visszahívás értékét úgy, hogy egy adott osztályt osztályként true kezel, és az összes többi osztályt osztályként false egyesíti. |
Számítás |
| weighted_accuracy | A súlyozott pontosság olyan pontosság, amelyben az egyes mintákat az ugyanahhoz az osztályhoz tartozó minták teljes számával súlyozza. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [0, 1] |
Számítás |
Bináris és többosztályos besorolási metrikák
Az automatizált gépi tanulás automatikusan észleli, hogy az adatok binárisak-e, és lehetővé teszi a felhasználók számára a bináris besorolási metrikák aktiválását akkor is, ha az adatok többosztályosak egy true osztály megadásával. Többosztályos besorolási metrikák akkor jelennek meg, ha egy adathalmaz két vagy több osztálysal rendelkezik. A bináris besorolási metrikák csak akkor jelennek meg, ha az adatok binárisak.
Vegye figyelembe, hogy a többosztályos besorolási metrikák többosztályos besorolásra szolgálnak. Bináris adatkészletre alkalmazva ezek a metrikák nem osztályként kezelik az true osztályt, ahogy várható volt. A egyértelműen többosztályos metrikák utótagja microaz , macrovagy weighted. Ilyenek például a average_precision_scorekövetkezők: , f1_score, precision_score, recall_scoreés AUC. A visszahívás kiszámítása helyett például a többosztályos átlagolt visszahívás tp / (tp + fn)(micromacrovagy weighted) egy bináris besorolási adatkészlet mindkét osztályára átlagol. Ez egyenértékű az osztály és false az true osztály visszahívásának külön kiszámításával, majd a kettő átlagának figyelembevételével.
Emellett, bár a bináris besorolás automatikus észlelése támogatott, továbbra is javasoljuk, hogy mindig manuálisan adja meg az true osztályt, hogy a bináris besorolási metrikákat a megfelelő osztályhoz számítsa ki.
A bináris besorolású adathalmazok metrikáinak aktiválásához, ha maga az adathalmaz többosztályos, a felhasználóknak csak az osztályként true kezelendő osztályt kell megadniuk, és a rendszer kiszámítja ezeket a metrikákat.
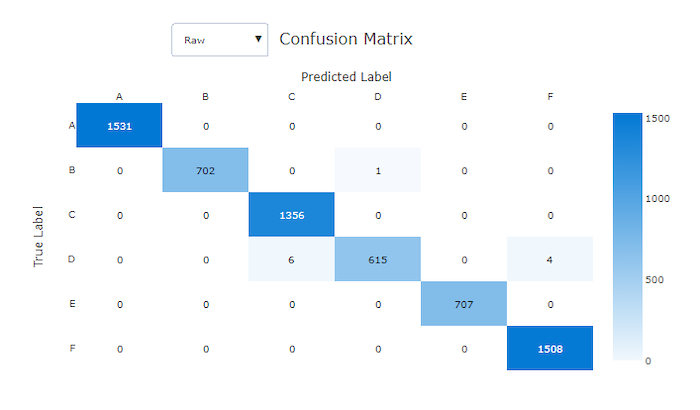
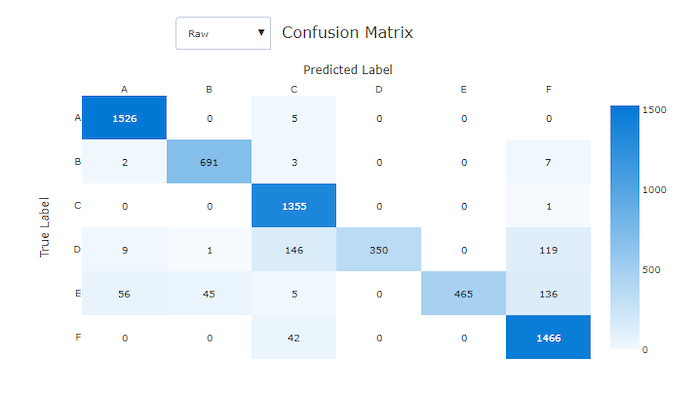
Keveredési mátrix
A keveredési mátrixok vizuálisan szemléltetik, hogy egy gépi tanulási modell hogyan végez szisztematikus hibákat a besorolási modellekre vonatkozó előrejelzéseiben. A névben szereplő "zavart" szó egy modell "zavaró" vagy helytelen címkével rendelkező mintáiból származik. A keveredési mátrix sorában i és oszlopában j lévő cella a kiértékelési adathalmaz azon mintáinak számát tartalmazza, amelyek osztályhoz C_i tartoznak, és a modell osztályként C_jvan besorolva.
A stúdióban a sötétebb cella nagyobb számú mintát jelez. A normalizált nézet kiválasztása a legördülő listában minden mátrixsoron normalizálódik, hogy az osztályként C_jelőrejelzett százalékos C_i érték jelenjen meg. Az alapértelmezett Nyers nézet előnye, hogy láthatja, hogy a tényleges osztályok eloszlásának egyensúlyhiánya miatt a modell helytelenül sorolta-e be a mintákat a kisebbségi osztályból, ami az egyensúlyhiányos adathalmazok gyakori problémája.
A jó modell keveredési mátrixa a legtöbb mintát az átló mentén tartalmazza.
Keveredési mátrix egy jó modellhez
Hibás modell keveredési mátrixa
ROC-görbe
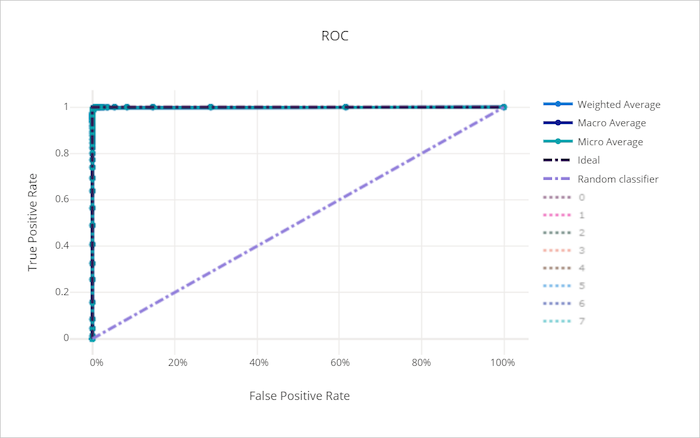
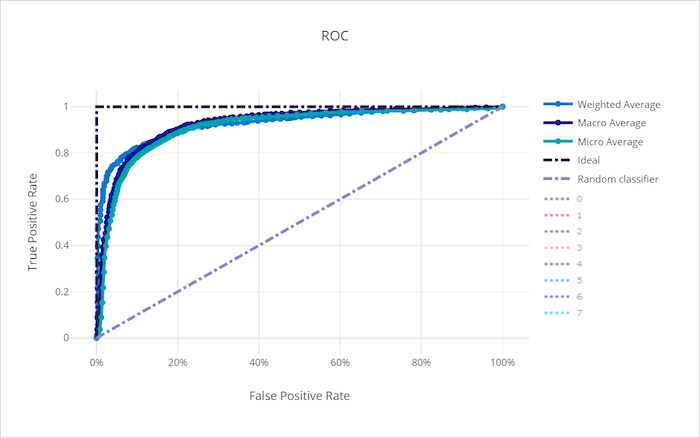
A fogadó működési jellemzője (ROC) görbéje a döntési küszöbérték változásával ábrázolja a valódi pozitív ráta (TPR) és a hamis pozitív ráta (FPR) közötti kapcsolatot. A ROC-görbe kevésbé informatív lehet, ha magas osztályú egyensúlytalanságú adathalmazokra vonatkozó modelleket képez, mivel a többségi osztály elfojthatja a kisebbségi osztályokból származó hozzájárulásokat.
A görbe alatti terület (AUC) a helyesen besorolt minták arányaként értelmezhető. Pontosabban az AUC annak a valószínűsége, hogy az osztályozó egy véletlenszerűen kiválasztott pozitív mintát rangsorol magasabbra, mint egy véletlenszerűen kiválasztott negatív minta. A görbe alakja intuíciót ad a TPR és az FPR közötti kapcsolathoz a besorolási küszöbérték vagy a döntési határ függvényeként.
A diagram bal felső sarkához közelítő görbe egy 100%-os TPR-t és 0%-os FPR-t, a lehető legjobb modellt közelíti meg. A véletlenszerű modell a bal alsó saroktól a jobb felső sarokig egy ROC-görbét hoz létre a vonal mentén y = x . A véletlenszerű modellnél rosszabb roC-görbével rendelkezik, amely a y = x vonal alá süllyed.
Tipp.
Besorolási kísérletek esetén az automatizált gépi tanulási modellekhez létrehozott vonaldiagramok felhasználhatók a modell osztályonkénti kiértékelésére vagy az összes osztály átlagolására. A különböző nézetek között a diagram jobb oldalán található jelmagyarázat osztálycímkéire kattintva válthat.
ROC-görbe egy jó modellhez
ROC-görbe egy rossz modellhez
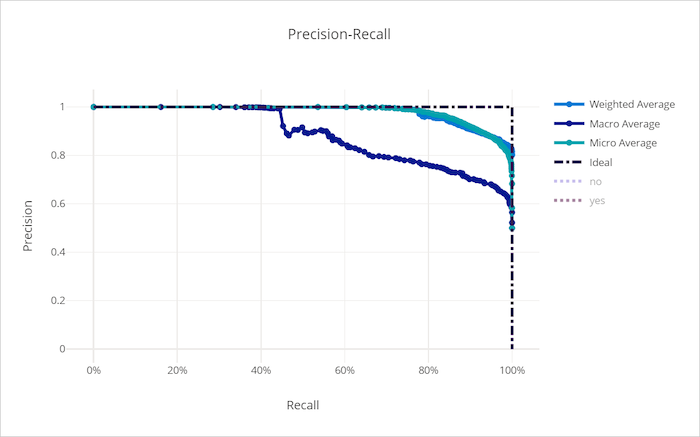
Pontossági visszahívási görbe
A pontosság-visszahívási görbe a döntési küszöbérték változásával ábrázolja a pontosság és a visszahívás közötti kapcsolatot. A visszahívás a modell azon képessége, hogy az összes pozitív mintát észlelje, a pontosság pedig az, hogy a modell képes elkerülni a negatív minták pozitívként való címkézését. Egyes üzleti problémák nagyobb visszahívást és nagyobb pontosságot igényelhetnek attól függően, hogy mennyire fontos elkerülni a hamis negatívokat és a hamis pozitívokat.
Tipp.
Besorolási kísérletek esetén az automatizált gépi tanulási modellekhez létrehozott vonaldiagramok felhasználhatók a modell osztályonkénti kiértékelésére vagy az összes osztály átlagolására. A különböző nézetek között a diagram jobb oldalán található jelmagyarázat osztálycímkéire kattintva válthat.
Pontosság-visszahívási görbe egy jó modellhez
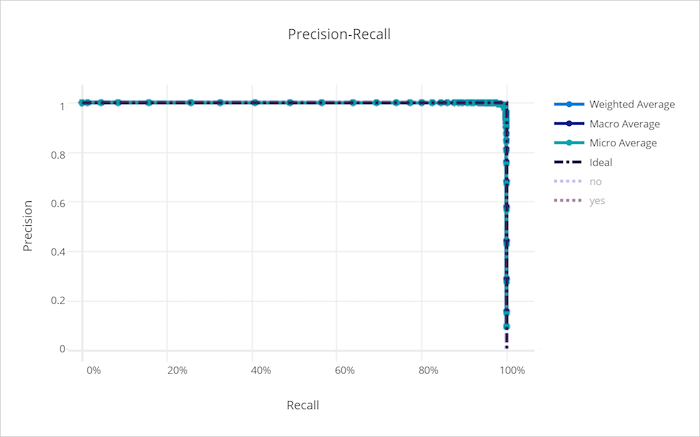
Pontosság-visszahívási görbe rossz modell esetén
Halmozott nyereségek görbéje
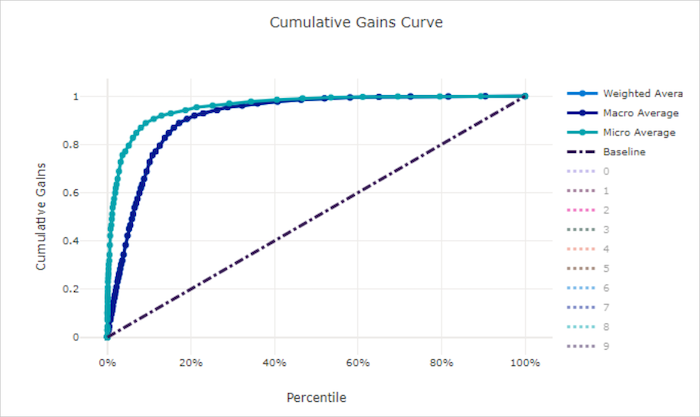
Az összesített nyereséggörbe a pozitív minták százalékos arányát ábrázolja helyesen a vizsgált minták százalékos arányának függvényeként, ahol a mintákat az előrejelzett valószínűség szerinti sorrendben vesszük figyelembe.
A nyereség kiszámításához először rendezze az összes mintát a modell által előrejelzett legnagyobbtól a legkisebb valószínűségig. Ezután vegye figyelembe x% a legmagasabb megbízhatósági előrejelzéseket. Ossza el az ebben észlelt x% pozitív minták számát a pozitív minták teljes számával a nyereség eléréséhez. Az összesített nyereség a pozitív minták százalékos aránya, amelyet akkor észlelünk, ha figyelembe vesszük az adatok egy százalékát, amely valószínűleg a pozitív osztályhoz tartozik.
A tökéletes modell az összes pozitív mintát rangsorolja az összes negatív minta fölé, amely két egyenes szegmensből álló összesített nyereséggörbét eredményez. Az első egy egyenes meredekséggel 1 / x , ahol (0, 0)(x, 1)x a pozitív osztályhoz tartozó minták aránya (1 / num_classes ha az osztályok kiegyensúlyozottak). A második egy vízszintes vonal a kezdőtől a (x, 1) másikig (1, 1). Az első szegmensben az összes pozitív minta megfelelően van besorolva, és a halmozott nyereség az első x% figyelembe vett mintán belülre kerül100%.
Az alapkonfigurációs véletlenszerű modell egy összegző nyereséggörbét fog tartalmazni, amely azt követi y = x , hogy a vizsgált minták esetében x% csak a teljes pozitív minták közül volt x% észlelhető. A kiegyensúlyozott adathalmazok tökéletes modellje mikroátlagos görbével és egy olyan makróátlagvonallal rendelkezik, amelynek meredeksége num_classes 100%-os, majd vízszintes, amíg az adatszázad 100 nem lesz.
Tipp.
Besorolási kísérletek esetén az automatizált gépi tanulási modellekhez létrehozott vonaldiagramok felhasználhatók a modell osztályonkénti kiértékelésére vagy az összes osztály átlagolására. A különböző nézetek között a diagram jobb oldalán található jelmagyarázat osztálycímkéire kattintva válthat.
Egy jó modell összesített nyereséggörbeje
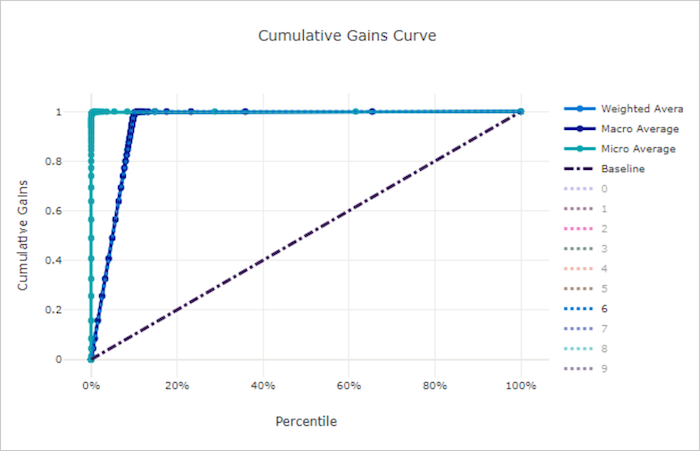
Halmozott nyereséggörbe rossz modell esetén
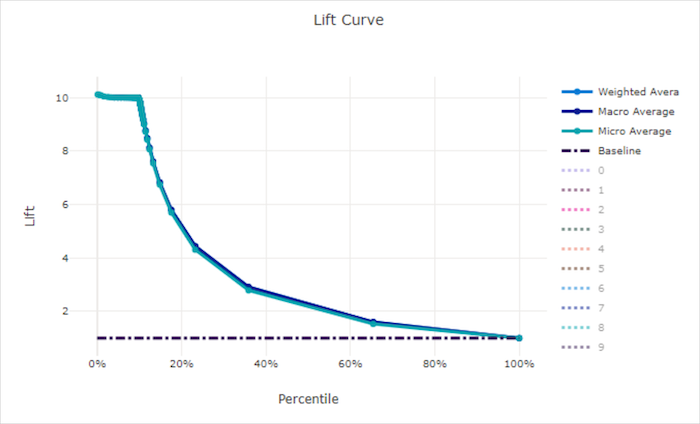
Emelkedő görbe
Az emelési görbe azt mutatja, hogy egy modell hányszor teljesít jobban egy véletlenszerű modellhez képest. Az emelés az összesített nyereség és a véletlenszerű modell összesített nyereségének aránya (amelynek mindig meg kell lennie 1).
Ez a relatív teljesítmény figyelembe veszi azt a tényt, hogy a besorolás nehezebbé válik az osztályok számának növelése során. (A véletlenszerű modell helytelenül előrejelzi a minták nagyobb részét egy 10 osztályt tartalmazó adatkészletből, mint egy kétosztályos adathalmaz)
Az alapkonfigurációs emelési görbe az a y = 1 vonal, ahol a modell teljesítménye összhangban van egy véletlenszerű modell teljesítményével. Általánosságban elmondható, hogy a jó modell emelési görbéje magasabb lesz ezen a diagramon, és messzebb lesz az x tengelytől, ami azt mutatja, hogy amikor a modell a legbizalmasabb az előrejelzéseiben, sokszor jobban teljesít, mint a véletlenszerű találgatás.
Tipp.
Besorolási kísérletek esetén az automatizált gépi tanulási modellekhez létrehozott vonaldiagramok felhasználhatók a modell osztályonkénti kiértékelésére vagy az összes osztály átlagolására. A különböző nézetek között a diagram jobb oldalán található jelmagyarázat osztálycímkéire kattintva válthat.
Görbe emelése egy jó modellhez
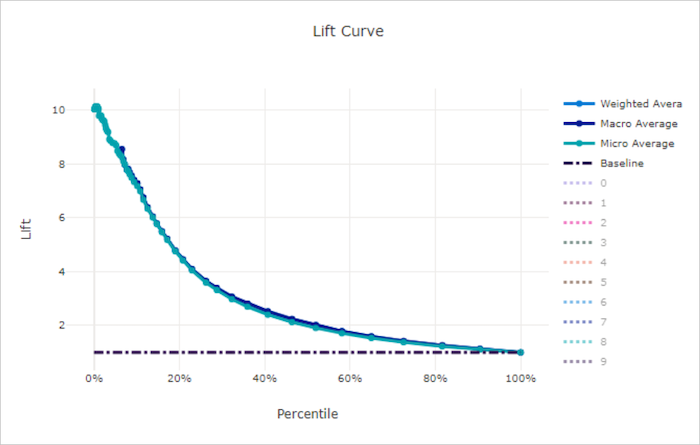
Görbe emelése rossz modell esetén
Kalibrálási görbe
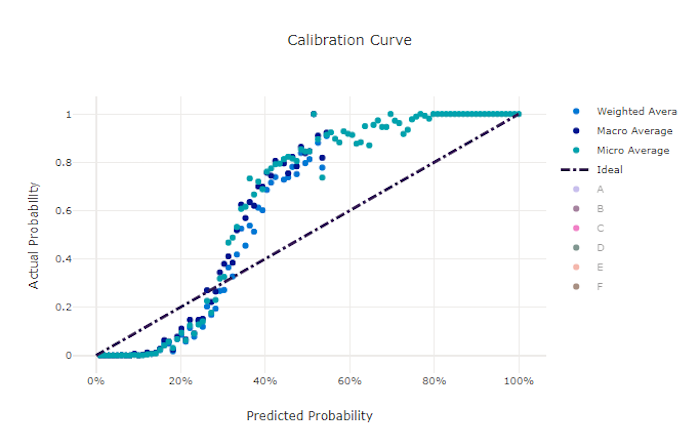
A kalibrációs görbe az egyes megbízhatósági szintek pozitív mintáinak arányával ábrázolja a modell előrejelzéseibe vetett bizalmát. A jól kalibrált modell megfelelően osztályozza az előrejelzések 100%-át, amelyhez 100%-os megbízhatóságot rendel, az általa hozzárendelt előrejelzések 50%-a pedig 50%-os megbízhatóságot, 20%-át pedig 20%-os megbízhatóságot. A tökéletesen kalibrált modellnek egy olyan kalibrációs görbéje lesz, amely azt a y = x vonalat követi, ahol a modell tökéletesen előrejelzi annak valószínűségét, hogy a minták az egyes osztályokhoz tartoznak.
A túl magabiztos modell a nullához közeli és egy közeli valószínűségeket fogja előrejelezni, ritkán bizonytalan az egyes minták osztályával kapcsolatban, és a kalibrációs görbe az "S" visszafelé néz ki. Az alulbiztos modell átlagosan kisebb valószínűséggel rendeli hozzá az előrejelzett osztályt, és a kapcsolódó kalibrációs görbe az "S" típushoz hasonlóan fog kinézni. A kalibrációs görbe nem azt ábrázolja, hogy a modell képes-e helyesen besorolni, hanem azt, hogy helyesen rendeli hozzá a megbízhatóságot az előrejelzéseihez. A rossz modell akkor is jó kalibrációs görbével rendelkezhet, ha a modell megfelelően rendeli hozzá az alacsony megbízhatóságot és a nagy bizonytalanságot.
Megjegyzés:
A kalibrációs görbe érzékeny a minták számára, így egy kis érvényesítési készlet zajos eredményeket hozhat, amelyeket nehéz értelmezni. Ez nem feltétlenül jelenti azt, hogy a modell nincs megfelelően kalibrálva.
Kalibrációs görbe egy jó modellhez
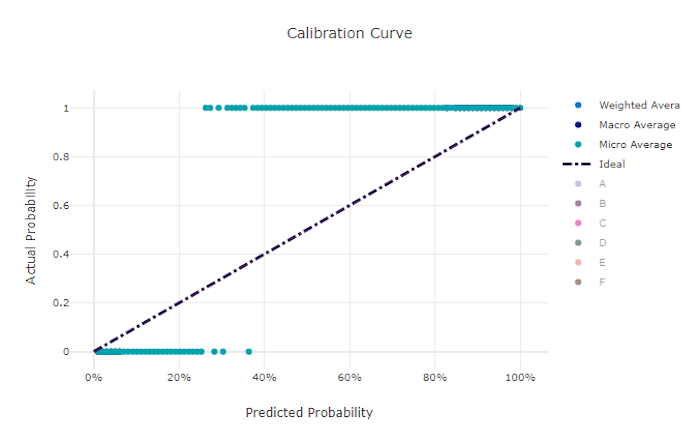
Nem megfelelő modell kalibrációs görbéje
Regressziós/előrejelzési metrikák
Az automatizált gépi tanulás ugyanazokat a teljesítménymetrikákat számítja ki minden létrehozott modell esetében, függetlenül attól, hogy regressziós vagy előrejelzési kísérletről van-e szó. Ezek a metrikák normalizáláson is átesnek, hogy lehetővé tegyék a különböző tartományokkal betanított adatokon betanított modellek összehasonlítását. További információ: metrikák normalizálása.
Az alábbi táblázat a regressziós és előrejelzési kísérletekhez létrehozott modellteljesítmény-metrikákat foglalja össze. A besorolási metrikákhoz hasonlóan ezek a metrikák is a scikit Learn implementációin alapulnak. A megfelelő scikit learn-dokumentáció ennek megfelelően van csatolva a Számítás mezőben.
| Metrika | Leírás | Számítás |
|---|---|---|
| explained_variance | A magyarázott variancia azt méri, hogy a modell milyen mértékben adja meg a célváltozó variációját. Az eredeti adatok varianciájának százalékos csökkenése a hibák varianciájával. Ha a hibák középértéke 0, akkor az egyenlő a meghatározási együtthatóval (lásd az alábbi r2_score). Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: (-inf, 1] |
Számítás |
| mean_absolute_error | A középérték abszolút hiba a cél és az előrejelzés közötti abszolút különbség várható értéke. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) Típusok: mean_absolute_error normalized_mean_absolute_errormean_absolute_error osztva az adatok tartományával. |
Számítás |
| mean_absolute_percentage_error | Az átlagos abszolút százalékos hiba (MAPE) az előrejelzett érték és a tényleges érték közötti átlagos különbség mértéke. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) |
|
| median_absolute_error | A medián abszolút hiba a cél és az előrejelzés közötti abszolút különbségek mediánja. Ez a veszteség robusztus a kiugró értékek számára. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) Típusok: median_absolute_errornormalized_median_absolute_error: a median_absolute_error osztva az adatok tartományával. |
Számítás |
| r2_score | Az R2 (a meghatározási együttható) a megfigyelt adatok teljes varianciájával arányos négyzetes hiba (M Standard kiadás) arányos csökkenését méri. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [-1, 1] Megjegyzés: Az R2 tartománya gyakran (-inf, 1). Az M Standard kiadás nagyobb lehet, mint a megfigyelt variancia, így az R2 tetszőlegesen nagy negatív értékekkel rendelkezhet az adatoktól és a modell előrejelzéseitől függően. Az automatizált ml-klipek R 2 pontszámot jelentettek-1 értéken, így az R2 esetében a -1 érték valószínűleg azt jelenti, hogy a valódi R2 pontszám kisebb, mint -1. A negatív R2 pontszám értelmezésekor vegye figyelembe a többi metrikaértéket és az adatok tulajdonságait. |
Számítás |
| root_mean_squared_error | A fő középérték négyzetes hiba (RM Standard kiadás) a cél és az előrejelzés közötti várható négyzetes különbség négyzetgyöke. Elfogulatlan becslés esetén az RM Standard kiadás a szórásnak felel meg. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) Típusok: root_mean_squared_error normalized_root_mean_squared_error: a root_mean_squared_error osztva az adatok tartományával. |
Számítás |
| root_mean_squared_log_error | A középérték négyzetes naplóhiba a várt négyzetes logaritmikus hiba négyzetgyöke. Célkitűzés: Közelebb a 0-hoz a jobb Tartomány: [0, inf) Típusok: root_mean_squared_log_error normalized_root_mean_squared_log_error: a root_mean_squared_log_error az adatok tartományával osztva. |
Számítás |
| spearman_correlation | A Spearman-korreláció a két adathalmaz közötti kapcsolat monotonitásának nemparametrikus mértéke. A Pearson-korrelációval ellentétben a Spearman-korreláció nem feltételezi, hogy mindkét adathalmaz általában elosztott. A többi korrelációs együtthatóhoz hasonlóan a Spearman -1 és 1 között változik, a 0 pedig nem utal korrelációra. A -1 vagy az 1 korrelációja pontosan monoton kapcsolatot jelent. A Spearman egy rangsor-sorrend korrelációs metrika, amely azt jelenti, hogy az előrejelzett vagy tényleges értékek változásai nem módosítják a Spearman-eredményt, ha nem módosítják az előrejelzett vagy tényleges értékek rangsorrendjét. Célkitűzés: Közelebb az 1-hez, annál jobb Tartomány: [-1, 1] |
Számítás |
Metrika normalizálása
Az automatizált gépi tanulás normalizálja a regressziós és előrejelzési metrikákat, amelyek lehetővé teszik a különböző tartományokkal betanított adatokon betanított modellek összehasonlítását. A nagyobb tartományú adatokra betanított modell nagyobb hibával rendelkezik, mint a kisebb tartományú adatokra betanított modell, kivéve, ha ez a hiba normalizálva van.
Bár a hibametrikák normalizálására nincs szabványos módszer, az automatizált gépi tanulás az adatok tartományával való osztás gyakori módszere: normalized_error = error / (y_max - y_min)
Megjegyzés:
A rendszer nem menti az adattartományt a modellel. Ha ugyanazt a modellt használja egy visszatartott tesztkészleten, és y_max a tesztadatok alapján változhat, y_min és a normalizált metrikák nem használhatók közvetlenül a modell betanítási és tesztkészleteken végzett teljesítményének összehasonlítására. A betanítási y_min készlet értékét és y_max értékét átadva igazságossá teheti az összehasonlítást.
Előrejelzési metrikák: normalizálás és összesítés
Az előrejelzési modell kiértékeléséhez használt metrikák kiszámítása különleges szempontokat igényel, ha az adatok több idősort tartalmaznak. A metrikák több adatsorhoz való összesítéséhez két természetes lehetőség közül választhat:
- Egy makróátlag, amelyben az egyes sorozatok kiértékelési metrikái egyenlő súlyt kapnak,
- Egy mikroátlag , amelyben az egyes előrejelzések kiértékelési metrikái azonos súlyúak.
Ezek az esetek közvetlen analógiával rendelkeznek a makró- és mikroszintű átlagoláshoz többosztályos besorolásban.
A makró és a mikro átlagolás különbsége fontos lehet a modell kiválasztásához szükséges elsődleges metrikák kiválasztásakor. Vegyük például azt a kiskereskedelmi forgatókönyvet, amelyben a fogyasztói termékek egy kiválasztott termékére vonatkozó keresletet szeretnénk előrejelzni. Egyes termékek sokkal nagyobb mennyiségben értékesítenek, mint mások. Ha elsődleges metrikaként egy mikroátlagos RM-t választ Standard kiadás lehetséges, hogy a nagy mennyiségű elemek a modellezési hiba többségéhez járulnak hozzá, és ennek következtében uralják a metrikát. A modellkijelölési algoritmus ezután nagyobb pontosságú modelleket részesíthet előnyben a nagy kötetű elemeken, mint az alacsony kötetű modelleken. Ezzel szemben a makró átlagolt, normalizált RM Standard kiadás a nagy kötetű elemek súlyának körülbelül azonos súlyt ad.
Az alábbi táblázat azt mutatja be, hogy az AutoML előrejelzési metrikái közül melyik használ makrót és mikro átlagolást:
| Makró átlagolt | Mikroátlagos |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Vegye figyelembe, hogy a makróval átlagolt metrikák külön normalizálják az egyes adatsorokat. Ezután az egyes sorozatok normalizált metrikáit átlagoltuk a végeredmény érdekében. A makró és a mikro megfelelő kiválasztása az üzleti forgatókönyvtől függ, de általában a használatát normalized_root_mean_squared_errorjavasoljuk.
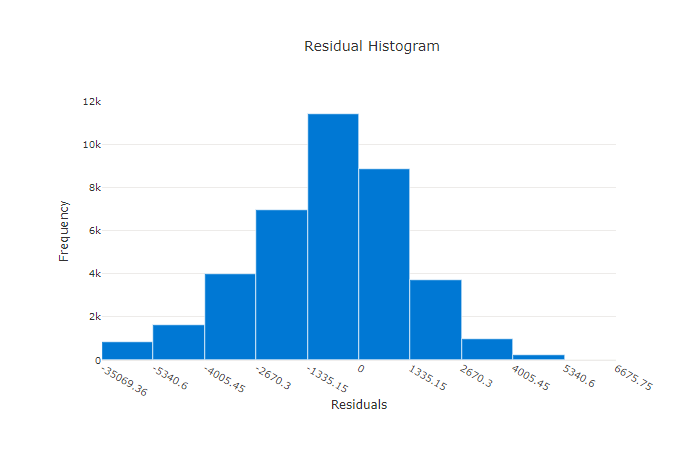
Reziduálisok
A reziduális diagram a regressziós és előrejelzési kísérletekhez létrehozott előrejelzési hibák (reziduálisok) hisztogramja. A reziduálisok kiszámítása az összes mintához hasonlóan y_predicted - y_true történik, majd hisztogramként jelenik meg a modell torzításainak megjelenítéséhez.
Ebben a példában vegye figyelembe, hogy mindkét modell kissé elfogult a tényleges értéknél alacsonyabb előrejelzéshez. Ez nem ritka olyan adathalmazok esetében, amikor a tényleges célok eloszlása ferde, de rosszabb modellteljesítményt jelez. Egy jó modell reziduális eloszlással rendelkezik, amely nullára csúcsosul, és a végletek között kevés reziduális lesz. Egy rosszabb modellben a maradékok eloszlása nulla körül kevesebb mintával lesz elosztva.
Jó modell reziduális diagramja
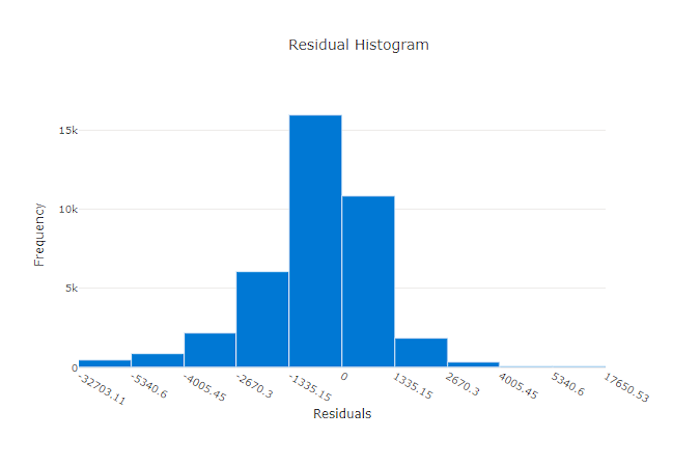
Hibás modell reziduális diagramja
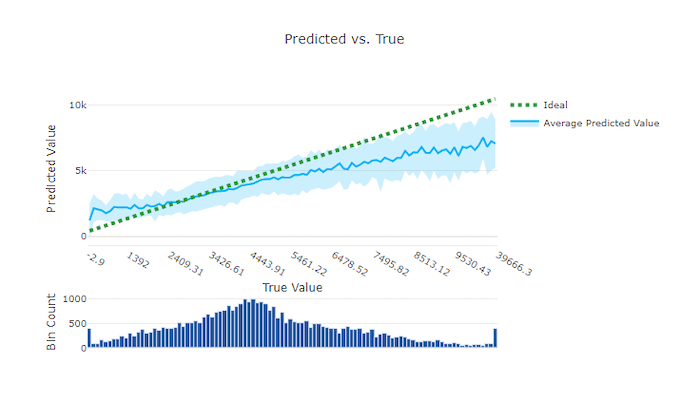
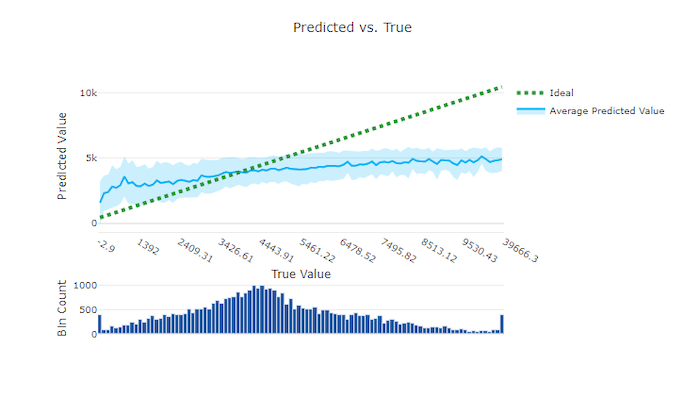
Előrejelzett és valós
A regressziós és előrejelzési kísérlethez az előrejelzett és az igaz diagram ábrázolja a célfunkció (igaz/tényleges értékek) és a modell előrejelzései közötti kapcsolatot. A valódi értékek az x tengely mentén vannak rögzítve, és minden egyes doboz esetében a várható középérték hibasávokkal van ábrázolva. Így megállapíthatja, hogy egy modell elfogult-e bizonyos értékek előrejelzéséhez. A vonal az átlagos előrejelzést jeleníti meg, az árnyékolt terület pedig az adott középérték körüli előrejelzések varianciáját jelzi.
A leggyakoribb igaz érték gyakran a legpontosabb előrejelzésekkel rendelkezik a legalacsonyabb varianciával. A trendvonal távolsága az ideális y = x vonaltól, ahol kevés igaz érték van, a modell teljesítményének jó mértéke a kiugró értékeken. A diagram alján található hisztogrammal megadhatja a tényleges adateloszlás okát. Ha több olyan adatmintát is tartalmaz, ahol a terjesztés ritka, javíthatja a modell teljesítményét a nem látott adatokon.
Ebben a példában vegye figyelembe, hogy a jobb modell előrejelzett és igaz vonallal rendelkezik, amely közelebb van az ideális y = x vonalhoz.
Jó modell előrejelzett és igaz diagramja
Rossz modell előrejelzett és igaz diagramja
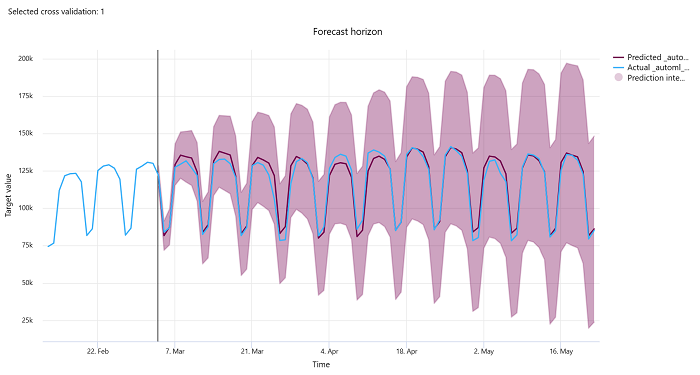
Előrejelzési horizont
Az előrejelzési kísérletekhez az előrejelzési horizontdiagram az előrejelzett modellek és a keresztérvényesítési hajtásonként idő szerint leképezett tényleges értékek közötti kapcsolatot ábrázolja, akár 5-szörösre is. Az x tengely az időt a betanítási beállítás során megadott gyakoriság alapján képezi le. A diagram függőleges vonala jelöli az előrejelzési horizontpontot, más néven horizontvonalat, amely az az időszak, amikor el szeretné kezdeni az előrejelzések előállítását. Az előrejelzési horizont vonalától balra megtekintheti a korábbi betanítási adatokat a korábbi trendek jobb megjelenítése érdekében. Az előrejelzési horizonttól jobbra a különböző keresztérvényesítési redők és idősor-azonosítók tényleges adatai (a kék vonal) alapján jelenítheti meg az előrejelzéseket (a lila vonalat). Az árnyékolt lila terület az adott középérték körüli előrejelzések megbízhatósági intervallumait vagy varianciáját jelzi.
A diagram jobb felső sarkában található ceruza szerkesztése ikonra kattintva kiválaszthatja, hogy mely keresztérvényesítési és idősor-azonosító kombinációk jelenjenek meg. Válassza ki az első 5 keresztérvényesítési hajtást és legfeljebb 20 különböző idősor-azonosítót a különböző idősorok diagramjának megjelenítéséhez.
Fontos
Ez a diagram elérhető a betanítási futtatásban a betanítási és érvényesítési adatokból, valamint a betanítási adatok és a tesztelési adatok alapján végzett tesztfuttatásban létrehozott modellekhez. Legfeljebb 20 adatpontot engedélyezünk az előrejelzés kezdete előtt és után legfeljebb 80 adatpontot. A DNN-modellek esetében ez a betanítási futtatásban szereplő diagram az utolsó korszak adatait jeleníti meg, azaz a modell teljes betanítása után. Ha a betanítási futtatás során explicit módon adták meg az érvényesítési adatokat, a tesztfuttatásban ez a diagram rést tartalmazhat a horizontvonal előtt. Ennek az az oka, hogy a betanítási adatok és a tesztadatok a teszt futása során kihagyják az érvényesítési adatokat, ami hézagot eredményez.
Képmodellek metrikái (előzetes verzió)
Az automatizált gépi tanulás az érvényesítési adathalmaz képeit használja a modell teljesítményének kiértékeléséhez. A modell teljesítményének mérése korszak szintjén történik, hogy megértse a betanítás előrehaladását. Egy korszak akkor lép ér véget, amikor egy teljes adatkészletet pontosan egyszer ad át előre és hátra a neurális hálózaton keresztül.
Képbesorolási metrikák
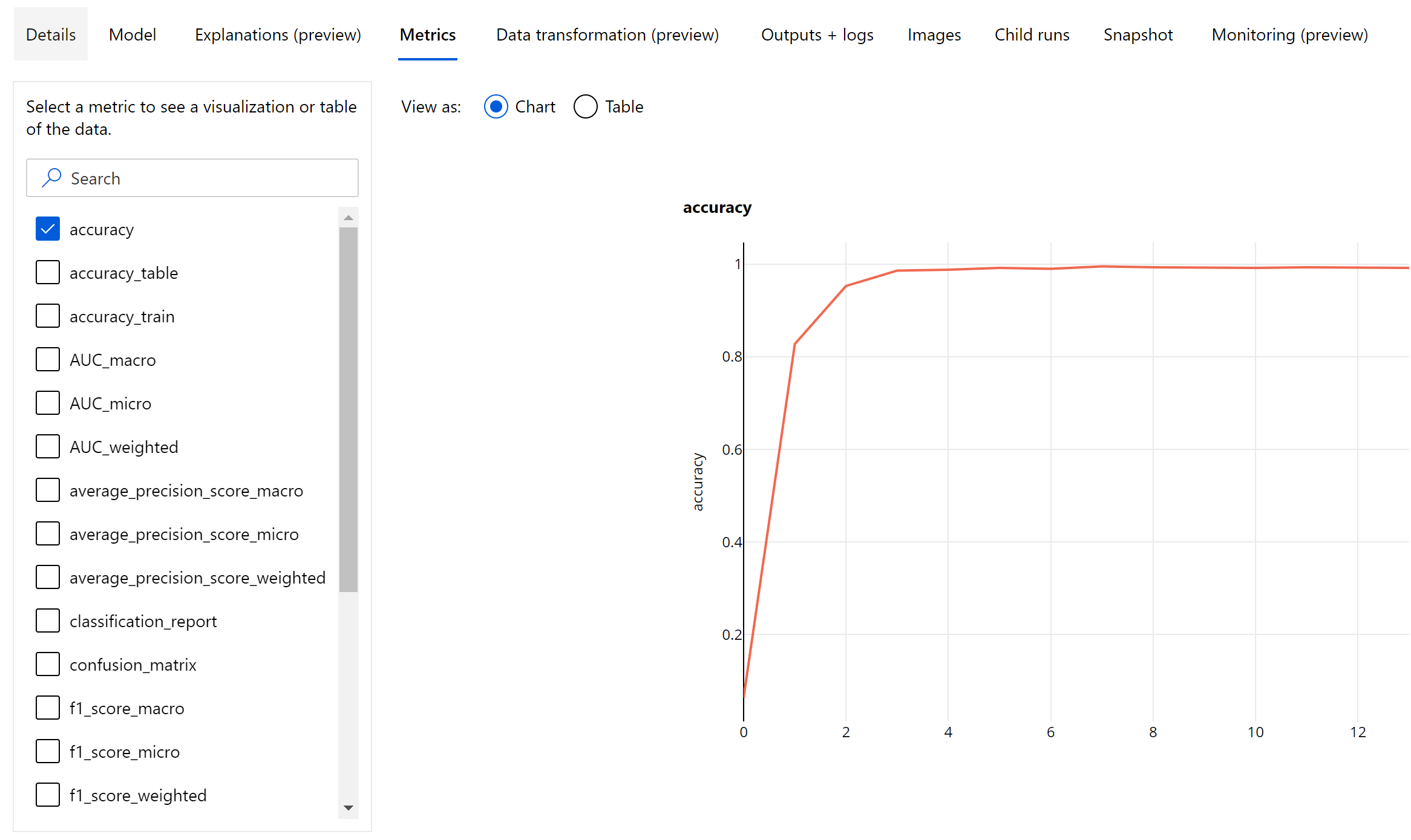
Az értékelés elsődleges metrikája a bináris és többosztályos besorolási modellek pontossága , a többcímkés besorolási modelleknél pedig az IoU (Metszet az unión keresztül) esetében. A képbesorolási modellek besorolási metrikái megegyeznek a besorolási metrikák szakaszban meghatározottakkal . A rendszer naplózza a korszakhoz társított veszteségértékeket is, amelyek segítenek monitorozni a betanítás előrehaladását, és megállapítani, hogy a modell túlillesztés vagy alulillesztés-e.
A besorolási modell minden előrejelzése megbízhatósági pontszámmal van társítva, amely azt a megbízhatósági szintet jelzi, amellyel az előrejelzés készült. A többcímkés képosztályozási modellek alapértelmezés szerint 0,5-ös pontszámküszöbgel vannak kiértékelve, ami azt jelenti, hogy csak az ilyen megbízhatósági szintű előrejelzések tekinthetők pozitív előrejelzésnek a társított osztály számára. A többosztályos besorolás nem használ pontszámküszöböt, hanem a maximális megbízhatósági pontszámmal rendelkező osztályt tekintjük előrejelzésnek.
Korszakszintű metrikák képbesoroláshoz
A táblázatos adathalmazok besorolási metrikáitól eltérően a képbesorolási modellek az összes besorolási metrikát egy korszak szintjén naplózják az alábbiak szerint.
Összefoglaló metrikák képbesoroláshoz
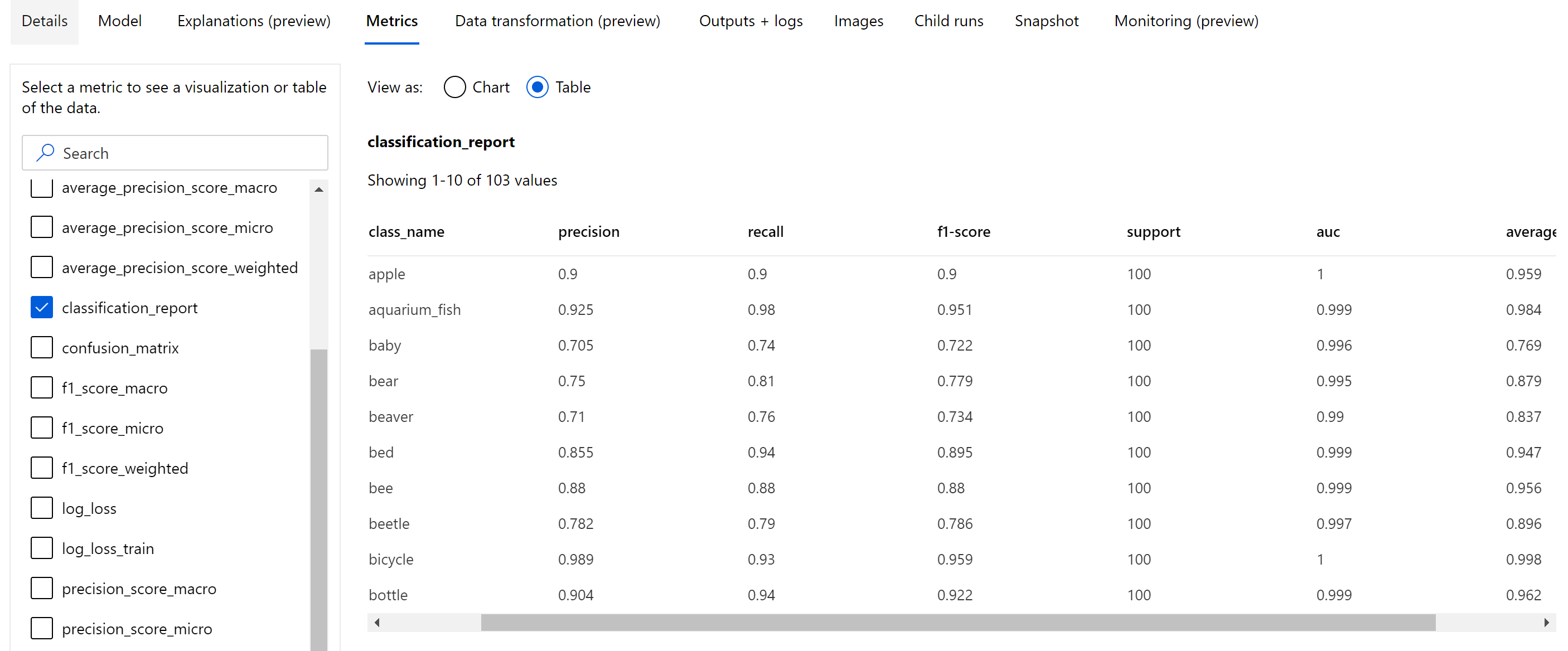
A korszak szintjén naplózott skaláris metrikákon kívül a képbesorolási modell olyan összefoglaló metrikákat is naplóz, mint a keveredési mátrix, a besorolási diagramok, beleértve a ROC-görbét, a pontosságvisszahívási görbét és a modell besorolási jelentését a legjobb korszakból, ahol a legmagasabb elsődleges metrika (pontosság) pontszámot kapjuk.
A besorolási jelentés olyan metrikák osztályszintű értékeit tartalmazza, mint a pontosság, a visszahívás, az f1-pontszám, a támogatás, az auc és a average_precision különböző szintű átlagolással – mikro, makró és súlyozott, az alábbiak szerint. Tekintse meg a metrikadefiníciókat a besorolási metrikák szakaszból.
Objektumészlelési és példányszegmentálási metrikák
A képobjektum-észlelési vagy -példányszegmentálási modell minden előrejelzése megbízhatósági pontszámmal van társítva.
A pontszám küszöbértékénél nagyobb megbízhatósági pontszámmal rendelkező előrejelzések előrejelzésként jelennek meg, és a metrikaszámításban használatosak, amelynek alapértelmezett értéke modellspecifikus, és a hiperparaméter finomhangolási oldaláról (box_score_threshold hiperparaméter) hivatkozható.
A képobjektum-észlelési és példányszegmentálási modell metrikaszámítása egy IoU (Metszet az Unió felett metszet) nevű metrikával meghatározott átfedéses mérésen alapul, amelyet úgy számítunk ki, hogy elosztjuk az átfedés területét az alapigazság és az előrejelzések közötti átfedés területével az alapigazság és az előrejelzések egyesítésének területe alapján. Az összes előrejelzésből kiszámított IoU egy átfedési küszöbértékkel , az úgynevezett IoU-küszöbértékkel van összehasonlítva, amely meghatározza, hogy egy előrejelzés mekkora átfedésben legyen egy felhasználó által jegyzett alapigazsággal annak érdekében, hogy pozitív előrejelzésnek lehessen tekinteni. Ha az előrejelzésből kiszámított IoU kisebb az átfedési küszöbértéknél, az előrejelzés nem tekinthető pozitív előrejelzésnek a társított osztály esetében.
A képobjektum-észlelési és példányszegmentációs modellek kiértékelésének elsődleges metrikája az átlagos pontosság (mAP) átlaga. Az mAP az összes osztály átlagos pontosságának (AP) átlagértéke. Az automatizált gépi tanulási objektumészlelési modellek támogatják az mAP számítását az alábbi két népszerű módszer használatával.
Pascal VOC-metrikák:
A Pascal VOC mAP az objektumészlelési/példányszegmentálási modellek mAP-számításának alapértelmezett módja. A Pascal VOC stílusú mAP metódus kiszámítja a terület értékét a pontossági visszahívási görbe egy verziójában. Az első p(ri), amely a visszahívási pontosság, az összes egyedi visszahívási értékhez kiszámítva. a p(ri) helyére a visszahívási r' >= ri maximális pontosságot kell beszedni. A pontossági érték monoton módon csökken a görbe ezen verziójában. A Pascal VOC mAP-metrikája alapértelmezés szerint 0,5-ös IoU-küszöbértékkel van kiértékelve. Ennek a koncepciónak a részletes magyarázata ebben a blogban érhető el.
COCO-metrikák:
A COCO-kiértékelési módszer egy 101 pontos interpolált módszert használ az AP-számításhoz, valamint tíz IoU-küszöbérték átlagolását. AP@[.5:.95] az IoU átlagos AP-értékének felel meg 0,5 és 0,95 közötti, 0,05-ös lépésmérettel. Az automatizált gépi tanulás naplózza a COCO metódus által meghatározott tizenkét metrikát, beleértve az AP-t és az AR-t (az átlagos visszahívást) az alkalmazásnaplók különböző skáláiban, míg a metrikák felhasználói felülete csak az mAP-t jeleníti meg egy 0,5-ös IoU-küszöbértéknél.
Tipp.
A képobjektum-észlelési modell kiértékelése kakaómetrikát használhat, ha a validation_metric_type hiperparaméter "coco" értékre van állítva a hiperparaméter finomhangolási szakaszában leírtak szerint.
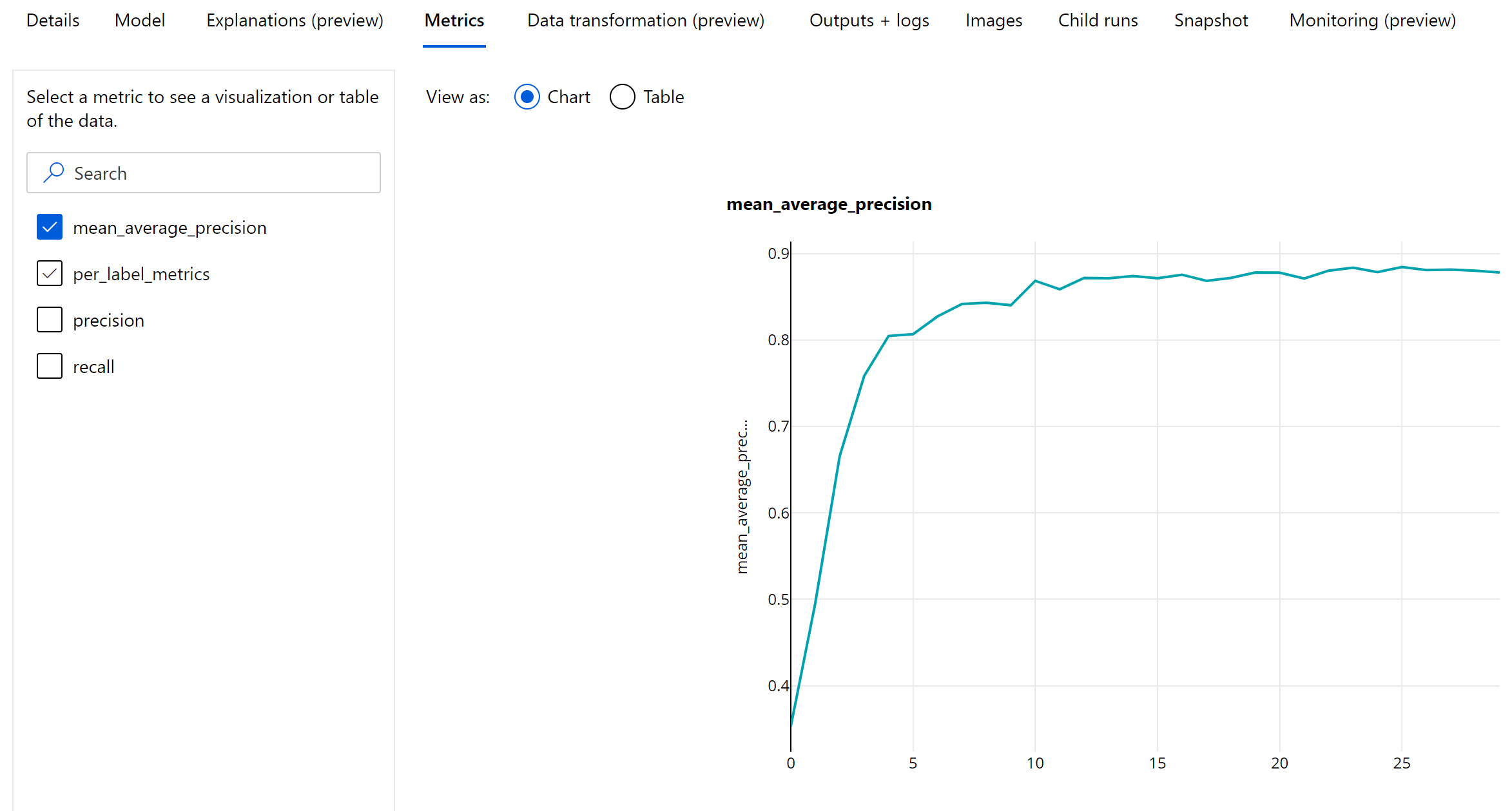
Korszakszintű metrikák az objektumészleléshez és a példány szegmentálásához
Az mAP, a pontosság és a visszahívás értékeit a rendszer rendszerállapot szintjén naplózza a képobjektum-észlelési/példányszegmentálási modellek esetében. Az mAP, a pontosság és a visszahívási metrikák szintén osztályszinten vannak naplózva,"per_label_metrics" néven. A "per_label_metrics" táblának kell tekinteni.
Megjegyzés:
A precizitás, a visszahívás és a per_label_metrics epoch szintű metrikái nem érhetők el a "coco" metódus használatakor.
Felelős AI-irányítópult a legjobban ajánlott AutoML-modellért (előzetes verzió)
Az Azure Machine Tanulás Felelős AI-irányítópult egyetlen felületet biztosít, amellyel hatékonyan és hatékonyan implementálhatja a felelős AI-t a gyakorlatban. A felelős AI-irányítópult csak táblázatos adatokkal támogatott, és csak besorolási és regressziós modellek esetén támogatott. Számos kiforrott felelős AI-eszközt fog össze a következő területeken:
- Modell teljesítményének és méltányosságának felmérése
- Adatfeltárás
- Gépi tanulás értelmezhetősége
- Hibaelemzés
Bár a modellértékelési metrikák és diagramok jóak a modell általános minőségének mérésére, az olyan műveletek, mint a modell méltányosságának vizsgálata, a magyarázatok megtekintése (más néven az, hogy az adathalmaz milyen modellekkel rendelkezik az előrejelzések készítéséhez), a hibák és a lehetséges vakfoltok vizsgálata elengedhetetlen a felelős AI gyakorlása során. Az automatizált gépi tanulás ezért biztosít egy felelős AI-irányítópultot, amely segít a modell különféle elemzéseinek megfigyelésében. Megtudhatja, hogyan tekintheti meg a Felelős AI-irányítópultot az Azure Machine Tanulás Studióban.
Megtudhatja, hogyan hozhatja létre ezt az irányítópultot a felhasználói felületen vagy az SDK-on keresztül.
Modellmagyarázatok és funkciók fontossága
Bár a modellértékelési metrikák és diagramok alkalmasak a modell általános minőségének mérésére, a felelős AI gyakorlása során elengedhetetlen annak vizsgálata, hogy a modell mely adathalmaz-jellemzőket használja az előrejelzések készítéséhez. Ezért az automatizált gépi tanulás egy modellmagyarázat-irányítópultot biztosít az adathalmaz-funkciók relatív hozzájárulásainak méréséhez és jelentéséhez. Megtudhatja, hogyan tekintheti meg a magyarázatok irányítópultját az Azure Machine Tanulás Studióban.
Megjegyzés:
Az értelmezhetőség, a legjobb modell magyarázata nem érhető el automatizált gépi tanulási előrejelzési kísérletekhez, amelyek a következő algoritmusokat javasolják a legjobb modellként vagy együttesként:
- TCNForecaster
- AutoArima
- ExponenciálisSmoothing
- Próféta
- Átlagos
- Naiv
- Szezonális átlag
- Szezonális naiv
Következő lépések
- Próbálja ki az automatizált gépi tanulási modell magyarázati mintajegyzetfüzeteit.
- Az automatizált gépi tanulással kapcsolatos konkrét kérdésekért keresse fel a következőt askautomatedml@microsoft.com: .