Gyakori forgatókönyvek diagnosztizálása a Service Fabric használatával
Ez a cikk bemutatja, hogy a felhasználók milyen gyakori forgatókönyveket tapasztaltak a Service Fabric monitorozása és diagnosztikájának területén. A bemutatott forgatókönyvek a service fabric mind a 3 rétegét lefedik: alkalmazás, fürt és infrastruktúra. Minden megoldás az Application Insights és az Azure Monitor naplóit, az Azure monitorozási eszközeit használja az egyes forgatókönyvek elvégzéséhez. Az egyes megoldások lépései bemutatja, hogyan használhatják az Application Insights és az Azure Monitor naplóit a Service Fabric kontextusában.
Megjegyzés
Ez a cikk nemrég frissült, hogy a Log Analytics helyett az Azure Monitor-naplók kifejezést használja. A naplóadatok továbbra is egy Log Analytics-munkaterületen tárolódnak, és ugyanazon Log Analytics-szolgáltatás gyűjti és elemzi azokat. Frissítjük a terminológiát, hogy jobban tükrözze a naplók szerepét az Azure Monitorban. Részletekért tekintse meg az Azure Monitor terminológiai változásait ismertető cikket.
Előfeltételek és javaslatok
A cikkben szereplő megoldások a következő eszközöket fogják használni. Javasoljuk, hogy ezeket állítsa be és konfigurálja:
- Application Insights a Service Fabric használatával
- Azure Diagnostics engedélyezése a fürtön
- Log Analytics-munkaterület beállítása
- Log Analytics-ügynök a teljesítményszámlálók nyomon követéséhez
Hogyan tekinthetem meg a nem kezelt kivételeket az alkalmazásban?
Keresse meg azt az Application Insights-erőforrást, amellyel az alkalmazás konfigurálva van.
Kattintson a bal felső sarokban található Keresés elemre . Ezután kattintson a szűrőre a következő panelen.
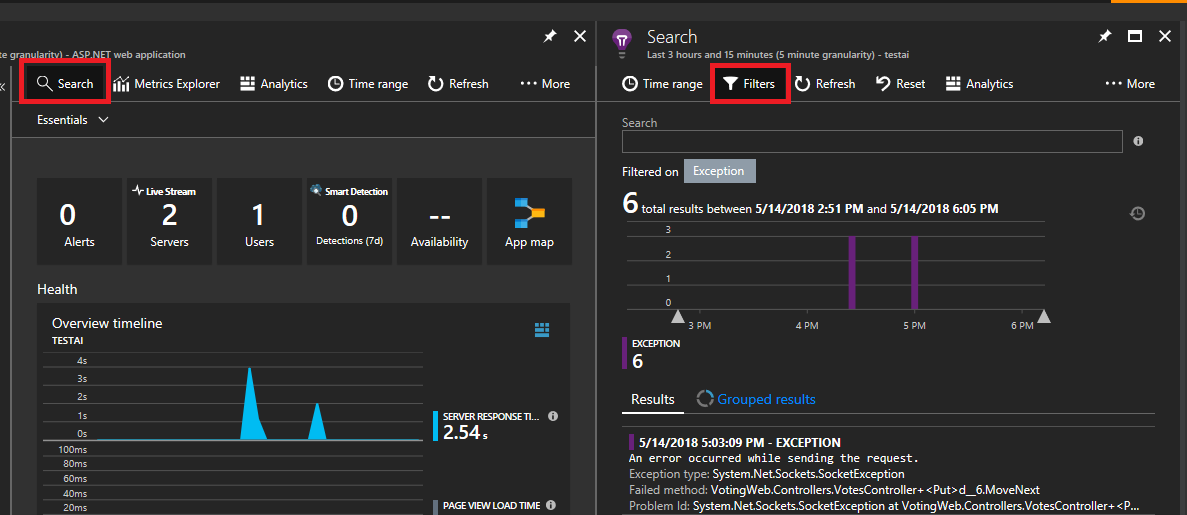
Számos eseménytípust (nyomkövetést, kérést, egyéni eseményt) fog látni. Szűrőként válassza a "Kivétel" lehetőséget.
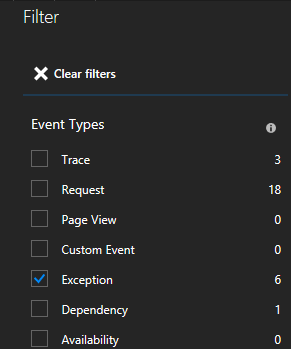
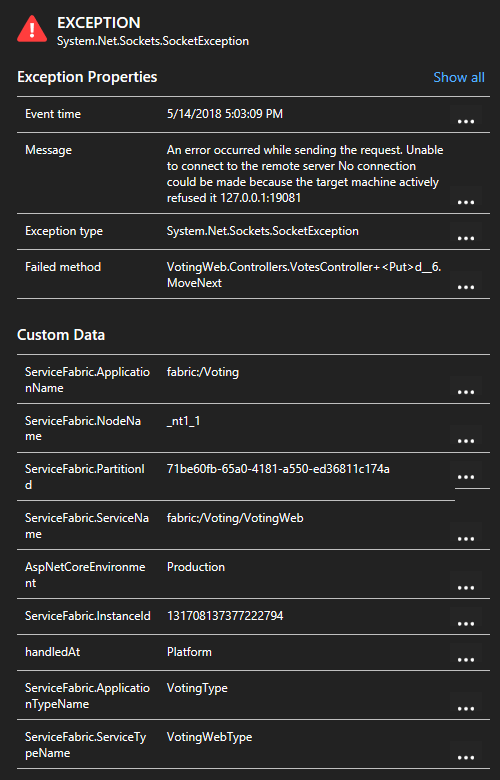
Ha egy kivételre kattint a listában, további részleteket tekinthet meg, beleértve a szolgáltatáskörnyezetet is, ha a Service Fabric Application Insights SDK-t használja.
Hogyan a szolgáltatásokban használt HTTP-hívások megtekintése?
Ugyanabban az Application Insights-erőforrásban kivétel helyett a "kérésekre" szűrhet, és megtekintheti az összes elküldött kérést
Ha a Service Fabric Application Insights SDK-t használja, láthatja a szolgáltatások egymáshoz csatlakoztatott vizuális ábrázolását, valamint a sikeres és sikertelen kérések számát. A bal oldalon kattintson az "Alkalmazástérkép" elemre.
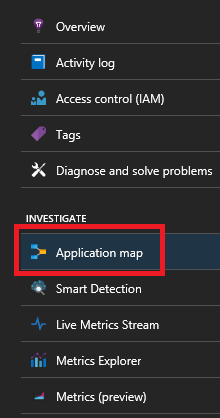
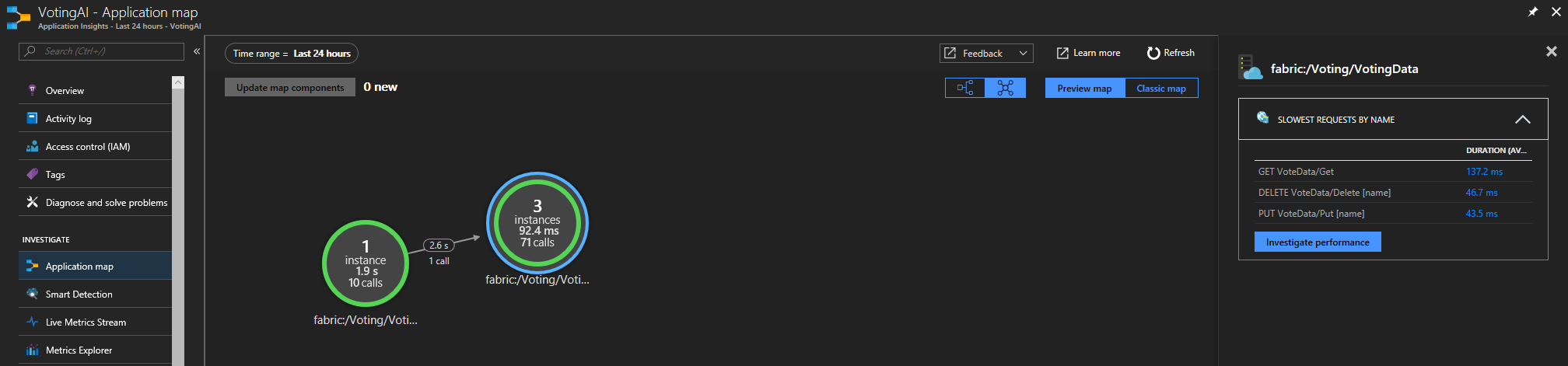
Az alkalmazástérképről további információt az Alkalmazástérkép dokumentációjában talál.
Hogyan hozzon létre egy riasztást, amikor egy csomópont leáll
A csomóponteseményeket a Service Fabric-fürt követi nyomon. Lépjen a ServiceFabric(NameofResourceGroup) nevű Service Fabric Analytics-megoldáserőforrásra
Kattintson az "Összefoglalás" nevű panel alján található gráfra
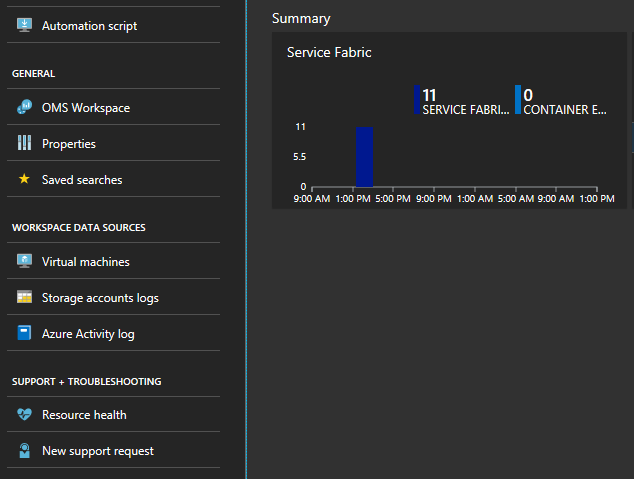
Itt számos különböző metrikát megjelenítő grafikon és csempe található. Kattintson az egyik gráfra, és megnyitja a Naplókeresést. Itt bármilyen fürteseményt vagy teljesítményszámlálót lekérdezhet.
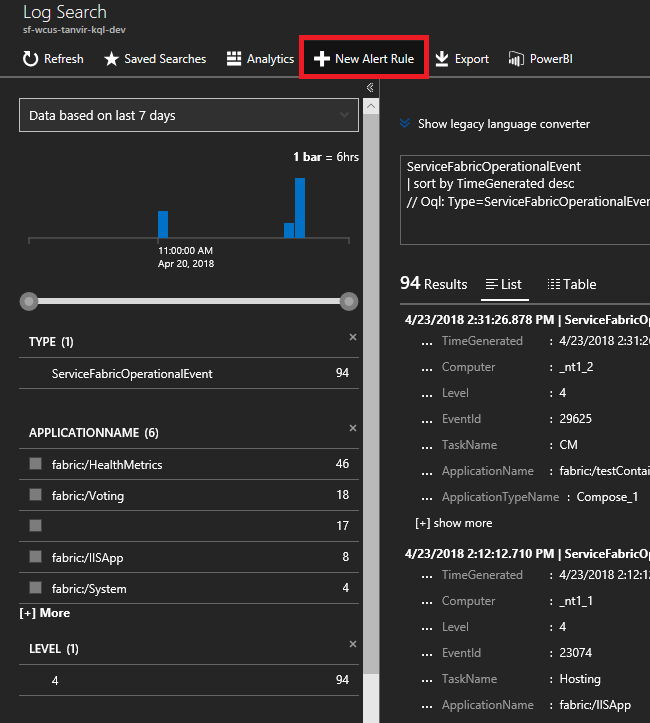
Adja meg a következő lekérdezést. Ezek az eseményazonosítók a Node-események referenciájában találhatók
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Kattintson felül az "Új riasztási szabály" elemre, és most, amikor egy esemény e lekérdezés alapján érkezik, riasztást fog kapni a választott kommunikációs módszerben.
Hogyan kaphatok riasztást az alkalmazásfrissítések visszaállításáról?
Ugyanabban a naplókeresési ablakban, mint korábban, írja be a következő lekérdezést a frissítés-visszaállításokhoz. Ezek az eseményazonosítók az Alkalmazásesemények referenciában találhatók
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Kattintson az "Új riasztási szabály" elemre a tetején, és most, amikor egy esemény a lekérdezés alapján érkezik, riasztást fog kapni.
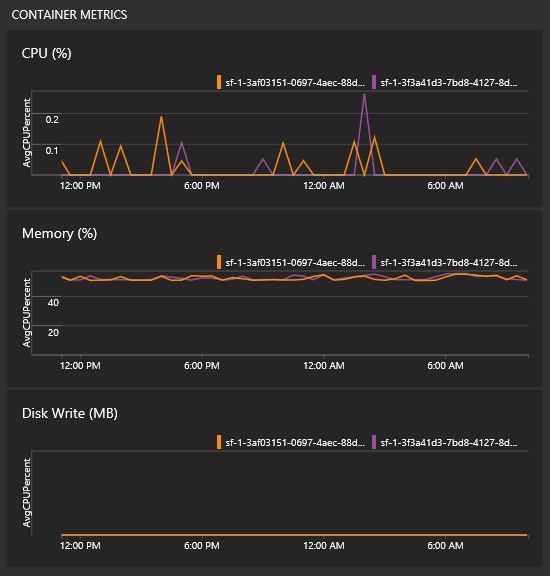
Hogyan lásd a tárolómetrikákat?
Az összes gráfot tartalmazó nézetben a tárolók teljesítményére vonatkozó csempék jelennek meg. A csempék feltöltéséhez szüksége lesz a Log Analytics-ügynökre és a tárolómonitorozási megoldásra .
Megjegyzés
A tárolón belüli telemetriai eszközökhöz hozzá kell adnia az Application Insights nuget-csomagot a tárolókhoz.
Hogyan monitorozhatom a teljesítményszámlálókat?
Miután hozzáadta a Log Analytics-ügynököt a fürthöz, hozzá kell adnia a nyomon követni kívánt teljesítményszámlálókat. Lépjen a Log Analytics-munkaterület lapjára a portálon – a megoldás oldaláról a munkaterület lap a bal oldali menüben található.

Miután a munkaterület oldalán volt, kattintson a bal oldali menü "Speciális beállítások" elemére.
Kattintson az Adat > Windows-teljesítményszámlálók (Linux rendszerű gépek adat > linuxos teljesítményszámlálói) elemre, hogy a Log Analytics-ügynökön keresztül megkezdje adott számlálók gyűjtését a csomópontokról. Íme néhány példa a hozzáadandó számlálók formátumára
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeA rövid útmutatóban a VotingData és a VotingWeb a használt folyamatnevek, így a számlálók nyomon követése a következőképpen néz ki:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes
Ez lehetővé teszi, hogy az infrastruktúra hogyan kezelje a számítási feladatokat, és releváns riasztásokat állítson be az erőforrás-használat alapján. Például érdemes lehet riasztást beállítani, ha a processzor teljes kihasználtsága 90% felett vagy 5% alatt van. Ehhez a számlálónévhez a következőt használná: "Processzoridő%-a". Ehhez hozzon létre egy riasztási szabályt a következő lekérdezéshez:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Hogyan a Reliable Services és az Actors teljesítményét?
A Reliable Services vagy Actors alkalmazásokban való teljesítményének nyomon követéséhez gyűjtse össze a Service Fabric-aktor, az aktormetódus, a szolgáltatás és a szolgáltatásmetódus számlálóit is. Íme néhány példa a megbízható szolgáltatás- és aktorteljesítmény-számlálók gyűjtésére
Megjegyzés
A Log Analytics-ügynök jelenleg nem gyűjthet Service Fabric-teljesítményszámlálókat, de más diagnosztikai megoldások is gyűjthetők
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Tekintse meg ezeket a hivatkozásokat a Reliable Services és az Actors teljesítményszámlálóinak teljes listájához
Következő lépések
- A kódcsomagok gyakori aktiválási hibáinak keresése
- Riasztások beállítása AI-ban , hogy értesítést kapjon a teljesítmény vagy a használat változásairól
- Az Application Insights intelligens észlelése proaktív elemzést végez az AI-nak küldött telemetriai adatokról, hogy figyelmeztessen a lehetséges teljesítményproblémákra
- További információ az Azure Monitor-naplók riasztásairól az észlelés és a diagnosztika támogatásához.
- A helyszíni fürtök esetében az Azure Monitor-naplók egy átjárót (HTTP Forward Proxyt) kínálnak, amellyel adatokat küldhet az Azure Monitor-naplókba. Erről további információt a Számítógépek csatlakoztatása internetelérés nélkül az Azure Monitor-naplókhoz a Log Analytics-átjáró használatával című témakörben olvashat.
- Ismerkedés az Azure Monitor-naplók részeként kínált naplókeresési és lekérdezési funkciókkal
- Részletesebb áttekintést kaphat az Azure Monitor-naplókról és az általa kínált lehetőségekről: Mi az az Azure Monitor-naplók?