Oktatóanyag: Modellfejlesztés felhőalapú munkaállomáson
Megtudhatja, hogyan fejleszthet betanítási szkriptet jegyzetfüzettel egy Azure Machine Tanulás felhőalapú munkaállomáson. Ez az oktatóanyag az első lépésekhez szükséges alapismereteket ismerteti:
- A felhőbeli munkaállomás beállítása és konfigurálása. A felhőalapú munkaállomást egy Azure Machine Tanulás számítási példány működteti, amely előre konfigurálva van környezetekkel a különböző modellfejlesztési igények támogatására.
- Felhőalapú fejlesztési környezetek használata.
- Az MLflow használatával nyomon követheti a modellmetrikáit, mindezt egy jegyzetfüzetből.
Előfeltételek
Az Azure Machine Tanulás használatához először munkaterületre lesz szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
Kezdje a jegyzetfüzetekkel
A munkaterület Jegyzetfüzetek szakasza jó kiindulópont az Azure Machine Tanulás és képességeinek megismeréséhez. Itt csatlakozhat számítási erőforrásokhoz, dolgozhat terminállal, és szerkesztheti és futtathatja a Jupyter-jegyzetfüzeteket és -szkripteket.
Jelentkezzen be az Azure Machine Tanulás Studióba.
Jelölje ki a munkaterületet, ha még nincs megnyitva.
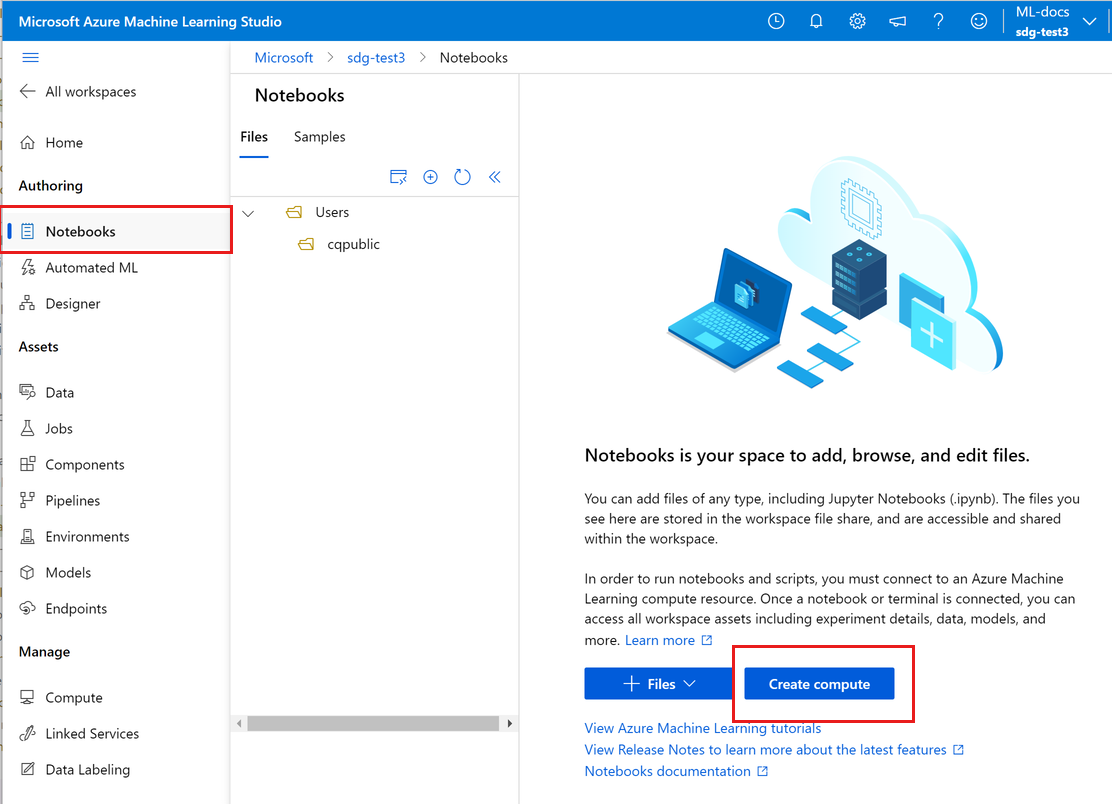
A bal oldali navigációs sávon válassza a Jegyzetfüzetek lehetőséget.
Ha nincs számítási példánya, a képernyő közepén megjelenik a Számítás létrehozása. Válassza a Számítás létrehozása lehetőséget, és töltse ki az űrlapot. Az összes alapértelmezett beállítást használhatja. (Ha már rendelkezik számítási példánnyal, akkor a Terminál azon a helyen. Az oktatóanyag későbbi részében a Terminált fogja használni.)
Új környezet beállítása prototípus-készítéshez (nem kötelező)
Ahhoz, hogy a szkript futhasson, a kód által várt függőségekkel és kódtárakkal konfigurált környezetben kell dolgoznia. Ez a szakasz segít létrehozni egy, a kódra szabott környezetet. Az új Jupyter-kernel létrehozásához, amelyhez a jegyzetfüzet csatlakozik, egy YAML-fájlt fog használni, amely meghatározza a függőségeket.
Töltsön fel egy fájlt.
A feltöltött fájlok egy Azure-fájlmegosztásban vannak tárolva, és ezek a fájlok az egyes számítási példányokra vannak csatlakoztatva, és meg vannak osztva a munkaterületen.
- Töltse le ezt a conda környezeti fájlt, workstation_env.yml fájlt a számítógépre a jobb felső sarokban található Nyers fájl letöltése gombbal.
Válassza a Fájlok hozzáadása lehetőséget, majd válassza a Fájlok feltöltése lehetőséget a munkaterületre való feltöltéshez.
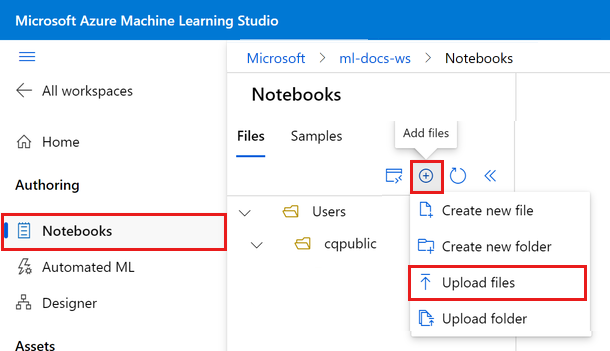
Válassza a Tallózás lehetőséget, és válassza ki a fájl(ok)t.
Válassza a letöltött workstation_env.yml fájlt.
Válassza a Feltöltés lehetőséget.
A workstation_env.yml fájlt a Felhasználónév mappa alatt láthatja a Fájlok lapon. A fájl előnézetének megtekintéséhez jelölje ki ezt a fájlt, és nézze meg, hogy milyen függőségeket határoz meg. A következőhöz hasonló tartalom jelenik meg:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibHozzon létre egy kernelt.
Most az Azure Machine Tanulás terminállal hozzon létre egy új Jupyter-kernelt a workstation_env.yml fájl alapján.
Terminálablak megnyitásához válassza a Terminál lehetőséget. A terminált a bal oldali parancssávon is megnyithatja:
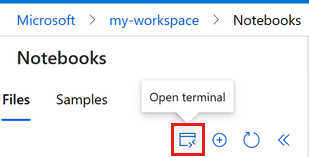
Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.

A számítás futtatása után egy üdvözlő üzenet jelenik meg a terminálban, és elkezdheti beírni a parancsokat.
Tekintse meg az aktuális Conda-környezeteket. Az aktív környezet *-nal van megjelölve.
conda env listHa létrehozott egy almappát ehhez az oktatóanyaghoz,
cdmost már ebbe a mappába.Hozza létre a környezetet a megadott Conda-fájl alapján. A környezet létrehozása néhány percet vesz igénybe.
conda env create -f workstation_env.ymlAktiválja az új környezetet.
conda activate workstation_envEllenőrizze, hogy a megfelelő környezet aktív-e, és keresse meg ismét a *-gal megjelölt környezetet.
conda env listHozzon létre egy új Jupyter-kernelt az aktív környezet alapján.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Zárja be a terminálablakot.

Most már van egy új kernele. Ezután megnyit egy jegyzetfüzetet, és ezt a kernelt fogja használni.
Create a notebook
Válassza a Fájlok hozzáadása lehetőséget, majd az Új fájl létrehozása lehetőséget.
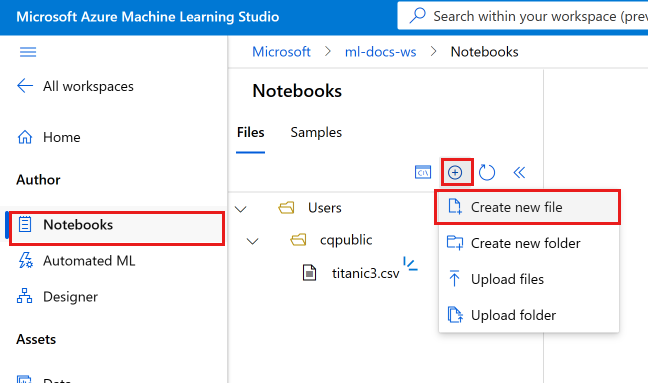
Nevezze el az új jegyzetfüzetet a develop-tutorial.ipynb fájlnak (vagy adja meg az előnyben részesített nevet).
Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.
Látni fogja, hogy a jegyzetfüzet a jobb felső sarokban csatlakozik az alapértelmezett kernelhez. Váltson a Tutorial Workstation Env kernel használatára, ha létrehozta a kernelt.
Betanítási szkript fejlesztése
Ebben a szakaszban egy Python-betanítási szkriptet fejleszt, amely előrejelzi a hitelkártya alapértelmezett kifizetéseit az UCI-adatkészletből származó előkészített teszt- és betanítási adatkészletek használatával.
Ez a kód a metrikák naplózásához a betanításhoz és az MLflow-hoz használható sklearn .
Kezdje a betanítási szkriptben használni kívánt csomagokat és kódtárakat importáló kóddal.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitEzután töltse be és dolgozza fel a kísérlet adatait. Ebben az oktatóanyagban egy internetes fájlból olvassa be az adatokat.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Készítse fel az adatokat a betanításra:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAdjon hozzá kódot az automatikus kitöltés
MLflowmegkezdéséhez, hogy nyomon tudja követni a metrikákat és az eredményeket. A modellfejlesztésMLflowiteratív jellegével segít naplózni a modell paramétereit és eredményeit. Tekintse át ezeket a futtatásokat a modell teljesítményének összehasonlításához és megértéséhez. A naplók kontextust is biztosítanak, amikor készen áll arra, hogy a fejlesztési fázisból a munkafolyamatok betanítási fázisára lépjen az Azure Machine Tanulás.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Modell betanítása.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Megjegyzés:
Figyelmen kívül hagyhatja a mlflow-figyelmeztetéseket. Továbbra is minden követendő eredményt megkap.
Továbbhaladás
Most, hogy már rendelkezik modelleredményekkel, érdemes lehet módosítani valamit, és próbálkozzon újra. Próbálkozzon például egy másik osztályozó technikával:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Megjegyzés:
Figyelmen kívül hagyhatja a mlflow-figyelmeztetéseket. Továbbra is minden követendő eredményt megkap.
Eredmények vizsgálata
Most, hogy két különböző modellt kipróbált, a nyomon követett MLFfow eredmények alapján döntse el, melyik modell a jobb. Hivatkozhat olyan metrikákra, mint a pontosság vagy a forgatókönyvek szempontjából leginkább fontos egyéb mutatók. Ezeket az eredményeket részletesebben is megismerheti, ha a létrehozott MLflowfeladatokat vizsgálja meg.
A bal oldali navigációs sávon válassza a Feladatok lehetőséget.
Válassza a Felhőalapú fejlesztés oktatóanyag hivatkozását.
Két különböző feladat jelenik meg, egyet a kipróbált modellekhez. Ezek a nevek automatikusan jönnek létre. Ha egy név fölé viszi az egérmutatót, használja a név melletti ceruzaeszközt, ha át szeretné nevezni.
Válassza ki az első feladat hivatkozását. A név a tetején jelenik meg. A ceruza eszközzel itt is átnevezheti.
A lapon a feladat részletei láthatók, például tulajdonságok, kimenetek, címkék és paraméterek. A Címkék területen megjelenik a modell típusát leíró estimator_name.
Válassza a Metrikák lapot a naplózott
MLflowmetrikák megtekintéséhez. (Az eredmények várhatóan eltérnek, mivel más betanítási készlettel rendelkezik.)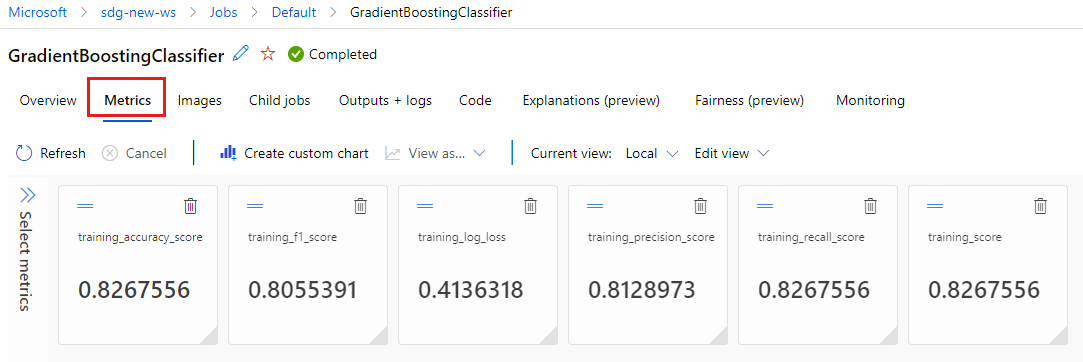
Válassza a Képek lapot a létrehozott
MLflowképek megtekintéséhez.
Térjen vissza, és tekintse át a másik modell metrikáit és rendszerképeit.
Python-szkript létrehozása
Most hozzon létre egy Python-szkriptet a jegyzetfüzetből a modell betanításához.
A jegyzetfüzet eszköztárán válassza ki a menüt.
Válassza az Exportálás Pythonként> lehetőséget.

Nevezze el a fájlt train.py.
Tekintse át ezt a fájlt, és törölje a betanítási szkriptben nem kívánt kódot. Tartsa meg például a használni kívánt modell kódját, és törölje a nem kívánt modell kódját.
- Győződjön meg arról, hogy megtartja az automatikusan elinduló kódot (
mlflow.sklearn.autolog()). - Törölheti az automatikusan létrehozott megjegyzéseket, és további megjegyzéseket fűzhet hozzá.
- Ha interaktívan futtatja a Python-szkriptet (terminálban vagy jegyzetfüzetben), megtarthatja a kísérlet nevét (
mlflow.set_experiment("Develop on cloud tutorial")) meghatározó sort. Vagy adjon neki egy másik nevet is, hogy más bejegyzésként tekintse meg a Feladatok szakaszban. Amikor azonban előkészíti a szkriptet egy betanítási feladathoz, ez a sor nem fog működni, és nem szabad kihagyni – a feladatdefiníció tartalmazza a kísérlet nevét. - Egyetlen modell betanításakor a futtatás (
mlflow.start_run()és ) indításához ésmlflow.end_run()befejezéséhez szükséges vonalak szintén nem szükségesek (hatásuk nem lesz), de tetszés szerint be is hagyhatók.
- Győződjön meg arról, hogy megtartja az automatikusan elinduló kódot (
Ha végzett a szerkesztésekkel, mentse a fájlt.
Most már rendelkezik egy Python-szkripttel az előnyben részesített modell betanításához.
A Python-szkript futtatása
Egyelőre ezt a kódot a számítási példányon futtatja, amely az Azure Machine Tanulás fejlesztési környezete. Oktatóanyag: A modell betanítása bemutatja, hogyan futtathat egy betanítási szkriptet skálázhatóbb módon a nagyobb teljesítményű számítási erőforrásokon.
A bal oldalon válassza a Terminál megnyitása lehetőséget egy terminálablak megnyitásához.
Tekintse meg az aktuális Conda-környezeteket. Az aktív környezet *-nal van megjelölve.
conda env listHa létrehozott egy új kernelt, aktiválja most:
conda activate workstation_envHa létrehozott egy almappát ehhez az oktatóanyaghoz,
cdmost már ebbe a mappába.Futtassa a betanítási szkriptet.
python train.py
Megjegyzés:
Figyelmen kívül hagyhatja a mlflow-figyelmeztetéseket. Továbbra is lekérheti az összes metrikát és képet az automatikus kitöltésből.
Szkripteredmények vizsgálata
Térjen vissza a Feladatokhoz a betanítási szkript eredményeinek megtekintéséhez. Ne feledje, hogy a betanítási adatok az egyes felosztásokkal változnak, így az eredmények a futtatások között is eltérnek.
Clean up resources
Ha most más oktatóanyagokra szeretne továbblépni, ugorjon a Következő lépésekre.
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali navigációs területén válassza a Számítás lehetőséget.
- A felső lapokban válassza a Számítási példányok lehetőséget
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine-Tanulás oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
A listából válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
További információk:
- Összetevőktől modellekig az MLflow-ban
- Git használata az Azure Machine Learninggel
- Jupyter-jegyzetfüzetek futtatása a munkaterületen
- Számításipéldány-terminál használata a munkaterületen
- Jegyzetfüzet- és terminál-munkamenetek kezelése
Ez az oktatóanyag bemutatta a modell létrehozásának első lépéseit, és a prototípuskészítést ugyanazon a gépen, ahol a kód található. Az éles betanításhoz ismerje meg, hogyan használhatja ezt a betanítási szkriptet nagyobb teljesítményű távoli számítási erőforrásokon: