Automatizált gépi tanulási modell betanítási kódjának megtekintése
Ebből a cikkből megtudhatja, hogyan tekintheti meg a létrehozott betanítási kódot bármely automatizált gépi tanulással betanított modellből.
Az automatizált gépi tanulással betanított modellek kódlétrehozása a következő részleteket teszi lehetővé, amelyeket az automatizált gépi tanulás a modell betanítása és buildelése során használ egy adott futtatáshoz.
- Adatok előfeldolgozása
- Algoritmus kiválasztása
- Jellemzősítés
- Hiperparaméterek
Kiválaszthat bármilyen automatizált gépi tanulási betanított modellt, ajánlott vagy gyermekfuttatást, és megtekintheti az adott modellt létrehozó Python-betanítási kódot.
A létrehozott modell betanítási kódjával
- Ismerje meg , milyen featurizációs folyamatot és hiperparamétereket használ a modell algoritmusa.
- Betanított modellek nyomon követése/verziója/naplózása . A verziószámozott kód tárolása az éles környezetben üzembe helyezendő modellhez használt konkrét betanítási kód nyomon követéséhez.
- Testre szabhatja a betanítási kódot a hiperparaméterek módosításával vagy az ML és az algoritmusok képességeinek/tapasztalatának alkalmazásával, és egy új modell újratanításával a testreszabott kóddal.
Az alábbi ábra azt szemlélteti, hogy az automatizált gépi tanulási kísérletek kódját minden tevékenységtípussal létrehozhatja. Először válasszon ki egy modellt. A kiválasztott modell ki lesz emelve, majd az Azure Machine Tanulás átmásolja a modell létrehozásához használt kódfájlokat, és megjeleníti őket a jegyzetfüzetek megosztott mappájában. Innen igény szerint megtekintheti és testre szabhatja a kódot.
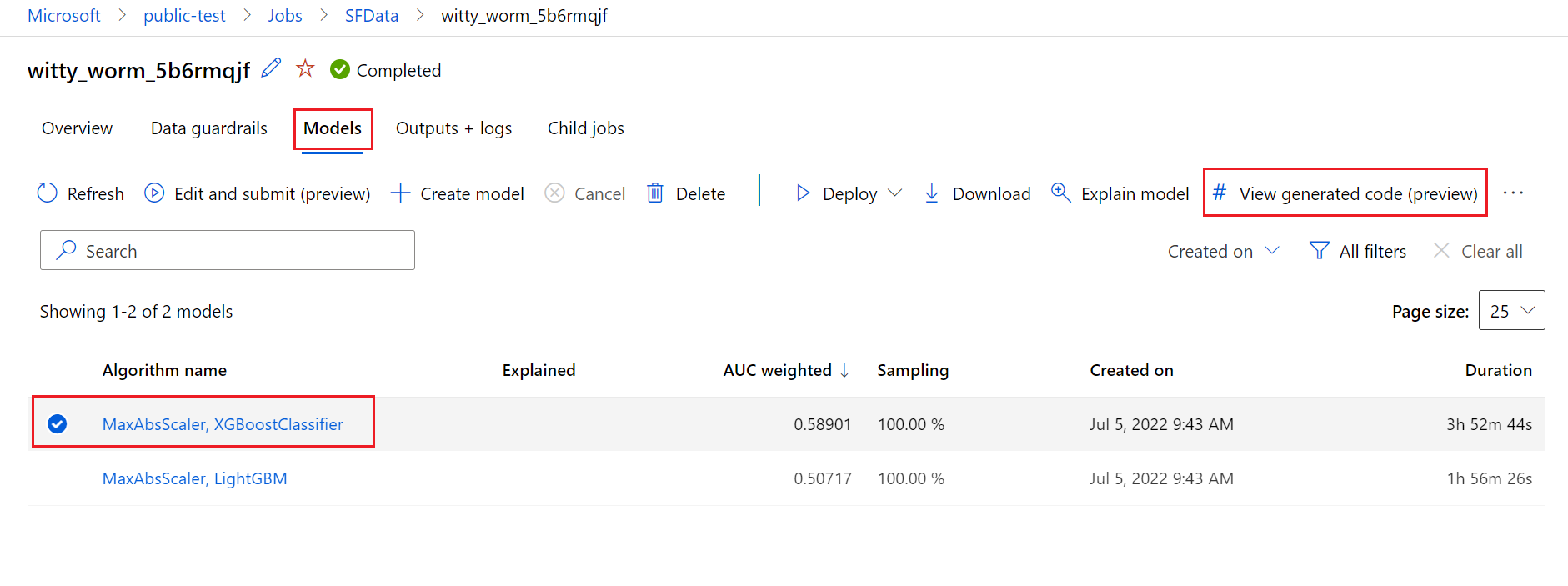
Előfeltételek
Egy Azure Machine Learning-munkaterület. A munkaterület létrehozásához lásd : Munkaterület-erőforrások létrehozása.
Ez a cikk feltételezi, hogy bizonyos ismeretekkel rendelkezik egy automatizált gépi tanulási kísérlet beállításához. Kövesse az oktatóanyagot vagy útmutatót a gépi tanulási kísérlet fő tervezési mintáinak megtekintéséhez.
Az automatizált ML-kódlétrehozás csak távoli Azure Machine-Tanulás számítási célokon futtatott kísérletekhez érhető el. A kódlétrehozás helyi futtatások esetén nem támogatott.
Az Azure Machine Tanulás Studio, az SDKv2 vagy a CLIv2 által aktivált összes automatizált ml-futtatás engedélyezve lesz a kódlétrehozásban.
Generált kód- és modellösszetevők lekérése
Alapértelmezés szerint minden automatizált gépi tanulási modell létrehozza a betanítási kódját a betanítás befejezése után. Az automatizált gépi tanulás menti ezt a kódot a kísérletben outputs/generated_code az adott modellhez. A kiválasztott modell Kimenetek + naplók lapján az Azure Machine Tanulás studio felhasználói felületén tekintheti meg őket.
script.py Ez a modell betanítási kódja, amelyet valószínűleg elemezni szeretne a featurizálási lépésekkel, a használt algoritmusokkal és hiperparaméterekkel.
script_run_notebook.ipynb notebook kazánlemez kóddal a modell betanítási kódjának (script.py) az Azure Machine Tanulás számításához az Azure Machine Tanulás SDKv2-n keresztül.
Az automatizált gépi tanulási folyamat befejeződése után az Azure Machine Tanulás studio felhasználói felületén keresztül elérheti a script.py fájlokat és script_run_notebook.ipynb a fájlokat.
Ehhez nyissa meg az automatizált gépi tanulási kísérlet szülőfuttatási lapjának Modellek lapját. Miután kiválasztotta az egyik betanított modellt, kiválaszthatja a Létrehozott kód megtekintése gombot. Ez a gomb átirányítja a Jegyzetfüzetek portál bővítményre, ahol megtekintheti, szerkesztheti és futtathatja az adott kiválasztott modellhez létrehozott kódot.
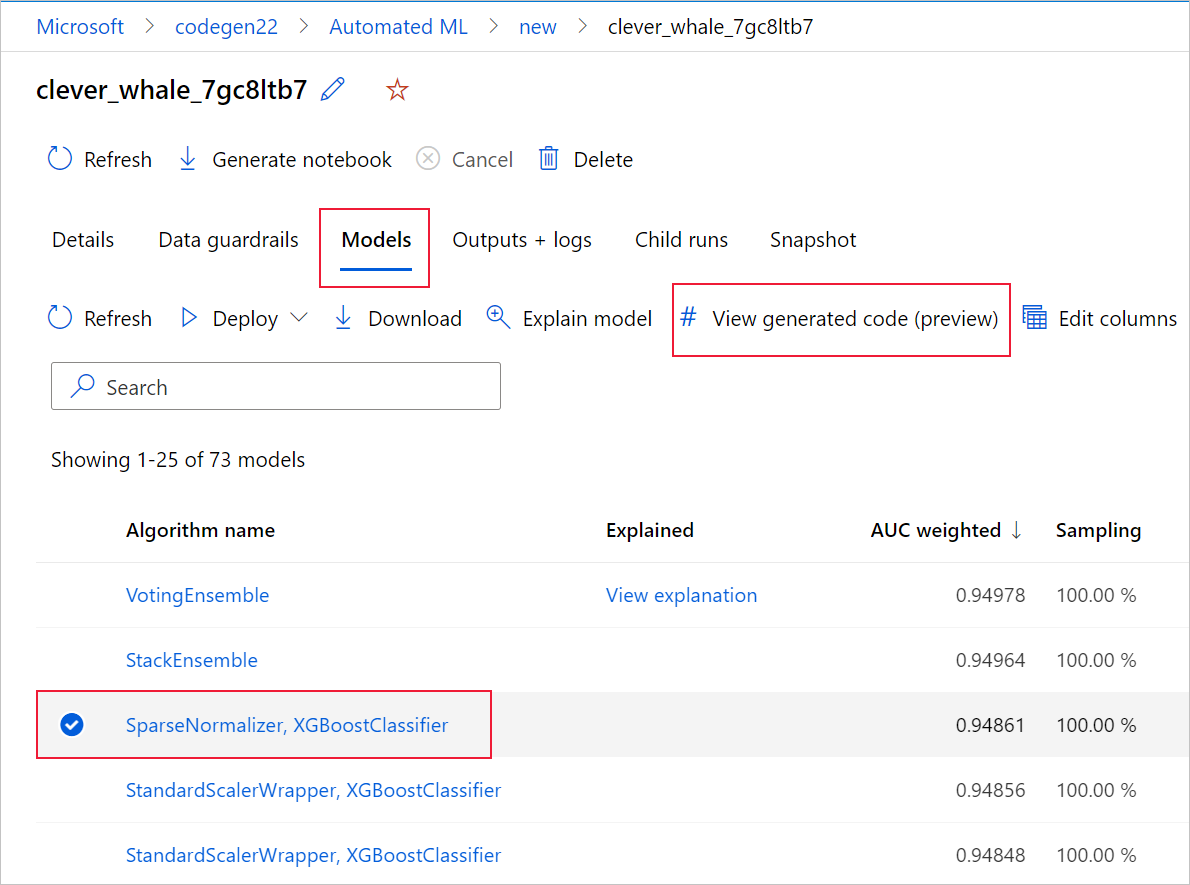
A modell által létrehozott kódhoz a gyermekfuttatás lapjának tetejéről is hozzáférhet, ha egy adott modell gyermekfuttatási lapjára lép.
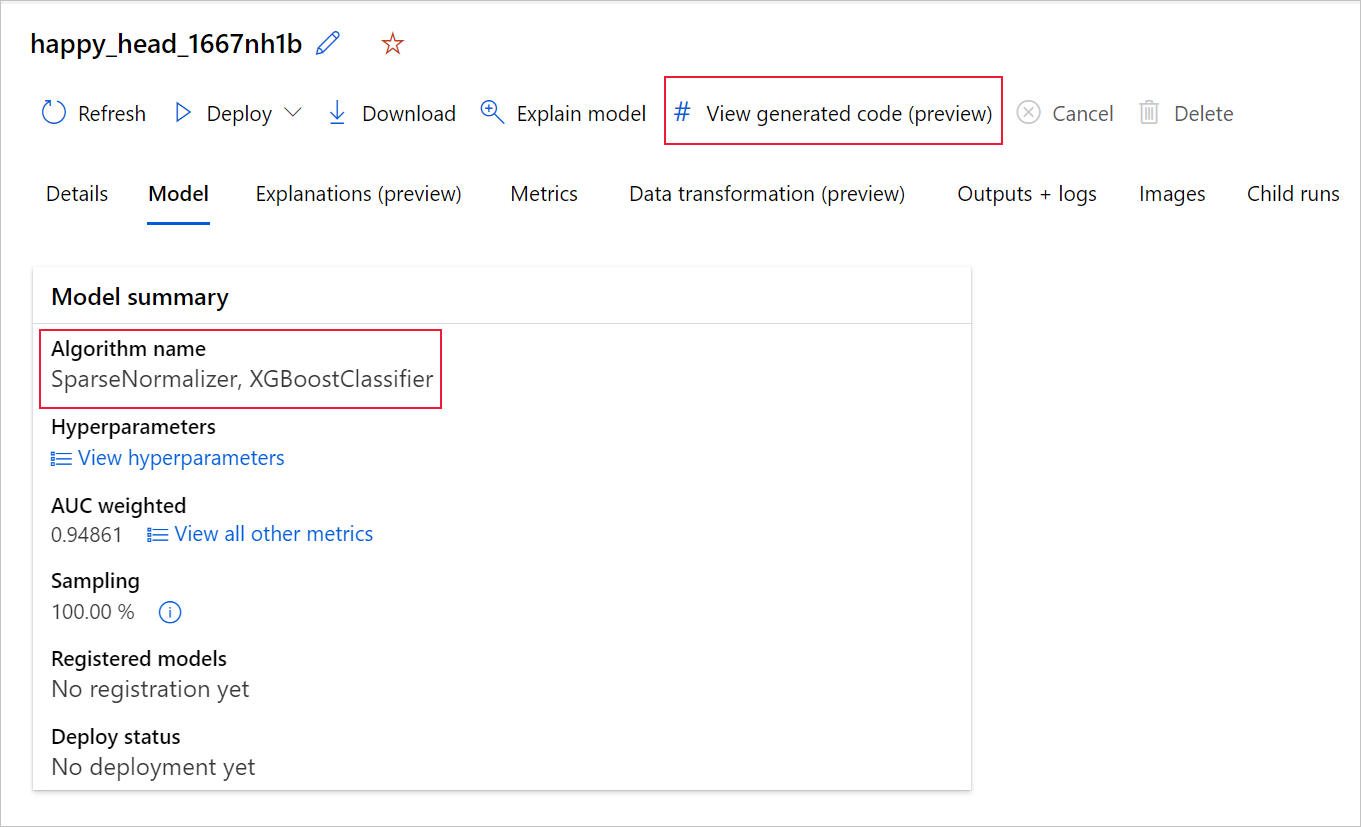
Ha a Python SDKv2-t használja, letöltheti a "script.py" és a "script_run_notebook.ipynb" fájlt is, ha lekérte a legjobb futtatást az MLFlow-n keresztül , és letölti az eredményül kapott összetevőket.
Korlátozások
A Generált kód nézet kiválasztásakor ismert probléma merült fel. Ez a művelet nem irányítja át a Jegyzetfüzetek portálra, ha a tárterület egy virtuális hálózat mögött található. Áthidaló megoldásként a felhasználó manuálisan letöltheti a script.py és a script_run_notebook.ipynb fájlokat a Kimenetek + Naplók lapra navigálva a kimenetek>generated_code mappa alatt. Ezek a fájlok manuálisan is feltölthetők a jegyzetfüzetek mappájába a futtatásukhoz vagy szerkesztésükhöz. Ezen a hivatkozáson további információt tudhat meg az Azure Machine Tanulás virtuális hálózatairól.
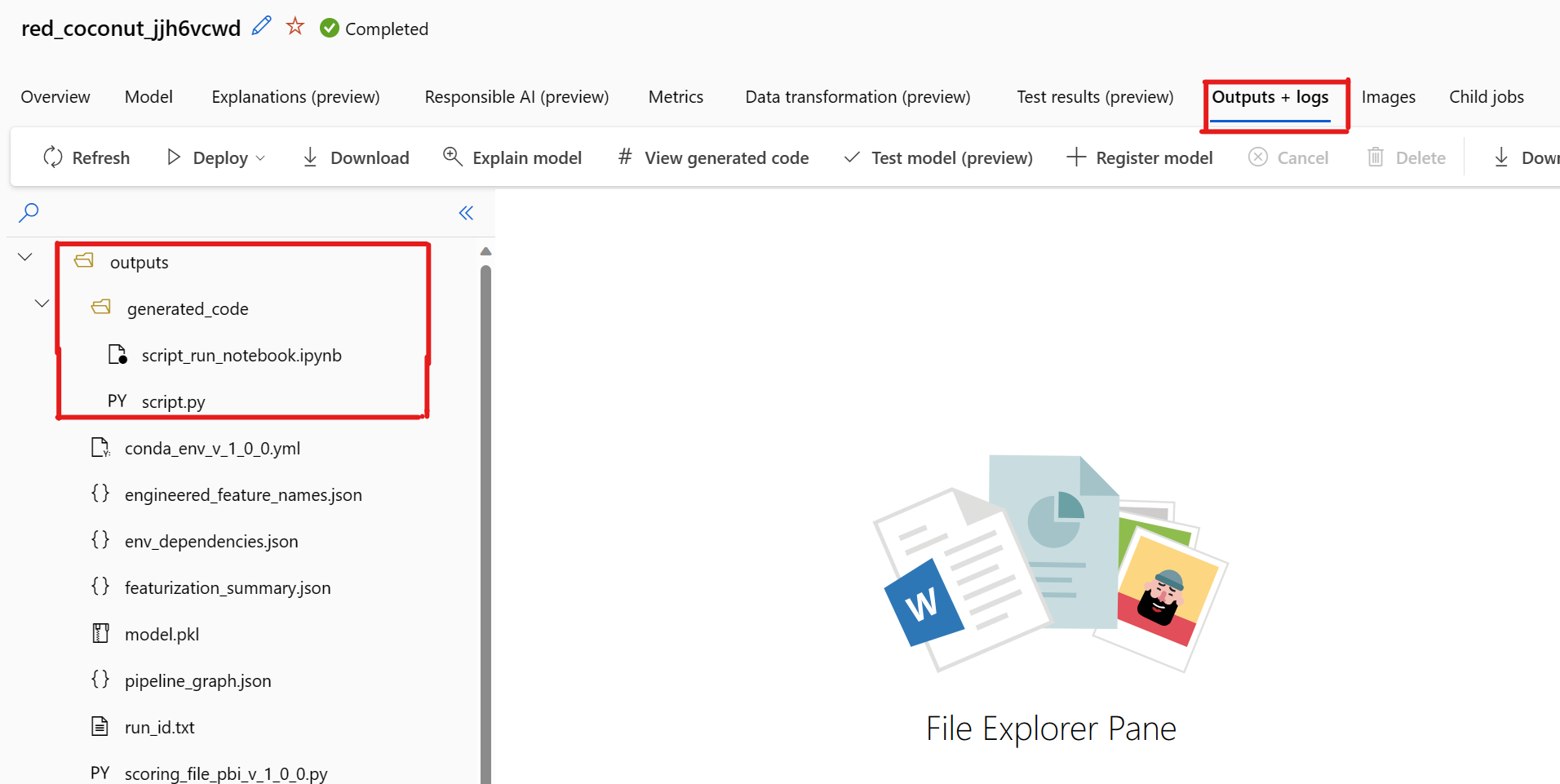
script.py
A script.py fájl tartalmazza a modell korábban használt hiperparaméterekkel való betanításához szükséges alapvető logikát. Bár az Azure Machine Tanulás szkriptfuttatásának kontextusában kívánják végrehajtani, néhány módosítással a modell betanítási kódja önállóan is futtatható a saját helyszíni környezetben.
A szkript nagyjából a következő részekre bontható: adatbetöltés, adat-előkészítés, adat featurizálás, előfeldolgozás/algoritmus specifikációja és betanítás.
Az adatok betöltése
A függvény get_training_dataset() betölti a korábban használt adathalmazt. Feltételezi, hogy a szkript egy Azure Machine-Tanulás szkriptben fut, ugyanazon a munkaterületen, mint az eredeti kísérlet.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Ha szkriptfuttatás részeként fut, Run.get_context().experiment.workspace lekéri a megfelelő munkaterületet. Ha azonban ez a szkript egy másik munkaterületen belül fut, vagy helyileg fut, módosítania kell a szkriptet a megfelelő munkaterület explicit megadásához.
A munkaterület lekérése után a rendszer az eredeti adatkészletet az azonosítójával kéri le. Egy másik, pontosan ugyanazzal a struktúrával rendelkező adatkészletet azonosító vagy név alapján is meg lehet adni az get_by_id() vagy get_by_name()azokkal. Az azonosítót később a szkriptben találhatja meg a következő kódhoz hasonló szakaszban.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Dönthet úgy is, hogy ezt a teljes függvényt saját adatbetöltési mechanizmusra cseréli; Az egyetlen korlátozás az, hogy a visszatérési értéknek Pandas-adatkeretnek kell lennie, és hogy az adatoknak ugyanolyan alakúnak kell lenniük, mint az eredeti kísérletben.
Adatelőkészítési kód
A függvény prepare_data() megtisztítja az adatokat, felosztja a funkciót és a minta súlyoszlopokat, és előkészíti az adatokat a betanításban való használatra.
Ez a függvény az adathalmaz típusától és a kísérletfeladat típusától függően változhat: besorolás, regresszió, idősorozat-előrejelzés, képek vagy NLP-feladatok.
Az alábbi példa azt mutatja be, hogy általában az adatbetöltési lépésből származó adatkeret lesz átadva. Ha eredetileg meg van adva a címkeoszlop és a mintasúly, a rendszer kinyeri a címkeoszlopot és a mintasúlyokat, és azokat tartalmazó NaN sorokat elveti a bemeneti adatokból.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Ha további adatelőkészítést szeretne végezni, az ebben a lépésben elvégezhető az egyéni adatelőkészítési kód hozzáadásával.
Adat featurizációs kód
A függvény generate_data_transformation_config() a végleges scikit-learn folyamat featurizálási lépését adja meg. Az eredeti kísérletben szereplő featurálókat itt reprodukáljuk a paraméterekkel együtt.
Az ebben a függvényben lehetséges adatátalakítás történhet például imputereken, például és CatImputer(), SimpleImputer() vagy átalakítókon, például StringCastTransformer() és LabelEncoderTransformer().
Az alábbiakban egy olyan típusú StringCastTransformer() transzformátort talál, amely oszlopok egy készletének átalakítására használható. Ebben az esetben a készlet által jelzett column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Ha sok olyan oszlopot használ, amelyeknek ugyanazt a featurizációt/átalakítást kell alkalmazniuk (például 50 oszlopot több oszlopcsoportban), ezeket az oszlopokat típus szerinti csoportosítással kezeli a rendszer.
Az alábbi példában figyelje meg, hogy minden csoporthoz egyedi leképező van alkalmazva. A rendszer ezt a leképezőt alkalmazza a csoport minden oszlopára.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Ez a megközelítés egyszerűbb kódot tesz lehetővé, mivel nem rendelkezik egy transzformátor kódblokkjával az egyes oszlopokhoz, ami különösen nehézkes lehet akkor is, ha több tíz vagy több száz oszlopot tartalmaz az adathalmazban.
Besorolási és regressziós feladatokFeatureUnion esetén [] a rendszer a featurálókhoz használatos.
Az idősorozat-előrejelzési modellek esetében a rendszer több idősorozat-tudatos featurizert gyűjt egy scikit-learn folyamatba, majd becsomagolja a TimeSeriesTransformer.
Az idősor-előrejelzési modellek minden felhasználó által megadott featurizációk az automatizált gépi tanulás által biztosítottak előtt történnek.
Előfeldolgozó specifikációkódja
A függvény generate_preprocessor_config()– ha van ilyen – egy előfeldolgozási lépést határoz meg, amely a végleges scikit-learn folyamat featurizálása után végezhető el.
Ez az előfeldolgozási lépés általában csak az adatszabványozásból/normalizálásból áll, amely a sklearn.preprocessing.
Az automatizált gépi tanulás csak a nem nem szerkeszthető besorolási és regressziós modellek előfeldolgozási lépését adja meg.
Íme egy példa egy generált előfeldolgozási kódra:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Algoritmusok és hiperparaméterek specifikációkódja
Az algoritmus és a hiperparaméterek specifikációkódja valószínűleg sok ml-szakembert érdekel a legjobban.
A generate_algorithm_config() függvény a modell betanításához használt tényleges algoritmust és hiperparamétereket adja meg a végső scikit-learn folyamat utolsó szakaszaként.
Az alábbi példa egy XGBoostClassifier algoritmust használ adott hiperparaméterekkel.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
A generált kód a legtöbb esetben nyílt forráskód szoftvercsomagokat és osztályokat használ. Vannak olyan példányok, ahol a köztes burkolóosztályokkal egyszerűbbé tehető a kód. Alkalmazhat például XGBoost-osztályozót és más gyakran használt kódtárakat, például LightGBM- vagy Scikit-Learn-algoritmusokat.
Ml Professionalként testre szabhatja az algoritmus konfigurációs kódját úgy, hogy szükség szerint módosítja annak hiperparamétereit az adott algoritmussal kapcsolatos készségei és tapasztalata és az adott ML-probléma alapján.
Az együttesmodellek generate_preprocessor_config_N() esetében (ha szükséges), és generate_algorithm_config_N() az együttes modell minden tanulójához vannak definiálva, ahol N az egyes tanulók elhelyezése az együttesmodell listájában. A verem-együttes modellek esetében a metatanuló generate_algorithm_config_meta() definiálva van.
Betanítási kód a végpontok között
A kódlétrehozás build_model_pipeline()train_model() a scikit-learn folyamatot, illetve a meghívást fit() adja ki és határozza meg.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
A scikit-learn folyamat tartalmazza a featurizációs lépést, egy előprocesszort (ha használják), valamint az algoritmust vagy a modellt.
Az idősorozat-előrejelzési modellek esetében a scikit-learn folyamat egy ForecastingPipelineWrapperolyan folyamatba van burkolva, amely további logikával rendelkezik az idősorok adatainak az alkalmazott algoritmustól függően való megfelelő kezeléséhez.
Minden tevékenységtípus esetében olyan esetekben használjuk PipelineWithYTransformer , amikor a címkeoszlopot kódolni kell.
Ha már rendelkezik a scikit-Learn folyamattal, a modell betanítása csak a fit() következő módon hívható meg:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
A visszatérési érték train_model() a bemeneti adatokra illesztett/betanított modell.
Az összes korábbi függvényt futtató fő kód a következő:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Ha már rendelkezik a betanított modellel, a predict() metódussal előrejelzéseket készíthet. Ha a kísérlet egy idősorozat-modellhez készült, használja az előrejelzés() metódust az előrejelzésekhez.
y_pred = model.predict(X)
Végül a modell szerializálva lesz, és "model.pkl" nevű fájlként .pkl van mentve:
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
A script_run_notebook.ipynb jegyzetfüzet egy Azure Machine-Tanulás számítási feladat egyszerű végrehajtásának script.py egyik módja.
Ez a jegyzetfüzet hasonló a meglévő automatizált gépi tanulási mintajegyzetfüzetekhez, azonban az alábbi szakaszokban ismertetett néhány fő különbség van.
Environment
Az automatizált ml-futtatás betanítási környezetét általában az SDK automatikusan beállítja. Az egyéni szkriptek futtatásakor azonban a generált kódhoz hasonlóan az automatizált gépi tanulás már nem hajtja végre a folyamatot, ezért a környezetet meg kell adni a parancsfeladat sikeres végrehajtásához.
A kódlétrehozás lehetőség szerint újra felhasználja az eredeti automatizált gépi tanulási kísérletben használt környezetet. Ezzel garantálja, hogy a betanítási szkript futtatása nem hiúsul meg a hiányzó függőségek miatt, és előnye, hogy nincs szükség Docker-rendszerképek újraépítésére, ami időt és számítási erőforrásokat takarít meg.
Ha olyan módosításokat script.py hajt végre, amelyek további függőségeket igényelnek, vagy saját környezetet szeretne használni, akkor ennek megfelelően frissítenie kell a script_run_notebook.ipynb környezetet.
A kísérlet elküldése
Mivel a létrehozott kódot már nem az automatizált gépi tanulás vezérli, az AutoML-feladat létrehozása és elküldése helyett létre kell hoznia és Command Job meg kell adnia a létrehozott kódot (script.py).
Az alábbi példa a parancsfeladat futtatásához szükséges paramétereket és rendszeres függőségeket tartalmazza, például a számítást, a környezetet stb.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
További lépések
- További információ a modell üzembe helyezésének módjáról és módjáról.
- Megtudhatja, hogyan engedélyezheti az értelmezhetőségi funkciókat kifejezetten az automatizált gépi tanulási kísérletekben.