AutoML-betanítás beállítása a Pythonnal
ÉRVÉNYES: Python SDK azureml v1
Python SDK azureml v1
Ebből az útmutatóból megtudhatja, hogyan állíthat be automatikus gépi tanulást, AutoML-t, és hogyan futtathat betanítást az Azure Machine Tanulás Python SDK-val az Azure Machine Tanulás automatizált gépi tanulással. Az automatizált gépi tanulás kiválaszt egy algoritmust és hiperparamétereket, és létrehoz egy üzembe helyezésre kész modellt. Ez az útmutató részletesen ismerteti az automatizált gépi tanulási kísérletek konfigurálásához használható különféle lehetőségeket.
A végpontok közötti példaért tekintse meg az AutoML- betanítási regressziós modellt ismertető oktatóanyagot.
Ha inkább a kód nélküli felületet választja, a kód nélküli AutoML-betanítást is beállíthatja az Azure Machine Tanulás studióban.
Előfeltételek
Ebben a cikkben a következőt kell megadnia:
Egy Azure Machine Learning-munkaterület. A munkaterület létrehozásához lásd : Munkaterület-erőforrások létrehozása.
Az Azure Machine Tanulás Python SDK telepítve van. Az SDK telepítéséhez
Hozzon létre egy számítási példányt, amely automatikusan telepíti az SDK-t, és előre konfigurálva van az ML-munkafolyamatokhoz. További információ: Azure Machine Tanulás számítási példány létrehozása és kezelése.
Telepítse saját maga a
automlcsomagot, amely tartalmazza az SDK alapértelmezett telepítését.
Fontos
A cikkben szereplő Python-parancsokhoz a legújabb
azureml-train-automlcsomagverzió szükséges.- Telepítse a legújabb
azureml-train-automlcsomagot a helyi környezetbe. - A legújabb
azureml-train-automlcsomag részleteiért tekintse meg a kibocsátási megjegyzéseket.
Figyelmeztetés:
A Python 3.8 nem kompatibilis a .
automl
A kísérlet típusának kiválasztása
A kísérlet megkezdése előtt meg kell határoznia, hogy milyen gépi tanulási problémát old meg. Az automatizált gépi tanulás támogatja az , regressionés forecastinga . típusú feladattípusokatclassification. További információ a tevékenységtípusokról.
Megjegyzés:
A természetes nyelvi feldolgozás (NLP) feladatainak támogatása: a képbesorolás (többosztályos és többcímke) és az elnevezett entitásfelismerés nyilvános előzetes verzióban érhető el. További információ az NLP-feladatokról az automatizált gépi tanulásban.
Ezek az előzetes verziójú képességek szolgáltatásszint-szerződés nélkül érhetők el. Előfordulhat, hogy bizonyos funkciók nem támogatottak, vagy korlátozott funkciókkal rendelkeznek. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Az alábbi kód a task konstruktor paraméterét használja a AutoMLConfig kísérlet típusának classificationmegadásához.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Adatforrás és formátum
Az automatizált gépi tanulás támogatja a helyi számítógépen vagy a felhőben, például az Azure Blob Storage-ban található adatokat. Az adatok beolvashatók egy Pandas DataFrame-be vagy egy Azure Machine-Tanulás TabularDatasetbe. További információ az adathalmazokról.
A gépi tanulás betanítási adatainak követelményei:
- Az adatoknak táblázatos formában kell lenniük.
- Az előrejelezendő értéknek, a céloszlopnak az adatokban kell lennie.
Fontos
Az automatizált gépi tanulási kísérletek nem támogatják az identitásalapú adathozzáférést használó adathalmazok betanítását.
Távoli kísérletek esetén a betanítási adatoknak elérhetőnek kell lenniük a távoli számításból. Az automatizált gépi tanulás csak akkor fogadja el az Azure Machine Tanulás TabularDatasetset, ha távoli számításon dolgozik.
Az Azure Machine Learning-adathalmazok a következő funkciókat biztosítják:
- Egyszerűen továbbíthat adatokat statikus fájlokból vagy URL-forrásokból a munkaterületre.
- Az adatok elérhetővé tétele a betanítási szkriptek számára a felhőbeli számítási erőforrásokon való futtatáskor. Tekintse meg az adatkészletek betanítása című témakört, amely bemutatja, hogyan csatlakoztathat adatokat a távoli számítási célhoz az
Datasetosztály használatával.
Az alábbi kód létrehoz egy TabularDatasetet egy webes URL-címből. Az adatkészletek más forrásokból, például helyi fájlokból és adattárakból való létrehozására vonatkozó példakódokat a TabularDataset létrehozása című témakörben talál.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
A helyi számítási kísérletekhez a pandas adatkereteket javasoljuk a gyorsabb feldolgozási idő érdekében.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Betanítási, érvényesítési és tesztelési adatok
Külön betanítási és érvényesítési adatkészleteket közvetlenül a AutoMLConfig konstruktorban adhat meg. További információ az AutoML-kísérletek betanítási , érvényesítési, keresztérvényesítési és tesztelési adatainak konfigurálásáról.
Ha nem ad meg explicit módon egy vagy n_cross_validation több paramétertvalidation_data, az automatizált gépi tanulás alapértelmezett technikákat alkalmaz az ellenőrzés végrehajtásának meghatározására. Ez a meghatározás a paraméterhez rendelt training_data adathalmaz sorainak számától függ.
| Betanítási adatok mérete | Érvényesítési technika |
|---|---|
| 20 000 sornál nagyobb | Betanítási/érvényesítési adatok felosztása lesz alkalmazva. Az alapértelmezett beállítás az, hogy a kezdeti betanítási adatkészlet 10%-át használja érvényesítési csoportként. Ez az érvényesítési csoport a metrikák kiszámításához használatos. |
| 20 000 sornál kisebb | A rendszer keresztérvényesítési megközelítést alkalmaz. A hajtások alapértelmezett száma a sorok számától függ. Ha az adathalmaz kevesebb, mint 1000 sor, akkor a rendszer 10 hajtást használ. Ha a sorok 1000 és 20 000 között vannak, akkor a rendszer három hajtást használ. |
Tipp.
A tesztadatok (előzetes verzió) feltöltésével kiértékelheti az ön számára létrehozott automatizált gépi tanulási modelleket. Ezek a funkciók kísérleti előzetes verziójú képességek, és bármikor változhatnak. Az alábbiak végrehajtásának módját ismerheti meg:
- Adja át a tesztadatokat az AutoMLConfig-objektumnak.
- Tesztelje a kísérlethez létrehozott automatizált gépi tanulási modelleket.
Ha inkább kód nélküli felületet szeretne használni, tekintse meg az AutoML beállítása a studio felhasználói felülettel című 12. lépést
Nagy méretű adatok
Az automatizált gépi tanulás korlátozott számú algoritmust támogat a nagy adatok betanításához, amelyek sikeresen készíthetnek modelleket a big datahoz a kis virtuális gépeken. Az automatizált gépi tanulási heurisztika olyan tulajdonságoktól függ, mint az adatméret, a virtuális gépek memóriamérete, a kísérlet időtúllépési és featurizálási beállításai, amelyek meghatározzák, hogy ezeket a nagy adatalgoritmusokat kell-e alkalmazni. További információ az automatizált gépi tanulásban támogatott modellekről.
Regresszióhoz online színátmenetes degresszor és gyors lineáris regresszió
Besoroláshoz az Átlagolt perceptron osztályozó és a Lineáris SVM-osztályozó; ahol a lineáris SVM-osztályozó nagy adat- és kis adatverziókkal is rendelkezik.
Ha felül szeretné bírálni ezeket a heurisztikusokat, alkalmazza a következő beállításokat:
| Feladatok | Beállítás | Jegyzetek |
|---|---|---|
| Adatstreamelési algoritmusok letiltása | blocked_models az AutoMLConfig objektumban, és sorolja fel a nem használni kívánt modell(ek)et. |
Futási hibát vagy hosszú futási időt eredményez |
| Adatstreamelési algoritmusok használata | allowed_models az AutoMLConfig objektumban, és listázhatja a használni kívánt modell(ek)et. |
|
| Adatstreamelési algoritmusok használata (studio UI-kísérletek) |
Tiltsa le az összes modellt, kivéve a használni kívánt big data algoritmusokat. |
Számítás a kísérlet futtatásához
Ezután határozza meg, hogy a modell hol lesz betanítve. Az automatizált gépi tanulási kísérlet a következő számítási lehetőségeken futtatható.
Válasszon egy helyi számítást: Ha a forgatókönyv a kis adatokkal és rövid vonatokkal végzett kezdeti feltárásokról vagy demókról szól (például másodpercekről vagy néhány percről gyermekenként), akkor a helyi számítógépen történő betanítás jobb választás lehet. Nincs beállítási idő, az infrastruktúra-erőforrások (a számítógép vagy a virtuális gép) közvetlenül elérhetők. A helyi számításra ebben a jegyzetfüzetben tekinthet meg egy példát.
Válasszon távoli ml számítási fürtöt: Ha olyan nagyobb adatkészletekkel végzett betanítást, mint például az éles betanításokban, amelyek hosszabb vonatokat igénylő modelleket hoznak létre, a távoli számítás sokkal jobb végpontok közötti időt biztosít, mivel
AutoMLpárhuzamossá teszi a vonatokat a fürt csomópontjai között. Távoli számítás esetén a belső infrastruktúra indítási ideje gyermekfuttatásonként körülbelül 1,5 percet vesz fel, valamint további perceket a fürtinfrastruktúra számára, ha a virtuális gépek még nem működnek.Az Azure Machine Tanulás Managed Compute egy felügyelt szolgáltatás, amely lehetővé teszi gépi tanulási modellek betanítása Azure-beli virtuális gépek fürtöire. A számítási példány számítási célként is támogatott.Azure Databricks-fürt az Azure-előfizetésben. További részleteket az Azure Databricks-fürt beállítása automatizált gépi tanuláshoz című témakörben talál. Az Azure Databrickset használó jegyzetfüzetekre ezen a GitHub-helyen találhat példákat.
A számítási cél kiválasztásakor vegye figyelembe ezeket a tényezőket:
| Előnyök (előnyök) | Hátrányok (hátrányok) | |
|---|---|---|
| Helyi számítási cél | ||
| Távoli gépi tanulási számítási fürtök |
A kísérlet beállításainak konfigurálása
Az automatizált gépi tanulási kísérlet konfigurálásához számos lehetőség közül választhat. Ezek a paraméterek egy AutoMLConfig objektum példányosításával vannak beállítva. A paraméterek teljes listáját az AutoMLConfig osztályban találja.
Az alábbi példa egy besorolási feladatra mutat be. A kísérlet elsődleges metrikaként az AUC-t használja, és a kísérlet időkorlátja 30 perc és 2 keresztérvényesítési redő.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Az előrejelzési feladatokat is konfigurálhatja, ami további beállításokat igényel. További részletekért tekintse meg az AutoML beállítása idősorozat-előrejelzési cikket.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Támogatott modellek
Az automatizált gépi tanulás különböző modelleket és algoritmusokat próbál ki az automatizálási és finomhangolási folyamat során. Felhasználóként nincs szükség az algoritmus megadására.
A három különböző task paraméterérték határozza meg az alkalmazni kívánt algoritmusok vagy modellek listáját. allowed_models A paraméterekkel blocked_models tovább módosíthatja az iterációkat az elérhető modellekkel, hogy belefoglalják vagy kizárják azokat.
Az alábbi táblázat tevékenységtípusonként összegzi a támogatott modelleket.
Megjegyzés:
Ha az automatizált gépi tanulással létrehozott modelleket ONNX-modellbe szeretné exportálni, csak a * (csillaggal) jelölt algoritmusok konvertálhatók ONNX formátumra. További információ a modellek ONNX-gé alakításáról.
Azt is vegye figyelembe, hogy az ONNX jelenleg csak a besorolási és regressziós feladatokat támogatja.
Elsődleges metrika
A primary_metric paraméter meghatározza a modellbetanítás során az optimalizáláshoz használandó metrikát. A választható metrikákat a választott tevékenységtípus határozza meg.
Az automatizált gépi tanulás elsődleges metrikájának kiválasztása az optimalizáláshoz számos tényezőtől függ. Azt javasoljuk, hogy az elsődleges szempont egy olyan metrika kiválasztása legyen, amely a legjobban megfelel az üzleti igényeinek. Ezután fontolja meg, hogy a metrika alkalmas-e az adathalmaz-profilhoz (adatméret, tartomány, osztályeloszlás stb.). Az alábbi szakaszok a tevékenységtípus és az üzleti forgatókönyv alapján összegzik az ajánlott elsődleges metrikákat.
Az automatizált gépi tanulási eredmények megismerésében megismerheti ezeknek a metrikáknak a konkrét definícióit.
Metrikák besorolási forgatókönyvekhez
A küszöbérték-függő metrikák, például accuracya norm_macro_recall, recall_score_weighted, és precision_score_weighted nem feltétlenül optimalizálhatók olyan adathalmazokhoz, amelyek kicsik, nagyon nagy osztályeltérésben (osztálykiegyenlülés), vagy ha a várt metrikaérték nagyon közel van a 0,0-hoz vagy az 1.0-hoz. Ezekben az esetekben AUC_weighted jobb választás lehet az elsődleges metrika számára. Az automatizált gépi tanulás befejezése után kiválaszthatja a nyertes modellt az üzleti igényeinek leginkább megfelelő metrika alapján.
| Metric | Példa használati eset(ek) |
|---|---|
accuracy |
Képbesorolás, Hangulatelemzés, Változás előrejelzése |
AUC_weighted |
Csalásészlelés, Képbesorolás, Anomáliadetektálás/levélszemétészlelés |
average_precision_score_weighted |
Hangulatelemzés |
norm_macro_recall |
Változás előrejelzése |
precision_score_weighted |
Regressziós forgatókönyvekhez használható metrikák
r2_score, normalized_mean_absolute_error és normalized_root_mean_squared_error megpróbálják minimalizálni az előrejelzési hibákat. r2_score és normalized_root_mean_squared_error mindkettő minimálisra csökkenti az átlagos négyzetes hibákat, miközben normalized_mean_absolute_error csökkenti a hibák átlagos abszolút értékét. Az abszolút érték minden nagyságrendben kezeli a hibákat, és a négyzetes hibák sokkal nagyobb büntetést kapnak a nagyobb abszolút értékeket tartalmazó hibákért. Attól függően, hogy nagyobb hibákat kell-e többé vagy sem büntetni, választhat, hogy optimalizálja a négyzetes vagy az abszolút hibát.
A fő különbség a normalizálásuk r2_scorenormalized_root_mean_squared_error módja és jelentéseik között. normalized_root_mean_squared_error a tartomány szerint normalizált, négyzetes középértéket jelenti, és az előrejelzés átlagos hibaértékeként értelmezhető. r2_score az adateltérés becslése által normalizált átlagos négyzetes hiba. A modell által rögzíthető variációk aránya.
Megjegyzés:
r2_score és normalized_root_mean_squared_error ugyanúgy viselkedik, mint az elsődleges metrikák. Rögzített érvényesítési csoport alkalmazása esetén ez a két metrika ugyanazt a célt optimalizálja, a középérték négyzetes hibát jelenti, és ugyanazt a modellt fogja optimalizálni. Ha csak egy betanítási készlet áll rendelkezésre, és keresztérvényesítést alkalmaz, azok kissé eltérőek lesznek, mivel a normalizáló normalized_root_mean_squared_error a betanítási készlet tartományaként van rögzítve, de a normalizáló r2_score minden hajtás esetében eltérő lehet, mivel ez az egyes hajtások varianciája.
Ha a rangsor a pontos érték helyett érdekes, akkor jobb választás lehet, spearman_correlation mivel a valós értékek és az előrejelzések közötti rang-korrelációt méri.
A regresszió elsődleges metrikái azonban jelenleg nem foglalkoznak a relatív különbségekkel. r2_scorenormalized_mean_absolute_errornormalized_root_mean_squared_error A 30 000 ft-os fizetéssel rendelkező feldolgozók esetében a 20 ezer dolláros előrejelzési hibát ugyanúgy kezelheti, mint a 20 millió usd értékű feldolgozót, ha ez a két adatpont ugyanahhoz az adatkészlethez tartozik a regresszióhoz, vagy az idősorazonosító által megadott idősorhoz. Míg a valóságban, előre csak $ 20k ki egy $ 20M fizetés nagyon közel (egy kis 0,1% relatív különbség), míg $ 20k ki $ 30k nem közel (nagy 67%-os relatív különbség). A relatív különbség problémájának megoldásához betanítani lehet egy modellt a rendelkezésre álló elsődleges metrikákkal, majd kiválaszthatja a modellt a legjobb mean_absolute_percentage_error vagy root_mean_squared_log_error.
| Metric | Példa használati eset(ek) |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Ár-előrejelzés (ház/termék/tipp), Pontszám előrejelzésének áttekintése |
r2_score |
Légitársaság késése, Fizetés becslése, Hibafeloldási idő |
normalized_mean_absolute_error |
Idősor-előrejelzési forgatókönyvek metrikái
A javaslatok hasonlóak a regressziós forgatókönyvekhez feljegyzett javaslatokhoz.
| Metric | Példa használati eset(ek) |
|---|---|
normalized_root_mean_squared_error |
Ár-előrejelzés (előrejelzés), Készletoptimalizálás, Kereslet-előrejelzés |
r2_score |
Ár-előrejelzés (előrejelzés), Készletoptimalizálás, Kereslet-előrejelzés |
normalized_mean_absolute_error |
Adatok featurizálása
Minden automatizált gépi tanulási kísérletben az adatok automatikusan skálázódnak és normalizálódnak, hogy segítsenek bizonyos algoritmusoknak, amelyek érzékenyek a különböző skálázású funkciókra. Ezt a skálázást és normalizálást featurizációnak nevezzük. További részletekért és kód példákért lásd az AutoML-ben a featurizációt.
Megjegyzés:
A gépi tanulás automatizált featurizálási lépései (funkció normalizálása, hiányzó adatok kezelése, szöveg numerikussá alakítása stb.) a mögöttes modell részévé válnak. Ha a modellt előrejelzésekhez használja, a betanítás során alkalmazott featurizációs lépések automatikusan a bemeneti adatokra lesznek alkalmazva.
Amikor konfigurálja a kísérleteket az AutoMLConfig objektumban, engedélyezheti vagy letilthatja a beállítást featurization. Az alábbi táblázat az AutoMLConfig objektumban a featurizálás elfogadott beállításait mutatja be.
| Featurization Configuration | Leírás |
|---|---|
"featurization": 'auto' |
Azt jelzi, hogy az előfeldolgozás részeként a rendszer automatikusan végrehajtja az adatvédettségi és a featurizálási lépéseket . Alapértelmezett beállítás. |
"featurization": 'off' |
Azt jelzi, hogy a featurizációs lépést nem szabad automatikusan elvégezni. |
"featurization": 'FeaturizationConfig' |
Azt jelzi, hogy a testre szabott featurizációs lépést kell használni. Ismerje meg, hogyan szabhatja testre a featurizációt. |
Együttes konfigurálása
Az együttes modellek alapértelmezés szerint engedélyezve vannak, és az AutoML-futtatások utolsó futtatási iterációiként jelennek meg. Jelenleg a VotingEnsemble és a StackEnsemble támogatott.
A szavazás soft-votingt valósít meg, amely súlyozott átlagokat használ. A halmozási implementáció kétrétegű implementációt használ, ahol az első réteg ugyanazokat a modelleket tartalmazza, mint a szavazó együttes, a második réteg pedig az első réteg modelljeinek optimális kombinációját.
Ha ONNX-modelleket használ, vagy engedélyezve van a modell magyarázata, a halmozás le van tiltva, és csak a szavazatok lesznek használva.
Az együttes betanítása a enable_voting_ensembleenable_stack_ensemble logikai paraméterekkel letiltható.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Az alapértelmezett együttes viselkedésének módosításához több alapértelmezett argumentum is megadható, mint kwargs egy AutoMLConfig objektumban.
Fontos
Az alábbi paraméterek nem az AutoMLConfig osztály explicit paraméterei.
ensemble_download_models_timeout_sec: A VotingEnsemble és a StackEnsemble modell létrehozása során a rendszer az előző gyermekfuttatásokból több beépített modellt tölt le. Ha ezt a hibát tapasztalja:AutoMLEnsembleException: Could not find any models for running ensemblingakkor előfordulhat, hogy több időt kell biztosítania a modellek letöltéséhez. Az alapértelmezett érték 300 másodperc a modellek párhuzamos letöltéséhez, és nincs maximális időtúllépési korlát. Ha több időre van szükség, konfigurálja ezt a paramétert 300 másodpercnél nagyobb értékkel.Megjegyzés:
Ha eléri az időtúllépést, és vannak letöltött modellek, akkor a ensembling annyi modellel folytatódik, amennyit letöltött. Nem szükséges, hogy az összes modellt le kell tölteni ahhoz, hogy az adott időkorláton belül befejeződjön. A következő paraméterek csak a StackEnsemble-modellekre vonatkoznak:
stack_meta_learner_type: a metatanuló az egyes heterogén modellek kimenetére betanított modell. Az alapértelmezett metatanulókLogisticRegressiona besorolási feladatokhoz (vagyLogisticRegressionCVha engedélyezve van a keresztérvényesítés) ésElasticNeta regressziós/előrejelzési tevékenységekhez (vagyElasticNetCVha a keresztérvényesítés engedélyezve van). Ez a paraméter a következő sztringek egyike lehet:LogisticRegression, ,LightGBMClassifierLogisticRegressionCV,ElasticNet,ElasticNetCV, vagyLinearRegressionLightGBMRegressor.stack_meta_learner_train_percentage: meghatározza a betanítási csoport (a betanítási és érvényesítési típus kiválasztásakor) a metatanuló betanításához lefoglalandó arányát. Az alapértelmezett érték0.2.stack_meta_learner_kwargs: a metatanuló inicializálójának átadandó választható paraméterek. Ezek a paraméterek és paramétertípusok a megfelelő modellkonstruktor paramétereit és paramétertípusait tükrözik, és továbbítják a modellkonstruktornak.
Az alábbi kód egy példát mutat be az egyéni együttes viselkedésének megadására egy AutoMLConfig objektumban.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Kilépési feltételek
A kísérlet befejezéséhez az AutoMLConfigban definiálhat néhány lehetőséget.
| Feltételek | leírás |
|---|---|
| Nincs feltétel | Ha nem határoz meg kilépési paramétereket, a kísérlet addig folytatódik, amíg az elsődleges metrika nem végez további előrehaladást. |
| Hosszabb idő után | A experiment_timeout_minutes beállításokban megadhatja, hogy a kísérlet mennyi ideig futjon percek alatt. A kísérlet időtúllépési hibáinak elkerülése érdekében legalább 15 perc vagy 60 perc áll rendelkezésre, ha a sor oszlopmérete meghaladja a 10 milliót. |
| Elérte a pontszámot | A használat experiment_exit_score befejezi a kísérletet egy megadott elsődleges metrikapont elérése után. |
Kísérlet futtatása
Figyelmeztetés:
Ha ugyanazt a konfigurációs beállítást és elsődleges metrikát többször futtatja, valószínűleg az egyes kísérletekben a végleges metrikák pontszámának és a létrehozott modelleknek a variációja jelenik meg. Az automatizált gépi tanulási algoritmusok eredendő véletlenszerűséggel rendelkeznek, ami kismértékű eltérést okozhat a modellek kimenetében a kísérlet és az ajánlott modell végső metrikák pontszámában, például a pontosságban. Valószínűleg ugyanazzal a modellnévvel, de különböző hiperparaméterekkel is látni fogja az eredményeket.
Az automatizált gépi tanuláshoz létre kell hoznia egy Experiment objektumot, amely egy elnevezett objektum egy Workspace kísérletek futtatásához használt objektumban.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Küldje el a kísérletet futtatásra, és hozzon létre egy modellt. Adja át a AutoMLConfig metódusnak a submit modell létrehozásához.
run = experiment.submit(automl_config, show_output=True)
Megjegyzés:
A függőségek először egy új gépen lesznek telepítve. A kimenet megjelenítése akár 10 percet is igénybe vehet.
Ha úgy van beállítva show_output , hogy True a kimenet megjelenjen a konzolon.
Több gyermekfuttatás fürtökön
Az automatizált gépi tanulási kísérlet gyermekfuttatásai olyan fürtön is elvégezhetők, amely már futtat egy másik kísérletet. Az időzítés azonban attól függ, hogy hány csomópontja van a fürtnek, és hogy ezek a csomópontok elérhetők-e egy másik kísérlet futtatásához.
A fürt minden csomópontja önálló virtuális gépként (VM) működik, amely egyetlen betanítási futtatásra képes; automatizált gépi tanulás esetén ez gyermekfuttatást jelent. Ha az összes csomópont foglalt, az új kísérlet várólistára kerül. Ha azonban vannak ingyenes csomópontok, az új kísérlet automatizált ml-gyermekfuttatásokat futtat párhuzamosan az elérhető csomópontokon/virtuális gépeken.
A gyermekfuttatások kezeléséhez és azok végrehajtásához javasoljuk, hogy kísérletenként hozzon létre egy dedikált fürtöt, és egyezzen a kísérlet számával max_concurrent_iterations a fürt csomópontjainak számával. Így a fürt összes csomópontját egyszerre, az egyidejű gyermekfuttatások/iterációk számával együtt használhatja.
Konfiguráljon max_concurrent_iterations az AutoMLConfig objektumban. Ha nincs konfigurálva, akkor alapértelmezés szerint kísérletenként csak egy egyidejű gyermekfuttatás/iteráció engedélyezett.
Számítási példány max_concurrent_iterations esetén a számítási példány virtuális gépén lévő magok számával megegyező értékre állítható be.
Modellek és metrikák megismerése
Az automatizált gépi tanulás lehetőséget kínál a betanítási eredmények monitorozására és kiértékelésére.
Ha jegyzetfüzetben van, megtekintheti a betanítási eredményeket egy widgetben vagy a beágyazott szövegben. További részletekért tekintse meg az automatizált gépi tanulási futtatások figyelése című témakört.
Az egyes futtatásokhoz megadott teljesítménydiagramokra és metrikákra vonatkozó definíciókat és példákat az automatizált gépi tanulási kísérletek eredményeinek kiértékelése című témakörben talál.
Ha szeretné lekérni a featurizációs összegzést, és tudni szeretné, hogy milyen funkciók lettek hozzáadva egy adott modellhez, tekintse meg a featurizáció átláthatóságát.
Megtekintheti a hiperparamétereket, a skálázási és normalizálási technikákat, valamint az egyéni kódmegoldással print_model()egy adott automatizált ml-futtatásra alkalmazott algoritmust.
Tipp.
Az automatizált gépi tanulás lehetővé teszi az automatikus gépi tanulással betanított modellekhez létrehozott modell betanítási kódjának megtekintését is. Ez a funkció nyilvános előzetes verzióban érhető el, és bármikor változhat.
Automatizált gépi tanulási futtatások monitorozása
Automatizált gépi tanulási futtatások esetén a diagramok egy korábbi futtatásból való eléréséhez cserélje le <<experiment_name>> a megfelelő kísérlet nevét:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
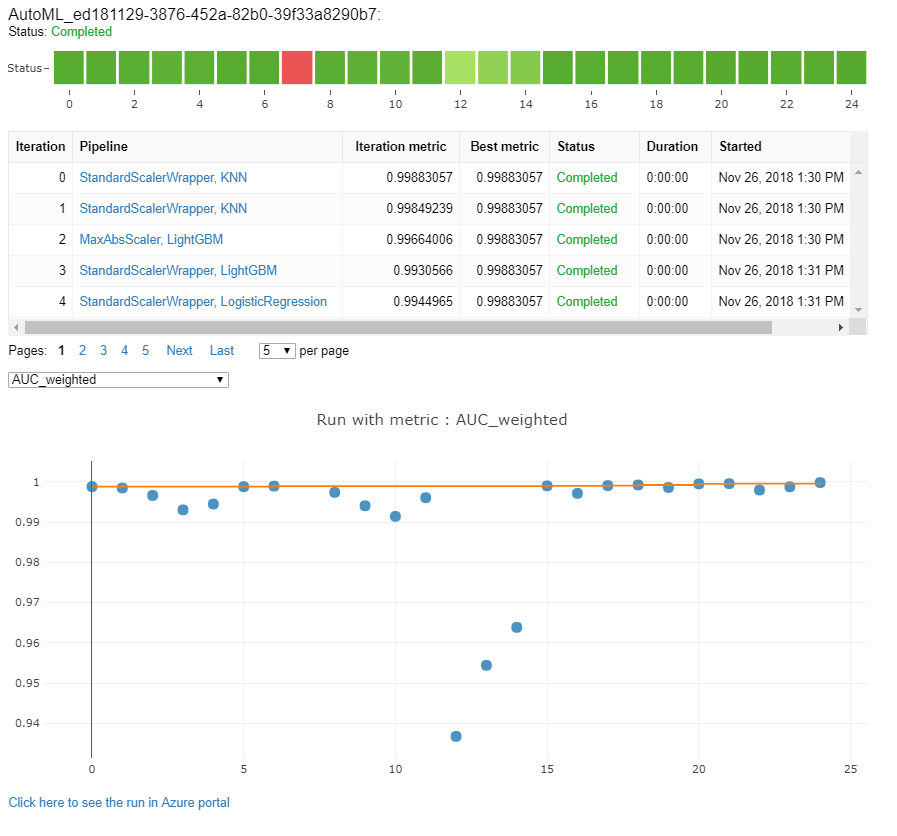
Tesztmodellek (előzetes verzió)
Fontos
A modellek tesztelése tesztadatkészlettel az automatizált gépi tanulás által generált modellek kiértékeléséhez előzetes verziójú funkció. Ez a funkció egy kísérleti előzetes verziójú funkció, amely bármikor változhat.
Figyelmeztetés:
Ez a funkció nem érhető el az alábbi automatizált gépi tanulási forgatókönyvekhez
Ha átadja a paramétereket a test_datatest_sizeAutoMLConfigrendszernek, automatikusan elindít egy távoli tesztfuttatást, amely a megadott tesztadatok alapján értékeli ki az automatizált gépi tanulás által a kísérlet befejezésekor javasolt legjobb modellt. Ezt a távoli tesztfuttatást a kísérlet végén, a legjobb modell meghatározása után végezzük el. Megtudhatja, hogyan továbbíthat tesztadatokat a saját gépére AutoMLConfig.
Tesztfeladat eredményeinek lekérése
Az előrejelzéseket és metrikákat az Azure Machine Tanulás Studióból vagy a következő kóddal szerezheti be a távoli tesztfeladatból.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
A modelltesztelési feladat létrehozza a munkaterülettel létrehozott alapértelmezett adattárban tárolt predictions.csv fájlt. Ez az adattár az azonos előfizetéssel rendelkező összes felhasználó számára látható. A tesztfeladatok nem ajánlottak forgatókönyvekhez, ha a tesztfeladathoz használt vagy létrehozott információknak magánjellegűnek kell lenniük.
Meglévő automatizált gépi tanulási modell tesztelése
A létrehozott egyéb automatizált gépi tanulási modellek, a legjobb feladat vagy a gyermekfeladat teszteléséhez használja ModelProxy() a modell tesztelését a fő AutoML-futtatás befejezése után. ModelProxy() már visszaadja az előrejelzéseket és a metrikákat, és nem igényel további feldolgozást a kimenetek lekéréséhez.
Megjegyzés:
A ModelProxy egy kísérleti előzetes verziójú osztály, amely bármikor változhat.
Az alábbi kód bemutatja, hogyan tesztelhet egy modellt bármilyen futtatásból a ModelProxy.test() metódussal. A test() metódusban megadhatja, hogy csak a paraméterrel include_predictions_only futtatott teszt előrejelzéseit szeretné-e látni.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Modellek regisztrálása és üzembe helyezése
Miután tesztelt egy modellt, és megerősítette, hogy éles környezetben szeretné használni, regisztrálhatja azt későbbi használatra, és
Ha egy modellt automatizált gépi tanulási futtatásból szeretne regisztrálni, használja a metódust register_model() .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Az üzembehelyezési konfiguráció létrehozásával és a regisztrált modell webszolgáltatásban való üzembe helyezésével kapcsolatos részletekért tekintse meg a modell üzembe helyezésének módját és helyét.
Tipp.
Regisztrált modellek esetén az egykattintásos üzembe helyezés az Azure Machine Tanulás Studióban érhető el. Megtudhatja , hogyan helyezhet üzembe regisztrált modelleket a stúdióból.
Modell értelmezhetősége
A modellértelmezhetőség lehetővé teszi annak megértését, hogy a modellek miért készítettek előrejelzéseket, valamint az alapul szolgáló jellemzők fontossági értékeit. Az SDK különböző csomagokat tartalmaz a modell értelmezhetőségi funkcióinak engedélyezéséhez mind betanítási, mind következtetési időben a helyi és az üzembe helyezett modellekhez.
Megtudhatja, hogyan engedélyezheti az értelmezhetőségi funkciókat kifejezetten az automatizált gépi tanulási kísérletekben.
Az SDK más területein az automatizált gépi tanuláson kívül a modellmagyarázatok és a funkciók fontosságának engedélyezéséről az értelmezhetőségről szóló fogalomcikkben talál általános információkat.
Megjegyzés:
A Magyarázó ügyfél jelenleg nem támogatja az ForecastTCN-modellt. Ez a modell nem ad vissza magyarázó irányítópultot, ha a legjobb modellként adja vissza, és nem támogatja az igény szerinti magyarázatfuttatásokat.
Következő lépések
További információ a modell üzembe helyezésének módjáról és módjáról.
További információ a regressziós modellek automatizált gépi tanulással való betanításáról.
Automatizált gépi tanulási kísérletek hibaelhárítása.